
この記事は、The Parallel Universe Magazine 49 号に掲載されている「SYCLomatic: A New CUDA to SYCL Code Migration Tool」の日本語参考訳です。原文は更新される可能性があります。原文と翻訳文の内容が異なる場合は原文を優先してください。

CPU、GPU、FPGA、およびその他のアーキテクチャーでハイパフォーマンスと効率的な開発生産性を実現するには、開発者が目の前のタスクに最適なハードウェアを選択できる統一されたプログラミング・モデルが必要です。それには、標準化され、拡張可能な、高水準でオープンスタンダードのヘテロジニアス・プログラミング言語が不可欠です。また、開発者の生産性を向上させるとともに、どのアーキテクチャーでも一貫したパフォーマンスを提供する必要があります。Khronos Group の C++ ベースの SYCL* 標準は、C++ の機能を拡張し、マルチアーキテクチャーとディスジョイント・メモリー構成をサポートすることで、これらの課題に対処しています。
SYCL* の導入を容易にするため、開発者は SYCL* の開発をゼロから始めるのではなく、既存の CUDA* GPU コードを移行したいと考えるかもしれません。以前、インテル® DPC++ 互換性ツール (インテル® DPCT) を使用して CUDA* から SYCL* へ移行する記事を掲載しました。このツールは、インテル® oneAPI ベース・ツールキットに含まれており、インテルのテクニカル・コンサルティング・エンジニアによってサポートされています。
SYCLomatic オープンソース・プロジェクト
この互換性ツールは、開発者の要望に応え、「SYCLomatic」という名前でオープンソース・プロジェクトとしてリリースされています。多くの組織がこのツールを使用しており、一部の組織ではその機能を強化し、カスタマイズして自分たちのニーズに合わせてチューニングしています。その 1 つがアルゴンヌ国立研究所です。
「CRK-HACC は、現在活発に開発が行われている宇宙論的 N 体シミュレーション・コードです。Aurora の準備のため、インテル® DPC++ 互換性ツールを使用して、20 以上の (CUDA*) カーネルを SYCL* に素早く移行できました。コード移行ツールの現在のバージョンはファンクターへの移行をサポートしていないため、簡単な Clang ツールを記述して、生成された SYCL* ソースコードをニーズに合うようにリファクタリングしています。オープンソースの SYCLomatic プロジェクトでは、私たちのこれまでの研究を統合して、より堅牢なソリューションを提供し、ファンクターを利用可能な移行オプションにすることを計画しています。」
アルゴンヌ国立研究所
宇宙物理学 & 先進コンピューティング
HACC (Hardware/Hybrid Accelerated Cosmology Code)
Steve (Esteban) Rangel 氏
LLVM 例外付き Apache* 2.0 ライセンスを利用し、GitHub* でホストされている SYCLomatic プロジェクトは、CPU、GPU、FPGA 向けのオープンなヘテロジニアス開発を推進するため、開発者が貢献したり、フィードバックを送ることができるコミュニティーを用意しています。GitHub* ポータルにある「CONTRIBUTING.md」というガイドで、プロジェクトへの技術的貢献の手順が説明されています。開発者の皆さん、ぜひ本ツールを使用し、ツールを進化させるためフィードバックや貢献をお寄せください。このオープンソース・プロジェクトは、SYCL* 標準の採用を推進するコミュニティーに協力でき、開発者を単一ベンダーの独占的エコシステムから解放する重要なステップとなります。SYCLomatic に加えられた改善点は、インテル® DPC++ 互換性ツール製品にもフィードバックされます。
