
この記事は、インテル® AI Blog に掲載されている「Vector Neural Network Instructions Enable INT8 AI Inference on Intel Architecture」(https://www.intel.ai/vnni-enables-inference/) の日本語参考訳です。
医療画像解析、自然言語処理、科学分野の最も挑戦的な問題を調査。
世界中の組織で AI コンピューティングにインテル® アーキテクチャーが採用されています。Ai 推論アクセラレーションを搭載した唯一のマイクロプロセッサーである、第 2 世代インテル® Xeon® スケーラブル・プロセッサーは、解析、ハイパフォーマンス・コンピューティング、および AI 機能を必要とするビジネス・クリティカルなデータベースなどのワークロードに適しています。これらのワークロードに対応するインテル® アーキテクチャーの利点は、開発者には良く理解されており、インフラストラクチャーですぐに利用できるため、既存の IT 投資で AI 推論を実行することで time to value までの時間を短縮できます。
インテル® Deep Learning Boost (インテル® DL Boost) により、第 2 世代インテル® Xeon® スケーラブル・プロセッサーは、これまで以上に優れた AI プラットフォームを提供し、第 1 世代インテル® Xeon® スケーラブル・プロセッサーと比較して推論アプリケーションのスループットを最大 14 倍[1] 向上させます。2019 年 4 月にニューヨークで開催された AI カンファレンスのセッション (英語) で、インテル® DL Boost のベクトル・ニューラル・ネットワーク命令 (VNNI) と、従来の 3 つの命令を 1 つに統合することでキャッシュ効率を改善し、潜在的な帯域幅のボトルネックを回避して AI パフォーマンスを向上させる方法を説明しました。インテル® アドバンスト・ベクトル・エクステンション 512 (インテル® AVX-512) をベースとする VNNI は、推論を加速するだけでなく、重要な見識をもたらす可能性があります。VNNI について詳しく知りたい方は、ニューヨークで開催された AI カンファレンスのセッション (英語) の資料をご覧ください。
ベクトル・ニューラル・ネットワーク命令の仕組み
VNNI は、第 2 世代インテル® Xeon® スケーラブル・プロセッサーに AI 推論の高速化をもたらすと考えることができます。次に示すように、VNNI の利点は、第 1 世代インテル® Xeon® スケーラブル・プロセッサーで使用される同様の命令と比較することで理解できます。
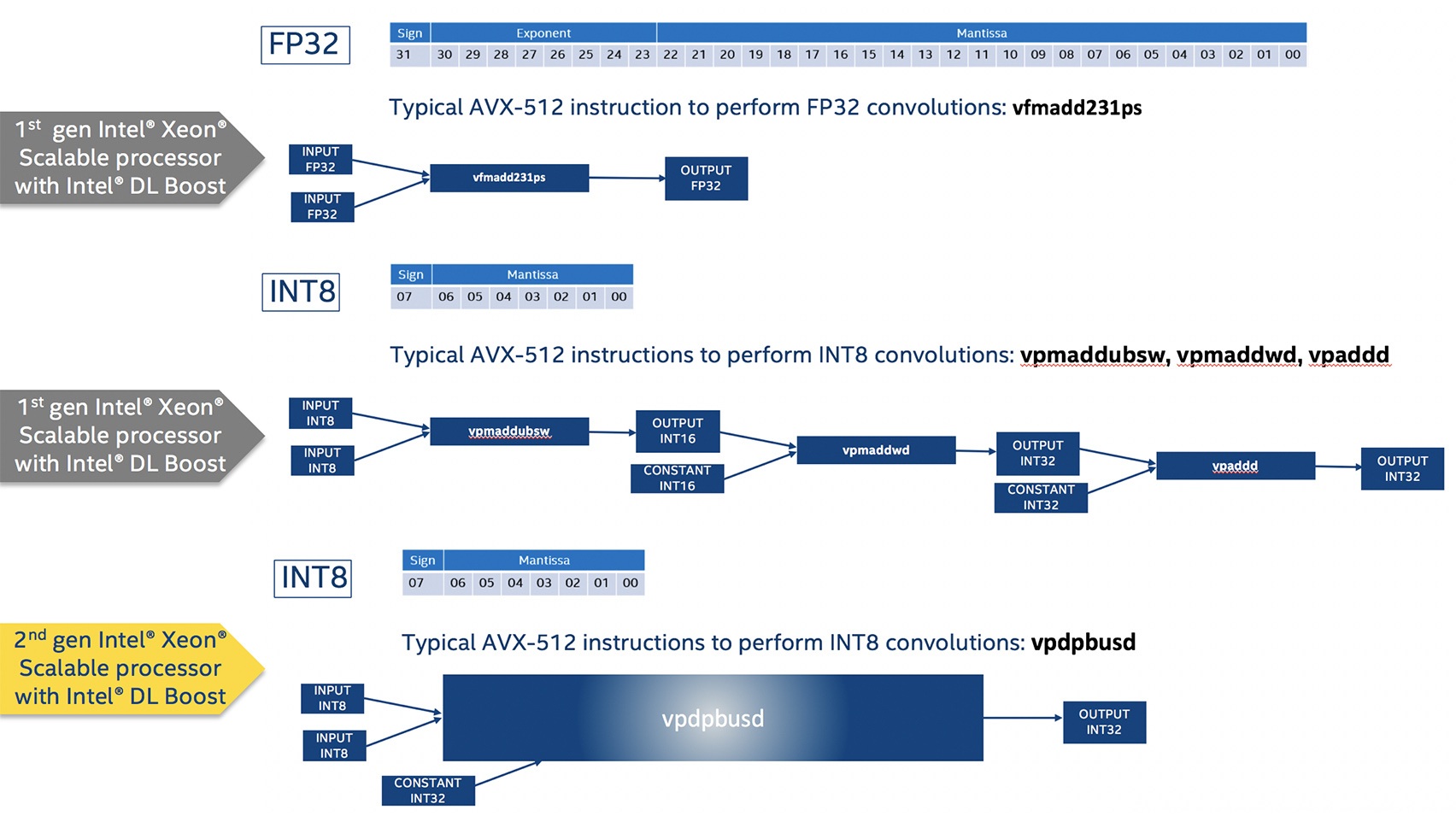
今日、大部分の商用ディープラーニング・アプリケーションは、訓練と推論ワークロードに 32 ビット精度の浮動小数点を利用しています。第 1 世代インテル® Xeon® スケーラブル・プロセッサーでは、ニューラル・ネットワークでよく使用される畳み込み演算は、インテル® AVX-512 命令セットの vfmadd231ps 命令で生成した FP32 データ型を使用して、ディープ・ニューラル・ネットワーク向けインテル® マス・カーネル・ライブラリー (インテル® MKL-DNN) (英語) で実装されていました。インテル® Xeon® スケーラブル・プロセッサーは、インテル® AVX-512 を搭載した最初のインテル® Xeon® CPU であり、1 コアあたり最大 2 つの 512 ビット FMA ユニットが並列計算により、1 サイクルで 2 つの vfmadd231ps 命令を実行できます。
