

この記事は、インテル® デベロッパー・ゾーンに掲載されている「Collecting OpenCL*-related Metrics with Intel® Graphics Performance Analyzers」 (http://software.intel.com/en-us/articles/collecting-opencl-related-metrics-with-intel-graphics-performance-analyzers) の日本語参考訳です。
はじめに
インテル® SDK for OpenCL* Applications は、インテル® Core™ プロセッサー・ファミリー・ベースのプラットフォームで実行する OpenCL* ビジュアル・コンピューティング・アプリケーション向け統合ソフトウェア開発環境です。
バージョン 2012 から、インテル® HD グラフィックス 4000/2500 内蔵の第 3 世代インテル® Core™ プロセッサー・ファミリーで OpenCL* 1.1をサポートしています。バージョン 2013 R2 では、インテル® グラフィックスを搭載する第 4 世代インテル® Core™ プロセッサー・ファミリーと OpenCL 1.2 をサポートしています。最新のインテル® SDK for OpenCL* Applications は、https://www.isus.jp/article/intel-software-dev-products/intel-opencl/ から入手できます。
インテル® HD グラフィックス向けのパフォーマンスの最適化については、『Intel® SDK for OpenCL* Applications – Optimization Guide』を参照してください。インテル® SDK for OpenCL* Applications は、インテル® グラフィックス・パフォーマンス・アナライザー (インテル® GPA) に統合して、ビジュアル・コンピューティング・アプリケーションの OpenCL* コードを最適化および解析することもできます。
インテル® GPA は、インテルの CPU と HD グラフィックス・デバイス向けにさまざまなメトリック (評価基準) をサポートしています。レンダリング (Microsoft* DirectX* API) パイプライン専用のものもあれば、OpenCL* 実行に関連した汎用的なものもあります。
また、インテル® GPA では、次のようなインテルの CPU と HD グラフィックス・デバイスの重要なハードウェア・カウンターをリアルタイムで確認することができます。
- CPU コアとインテル® HD グラフィックス・デバイスの実行ユニットの使用状況
- インテル® HD グラフィックス・デバイスのメモリー・トラフィック
- 消費電力など
この記事では、インテル® HD グラフィックス・デバイス向けの OpenCL* 関連のメトリックについて説明します。CPU メトリックは、インテル® VTune™ Amplifier XE などを使うことでより詳しい情報が得られます。CPU での OpenCL* のプロファイルについては、『Intel® SDK for OpenCL* Applications User’s Guide』のインテル® VTune™ Amplifier XE に関するセクションを参照してください。また、『Intel® Graphics Performance Analyzers Help』の「Intel® GPA Platform Analyzer: Platform View」で説明されているように、インテル® GPA では CPU 全体の使用状況とジョブの分散状況も確認できます。
インテル® GPA システム・アナライザー
メトリックを利用するには、最初にインテル® GPA モニターでアプリケーションを実行し、次にインテル® GPA システム・アナライザーのヘッドアップ・ディスプレイ (HUD) を使用します。すると、(図 1 の左のスクリーンショットのように) メトリックのパネルが表示されます。あるいは、スタンドアロンのシステム・アナライザーを別のウィンドウで開くこともできます (図 2 の右のスクリーンショット)。詳細は、『Intel® Graphics Performance Analyzers Help』を参照してください。