SYCLomatic ツールの仕組み
SYCLomatic は、CUDA* から SYCL* への移行を支援し、通常、CUDA* コードの 90 ~ 95% を自動的に SYCL* コードに移行します。開発者は残りのコーディングを手動で行い、ターゲット・アーキテクチャーで求められるパフォーマンスを達成できるようにチューニングします (図 1)。
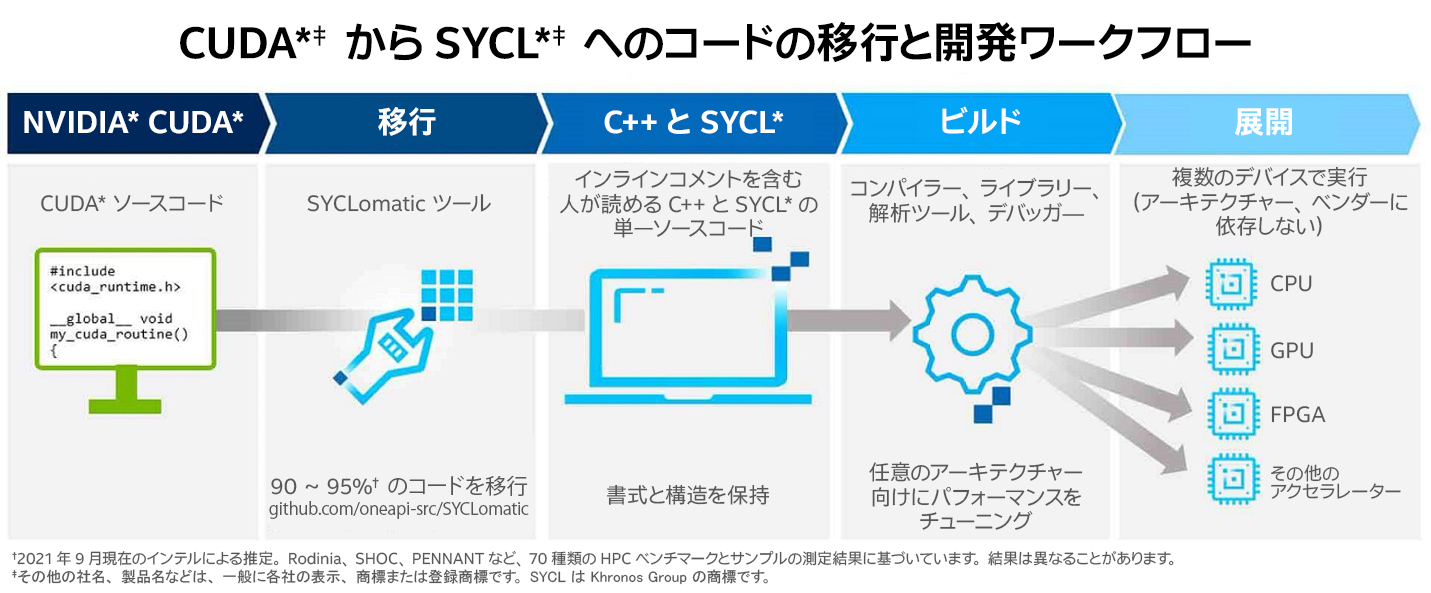
図 1. SYCLomatic のワークフロー
コード移行の成功例
多くの研究機関やインテルのお客様が、SYCLomatic と同じ技術を持つインテル® DPC++ 互換性ツールを使用して、複数のベンダーのアーキテクチャー上で CUDA* コードから SYCL* (または oneAPI の SYCL* 実装であるデータ並列 C++) への移行に成功しています。例として、ストックホルム大学の GROMACS 2022 (英語)、Zuse Institute Berlin (ZIB) (英語) の easyWave、Samsung Medison (英語)、Bittware (英語) などが挙げられます (その他の例は、oneAPI DevSummit のコンテンツ (英語) を参照してください)。また、アルゴンヌ国立研究所の Aurora スーパーコンピューター (英語)、ライプニッツ・スーパーコンピューティング・センター (LRZ) (英語)、GE Healthcare (英語) など、複数のお客様が現在および将来のインテル® Iris® Xe アーキテクチャー・ベースの GPU でコードをテストしています。
例: CUDA* ベクトル加算の SYCL* への移行
移行プロセスの実用的な概要を説明するため、ここではベクトル加算の簡単な CUDA* 実装を使用します。そして、SYCLomatic が生成するコードを詳しく見ていきます。主に、CUDA* と SYCL* が大きく異なるコードセクションに注目します。 このタスクには、インテル® oneAPI ベース・ツールキットの SYCLomatic とインテル® oneAPI DPC++/C++ コンパイラーを使用します。ツールキットをインストールするには、「インテル® oneAPI インストール・ガイド」 (英語) の手順に従ってください。次のワークフローを使用して、既存の CUDA* アプリケーションを SYCL* へ移行します。
- intercept-build ユーティリティーを使用して Makefile が実行するコマンドをインターセプトし、JSON 形式のコンパイル・データベース・ファイルに保存します。このステップは、シングルソースのプロジェクトではオプションです。
- SYCLomatic を使用して CUDA* コードを SYCL* へ移行します。
- 生成されたコードの正当性を検証し、警告メッセージで明示的に示された場合は、手動で移行を完了します。『インテル® DPC++ 互換性ツール・デベロッパー・ガイドおよびリファレンス』 (英語) を確認して警告を修正します。
- インテル® oneAPI DPC++/C++ コンパイラーでコードをコンパイルし、プログラムを実行して、出力を確認します。
その後、インテル® VTune™ プロファイラーを含むインテル® oneAPI の解析およびデバッグツールを使用して、コードをさらに最適化できます。
製品とパフォーマンス情報
1実際の性能は利用法、構成、その他の要因によって異なります。詳細については、www.Intel.com/PerformanceIndex (英語) を参照してください。
