

この記事は、The Parallel Universe Magazine 53 号に掲載されている「Performance Optimization on Intel Processors with High-Bandwidth Memory」の日本語参考訳です。原文は更新される可能性があります。原文と翻訳文の内容が異なる場合は原文を優先してください。

量子色力学 (QCD) は、素粒子間の強い力の相互作用の理論/研究です。格子 QCD は、粒子と力を空間領域と時間領域で離散化した格子として表すことにより QCD 問題を解きます。HotQCD は、高エネルギー物理学の研究コミュニティーで広く使用されている C++ ハイブリッド MPI/OpenMP* 格子 QCD シミュレーション・フレームワークです。
この記事では、インテル® Xeon® CPU マックス・シリーズで最適なパフォーマンスを実現するために HotQCD に適用するパフォーマンス・チューニング手法を説明します。インテル® Xeon® CPU マックス・シリーズとほかのインテル® Xeon® プロセッサーとの主な違いは、高帯域幅メモリー (HBM) の有無です (図 1a)。簡単に言えば、HBM は DDR メモリー (シングルスタック DRAM) よりも高いメモリー帯域幅パフォーマンスを実現する 3D スタック DRAM インターフェイスです。インテル® Xeon® CPU マックス・シリーズは (CPU ソケットあたり) 最大 56 のコアと、ソケットあたり 8 個の高 DRAM ダイを 4 つスタックした HBM2e を搭載しています。スタックの各 DRAM ダイの容量は 2GB です (ソケットあたり 4 x 8 x 2 = 64GB HBM)。