インテル® GPA システム・アナライザーの HUD を実行する場合 (Ctrl + F1 キーで実行可能)、同時に表示できるメトリックは 4 つです。表示するメトリックは、インテル® GPA モニターの [Profiles] ダイアログ (図 1 の右のスクリーンショット) で選択できます。
スタンドアロンのインテル® GPA システム・アナライザー (図 2) を実行する場合、同時に多数のメトリックを表示できます。スタンドアロンの実行では GUI レンダリングで GPU をロードしないため、システム・アナライザーに関連するオーバーヘッドが懸念される場合は、スタンドアロンを利用したほうが良いでしょう。ネットワークを介して利用できますが、(デュアルモニターを使用するか、全画面表示のアプリケーションでなければ) ローカルでプロファイルすることも可能です。メトリックの収集によるオーバーヘッドは測定結果に影響する可能性があるため、収集するデータをよく吟味し、必要なデータだけを収集します。詳細は、『Intel® Graphics Performance Analyzers Help』の「Local Usage Mode」または「Network Usage Mode」を参照してください。
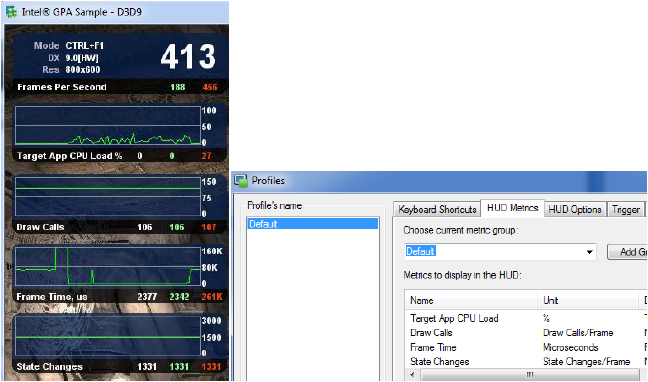
図 1. 左: インテル® GPA システム・アナライザー HUD (Ctrl + F1 キーでモードの切り替えが可能)
右: インテル® GPA モニターの [Profiles] ダイアログの [HUD Metrics] タブ
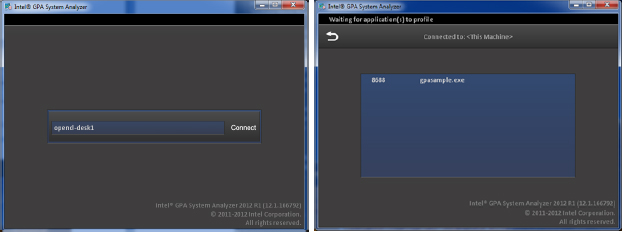
図 2. スタンドアロンのインテル® GPA システム・アナライザー
左: マシンへの接続 (ローカルマシンへの接続には “localhost” を使用)
右: プロファイル可能なアプリケーションのリスト
マシンに接続し、プロファイルするアプリケーションを選択すると、アナライザーのメインウィンドウが開きます (図 3)。
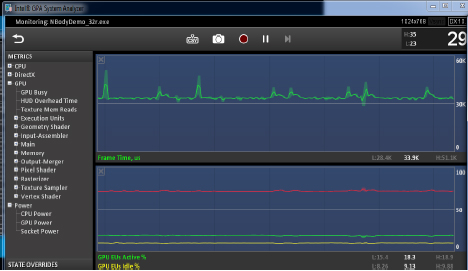
図 3. インテル® GPA システム・アナライザー
制限事項
DirectX* 以外のアプリケーションのプロファイルでは、CPU メトリックのみ利用できます。これは、汎用的な GPU メトリックであっても、各 Direct3D* フレーム内ではわずかな変化しか見られないため、コンソール・アプリケーションでは GPU 関連のメトリックを表示できないためです。
OpenCL* 関連のメトリック
次の種類の OpenCL* 関連のメトリックがサポートされます。
- コアの使用状況など CPU 固有のメトリック
- HD グラフィックスの実行ユニット (EU) に関するメトリック。GPU EU アクティブ/アイドル/ストールが最も重要です。
- GPU メモリーの読み込み/書き込みなどメモリーに関するメトリック
- CPU、インテル® HD グラフィックス・デバイス、パッケージ全体の消費電力に関するメトリック
これらは、インテル® GPA システム・アナライザーの左側のメトリックツリーにあります (図 4)。[GPU Busy] には OpenCL* などの汎用的な計算は含まれません。つまり、このメトリックは「3D レンダリング・コンテキスト内で GPU がビジー」であった割合を示しています。詳細は、『Intel® Graphics Performance Analyzers Help』を参照してください。
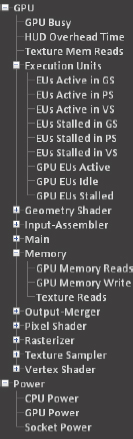
図 4. インテル® GPA システム・アナライザーで利用可能なメトリックリスト
よく使用されるメトリック
図 3 のシステム・アナライザーのスクリーンショットは、左側には利用可能なメトリックが表示され、右側には (リストからドラッグアンドドロップした) アクティブなメトリックのグラフが表示されています。このセクションでは、よく使用されるメトリックを紹介します。
OpenCL* タスクの特定
