

インテル Parallel Universe マガジンの最新号 (英語) が公開されました。
注目記事: インテルの CPU と GPU 向けの LLVM と GCC のベクトル化
掲載記事
- OpenMP* を使用した効率良いヘテロジニアス並列プログラミング
- ArrayFire* と oneAPI、各種ライブラリー、OpenCL* の相互運用性
- oneAPI レベルゼロ・インターフェイスの使用
- Habana* Gaudi* 上での MLPerf* トレーニングの SigOpt を使用したハイパーパラメーター最適化
- Modin で pandas* のワークフローをスケーリング
- Ray から Chronos へ
編集者からのメッセージ
勢いを増す oneAPI
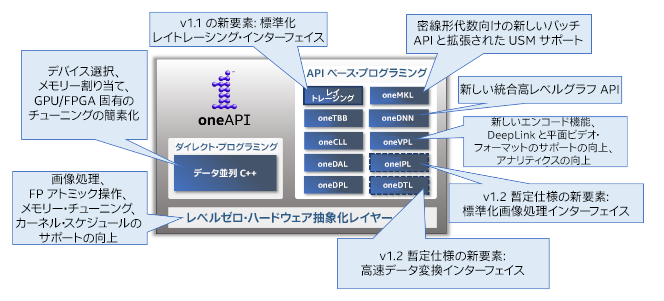
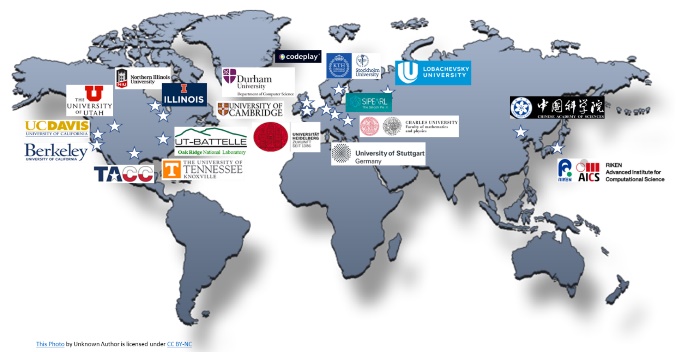
『The Parallel Universe』の編集者になった直後の「編集者からのメッセージ」では、来るべきヘテロジニアス並列コンピューティング時代に不安を感じていたことを述べました。あれから 5 年経った今は、oneAPI (英語) のお陰でヘテロジニアス並列コンピューティングの未来について楽観視しています。インテル コーポレーションの副社長兼ソフトウェア開発製品事業本部長の Sanjiv Shah は最近のブログ「oneAPI の進歩に感謝」 (英語) において、同様に楽観的な意見を述べています。新しい oneAPI v1.1 仕様が公開され、v1.2 暫定仕様では多くの新機能が追加されています。2021 年は新たに 11 の oneAPI 研究拠点が世界各地で発足しました。そして、oneAPI はまたもや HPCwire Reader’s Choice Award に選ばれ、「2021 年ベスト HPC プログラミング・ツール/テクノロジー」 (英語) を受賞しました。2022 年にはさらなる飛躍が期待されます。 |
  |
本号の注目記事「インテルの CPU と GPU 向けの LLVM と GCC のベクトル化」では、最新のコンパイラーにおける SIMD (Single Instruction, Multiple Data) サポートの進化を解説し、自動ベクトル化、プログラマーによるベクトル化、およびデータ並列ライブラリー・アプローチの例を示します。
「OpenMP* を使用した効率良いヘテロジニアス並列プログラミング」では、CPU と GPU を同時に動作させるベスト・プラクティスを紹介します。標準の OpenMP* ディレクティブを使用して、非同期のヘテロジニアス並列処理を表現するためのアドバイスとコード例を提供します。
関心の分離 (SoC) (英語) の観点から考えると、私自身はパフォーマンス・チューニング・エンジニアというよりも、ドメイン・サイエンティスト寄りで、ハードウェアの詳細を隠しつつパフォーマンスを発揮するプログラミングの抽象化に興味があります。最近は、ArrayFire* (英語) というヘテロジニアス並列ライブラリーを実験的に使っており、生産性とパフォーマンスの両面で良い結果が得られています。私の体験談は将来の号で紹介する予定ですが、本号では ArrayFire* のソフトウェア・エンジニアである Stefan Yurkevitch 氏が「ArrayFire* と oneAPI、各種ライブラリー、OpenCL* との相互運用性」について述べています。
「oneAPI レベルゼロ・インターフェイスの使用」では、ヘテロジニアス並列処理向けの高レベルのソフトウェア抽象化から、低レベルのハードウェア抽象化へと進みます。
本号の最後を締めくくるのはデータサイエンスに関する 3 つの記事です。1 つ目の記事は、モデルの精度を向上しつつ、「Habana* Gaudi* 上での MLPerf* トレーニングの SigOpt を使用したハイパーパラメーター最適化」を効率良く行う方法を紹介します。次の記事は、コードを書き換えずに「Modin で pandas* のワークフローをスケーリング」する方法を説明します。そして、最後の記事「Ray から Chronos へ」では、Ray 上に BigDL を使用してスケーラブルでエンドツーエンドの AI ワークフローを構築する方法を紹介します。
コードの現代化、ビジュアル・コンピューティング、データセンターとクラウド・コンピューティング、データサイエンス、システムと IoT 開発、oneAPI を利用したヘテロジニアス並列コンピューティング向けのインテル・ソリューションの詳細は、Tech.Decoded (英語) を参照してください。
Henry A. Gabb
2022 年 1 月
