

この記事は、インテル® デベロッパー・ゾーンに公開されている「Caffe* Training on Multi-node Distributed-memory Systems Based on Intel® Xeon® Processor E5 Family」(https://software.intel.com/en-us/articles/caffe-training-on-multi-node-distributed-memory-systems-based-on-intel-xeon-processor-e5) の日本語参考訳です。
ディープ・ニューラル・ネットワーク (DNN) 学習は計算集約型であり、問題の解決には現代の計算プラットフォーム上でも数日から数週間を要します。以前の記事、インテル® Xeon® プロセッサー E5 ファミリー上でのシングルノード Caffe* スコアと学習では、Caffe* フレームワークが AlexNet* トポロジー上で 10 倍の性能を向上し、シングルノード上で学習時間を 5 日間に短縮することを紹介しました。インテルでは、Pradeep Dubey のブログ (https://blogs.intel.com/blog/pushing-machine-learning-to-a-new-level-with-intel-xeon-and-intel-xeon-phi-processors-2 (英語)) で機械学習のビジョンを発信し続けており、このテクニカルプレビューではマルチノードの分散メモリー環境で Caffe* 向けの学習時間を数日から数時間に短縮する方法を紹介しています。
Caffe* は、Berkeley Vision and Learning Center (BVLC) によって開発されたディープ・ラーニング・フレームワークであり、画像認識向けの最も人気のあるコミュニティー・フレームワークです。また、Caffe* は、しばしば画像認識向けのニューラル・ネットワーク・トポロジーである AlexNet* や ImageNet* (http://www.image-net.org/ (英語)) 画像のデータベースとともにベンチマークとして使用されます。
Caffe* フレームワークは、デフォルトではマルチノード、分散メモリーシステムはサポートしておらず、分散メモリーシステム上で実行するには大規模な修正が必要となります。私たちは、インテル® MPI ライブラリーを利用して、同期ミニバッチ確率的勾配降下 (SGD) アルゴリズムの強力なスケーリングを達成します。1 反復あたりの計算は、マルチスレッド化された複数ノード並列実装が、シングルノード、シングルスレッドのシリアル実装と等価であるように、複数のノード間でスケールします。
私たちは、計算をスケールするため、データ並列、モデル並列、そしてハイブリッド並列の 3 つのアプローチを取ります。モデル並列は、重みの一部分が割り当てられた各ノードのように、ノードにモデルや重みを分割するために参照され、各ノードはミニバッチ内のすべてのデータポイントを処理します。これは、データ並列における重みと重み勾配の通信とは異なり、アクティベーションとアクティベーション勾配の通信が要求されます。
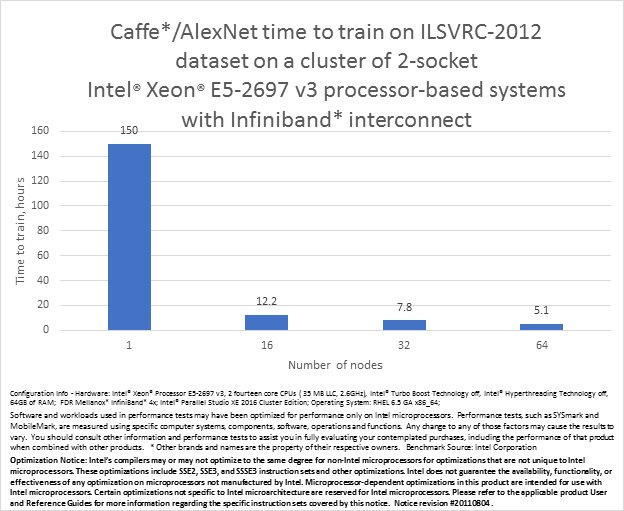
分散型の並列レベルを追加することで、ImageNet Large Scale Visual Recognition Challenge 2012 (ILSVRC-2012) の完全なデータセットをトレーニングし、インテル® Xeon® プロセッサー E5 ファミリー・ベースの 64 ノードのクラスターシステム上で、上位 5 つの精度 80% にわずか 5 時間で到達できました。
はじめに
この記事に記載されている新しい機能を将来のインテル® マス・カーネル・ライブラリー (インテル® MKL) とインテル® Data Analytics Acceleration Library (インテル® DAAL) に取り込むことに取り組んでいますが、開発者の皆さんはこの記事で証明したパフォーマンスを再現し、皆さん自身のデータセットで AlexNet* を学習させるため、この記事に添付されているテクニカル・プレビュー・パッケージを使用することができます。プレビューパッケージには、シングルノードとマルチノード実装の両方が含まれます。現在の実装では AlexNet* トポロジーのみがサポートされ、ほかの一般的に使用される DNN トポロジーでは動作しない可能性があることに留意してください。
パッケージは AlexNet* トポロジーをサポートしており、2 つの新しい ‘IntelPack’ と ‘IntelUnpack’ レイヤーを加えた ‘bvlc_alexnet’ に類似し、最適化されたコンボリューション、プーリング、正規化レイヤー、およびそれらすべてのレイヤー向けの MPI ベース実装を含む ‘intel_alexnet’ と ‘mpu_intel_alexnet’ モデルを導入しています。私たちはまた、ミニバッチの評価サイズを 50 から 256 に増やし、テスト反復を 1000 から 200 に減らすことで、ベクトル化を容易にするため検証パラメーターを変更することで、検証の実行に使用される画像数を一定に保つことができました。パッケージは、次のフォルダー内に ‘intel_alexnet’ モデルを含んでいます。
- models/intel_alexnet/deploy.prototxt
- models/intel_alexnet/solver.prototxt
- models/intel_alexnet/train_val.prototxt
- models/mpi_intel_alexnet/deploy.prototxt
- models/mpi_intel_alexnet/solver.prototxt
- models/mpi_intel_alexnet/train_val.prototxt
- models/mpi_intel_alexnet/train_val_shared_db.prototxt
- models/mpi_intel_alexnet/train_val_split_db.prototxt