パフォーマンス解析
HBM を搭載したインテルのプロセッサーには、メモリー (フラット、キャッシュ、HBM のみ) および NUMA (SNC1、SNC4) など、多くの構成モードがあります。各モードの詳細は本題から外れるためここでは詳しく取り上げません。詳細は、「インテル® Xeon® CPU マックス・シリーズ構成およびチューニング・ガイド」を参照してください。この記事で使用したシステムは、HBM のみメモリーモード (DDR5 なし) と SNC4 (サブ-NUMA クラスタ リング-4) で構成されています (図 1b)。
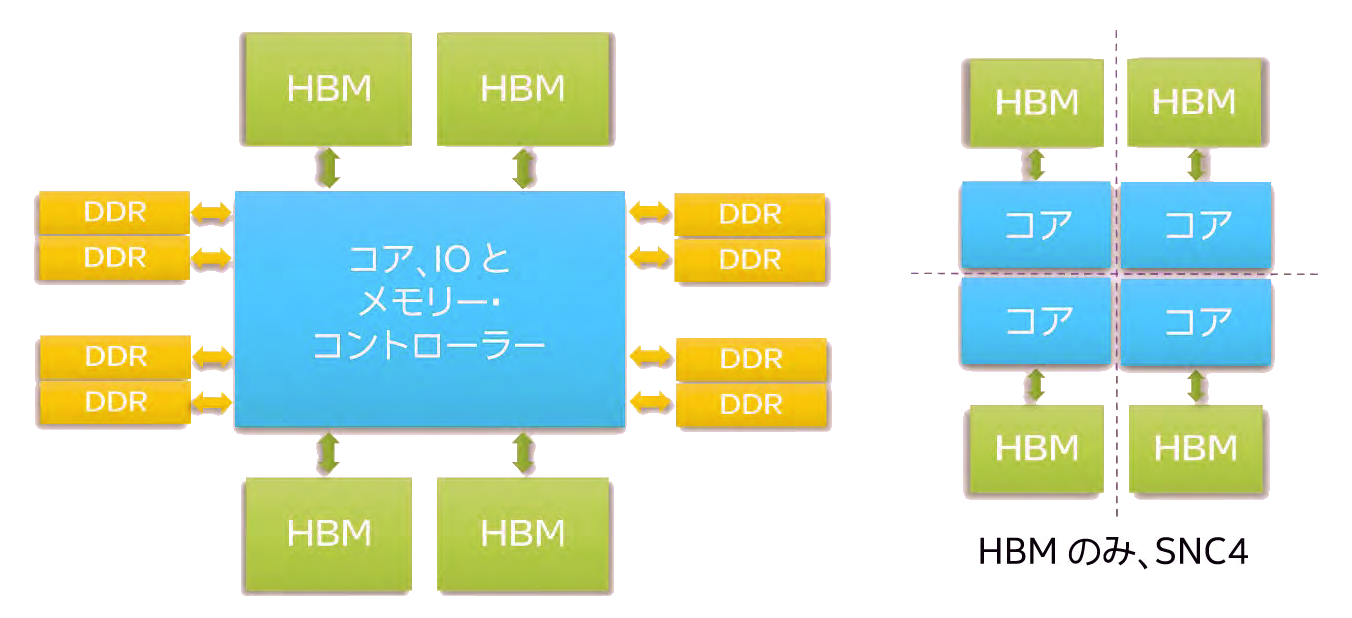
図 1. (a) インテル® Xeon® CPU マックス・シリーズ
(b) インテル® Xeon® CPU マックス・シリーズ (HBM のみ + SNC4 モード)
HotQCD のパフォーマンス・スナップショット [1 つの RHS (右辺) ベクトルを格子サイズ 324 (x=y=z=t=32) でベンチマーク] は、最も時間を費やしている関数 (dslash、合計実行時間の 90% を消費) がメモリー帯域幅依存である (プロセッサーがメモリー操作の待機時間の約 50% でストールしている) ことを示しています (図 2)。
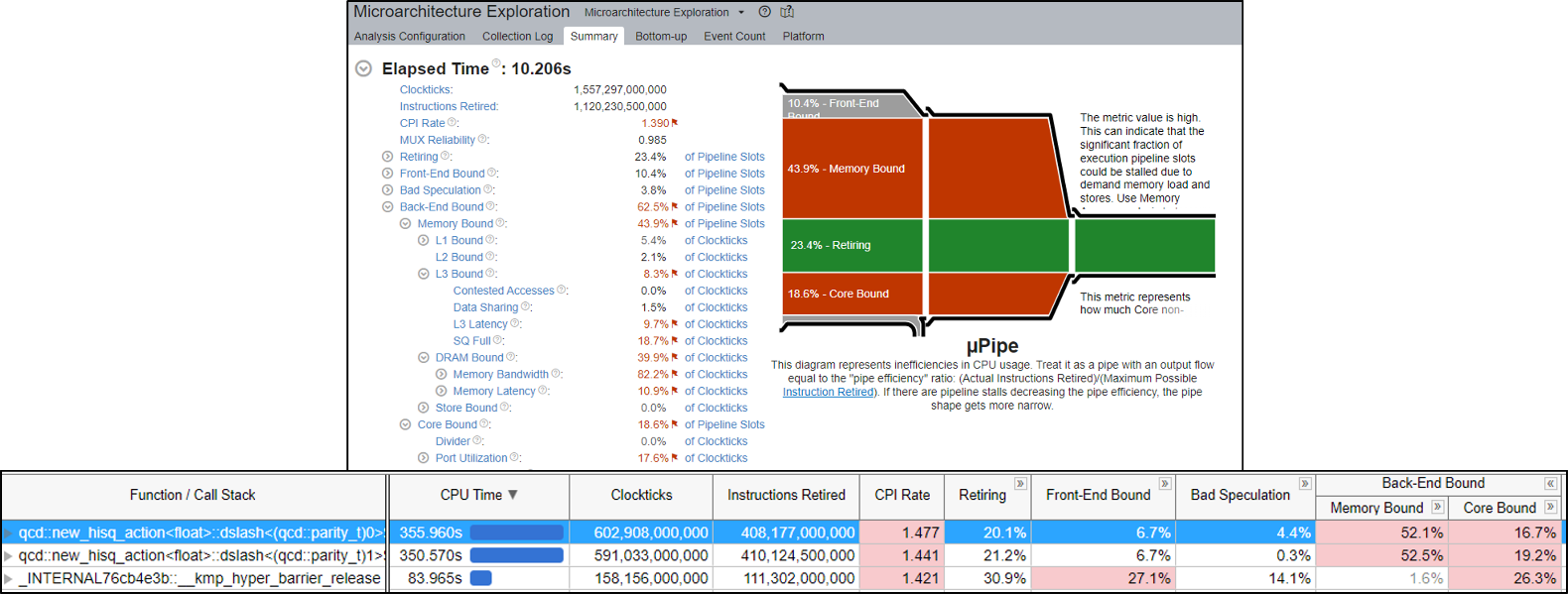
