
この記事は、インテル® デベロッパー・ゾーンに公開されている「Intel® Advisor Cookbook」の「Optimize Vectorization Aspects of a Real-Time 3D Cardiac Electrophysiology Simulation」(https://software.intel.com/content/www/us/en/develop/documentation/advisor-cookbook/top/optimize-vectorization-aspects-of-a-real-time-3d-cardiac-electrophysiology-simulation.html) の日本語参考訳です。
バージョン: 2021.1 (最終更新日: 2021 年 2 月 24 日)
このレシピは、インテル® Xeon® プロセッサー・ベースのプラットフォーム上で、インテル® Advisor を使用して、リアルタイムの 3D 心臓電気生理学シミュレーション・アプリケーションをベクトル化する方法を紹介します。
シナリオ
このレシピは、インテル® Advisor を使用して、アプリケーションのベクトル化に関連するパフォーマンスを解析する方法を示します。インテル® Advisor の推奨事項に基づいてソースコードを変更し、ベースラインの結果と比較してアプリケーションのパフォーマンスを 2.55 倍向上させます。以下のセクションでは、適用したすべての最適化ステップについて説明します。
コンポーネント
ここでは、このレシピで示す特定の結果を得るために使用したハードウェアとソフトウェアをリストします。
- パフォーマンス解析ツール: インテル® Advisor 2020
https://software.intel.com/content/www/us/en/develop/tools/advisor/choose-download.html (英語) からダウンロードできます。
- アプリケーション: Cardiac_demo サンプルアプリケーション
GitHub* (https://github.com/CardiacDemo/Cardiac_demo (英語)) からダウンロードできます。
ワークロード:
- 小規模メッシュ (17937 要素、4618 ノード)
- 中規模メッシュ (112790 要素、28187 ノード)
- コンパイラー: インテル® C++ コンパイラー 2020
