
この記事は、The Parallel Universe Magazine 48 号に掲載されている「Five Outstanding Additions Found in SYCL 2020」の日本語参考訳です。原文は更新される可能性があります。原文と翻訳文の内容が異なる場合は原文を優先してください。

SYCL* は、C++ にヘテロジニアス・プログラミングのサポートをもたらす Khronos の標準規格です。2020年末に SYCL* 2020 仕様が確定し、それ以降、コンパイラーのサポートが拡大しています (実装については、Khronos のウェブサイト (英語) を参照してください)。
SYCL* については、「C++ のヘテロジニアスな将来の考察」や、sycl.tech (英語) に掲載されている多数のリソースなど、多くの場所で取り上げられています。簡単に言えば、SYCL* は、「C++ でヘテロジニアス・プログラミングを可能にし、ベンダーやアーキテクチャーを超えた移植性を実現するにはどうすればよいか?」という重要な課題に取り組んでいます。
コミュニティーからの強力なフィードバックにより、SYCL* 2020 は、さまざまなマルチベンダーとマルチアーキテクチャーに対応したエキサイティングな新機能を備えています。この記事では、これらの新機能とその目的について説明します。
5 つの優れた機能
SYCL* 2020 の重要な目標は、SYCL* を ISO C++ と整合させることであり、これには 2 つの利点があります。1 つは、C++ プログラマーにとって SYCL* が自然であることを保証します。もう 1 つは、SYCL* が、ほかの C++ ライブラリーや ISO C++ 自体にも影響を与える、ヘテロジニアス・プログラミングに対するマルチベンダー、マルチアーキテクチャー・ソリューションとして機能できるようになります。
SYCL* 2020 の構文変更の多くは、ベース言語を C++11 から C++17 へ更新したことに伴うもので、開発者はクラス・テンプレート引数推定 (CTAD) (英語) や推定ガイドなどの機能を利用できるようになりました。しかし、多くの新機能も追加されています。この記事では、SYCL* 2020 の新機能の中から 5 つを取り上げ、それらが重要な理由を説明します。
- バックエンドは、OpenCL* 以外の言語/ フレームワークで構築された SYCL* 実装への扉を開き、SYCL* がより多様なハードウェアをターゲットにすることを可能にします。
- 統合共有メモリー (USM) は、ポインターベースのアクセスモデルで、SYCL* 1.2.1 のバッファー/アクセサーモデルの代替となるものです。
- リダクションは、一般的なプログラミング・パターンであり、SYCL* 2020 は「組込み」ライブラリーによってこれを高速化します。
- グループ・ライブラリーは、協調的なワークアイテムの抽象化を提供し、 (ベンダーに関係なく) ハードウェア機能と整合性を取ることで、アプリケーションのパフォーマンスとプログラマーの生産性を向上させます。
- アトミック参照は C++20 の std::atomic_ref と整合性があり、C++ メモリーモデルをヘテロジニアス・デバイスに拡張します。
これらの機能は、オープンで、マルチベンダー、かつマルチアーキテクチャーの SYCL* エコシステムを確立し、C++ プログラマーが現在および将来のヘテロジニアス・コンピューティングの可能性を十分に引き出すのに役立ちます。
1. バックエンド
バックエンドの導入により、SYCL* 2020 は OpenCL* 以外の言語/ フレームワークで構築された実装への扉を開きます。その結果、名前空間は cl::sycl:: から sycl:: に短縮され、SYCL* ヘッダーファイルは <CL/sycl.hpp> から <sycl/sycl.hpp> になりました。