通常、メトリックはシステム全体で収集されます。そのため、レンダリング、デスクトップ/Windows* の更新、汎用的な OpenCL* 計算などさまざまなタスクが含まれます。インテル® HD グラフィックス・デバイスの OpenCL* パフォーマンスをデバッグする場合は、レンダリングの影響を最小限に抑えるようにします。さまざまなビデオ・アクティビティー (例えば、インテル® クイック・シンク・ビデオやインテル® Media SDK を用いたハードウェア支援による変換など) もメトリックに影響します。「Using Intel® Graphics Performance Analyzers (GPA) to analyze Intel® Media Software Development Kit-enabled applications」 (http://software.intel.com/en-us/articles/using-intel-graphics-performance-analyzer-gpa-to-analyze-intel-media-software-development-kit-enabled-applications) のサンプル解析を参考にしてください。
OpenCL* タスクを特定する方法はいくつかあります。
- Microsoft* DirectX* 呼び出しを一時的に削除/コメントアウトします。
- 可能であれば、ほとんどのシーンが視錐台外になるように、カメラの向きや位置を変更するなどして、大量のレンダリング処理をスキップします。
- ピクセルシェーダーで処理されるピクセルがごくわずかになるようにズームアウトします。
- 「Pixels Rendered (レンダリングされたピクセル数)」メトリックを基にピクセル数を予測するか、最小限にします。
同様に、デコーディングを無効にする (および 1 つのフレームで作業する) などして、ビデオ変換の影響を最小限に抑えることができます。
「OpenCL* and Intel® Media SDK Interoperability」(http://software.intel.com/en-us/articles/vcsource-samples-opencl-and-intel-media-sdk/) サンプルは、簡単な GUI を使って、デコーディングを一時停止/再開し OpenCL* による処理を有効にします。システム・アナライザーでこのサンプルを試してみてください。サンプルの異なるパイプライン・ステージによるメトリックへの影響を理解できるでしょう。
フレーム時間
Frame Time (フレーム時間) メトリックは、フレーム時間をマイクロ秒で示します。このメトリックを選択すると、フレーム時間に関する情報が表示されます (図 5)。
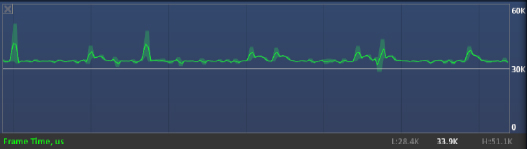
図 5. Frame Time (フレーム時間) メトリック
上記のスクリーンショットは、DirectX* フレームの Frame Time (フレーム時間) メトリックです (例えば Present 呼び出し間の時間)。フレームコストの分析における一般的な推奨事項については、前述の「OpenCL* タスクの特定」セクションを参照してください。
汎用的な実行ユニットメトリック
アルゴリズムがメモリーによって制限される場合を除き、実行ユニット (EU) がアプリケーションのパフォーマンス・ボトルネックになる可能性は高く、EU メトリックはこのようなボトルネックに関する情報を提供します。ここでの目標は、有益な計算で EU の利用率を最大限にすることです。『Intel® SDK for OpenCL* Applications – Optimization Guide』にそのためのヒントやコツが掲載されています。
以下は、EU 関連のメトリックの概要です。
- GPU EUs Active は、GPU 実行ユニット (EU) が実行中 (アクティブ状態) だった時間の割合 (%) を示します。Idle は、GPU 実行ユニット (EU) がアイドル状態だった時間の割合 (%) です。アイドル状態とは、EU が命令も実行しておらず、シェーダー命令を実行するべくストールもしていない状態を指します。