https://software.intel.com/content/www/us/en/develop/tools/compilers/c-compilers/choose-download.html (英語) からダウンロードできます。
- その他のツール: インテル® MPI ライブラリー 2019
https://software.intel.com/content/www/us/en/develop/tools/mpi-library/choose-download.html (英語) からダウンロードできます。
- オペレーティング・システム: Linux* (Red Hat* 4.8.5-39)
- CPU: 以下に示す構成のインテル® Xeon® プロセッサー (開発コード名 Cascade Lake) ベースのシステム。
===== Processor composition ===== Processor name : Intel(R) Xeon(R) Platinum 8260L Packages(sockets) : 2 Cores : 48 Processors(CPUs) : 96 Cores per package : 24 Threads per core : 2
プロセッサーの構成を表示するには、インテル® MPI ライブラリーの mpivars.sh スクリプトをソースして、cpuinfo -g コマンドを実行します。
必要条件
環境をセットアップ
- インテル® C++ コンパイラー、インテル® MPI ライブラリー、およびインテル® Advisor の環境変数を設定します。
$ source <compiler-install-dir>/linux/bin/compilervars.sh intel64 $ source <mpi-install-dir>/intel64/bin/mpivars.sh $ source <advisor-install-dir>/advixe-vars.sh
- ツールが正しく設定されたことを確認します。
$ mpiicc -v $ mpiexec -V $ advixe-cl –version
正しく設定されている場合、各ツールのバージョンが表示されます。
アプリケーションをビルド
- アプリケーションの GitHub* リポジトリーをローカルシステムにクローンします。
git clone https://github.com/CardiacDemo/Cardiac_demo.git
- *.tar.gz ファイルを展開します。
- サンプルパッケージのルートレベルにビルド・ディレクトリーを作成して、そのディレクトリーに移動します。
mkdir build cd build