図 2. インテル® VTune™ プロファイラーのマイクロアーキテクチャー全般解析を使用したベースラインのパフォーマンス・スナップショット
dslash の OpenMP* 並列領域を図 3 に示します。格子の各点で、演算子のオーバーロードにより 4 つの密行列-ベクトル積のセットが実行されます。関数はインテル® AVX-512 組込み関数で完全にベクトル化されていて、スレッド間の同期は行われません。link_std には 2 つの行列-ベクトル積があり、行列とベクトルはそれぞれ 9 つと 3 つのキャッシュラインで構成され、合計で 4 x 2 x (9 + 3) = 96 のキャッシュラインが読み取られます。link_naik は link_std と似ていますが、行列が 7 つのキャッシュラインのみをロードして構成され、合計で 4 x 2 x (7 + 3) = 80 のキャッシュラインが読み取られる点が異なります。すべてのメモリーアクセスは、無視できる量のデータ再利用でキャッシュラインにアライメントされます。これは、この関数がメモリー帯域幅依存で (FLOP とバイトの比率が約 0.9)、大量の読み取りトラフィックが発生していることを明確に示しています [176 (96 + 80) のキャッシュラインがすべて読み取られ、3 つのキャッシュラインのみメモリーに書き込まれます]。つまり、プロセッサーが浮動小数点演算を実行するには、メモリーからデータを継続的に読み取る必要があります。
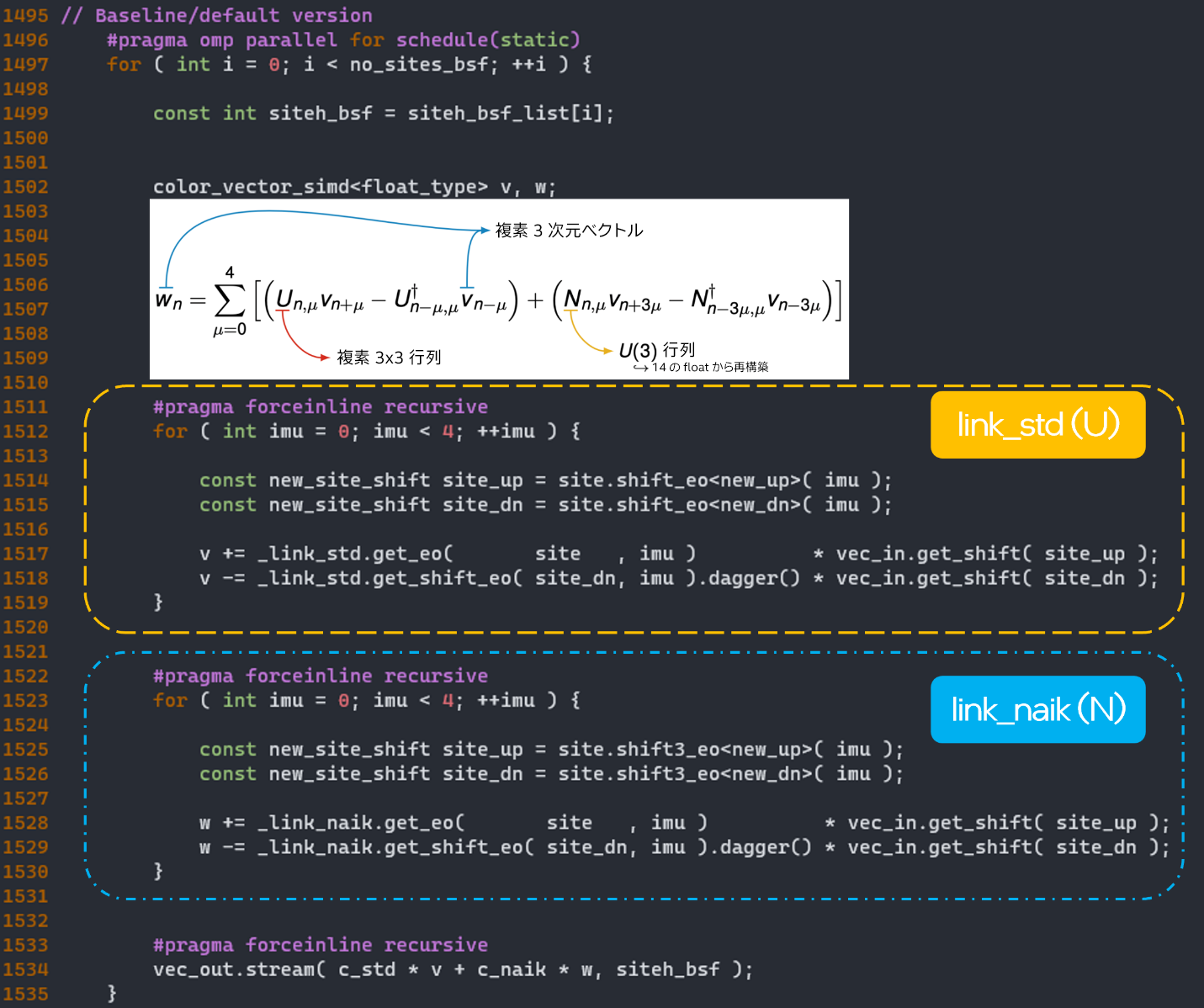
図 3. HotQCD dslash のコード