- GPU EUs Stalled は、GPU 実行ユニット (EU) がストール状態だった時間の割合 (%) を示します。EU は、そのすべてのスレッドが固定機能ユニットからの結果を待機している場合、ストール状態になります (例えば、テクスチャー・サンプラーからデータを要求するなど)。この場合、専用の EUs Stalled on Samp. (サンプラーによる EU ストール) メトリックから詳しい情報が得られます。
図 6 のスクリーンショットは、GPU EUs Stalled の割合が非常に高い状態を示しています。これは、メモリー帯域幅が効率良く使用されていないことが原因である可能性があります (例えば、データアクセスの粒度が最適でないか、キャッシュの廃棄により、データが利用可能になるのを GPU が待機しています)。データストールの疑いがある場合は、処理数/バイト比率を上げるようにカーネルを変更できます。
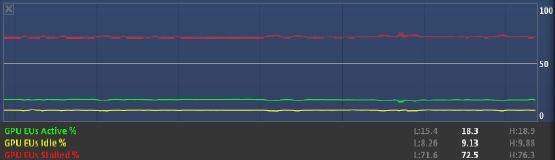
図 6. 汎用的な実行ユニットメトリック
ストールは、固定機能ユニット (例えば、超越関数に使用される mathbox など) の競合に起因している可能性もあります。このようなストールは、EUs Stalled on Math (数値演算ユニットによる EU ストール) メトリックから詳しい情報が得られます。この場合、精度を緩和するか、ネイティブ精度にしてみてください。詳細は、『Intel® Graphics Performance Analyzers Help』を参照してください。
最後に、ワークグループの数が足りない場合、EU 利用率が非常に低くなることがあります (GPU EUs Idle は高くなります)。clEnqueueNDRange 呼び出しに渡すローカルサイズが小さすぎても、EU はアイドル状態になります。詳細は、『Intel® SDK for OpenCL* Applications – Optimization Guide』の「Work-Group Size Recommendations Summary」を参照してください。
メモリー関連のメトリック
すべてのメモリー関連のメトリックの中で、OpenCL* カーネル実行に関係しているのは GPU Memory Reads/Writes (GPU メモリーの読み込み/書き込み) です。このメトリックを選択すると、図 7 のスクリーンショットのような、アプリケーションのメモリー・トラフィックが表示されます。
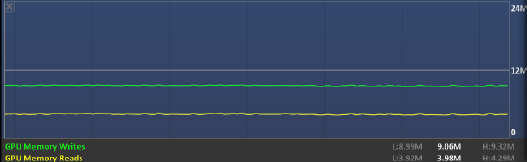
図 7. メモリーメトリック
この例では、総トラフィック (読み込み + 書き込み) が約 13GB/秒と多く、帯域幅がほぼ飽和状態にあります。理論的なメモリー・パフォーマンスと帯域幅の飽和については、『Intel® SDK for OpenCL* Applications – Optimization Guide』を参照してください。
この場合は、大きなチャンク (128 ビット) でデータにアクセスしてみると良いでしょう。詳細は、『Intel® SDK for OpenCL* Applications – Optimization Guide』を参照してください。帯域幅の負荷を緩和する別の最適化方法は、ローカルメモリーを使用することです。
まとめ
この記事では、以下の点について述べました。
- インテル® GPA システム・アナライザーの HUD またはスタンドアロンにより、選択したメトリック (カウンター) を簡単に追跡できます。
- システム・アナライザーは、インテルの CPU および HD グラフィックス・デバイスとソケット (システム) の使用状況を示す OpenCL* 関連のメトリックを提供します。
- インテル® HD グラフィックス・デバイスでは、実行ユニットとメモリー使用率のメトリックが最も重要です。
- メトリックの値については、『Intel® SDK for OpenCL* Applications – Optimization Guide』を参照してください。
コンパイラーの最適化に関する詳細は、最適化に関する注意事項を参照してください。