- アプリケーションをビルドします。
mpiicpc ../heart_demo.cpp ../luo_rudy_1991.cpp ../rcm.cpp ../mesh.cpp -g -o heart_demo -O3 -xCORE-AVX2 -std=c++11 -qopenmp -parallel-source-info=2
現在のディレクトリーに heart_demo 実行ファイルが生成されます。
デモを実行する には、次のコマンドを使用します。
export OMP_NUM_THREADS=1 mpirun -n 48 ./heart_demo -m ../mesh_mid -s ../setup_mid.txt -t 100 -i
ベースラインを確認する
- GUI で、ビルドした heart_demo アプリケーションのサーベイ (英語)、トリップカウント (英語)、および FLOP (英語) 解析を実行して結果を表示します。
- [Summary (サマリー)] レポートに移動してメトリックを確認します。
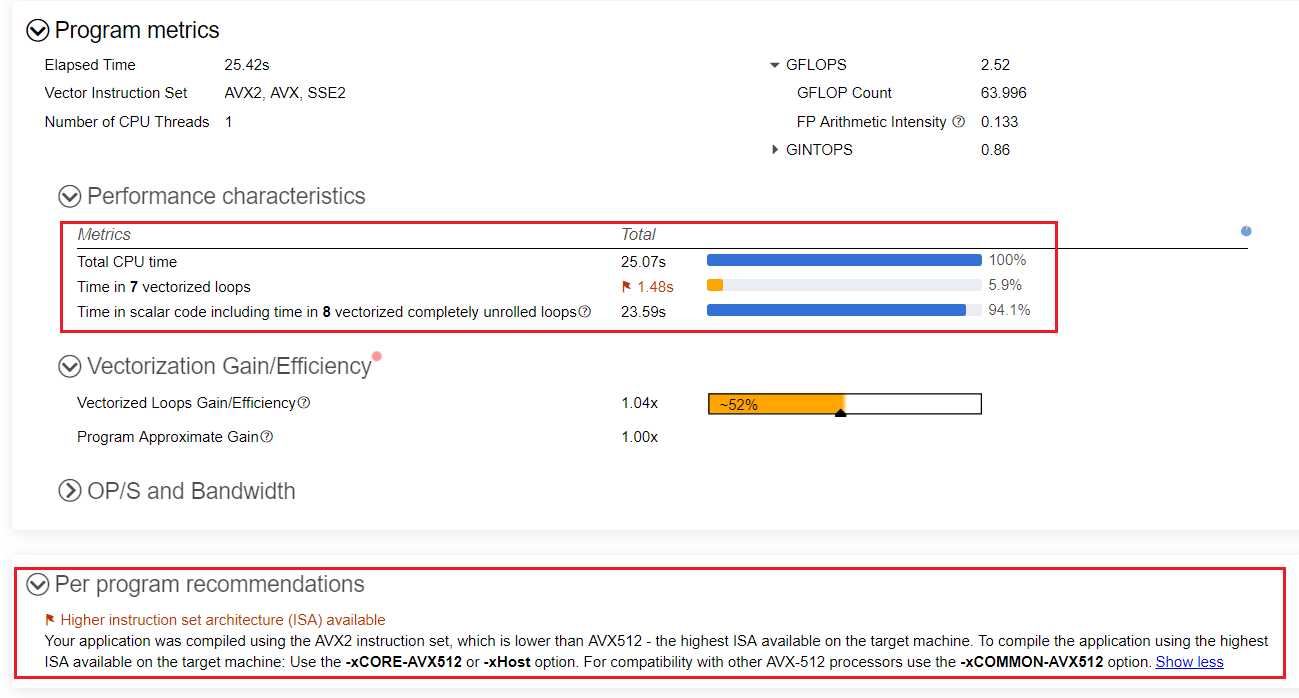
- ベクトル化されたループに費やされる時間は全体の 6% に過ぎず、残りの 94% はスカラーコードに費やされています。
- [Per Program Recommendation (プログラムごとの推奨事項)] は、ターゲットマシンで利用可能な最上位の命令セット・アーキテクチャー (ISA) である、インテル® アドバンスト・ベクトル・エクステンション 512 (インテル® AVX-512) の使用を提案しています。
- heart_demo アプリケーションの実行には 22.7 秒かかります。
注
[Summary (サマリー)] でレポートされる時間には、インテル® Advisor の解析によってオーバーヘッドが追加されている可能性があります。
利用可能な最上位の命令セット・アーキテクチャーを使用
インテル® Advisor の推奨に従って、アプリケーション全体のパフォーマンスを向上するため、マシンで利用可能な上位の ISA を使用します。
- インテル® AVX-512 を使用するためビルドコマンドに -xCORE-AVX512 -qopt-zmm-usage=high を追加して heart_demo をリビルドします。
mpiicpc ../heart_demo.cpp ../luo_rudy_1991.cpp ../rcm.cpp ../mesh.cpp -g -o heart_demo -O3 -xCORE-AVX512 -qopt-zmm-usage=high -std=c++11 -qopenmp -parallel-source-info=2
