

この記事は、Dr.Dobb’s Go Parallel に掲載されている「Cpuinfo: The Processor Information Utility for Intel MPI Library」 (http://drdobbs.com/go-parallel/blogs/parallel/232600802) の日本語参考訳です。
MPI アプリケーションに適したプロセスピニングを定義するには、クラスターノード、論理プロセッサー ID、パッケージ上の配置、異なるキャッシュレベルの共有、機能フラグなどの詳細情報を収集する必要があります。インテル® MPI ライブラリーに含まれる cpuinfo コマンドライン・ユーティリティーは、これらの情報収集に最も役立つツールです。異なる識別子を使用して、プロセスピニングの設定に必要な情報を取得することができます。ここでは、Windows* を使用した例を紹介します。
私はよく、ハードウェアに関する情報を提供するツールについて投稿しています。ハードウェアを理解することで、ハードウェアを最大限に活用するようにアプリケーションを最適化できるからです。実際に、MPI アプリケーションは、多数のマルチコア・プロセッサーを提供する複数のハイパフォーマンス・クラスター・ノード上で使用されます。
インテル® Cluster Studio 2012 およびインテル® Cluster Studio XE 2012 のリリース以来、最新のインテル® MPI ライブラリーと関連ツールへの関心が高まっています。どちらのスイートにもインテル® MPI ライブラリー 4.0 Update 3 が含まれており、cpuinfo ユーティリティーを利用することができます。インテル® MPI ライブラリーを初めて使う開発者からプロセッサー・ピニングの設定について聞かれた場合、私は常に cpuinfo コマンドライン・ユーティリティーを使用することの必要性を強調しています。たいてい、その次の質問は、このユーティリティーはどこからダウンロードできるか? というものです。インテル® MPI ライブラリーを使用している場合、バージョン 3.1 以降にはこのユーティリティーが含まれているため、ダウンロードする必要はありません。
デフォルトでは、インテル® MPI ライブラリーのアプリケーションとドキュメントは、[スタート] > [Intel(R) Software Development Products] > [Intel(R) MPI Library 4.0 Update 3] から利用できます。Build Environment コマンドライン・ランチャーは、[Build environment for IA-32] (IA-32 用アプリケーション用) と [Build environment for Intel(R) 64] (インテル® 64 アプリケーション用) メニューにあります (図 1 を参照)。[Build environment for Intel(R) 64] の [Build Environment] をクリックすると、新しいコマンドラインが起動し、必要なすべてのパスと環境変数を定義する mpivars.bat バッチファイルが実行されます。デフォルトでは、このショートカット・メニューは次のバッチファイルを実行します。
1 | C:\Windows\SysWOW64\cmd.exe /K "C:\Program Files (x86)\Intel\MPI\4.0.3.009\em64t\bin\mpivars.bat" |
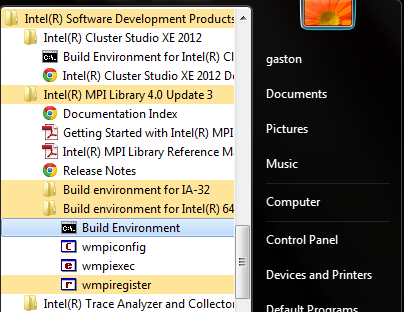
図 1. [Build Environment for Intel(R) 64] メニューと [Build Environment] コマンドライン・ランチャー
コマンドライン・ウィンドウが開き、cpuinfo ユーティリティーやその他のインテル® MPI コマンドライン・ユーティリティーを実行することができます (図 2 を参照)。ここでは、インテル® 64 アプリケーション用のビルド環境を選択しています。
図 2.インテル® MPI ライブラリー 4.0 Update 3 Windows* OS 版のインテル® 64 アプリケーション用ビルド環境
ビルド環境のコマンドラインが表示されたら、cpuinfo ユーティリティーを実行します。cpuinfo A を実行すると、すべての情報テーブルが出力されます。オプション A は、利用可能なすべてのオプションを表します。cpuinfo の出力はコンソールテキストなので、必要に応じてファイルへリダイレクトしてください。
特定の情報だけが必要な場合は、各情報テーブルを表す文字を指定することで、そのテーブルだけを出力できます。
オプション g は、単一のクラスターノードの一般情報を出力します。プロセッサー名、プロセッサー・モデル、ノード上のパッケージ (ソケット) 数、ノードごとの物理コアの合計数、ノードごとのハードウェア・スレッドまたは論理プロセッサーの合計数、パッケージ (ソケット) ごとの物理コアの合計数、物理コアごとのハードウェア・スレッドの合計数が表示されます。以下に、cpuinfo g を実行した際に出力されるテーブルの例を示します。
1 2 3 4 5 6 7 | ===== Processor composition =====Processor name: Genuine Intel(R) Name ModelPackages(sockets) : 2Cores : 16Processors(CPUs) : 32Cores per package : 8Threads per core : 2 |
以下は、各行を説明しています。
