
この記事は、The Parallel Universe Magazine 42 号に掲載されている「How to Speed Up Performance by Exploring GPU Configurations」の日本語参考訳です。

インテル® oneAPI ツールキット (英語) は、複数のアーキテクチャーにわたる多様なワークロードで妥協のないパフォーマンスを実現する、標準化ベースのプログラミング・モデルを提供します。最近、インテル® Advisor (英語) にインタラクティブにパフォーマンスをモデル化できるオフロード機能が追加されました。この記事では、オフロード・アドバイザーを使用して、将来のパフォーマンス向上の可能性を予測したり、特定のアプリケーションで最も影響の大きいハードウェア・コンポーネントを特定する方法を紹介します。この機能を使用することで、異なる GPU に計算をオフロードした場合、アプリケーションがどのように振る舞うかを調査できます。解析には、広く使用されているハイパフォーマンスな計算流体力学 (CFD) アプリケーションの Rodinia (英語) を使用します。
はじめに
ヘテロジニアス並列処理は、CFD 向けに CUDA* で実装されていました。基本的には、流体力学の 3 次元オイラー方程式を計算します。このアプリケーションは計算集約型であり、計算依存の問題があります。
ここでは、インテル® oneAPI 互換性ツールを使用して、CUDA* アプリケーションをデータ並列 C++ (DPC++) (英語) へ移行することを検証します。詳細は、The Parallel Universe 39 号の「インテル® oneAPI を使用したヘテロジニアス・プログラミング」を参照してください。
手法
ここでは、次の手法を使用します。
- オフロード・アドバイザーを使用して解析を実行します。
- 解析レポートからアプリケーションの主なボトルネックを確認します。例えば、計算、メモリー、またはその他の要因によってワークロードが制限されているかどうかを調べます。
- ボトルネックの情報を基に、さまざまな GPU 設定でパフォーマンス解析を実行して、ボトルネックを排除できるかどうかを確認します。例えば、ワークロードが計算依存の場合、実行ユニットの数を増やしてみます。
Rodinia アプリケーションは演算強度が高く、オフロード領域のほとんどは計算依存です。ベースライン・バージョンのオフロード・アドバイザー・レポートでは、オフロード領域の 92% が計算依存です (図 1)。つまり、実行ユニットを増やすことでアプリケーションを高速化できる可能性があります。また、呼び出しコストが 0% であることから、オフロードのオーバーヘッドの影響は少ないことが予想できます。その他のパラメーターは、現在の設定では無視できます。
オフロードの依存パラメーターから、ターゲット上でパフォーマンスを向上するために変更すべき設定が分かります。例えば、オフロードが計算依存の場合は、実行ユニット (EU) の数を増やします。一方、オフロードがメモリー依存の場合は、ターゲットの DRAM 帯域幅を増やして、GPU アクセラレーションのスピードアップを予測します。オフロード・アドバイザーは、ターゲットデバイス上での予測パフォーマンスをチューニングするインタラクティブなインターフェイスを提供します (図 2)。考慮すべきいくつかのオプションがあります。例えば、スライドバーを左右に動かして EU の数を増やしたり、減らしたりシミュレーションすることができます。同様にほかのパラメーターも調整できます。各種パラメーターを調整したら、後で解析に使用するため、![]() アイコンをクリックして設定をダウンロードします。
アイコンをクリックして設定をダウンロードします。
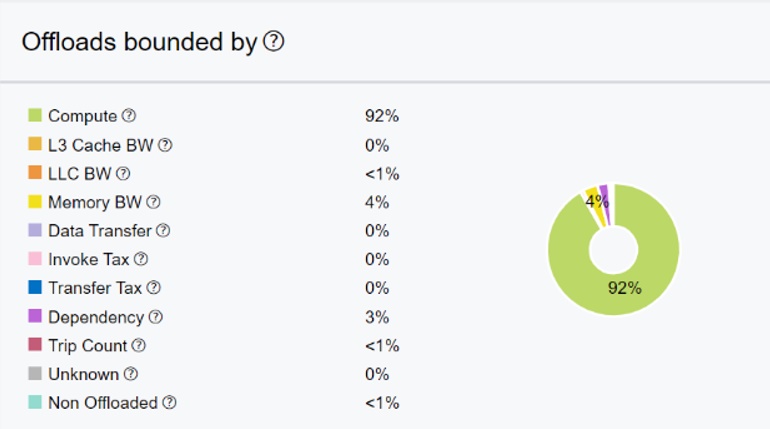
図 1. オフロードの依存パラメーターの内訳
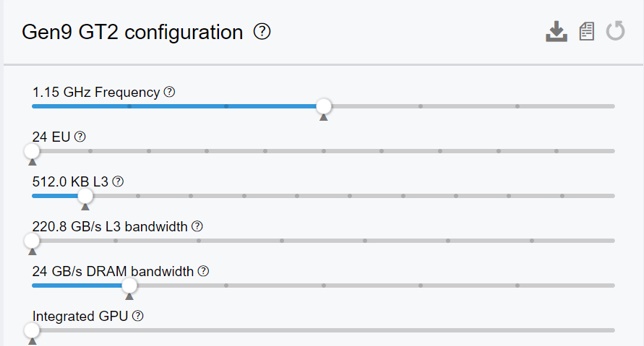
図 2. ターゲットデバイスの設定を変更してパフォーマンスを予測
結果
ここでは、fvcorr.domn.097K (https://git.scc.kit.edu/CES/Rodinia-SVM/blob/master/data/cfd/fvcorr.domn.097K) データセットを使用します。検証では、-jit オプションを使用して呼び出しコストを無効にします。ベースライン・バージョンを実行して結果を収集し、オフロード・アドバイザーを使用して解析します。次のように結果を収集します。

結果を解析するには、次のコマンドを使用します。
レポートファイルは、perf_models/m0000 フォルダーに書き込まれます。report.html ファイルをクリックして、ウェブブラウザーで結果を表示します。解析を実行するたびに、perf_models フォルダー内にプリフィクス m**** のフォルダーが作成されます。レポートファイルにはいくつかのウィンドウがありますが、ここでは [Summary] ウィンドウに注目します (図 3)。
コンパイラーの最適化に関する詳細は、最適化に関する注意事項を参照してください。