このオプションの詳細は、『インテル® C++ コンパイラー・デベロッパー・ガイドおよびリファレンス』の「qopt-zmm-usage、Qopt-zmm-usage」 (英語) を参照してください。
- サーベイ、トリップカウント、および FLOP 解析を再度実行して、[Summary (サマリー)] で結果を確認します。

最適化後、heart_demo アプリケーションの実行時間は 21.2 秒になりました。
インテル® AVX-512 命令を使用することで、ベースラインと比較して自動ベクトル化ループ の経過時間が若干軽減されました。例えば、[Survey & Roofline (サーベイ & ルーフライン)] タブでは、heart_demo.cpp:278 のループがベースラインの 1.310 秒から 0.260 秒にスピードアップしていることが分かります。
デフォルトの ISA を使用したループのセルフ時間:
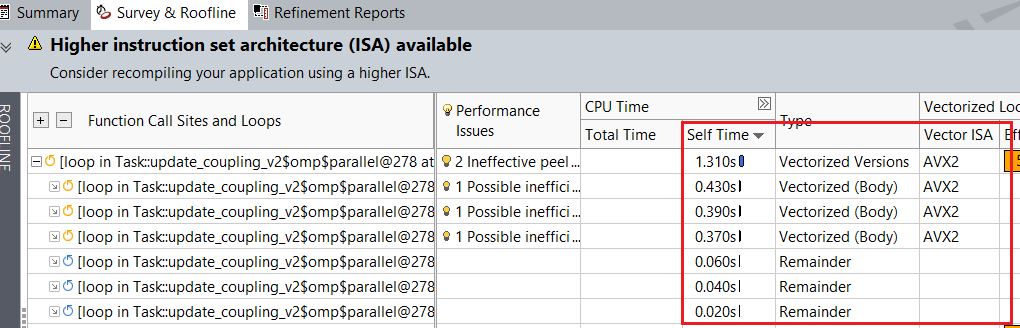
インテル® AVX-512 を使用したループのセルフ時間:

ベクトル化されなかったループをベクトル化する方法についてインテル® Advisor の推奨事項を確認するには、[Survey & Roofline (サーベイ & ルーフライン)] 以下の [Why No Vectorization (ベクトル化されなかった理由)] タブに移動します。heart_demo.cpp:332 のスカラーループに対して、インテル® Advisor は外部ループのベクトル化を強制することを推奨しています。
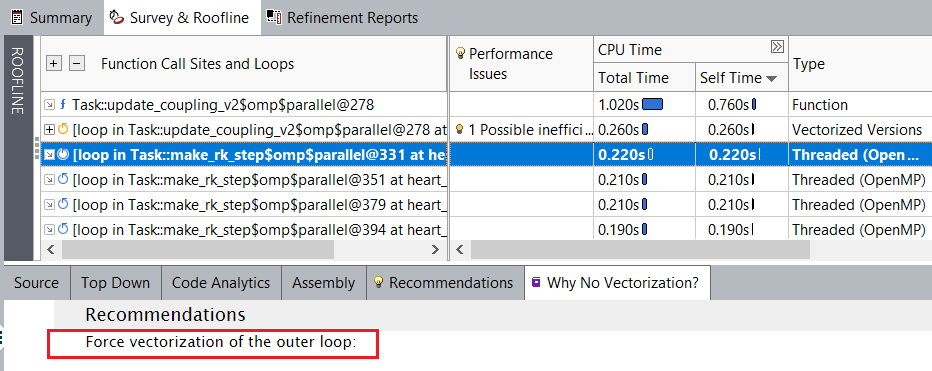
外部ループのベクトル化
インテル® Advisor の推奨に従って、heart_demo.cpp の行番号 332、352、366、および 380 の外部ループのベクトル化を強制します。
- 外部ループのベクトル化を強制する前に、依存関係解析を実行して、ループを安全にベクトル化できることを確認します。
- heart_demo.cpp の行番号 332、352、366、および 380 のループをマークアップします。
- 選択したループの依存関係解析 (英語) を実行します。
- 次のレポートタブで結果を確認します。
- [Refinement Reports (リファインメント・レポート)] では、インテル® Advisor が外部ループで依存関係を検出していないため、安全にベクトル化できることが分かります。