これは表面的な変更ではなく、SYCL* にとって重大な意味を持ちます。引き続き OpenCL* 上に実装できますが (そして多くの実装がそうしていますが)、汎用バックエンドのサポートにより、SYCL* はより多様なヘテロジニアス API とハードウェアをターゲットにできるプログラミング・モデルに変わりました。SYCL* は、C++ アプリケーションとベンダー固有のライブラリーとの間の「接着剤」として機能するようになり、開発者はより簡単に、しかもコードを変更することなく、さまざまなプラットフォームをターゲットにできます。
SYCL* 2020 は真にオープンで、クロスアーキテクチャー、かつクロスベンダーを実現
オープンソースの DPC++ コンパイラー・プロジェクト (英語) は、LLVM (clang) で SYCL* 2020 を実装し、この柔軟性を活かして NVIDIA*、AMD*、およびインテルの GPU をサポートします。SYCL* 2020 は真にオープンで、クロスアーキテクチャー、かつクロスベンダーを実現します (図 1)。
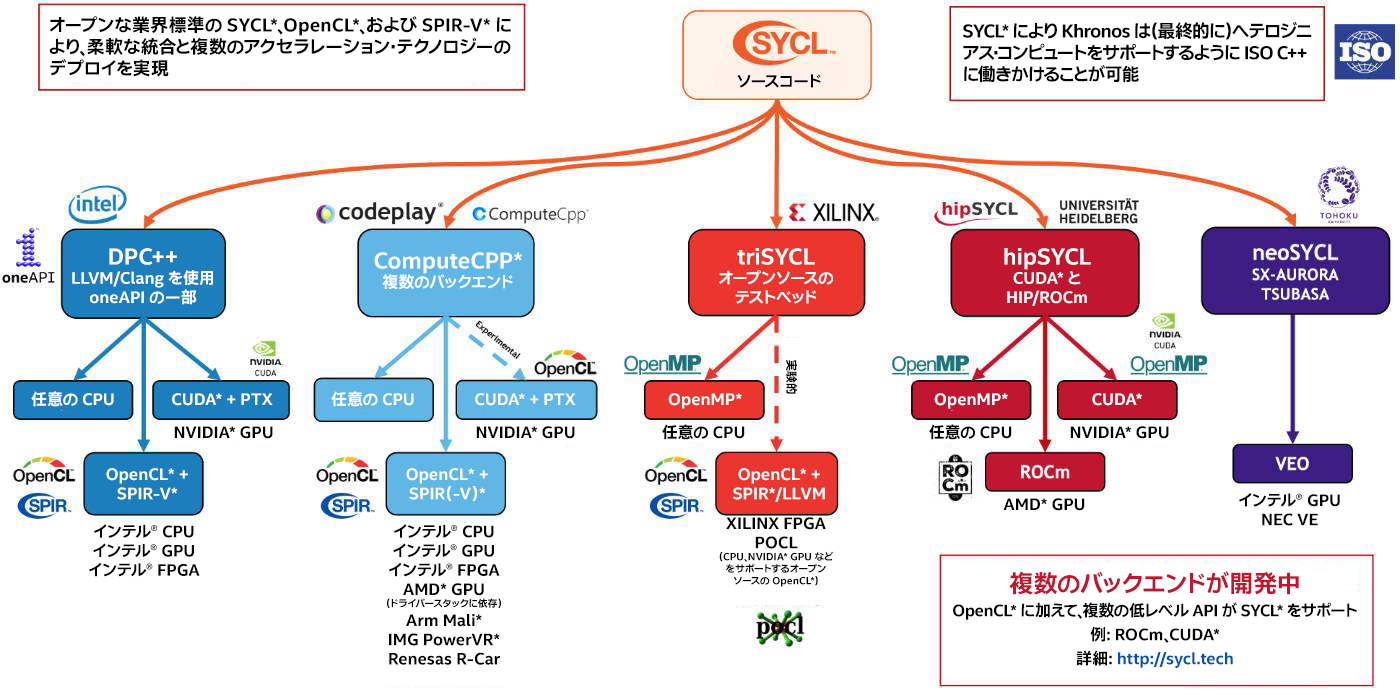
図 1. https://www.khronos.org/sycl/ (英語) の複数のバックエンドをターゲットとする SYCL* 実装
2. 統合共有メモリー
デバイスによっては、ホスト (CPU) と統一されたメモリービューをサポートできます。SYCL* 2020 では、これを統合共有メモリー (USM) と呼び、SYCL* 1.2.1 のバッファー/ アクセサーモデルに代わるポインターベースのアクセスモデルを可能にします。
USM を使ったプログラミングには、2 つの重要な利点があります。第一に、USM はホストとデバイスで単一の統合アドレス空間を提供します。USM 割り当てへのポインターはデバイス間で一貫しており、カーネルに直接引数として渡すことができます。これにより、既存のポインタベースの C++ および CUDA* コードの SYCL* への移行が大幅に簡素化されます。第二に、USM はデバイス間で自動的に移行する共有割り当てを可能にし、プログラマーの生産性を向上させ、C++ コンテナー (std::vector など) や C++ アルゴリズム (図 2 に示すようにインテル® oneDPL を介して) との互換性を提供します。
namespace stdsimd = std::experimental;
void simd_memcpy(
stdsimd::native_simd<float> x,
stdsimd::native_simd<float> y,
void *p)
{
auto cmp = x < y;
memcpy(p, &cmp, cmp.size()*4);
}
|
define void @_Z11simd_memcpy_Pv(<16 x float> %x.coerce,
<16 x float> %y.coerce, i8*
nocapture %p)
{
entry:
%0 = fcmp fast olt <16 x float> %x.coerce, %y.coerce
%cmp.sroa.0.sroa.0.0.p.sroa_cast = bitcast i8* %p to <16 x i1>*
store <16 x i1> %0, <16 x i1>* %cmp.sroa.0.sroa.0.0.p.sroa_cast
ret void
}
|
図 1. C++ SIMD データ並列ライブラリーの例
SIMD ベクトル化は、どのベクトル化手法を使用して SIMD コードを生成するかにかかわらず、最新の CPU および GPU 上で計算集約型ワークロードの最適なパフォーマンスを実現するために非常に重要です。次のセクションでは、いくつかのコード例とともに、CPU と GPU に関する最近の LLVM SIMD ベクトル化の進歩を紹介します。
製品とパフォーマンス情報
1実際の性能は利用法、構成、その他の要因によって異なります。詳細については、www.Intel.com/PerformanceIndex (英語) を参照してください。
