
この記事は、The Parallel Universe Magazine 44 号に掲載されている「Reduction Operations in Data Parallel C++」の日本語参考訳です。

リダクション操作の概要
リダクションは、並列プログラミングにおける一般的な操作で、配列の要素を 1 つの結果にレデュースします。例えば、大きな配列の要素の総和を求める場合 (図 1)、操作を並列に実行するには、部分和を計算し、それを順次組み合わせて最終的な結果を算出する必要があります。リダクション演算子 (総和、最小値、最大値、最小位置、最大位置など) は結合的であり、多くの場合、可換的です。リダクションの実装方法は多数あり、そのパフォーマンスはプロセッサー・アーキテクチャーに依存します。この記事では、データ並列 C++ (DPC++) でリダクションを表現するいくつかの方法を紹介し、それぞれのパフォーマンスへの影響について考察します。
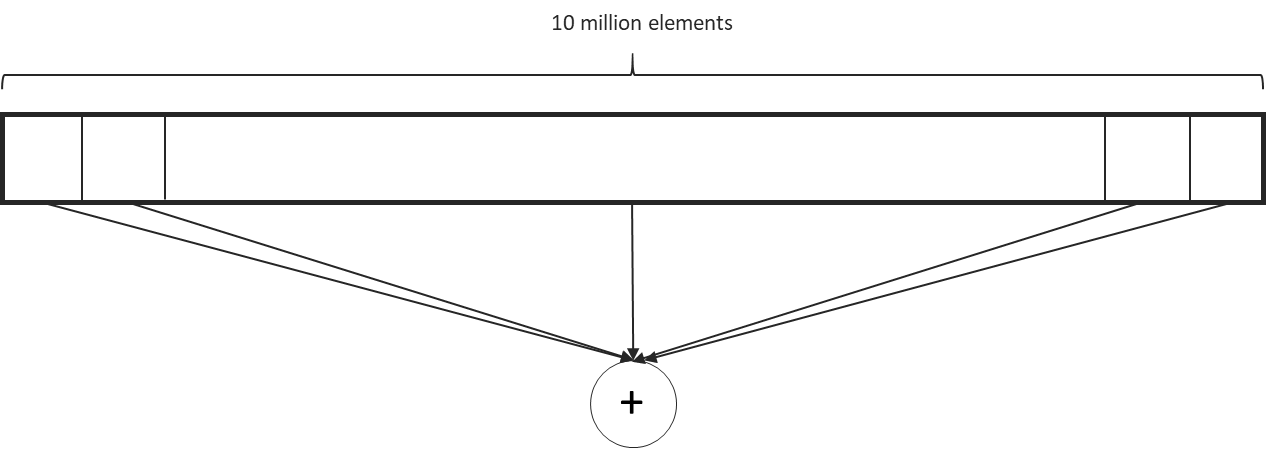
図 1. 総和リダクションの図
グローバルアトミックを使用した DPC++ のリダクション
以下の実装では、DPC++ カーネルの各ワークアイテムが入力配列の要素を処理して、グローバル変数をアトミックに更新します。
void reductionAtomics1(sycl::queue &q,
sycl::buffer<int> inbuf,
int &res,
int size) {
const size_t data_size = inbuf.get_size() / sizeof(int);
int num_work_items = data_size;
sycl::buffer<int> sum_buf(&res, 1);
q.submit([&](auto &h) {
sycl::accessor buf_acc(inbuf, h, sycl::read_only);
sycl::accessor sum_acc(sum_buf, h, sycl::write_only, sycl::noinit);
h.parallel_for(num_work_items, [=](auto index) {
size_t glob_id = index[0];
auto v = sycl::ONEAPI::atomic_ref<int,
sycl::ONEAPI::memory_order::relaxed,
sycl::ONEAPI::memory_scope::device,
sycl::access::address_space::global_space>(sum_acc[0]);
v.fetch_add(buf_acc[glob_id]);
});
});
コンパイラーが生成するスレッドの数 (コンパイラーが選択するターゲットデバイスのデフォルトのワークグループとサブグループのサイズに依存) によっては、単一のグローバル変数である sum_buf へのアクセス競合が頻繁に発生します。一般的に、このようなソリューションのパフォーマンスはあまり高くありません。
グローバルアトミックの競合の軽減
グローバル変数の更新時の競合を軽減する方法として、この変数にアクセスするスレッドの数を減らすことが挙げられます。これは、各ワークアイテムが配列の複数の要素を処理し、要素のチャンクに対してローカルなリダクションを実行した後、グローバルアトミック更新を実行することで実現できます (図 2)。
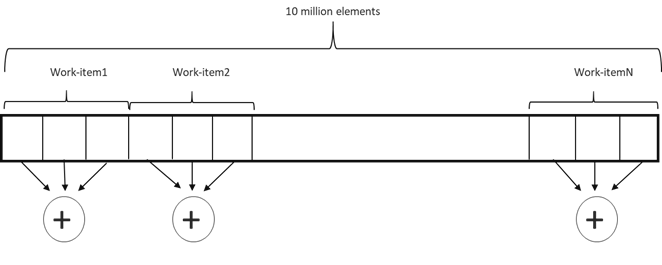
図 2. 各ワークアイテムは部分和を計算
以下は、この実装のコードです。
void reductionAtomics2(sycl::queue &q,
sycl::buffer<int> inbuf,
int &res) {
const size_t data_size = inbuf.get_size() / sizeof(int);
sycl::buffer<int> sum_buf(&res, 1);
int num_work_items =
q.get_device().get_info<sycl::info::device::max_compute_units>();
int BATCH = (data_size + num_work_items - 1) / num_work_items;
q.submit([&](auto &h) {
sycl::accessor buf_acc(inbuf, h, sycl::read_only);
sycl::accessor sum_acc(sum_buf, h, sycl::write_only, sycl::noinit);
h.parallel_for(num_processing_elements, [=](auto index) {
size_t glob_id = index[0];
size_t start = glob_id * BATCH;
size_t end = (glob_id + 1) * BATCH;
if (end > N)
end = N;
int sum = 0;
for (size_t i = start; i < end; i++)
sum += buf_acc[i];
auto v = sycl::ONEAPI::atomic_ref<int,
sycl::ONEAPI::memory_order::relaxed,
sycl::ONEAPI::memory_scope::device,
sycl::access::address_space::global_space>(sum_acc[0]);
v.fetch_add(sum);
});
});
}
この実装は、各ワークアイテムが連続するメモリー位置にアクセスするためあまり効率的ではなく、コンパイラーは非効率なコードを生成します。DPC++ コンパイラーは各ワークアイテムをベクトルレーンのように扱うため、連続するメモリー位置にアクセスするワークアイテムは非効率的になります。
コンパイラーの最適化に関する詳細は、最適化に関する注意事項を参照してください。