- [Survey & Roofline (サーベイ & ルーフライン)] レポートタブでは、トリップカウント・カラムに heart_demo.cpp の行番号 332、352、366、および 380 の外部ループのトリップカウント数が表示されます。内部ループは完全にアンロールされており、トリップカウントは 8 回のみです。
- 外部ループはトリップカウント数が高く、インテル® Advisor が依存関係を検出しなかったため、次に示すように #pragma omp parallel for simd 節を安全に追加できます。
#pragma omp parallel for simd for (int i=0; i<N; i++) { for (int j=0; j<DynamicalSystem::SYS_SIZE; j++) cnodes[i].cell.Y[j] = cnodes[i].state[j] + cnodes[i].rk4[0][j]/2.0; cnodes[i].cell.compute(time,cnodes[i].rk4[1]); for (int j=0; j<DynamicalSystem::SYS_SIZE; j++) cnodes[i].rk4[1][j] *= dt; } - アプリケーションをリビルドして、サーベイ、トリップカウント、および FLOP 解析を再度実行して、[Survey & Roofline (サーベイと & ルーフライン)] レポートで結果を確認します。
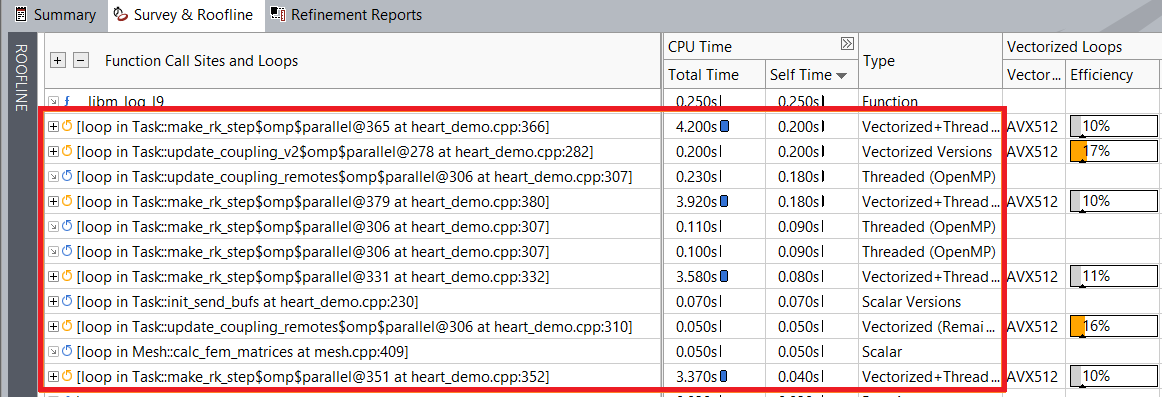
レポートから、外部ループのベクトル化により実行時間が向上したことが分かります。例えば、heart_demo.cpp:332 のループは最適化前の 4.2 秒から 3.58 秒にスピードアップしています。
外部ループをベクトル化する前のループの実行時間:
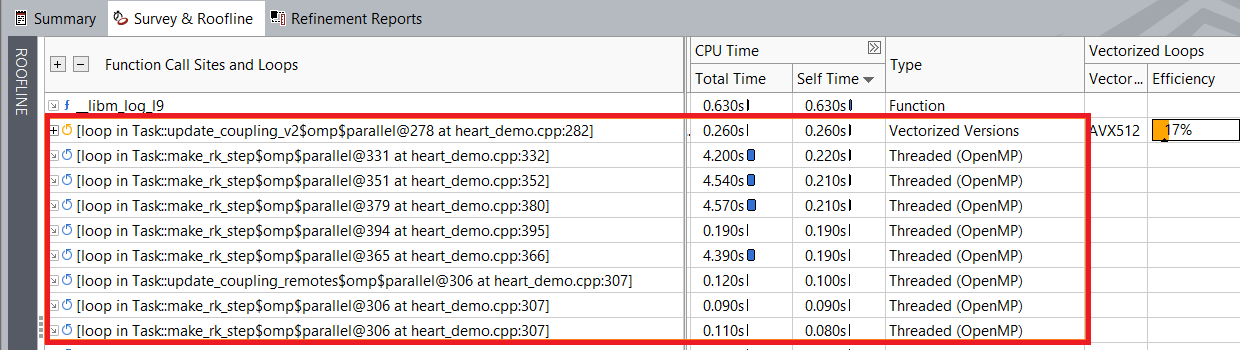
外部ループをベクトル化した後のループの実行時間:
最適化後、heart_demo アプリケーションの実行時間は 18.5 秒になりました。
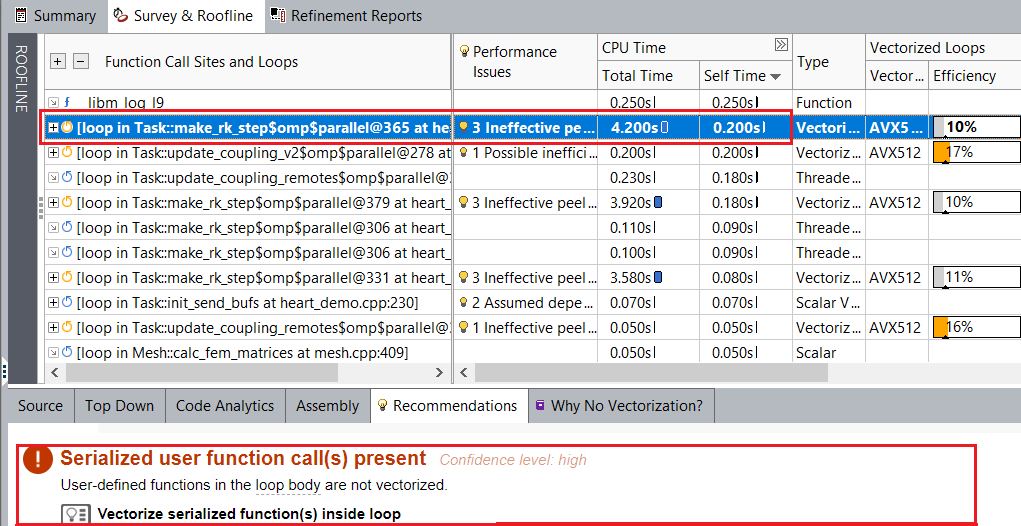