1 2 3 4 5 6 7 8 | ===== Processor composition =====Processor name: Genuine Intel(R) Name ModelPackages(sockets) : 2 -- ノード上のパッケージ (ソケット) 数Cores : 16 -- ノードごとの物理コアの合計数Processors(CPUs) : 32 -- ノードごとのハードウェア・スレッドまたは論理プロセッサーの合計数Cores per package : 8 -- パッケージ (ソケット) ごとの物理コアの合計数Threads per core : 2 -- 物理コアごとのハードウェア・スレッドの合計数。 CPU がインテル® ハイパースレッディング・テクノロジーに対応しているため、物理コアごとに 2 つのハードウェア・スレッドが提供されます。 |
オプション i は論理プロセッサー ID を出力するため、各ハードウェア・スレッドまたは論理プロセッサー (Processor)、コア内の一意のプロセッサー ID (Thread ID)、パッケージ内の一意のコア ID (Core ID)、およびノード内の一意のパッケージ ID (Package ID) を識別します。以下に、32 個の論理プロセッサーを提供する 2 個のパッケージに対して cpuinfo i を実行した際に出力されるテーブルの例を示します。
===== Processor identification =====
| Processor | Thread ID | Core ID | Package ID |
| 0 | 0 | 0 | 0 |
| 1 | 0 | 1 | 1 |
| 2 | 0 | 2 | 0 |
| 3 | 0 | 3 | 0 |
| 4 | 0 | 4 | 0 |
| 5 | 0 | 5 | 0 |
| 6 | 0 | 6 | 0 |
| 7 | 0 | 7 | 0 |
| 8 | 0 | 0 | 1 |
| 9 | 0 | 1 | 1 |
| 10 | 0 | 2 | 1 |
| 11 | 0 | 3 | 1 |
| 12 | 0 | 4 | 1 |
| 13 | 0 | 5 | 1 |
| 14 | 0 | 6 | 1 |
| 15 | 0 | 7 | 1 |
| 16 | 1 | 0 | 0 |
| 17 | 1 | 1 | 0 |
| 18 | 1 | 2 | 0 |
| 19 | 1 | 3 | 0 |
| 20 | 1 | 4 | 0 |
| 21 | 1 | 5 | 0 |
| 22 | 1 | 6 | 0 |
| 23 | 1 | 7 | 0 |
| 24 | 1 | 0 | 1 |
| 25 | 1 | 1 | 1 |
| 26 | 1 | 2 | 1 |
| 27 | 1 | 3 | 1 |
| 28 | 1 | 4 | 1 |
| 29 | 1 | 5 | 1 |
| 30 | 1 | 6 | 1 |
| 31 | 1 | 7 | 1 |
前述のテーブルでは分かりにくい場合、ノード分割テーブルが役立つでしょう。オプション d は、物理パッケージ ID (Package ID) ごとに 1 つのエントリーを表示するノード分割テーブルを出力します。パッケージごとに、パッケージに含まれる一意のコア ID (Core ID) のリストとハードウェア・スレッドまたは論理プロセッサー (Processors) のリストの両方が表示されます。括弧で囲まれたハードウェア・スレッドまたは論理プロセッサー (Processors) のグループは、一意のコア ID のものです。
以下に、cpuinfo d を実行した際に出力されるテーブルの例を示します (前述の cpuinfo i の出力例と比較してみてください)。
1 2 3 4 | ===== Placement on packages =====Package ID Core ID Processors0 0,1,2,3,4,5,6,7 (0,16)(1,17)(2,18)(3,19)(4,20)(5,21)(6,22)(7,23)1 0,1,2,3,4,5,6,7 (8,24)(9,25)(10,26)(11,27)(12,28)(13,29)(14,30)(15,31) |
オプション c は、論理プロセッサーによる異なるレベルとサイズのキャッシュ共有を出力します。キャッシュレベル (Cache) とそのサイズ (Size) に続き、括弧で囲まれたそのキャッシュを共有する論理プロセッサーのグループのリストが表示されます。括弧で囲まれた論理プロセッサーのグループはそれぞれキャッシュを共有します。
以下に、 cpuinfo c を実行した際に出力されるテーブルの例を示します。
1 2 3 4 5 6 7 8 | ===== Cache sharing =====Cache Size ProcessorsL1 32 KB(0,16)(1,17)(2,18)(3,19)(4,20)(5,21)(6,22)(7,23)(8,24)(9,25)(10,26)(11,27)(12,28)(13,29)(14,30)(15,31)L2 256 KB(0,16)(1,17)(2,18)(3,19)(4,20)(5,21)(6,22)(7,23)(8,24)(9,25)(10,26)(11,27)(12,28)(13,29)(14,30)(15,31)L3 20 MB(0,1,2,3,4,5,6,7,16,17,18,19,20,21,22,23)(8,9,10,11,12,13,14,15,24,25,26,27,28,29,30,31) |
この他にも、次の 2 つのオプションがあります。
- s — プロセッサー・シグネチャーを出力します。
- f — プロセッサーの機能フラグを出力します。
ノードに関する情報が必要な場合は、この cpuinfo と紹介したオプションを使用して必要なすべての情報を取得できます。識別子を理解すると、MPI アプリケーションに適したプロセスピニング設定を簡単に定義できます。
インテル® MPI ライブラリーは商用製品ですが、こちらから無料体験版をダウンロードすることができます。