‘Intel_alexnet’ と ‘mpi_intel_alexnet’ モデルは、両方とも ILSVRC-2012 トレーニング・セットを学習およびテストすることが可能です。
パッケージを利用するには、システム要件と制限に記載されているすべての Caffe* が依存するパッケージとインテル® ソフトウェア・ツールが、システムにインストールされていることを確認してください。
シングルノードで実行
- パッケージを展開します。
- 次の ‘intel_alexnet’ モデルファイルのデータベース、スナップショットの場所、および画像 mean ファイルへのパスをしています。
- models/intel_alexnet/deploy.prototxt
- models/intel_alexnet/solver.prototxt
- models/intel_alexnet/train_val.prototxt
- システム要件と制限で示すソフトウェア・ツール向けのランタイム環境を設定します。
- LD_LIBRARY_PATH 環境変数に、./build/lib/libcaffe.so へのパスを追加します。
- スレッド化の環境は次のように設定します。
$> export OMP_NUM_THREADS=<N_processors * N_cores>
$> export KMP_AFFINITY=compact,granularity=fine
注: OMP_NUM_THREADS には、2 以上の偶数値を設定する必要があります。 - 次のコマンドを使用してシングルノードで time 実行します。
$> ./build/tools/caffe time \
-iterations <number of iterations> \
–model=models/intel_alexnet/train_val.prototxt - 次のコマンドを使用してシングルノードで train 実行します。
$> ./build/tools/caffe train \
–solver=models/intel_alexnet/solver.prototxt
クラスター上で実行
- パッケージを展開します。
- システム要件と制限で示すソフトウェア・ツール向けのランタイム環境を設定します。
- LD_LIBRARY_PATH 環境変数に、./build-mpi/lib/libcaffe.so へのパスを追加します。
- 次のように、使用するノード数を NP 環境変数に設定します。
$> export NP=<number-of-mpi-ranks>
注: 最良のパフォーマンスはノードごとに 1 つの MPI ランクで達成されます。 - x${NP}.hosts の名称で、アプリケーションのルートディレクトリーにノードファイルを作成します。例えば、IBM* Platform LSF* では、次のコマンドを実行します。
$> cat $PBS_NODEFILE > x${NP}.hosts - 次の ‘mpi_intel_alexnet’ モデルファイルのデータベース、スナップショットの場所、および画像 mean ファイルへのパスをしています。
- models/mpi_intel_alexnet/deploy.prototxt
- models/mpi_intel_alexnet/solver.prototxt
- models/mpi_intel_alexnet/train_val_shared_db.prototxt
- 1. スレッド化の環境は次のように設定します。
$> export OMP_NUM_THREADS=<N_processors * N_cores>
$> export KMP_AFFINITY=compact,granularity=fine
注: OMP_NUM_THREADS には、2 以上の偶数値を設定する必要があります。 - 1. 次のコマンドを使用して、time 実行します。
$> mpirun -nodefile x${NP}.hosts -n $NP -ppn 1 -prepend-rank \
./build/tools/caffe time \
-iterations <number of iterations> \
–model=models/mpi_intel_alexnet/train_val.prototxt - 次のコマンドを使用して、train 実行します。
$> mpirun -nodefile x${NP}.hosts -n $NP -ppn 1 -prepend-rank \
./build-mpi/tools/caffe train \
–solver=models/mpi_intel_alexnet/solver.prototxt
システム要件と制限
パッケージは、最適化されていない Caffe* と同様のソフトウェア依存性があります。
- boost* 1.53.0
- OpenCV* 2.4.9
- protobuf* 3.0.0-beta1
- glog* 0.3.4
- gflags* 2.1.2
- lmdb* 0.9.16
- leveldb* 1.18
- HDF5* 1.8.15
- Red Hat* Enterprise Linux* 6.5 以降
インテル® ソフトウェア・ツール:
- インテル® MKL 11.3 以降
- インテル® MPI ライブラリー 5.0
ハードウェアの互換性:
- 第 4 世代インテル® Core™ プロセッサー (開発コード名 Haswell)
このソフトウェアは、AlexNet* トポロジーを使用してのみ評価されており、そのほかの構成では動作の保証はありません。
サポート
このパッケージ関する問い合わせは、mailto:intel.mkl@intel.com に直接お送りください。
| intel_optimized_technical_preview_for_multinode_caffe_1.1.tgz (3.4MB) https://software.intel.com/sites/default/files/managed/14/de/intel_optimized_technical_preview_for_multinode_caffe_1.1.tgz |
コンパイラーの最適化に関する詳細は、最適化に関する注意事項を参照してください。