しかし、ベクトル化された外部ループの効率が低いままです。[Survey & Roofline (サーベイ & ルーフライン)] でベクトル化された外部ループを選択して、推奨事項を確認します。例えば、heart_demo.cpp:366 のループには 「Serialized user function call(s) present (シリアル化されたユーザー関数の呼び出しがあります)」というパフォーマンスの問題があり、この問題を解決するためインテル® Advisor は「vectorizing serialized functions inside loop (ループ内のシリアル化された関数をベクトル化する)」ことを提案しています。heart_demo.cpp:332、352、および 380 のほかのベクトル化された外部ループにも同じパフォーマンスの問題があります。
SIMD 関数を使用
インテル® Advisor は heard_demo:366 のループでシリアル化されたユーザー関数呼び出しを検出し、これをベクトル化することを推奨しています。
- luo_rudy_1991.hpp の compute 関数に #pragma omp declare simd を追加します。
#pragma omp declare simd void compute (double time, double *out);
DECLARE SIMD (英語) 構文は、指定したサブルーチンまたは関数の SIMD バージョンの作成を有効にします。SIMD バージョンは、SIMD ループ内の 1 つの呼び出しから複数の引数を処理するのに使用できます。
- アプリケーションをリビルドして、サーベイ、トリップカウント、および FLOP 解析を再度実行して、[Survey & Roofline (サーベイと & ルーフライン)] レポートで結果を確認します。
最適化後、heart_demo アプリケーションの実行時間は 16.4 秒になりました。
SIMD 使用を最適化
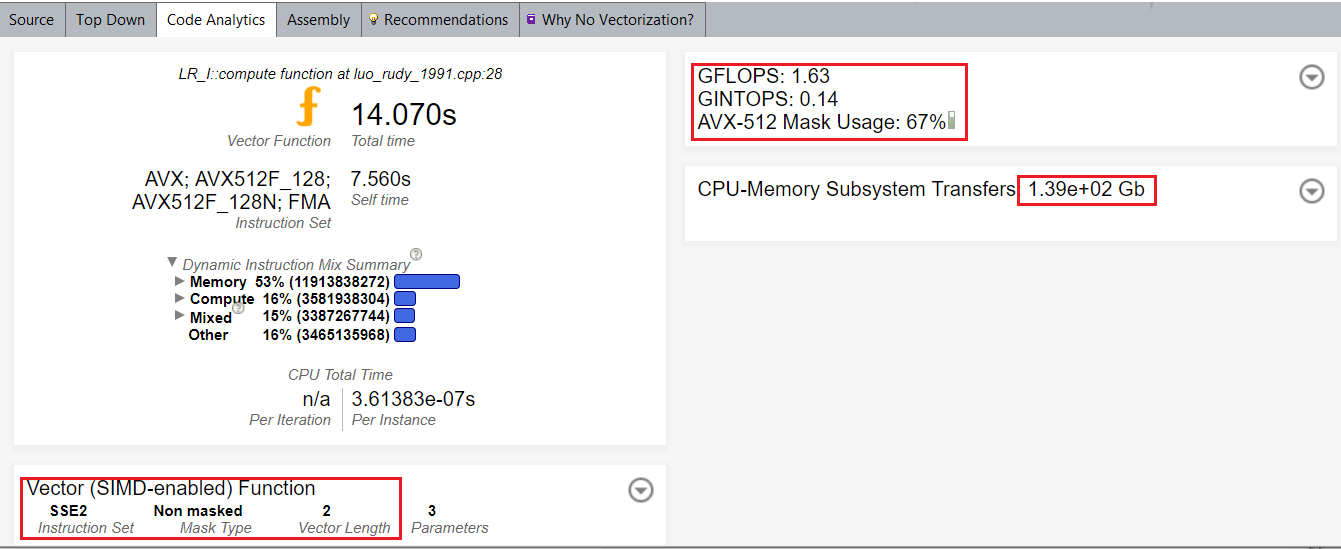
関数呼び出しをベクトル化した後、[Code Analytics (コード解析)] から、ベクトル長 8 とインテル® AVX-512 命令セットを使用する代わりに、ベクトル長 2 とインテル® ストリーミング SIMD 拡張命令 2 (インテル® SSE2) が使用されたこと分かります。
デフォルトでは、コンパイラーはインテル® SSE 命令セットを使用します。SIMD パフォーマンスを向上するには、vecabi=cmdtarget コンパイラー・オプションを使用するか、ベクトル関数の宣言で processor 節を指定します。
コンパイラー・オプションを使用して SIMD パフォーマンスを向上するには、次の操作を行います。
- ビルドコマンドに -vecabi=cmdtarget オプションを追加して、heart_demo をリビルドしてベクトル化された関数のインテル® AVX-512 バリアントを生成します。