最近では、演算の数値精度を低くすることで、結果の精度をほとんど低下させることなく、パフォーマンス向上をもたらす INT8 がディープラーニングの推論に使用されています。INT8 では 8 ビットを使用して 7 ビットの仮数と符号ビットで整数データを表し、FP32 は 32 ビットを使用して 22 ビットの仮数、8 ビットの指数、および 符号ビットで浮動小数点データを表現します。推論に INT8 を使用することで、転送するデータ量が減少し、データがより効率良く処理されるため、メモリー効率と計算効率が向上します。第 1 世代インテル® Xeon® スケーラブル・プロセッサーでは、インテル® AVX-512 の vpmaddubsw、vpmaddwd、および vpaddd 命令を使用して、インテル® MKL-DNN で畳み込み演算を実装し、低精度データの利点を活用します。これにより、畳み込み演算に FP32 データ型を使用する場合と比較してパフォーマンスは向上しますが、INT8 畳み込み演算は 3 命令を使用し、マイクロアーキテクチャーは 1 クロックサイクルに 512 ビット演算を 2 つしか実行できないという制限があるため、まだ改善の余地があります。
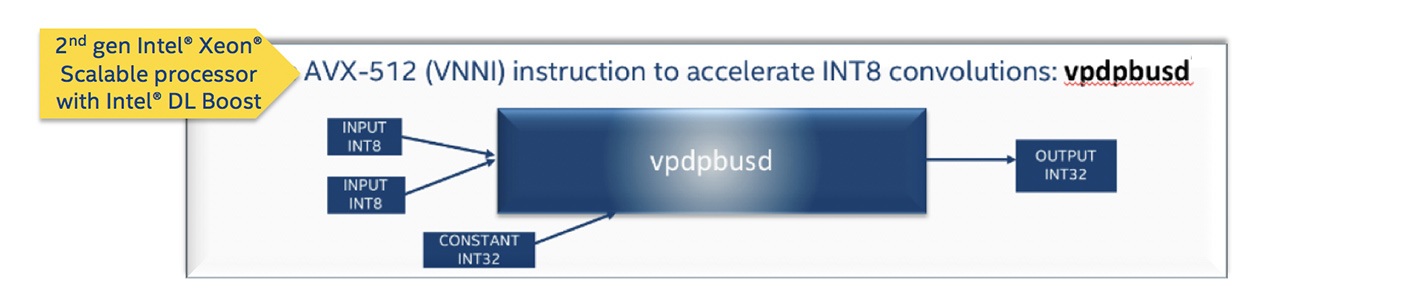
VNNI をサポートする第 2 世代インテル® Xeon® スケーラブル・プロセッサーでは、インテル® MKL-DNN の畳み込み演算は、個別の vpdpbusd インテル® AVX-512 命令により INT8 精度で実行されます。低精度の演算に単一の命令を使用できるため、これらの命令のうち 2 つを 1 クロックサイクルで実行できます。低精度と単一の命令は、ニューラル・ネットワークの畳み込み演算でマイクロアーキテクチャーの利用を最適化し、大幅なパフォーマンスの向上をもたらします。
ニューラル・ネットワークの推論は、順方向伝搬を行うため訓練されたモデルからの重みを必要とします。この重みは、訓練中に FP32 精度で格納されることがあります。FP32 のような浮動小数点データ型は、精度を保ち、訓練中の収束を確実に行うのに役立ちます。低精度の推論を行うため、訓練済みモデルからの FP32 型の重みは、量子化と呼ばれるプロセスを介して INT8 型に変換されます。浮動小数点データ型から整数データ型への変換では、精度がわずかに低下する可能性があります。精度を損なうことなく、INT8 データ型を推論で活用し利点を得るにはどうしたらよいでしょうか?
訓練の後、適切な量子化係数を見つけるため活性化に関する統計を収集します。この量子化係数を使用して、8 ビットの推論に対して訓練後に量子化を行います。さらに、訓練中にネットワーク内で「偽の」量子化を適用する量子化対応訓練と呼ばれる手法により、取得された FP32 の重みは、重みの更新後それぞれの反復で INT8 に量子化されます。この量子化対応訓練手法は、場合によってはわずかに高い精度をもたらします。
