

この記事は、インテル® デベロッパー・ゾーンに公開されている「Single Node Caffe Scoring and Training on Intel® Xeon E5-Series Processors」(https://software.intel.com/en-us/articles/single-node-caffe-scoring-and-training-on-intel-xeon-e5-series-processors) の日本語参考訳です。
ディープ・ニューラル・ネットワーク (DNN) アプリケーションは、インターネット検索エンジンや医療画像など、さまざまな分野で急激に成長しています。Pradeep Dubey のブログで、インテル® アーキテクチャー上でのマシンラーニングのビジョンを解説しています。インテルは、Pradeep Dubey のブログ (https://blogs.intel.com/blog/pushing-machine-learning-to-a-new-level-with-intel-xeon-and-intel-xeon-phi-processors-2/) (英語) でマシンラーニングのビジョンの概要を説明し、将来のインテル® マス・カーネル・ライブラリー (インテル® MKL) とインテル® Data Analytics Acceleration Library (インテル® DAAL) で利用可能となるマシンラーニングのワークロードを加速するソフトウェア・ソリューションを開発しています。このテクニカルプレビューでは、インテル® プラットフォームと開発中のソフトウェアで達成可能なパフォーマンスを紹介します。現在のテクニカルプレビューは、インテル® アドバンスト・ベクトル・エクステンション 2 (インテル® AVX2) が有効なプロセッサー上でのみ動作します。次の記事では、分散型のマルチノードでの可能性を示します。
Caffe* は、Berkeley Vision and Learning Center (BVLC) によって開発されたディープ・ラーニング・フレームワークであり、画像認識向けの最も人気のあるコミュニティー・フレームワークです。また、Caffe* は、しばしば画像認識向けのニューラル・ネットワーク・トポロジーである AlexNet* (https://papers.nips.cc/paper/4824-imagenet-classification-with-deep-convolutional-neural-networks.pdf) や ImageNet* (http://www.image-net.org/) 画像のデータベースとともにベンチマークとして使用されます。
Caffe* は、インテル® MKL で提供される最適化された数学ルーチンを利用することができますが、コードのモダン化技術を適用することで、インテル® Xeon® プロセッサー・ベースのシステムでのパフォーマンスをさらに向上できる可能性があります。インテル® MKL を適切に利用することで、最適化されていない Caffe* の実装と比較して、ベクトル化と並列化により学習のパフォーマンスを 11 倍高め、分類のパフォーマンスを 10 倍高めることができます。
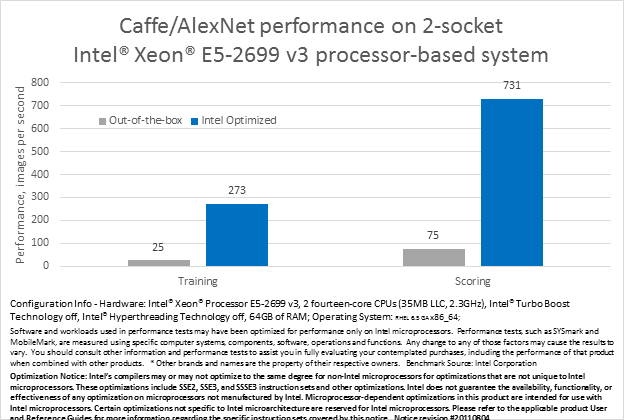
これらの最適化により、ILSVRC-2012 データセット上で上位 5 つの 80% の精度に AlexNet* をトレーニングする時間が、58 日から 5 日に減少できました。
はじめに
この記事に記載されている新しい機能を将来のインテル® MKL とインテル® DAAL に取り込むことに取り組んでいますが、開発者の皆さんはこの記事で証明したパフォーマンスを再現し、皆さん自身のデータセットで AlexNet* を学習させるため、この記事に添付されているテクニカル・プレビュー・パッケージを使用することができます。
パッケージは AlexNet* トポロジーをサポートしており、2 つの新しい ‘IntelPack’ と ‘IntelUnpack’ レイヤーを加えた ‘bvlc_alexnet’ に類似し、最適化されたコンボリューション、プーリング、正規化レイヤーの実装を含む ‘intel_alexnet’ モデルを導入しています。私たちはまた、ミニバッチの評価サイズを 50 から 256 に増やし、テスト反復を 1000 から 200 に減らすことで、ベクトル化を容易にするため検証パラメーターを変更することで、検証の実行に使用される画像数を一定に保つことができました。パッケージは、次のファイル内に ‘intel_alexnet’ モデルを含んでいます。
- models/intel_alexnet/deploy.prototxt
- models/intel_alexnet/solver.prototxt
- models/intel_alexnet/train_val.prototxt
‘Intel_alexnet’ モデルは、ILSVRC-2012 トレーニング・セットを学習およびテストすることが可能です。
パッケージを利用するには、システム要件と制限に記載されているすべての Caffe* が依存するパッケージが、システムにインストールされていることを確認してください。
- パッケージを展開します。
- 次の ‘intel_alexnet’ モデルファイルのデータベース、スナップショットの場所、および画像 mean ファイルへのパスを指定します。
- models/intel_alexnet/deploy.prototxt
- models/intel_alexnet/solver.prototxt
- models/intel_alexnet/train_val.prototxt
- システム要件と制限で示すソフトウェア・ツール向けのランタイム環境を設定します。
- LD_LIBRARY_PATH 環境変数に、./build/lib/libcaffe.so へのパスを追加します。
- スレッド化の環境は次のように設定します。
$> export OMP_NUM_THREADS=<N_processors * N_cores>
$> export KMP_AFFINITY=compact,granularity=fine - 次のコマンドを使用してシングルノードで time 実行します。
$> ./build/tools/caffe time \
-iterations <number of iterations> \
–model=models/intel_alexnet/train_val.prototxt - 次のコマンドを使用してシングルノードで train 実行します。
$> ./build/tools/caffe train \
–solver=models/intel_alexnet/solver.prototxt
パッケージは、最適化されていない Caffe* と同様のソフトウェア依存性があります。
- boost* 1.53.0
- OpenCV* 2.4.9
- protobuf* 3.0.0-beta1
- glog* 0.3.4
- gflags* 2.1.2
- lmdb* 0.9.16
- leveldb* 1.18
- HDF5* 1.8.15
- Red Hat* Enterprise Linux* 6.5 以降
およびインテル® MKL 11.3 以降。
ハードウェアの互換性:
このソフトウェアは、AlexNet* トポロジーを使用してのみ評価されており、その他の構成では動作の保証はありません。
サポート
このパッケージ関する問い合わせは、mailto:intel.mkl@intel.com に直接お送りください。
| intel_optimized_technical_preview_for_multinode_caffe_1.1.tgz (3.4MB) https://software.intel.com/sites/default/files/managed/a5/cc/intel_optimized_technical_preview_for_multinode_caffe_1.1.tgz |
コンパイラーの最適化に関する詳細は、最適化に関する注意事項を参照してください。