mpiicpc ../heart_demo.cpp ../luo_rudy_1991.cpp ../rcm.cpp ../mesh.cpp -g -o heart_demo -O3 -xCORE-AVX512 -qopt-zmm-usage=high -vecabi=cmdtarget -std=c++11 -qopenmp -parallel-source-info=2
- サーベイ、トリップカウント、および FLOP 解析を再度実行して、[Survey & Roofline (サーベイ & ルーフライン)] > [Code Analytics (コード解析)] に移動して結果を確認します。
この変更により、ベクトル長 8 とインテル® AVX-512 命令セットが使用されるようになります。
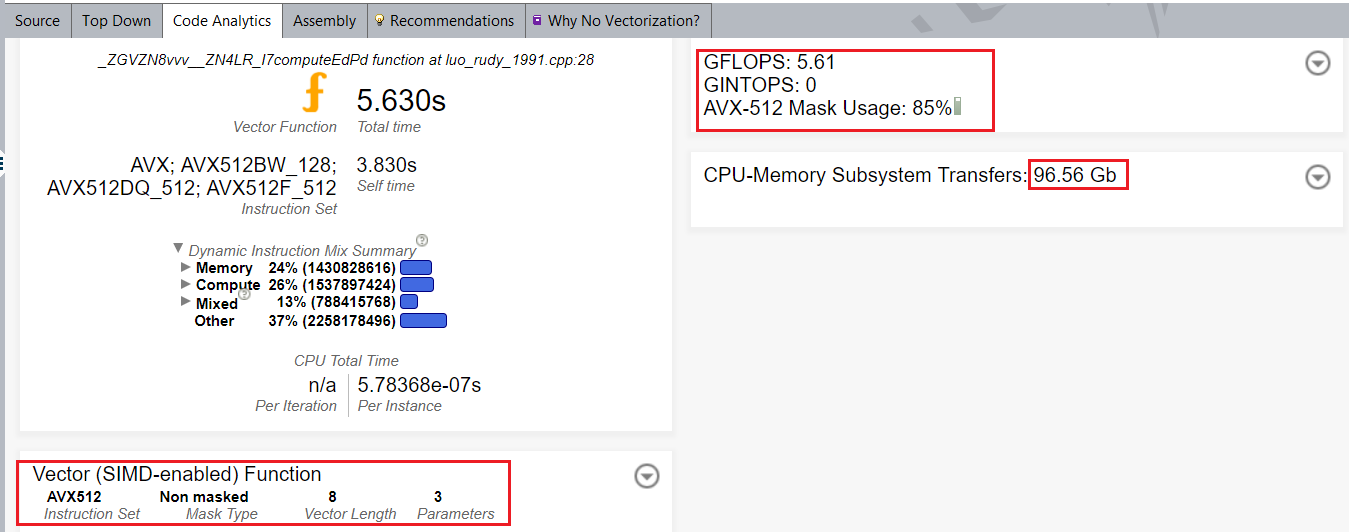
最適化後、heart_demo アプリケーションの実行時間は 9.2 秒になりました。
アンロールを無効化
heart_demo.cpp:310 のベクトル化された内部ループでは、インテル® Advisor はベクトル化されたリマインダー・ループを検出し、「disable unrolling (アンロールを無効にする)」ことを推奨しています。
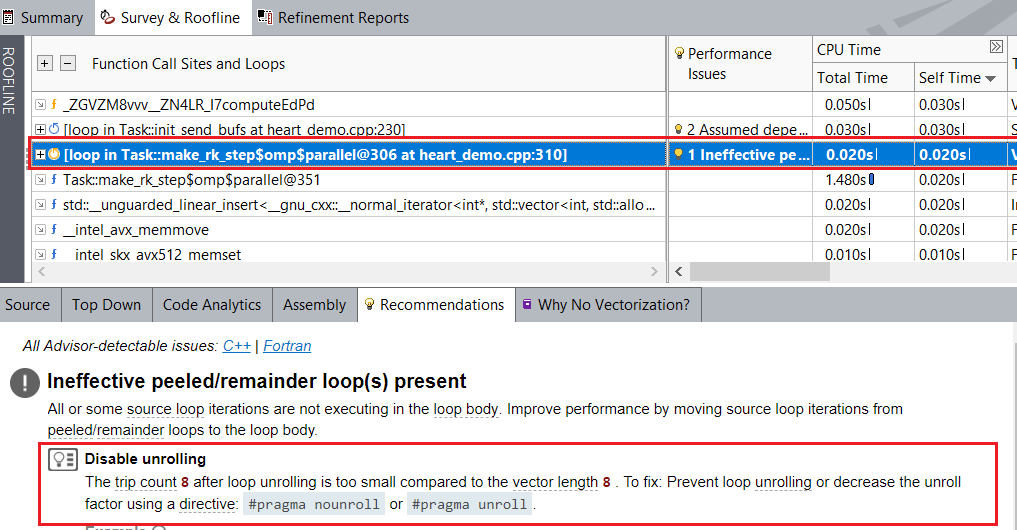
アンロールを無効にするには、次の操作を行います。
- リマインダー・ループとしてベクトル化される heart_demo.cpp:310 の内部ループの前に #pragma nounroll を追加します。
このプラグマにより、ループはベクトル化された本体として実行され、ベクトル化のリマインダーでは 36% であった FPU 利用率が 100% に向上しています。
- アプリケーションをリビルドして、サーベイ、トリップカウント、および FLOP 解析を再度実行して、[Survey & Roofline (サーベイ & ルーフライン)] > [Code Analytics (コード解析)] レポートで結果を確認します。
最適化後、heart_demo アプリケーションの実行時間は 8.9 秒になりました。
パフォーマンスの要約
上記の最適化手法により、シングルノード上でベースラインと比較して最終的に 2.55 倍のスピードアップを実現しました。また、適用された最適化により、アプリケーションのパフォーマンスも向上しました。
| ノード数 / RanksM 数 | ベースライン時間 | 最適化された時間 | スピードアップ |