OpenVino™ ツールキット、またはインテル® Optimizations for TensorFlow* やインテル® Optimizations for Pytorch* など、インテルにより最適化されたフレームワークを利用した量子化手法により、第 2 世代インテル® Xeon® スケーラブル・プロセッサーで VNNI のパフォーマンスの利点を実現できます。
ベクトル・ニューラル・ネットワーク命令の利点
VNNI は、多くの企業/組織でほかの多くのタスクに使用され、信頼されているプロセッサーで低精度の推論を可能にします。そのため、多機能で多目的な第 2 世代インテル® Xeon® スケーラブル・プロセッサーでは、AI 機能を他のワークロードとともに簡単に統合できます。さらに、ベクトル・ニューラル・ネットワーク命令は、AI 推論における畳み込み演算の数と複雑さを軽減し、これらの演算に必要な処理能力とメモリーアクセスも軽減されるため、バッチ推論とリアルタイム推論の両方でパフォーマンスが大幅に向上する可能性があります。
O’Reilly AI NYC について
VNNI、インテル® DL Boost、およびインテルの AI 向けの広範囲に渡るエッジ・ツー・クラウド技術のポートフォリオの詳細は、2019 年 4 月に開催された O’Reilly AI NYC のインテルのセッション「インテル® Deep Learning Boost の理解と統合」 (英語) の資料をご覧ください。また、intel.ai ウェブサイトに注目し、Twitter* の @IntelAI をフォローしてください。
謝辞: Akhilesh Kumar、Nagib Hakim、Vikram Saletore、Andres Rodriguez、Evarist Fomenko、Indu Kalyanaraman、Ramesh AG、Emily Hutson
[1] インテル® DL Boost とインテル® Xeon® Platinum 8280 プロセッサーにより推論スループットが 14 倍向上しました。詳細は、https://www.intel.ai/2ndgenxeonscalable/ を参照してください。
法務上の注意書きと最適化に関する注意事項
性能に関するテストに使用されるソフトウェアとワークロードは、性能がインテル® マイクロプロセッサー用に最適化されていることがあります。SYSmark* や MobileMark* などの性能テストは、特定のコンピューター・システム、コンポーネント、ソフトウェア、操作、機能に基づいて行ったものです。結果はこれらの要因によって異なります。製品の購入を検討される場合は、他の製品と組み合わせた場合の本製品の性能など、ほかの情報や性能テストも参考にして、パフォーマンスを総合的に評価することをお勧めします。詳細については、www.intel.com/benchmarks (英語) を参照してください。