|---|---|---|---|
| 1/48 | 22.7 秒 | 8.9 秒 | 2.55x |
| 2/96 | 11.5 秒 | 5.15 秒 | 2.23 倍 |
| 4/192 | 6.6 秒 | 3.5 秒 | 1.88 倍 |
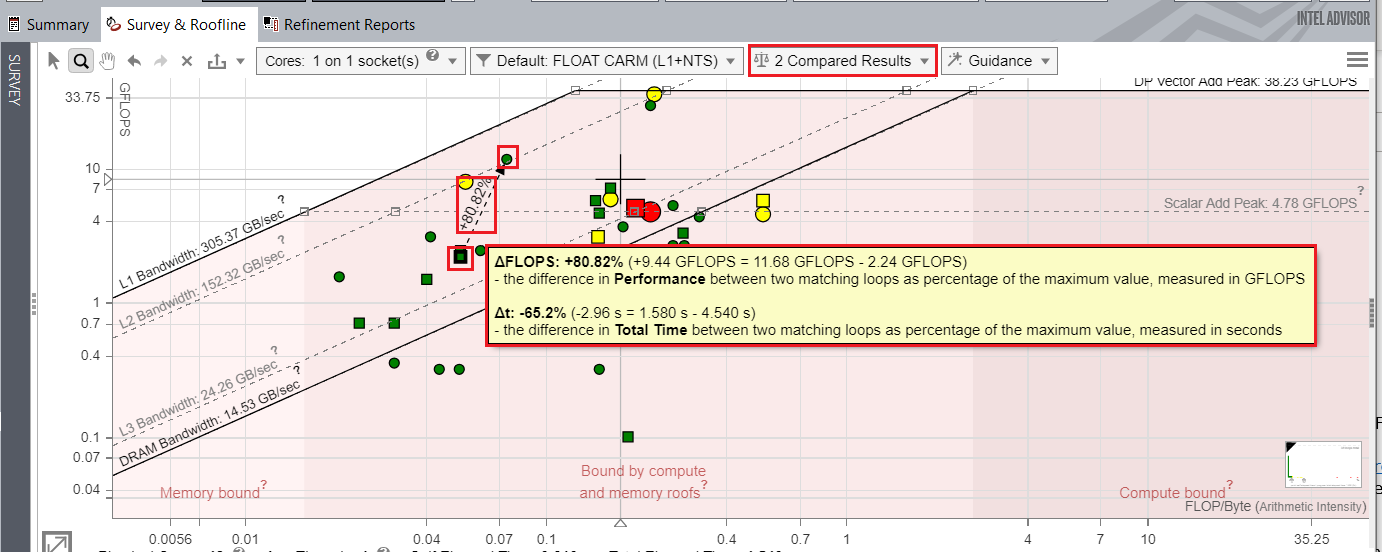
ルーフライン比較 (英語) 機能を使用してベースラインと最適化された結果を比較し、ループ間のパフォーマンスの向上を視覚化できます。
以下は、最適化の前と後のアプリケーションのパフォーマンスを比較したルーフライン・グラフです。heart_demo.cpp:352 のループの最適化の前と後のパフォーマンスの違いを示しており、FLOPS のパフォーマンスが 80.82% 向上していることが分かります。
次のステップ
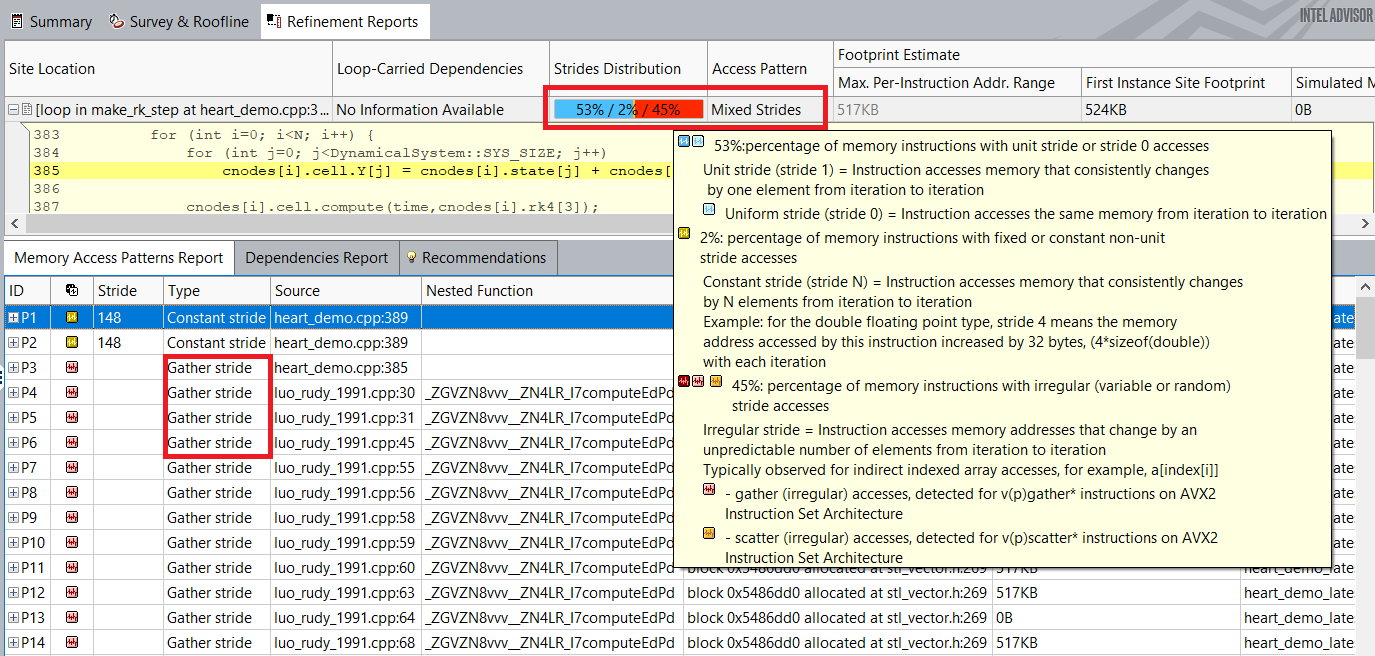
上記のルーフライン・グラフから分かるように、ベクトル化されたループはスカラー加算やベクトル加算のピークルーフにはまだ遠くおよびません。インテル® Advisor は、メモリー・アクセス・パターン (MAP) 解析 (英語) を実行して、ベクトル効率を低下させる可能性があるループ内の非効率なメモリーアクセスを特定することを推奨しています。
MAP 解析は、これらのループでは非ユニット・ストライド・アクセスがほぼ 50% に達していることを示しています。ループ内のランダムなストライドアクセスを変更することは、ループのベクトル化効率を向上させる次のステップとなります。
要約
アプリケーションのループ/関数を効率良くベクトル化できるように、インテル® Advisor は次のものを提供します。
- パフォーマンスを向上する推奨事項
- アプリケーションの実際のパフォーマンスとハードウェアによって課されるパフォーマンスの上限を示すルーフライン・グラフ
- ループ内のデータ依存関係やメモリーアクセスに関する詳しい情報を提供する、依存関係やメモリー・アクセス・パターンなどの詳細な解析
このレシピでは、インテル® Advisor の推奨事項に従って、リアルタイムの 3D 心臓電気生理学シミュレーションを行う heart_demo アプリケーションのパフォーマンスを、ベースラインと比較して 2.55 倍向上しました。
関連情報
製品とパフォーマンス情報
1実際の性能は利用法、構成、その他の要因によって異なります。詳細については、www.Intel.com/PerformanceIndex (英語) を参照してください。