性能の測定結果は 2017 年 7 月 11 日から 2019 年 4 月 1 日時点のテストに基づいています。また、現在公開中のすべてのセキュリティー・アップデートが適用されているとは限りません。詳細については、公開されている構成情報を参照してください。絶対的なセキュリティーを提供できる製品またはコンポーネントはありません。結果はインテル社内での分析またはアーキテクチャーのシミュレーションあるいはモデリングに基づくものであり、情報提供のみを目的としています。システム・ハードウェア、ソフトウェア、構成などの違いにより、実際の性能は掲載された性能テストや評価とは異なる場合があります。
インテル® コンパイラーでは、インテル® マイクロプロセッサーに限定されない最適化に関して、他社製マイクロプロセッサー用に同等の最適化を行えないことがあります。これには、インテル® ストリーミング SIMD 拡張命令 2、インテル® ストリーミング SIMD 拡張命令 3、インテル® ストリーミング SIMD 拡張命令 3 補足命令などの最適化が該当します。インテルは、他社製マイクロプロセッサーに関して、いかなる最適化の利用、機能、または効果も保証いたしません。
本製品のマイクロプロセッサー依存の最適化は、インテル® マイクロプロセッサーでの使用を前提としています。インテル® マイクロアーキテクチャーに限定されない最適化のなかにも、インテル® マイクロプロセッサー用のものがあります。この注意事項で言及した命令セットの詳細については、該当する製品のユーザー・リファレンス・ガイドを参照してください。
注意事項の改訂 #20110804
上記のベンチマーク結果は、追加のテストによって変更が必要になる可能性があります。結果は、テストに使用される特定のプラットフォーム構成や作業負荷に依存します。個々のユーザーのコンポーネント、コンピューター・システム、作業負荷では同様の結果が得られない可能性があります。結果は、必ずしもほかのベンチマークを代表するものではなく、ほかのベンチマークでは、結果が異なることがあります。
インテル® アドバンスト・ベクトル・エクステンション (インテル® AVX) は、特定のプロセッサー操作において高いスループットをもたらします。プロセッサーの電力特性が異なるため、インテル® AVX 命令を使用すると、a) 一部の部品が定格周波数以下で動作し、b) 一部の部品がインテル® ターボ・ブースト・テクノロジー 2.0 を使用しても、ターボ周波数が最大にならない場合があります。実際の性能はハードウェア、ソフトウェア、およびシステム構成によって異なります。詳細は、http://www.intel.com/go/turbo (英語) をご覧ください。
インテル® テクノロジーの機能と利点はシステム構成によって異なり、対応するハードウェアやソフトウェア、またはサービスの有効化が必要となる場合があります。実際の性能はシステム構成によって異なります。絶対的なセキュリティーを提供できるコンピューター・システムはありません。詳細については、各システムメーカーまたは販売店にお問い合わせいただくか、http://www.intel.co.jp/ を参照してください。
Intel、インテル、Intel ロゴ、Xeon、OpenVINO は、アメリカ合衆国および / またはその他の国における Intel Corporation またはその子会社の商標です。
* その他の社名、製品名などは、一般に各社の表示、商標または登録商標です。
