

この記事は、インテル® デベロッパー・ゾーンに掲載されている「Improve Intel MKL Performance for Small Problems: The Use of MKL_DIRECT_CALL」(https://software.intel.com/en-us/articles/improve-intel-mkl-performance-for-small-problems-the-use-of-mkl-direct-call) の日本語参考訳です。
インテル® マス・カーネル・ライブラリー (インテル® MKL) 11.2 の主要な新機能の 1 つは、小さな問題サイズにおけるパフォーマンスの大幅な向上です。バージョン 11.2 の xGEMM 関数 (行列の乗算) を使用するだけで、 バージョン 11.1 よりも優れたパフォーマンスが得られます。さらに、インテル® MKL 11.2 では、小行列演算のパフォーマンスを大幅に向上する新しい制御が追加されています。この制御は、”-DMKL_DIRECT_CALL” または “-DMKL_DIRECT_CALL_SEQ” を指定してインテル® MKL をリンクすることで有効になります。実行時に、小行列演算は高速な実行パスで処理されます。この高速なパスは、エラーチェックと複数の関数呼び出しレイヤーをスキップすることでオーバーヘッドを抑え、パフォーマンスを向上します。行列サイズは、数十行/数十列でなければなりません。それよりも大きな行列で MKL_DIRECT_CALL または MKL_DIRECT_CALL_SEQ を指定すると、行列は通常の実行パスで処理されます。そのため、パフォーマンスは向上しませんが、害になることもありません。
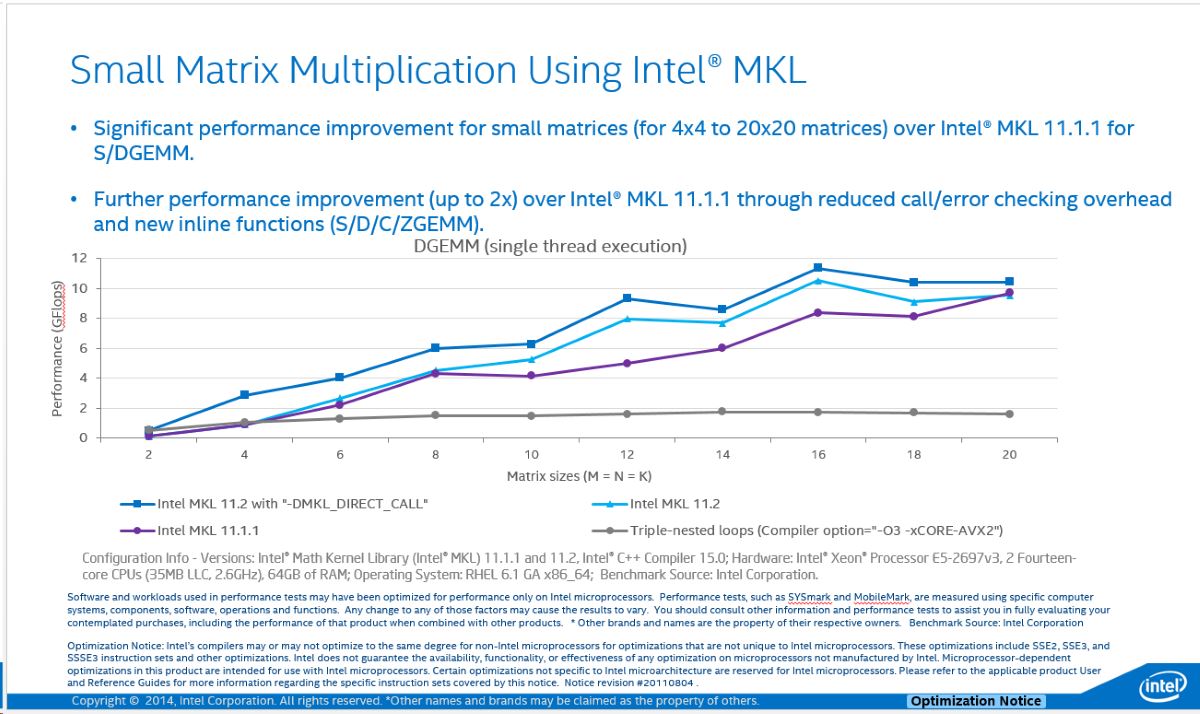
以下のグラフは、次の 4 つのシナリオで小行列 (4×4 から 20×20 の範囲) の倍精度行列-行列乗算を行った結果を比較したものです。
- 3 重入れ子構造のループを使用するネイティブ実装 (インテル® C++ コンパイラー 15.0 で “-O3 -xCORE-AVX2” オプションを指定してコンパイル)
- インテル® MKL 11.1.1 の DGEMM を使用
- インテル® MKL 11.2 の DGEMM を使用
- インテル® MKL 11.2 の DGEMM と “-DMKL_DIRECT_CALL” を使用
使用した行列はすべて正方行列です。インテル® MKL 11.2 のほうが 11.1.1 よりもパフォーマンスが優れていることが分かります。また、MKL_DIRECT_CALL によってもたらされる利点も明らかです。
MKL_DIRECT_CALL と MKL_DIRECT_CALL_SEQ の使用法
これらはリンク時に定義されるマクロで、インテル® MKL が小行列を高速なパスで処理するように指定します。1 つ目の MKL_DIRECT_CALL マクロは、並列バージョンのインテル® MKL ライブラリーにリンクする場合に使用します。2 つ目の MKL_DIRECT_CALL_SEQ マクロは、シーケンシャル・バージョンのインテル® MKL ライブラリーにリンクする場合に使用します。どちらのマクロも大きな行列では効果がありません。
Linux* システムの C プログラムでは、リンク行に -DMKL_DIRECT_CALL または -DMKL_DIRECT_CALL_SEQ を追加するだけです。Windows* では、/DMKL_DIRECT_CALL または /DMKL_DIRECT_CALL_SEQ を追加します。通常、-std=c99 (Windows* の場合は /Qstd=c99) も一緒に指定する必要があります。これは、インテル® C++ コンパイラー、GCC、Microsoft* Visual Studio* などの主要な C/C++ コンパイラーで検証されています。
Fortran プログラムでは、最初に “mkl_direct_call.fi” をインクルードします。以下は、『インテル® MKL ユーザーズガイド』から抜粋したコード例です。次に、リンク行に -DMKL_DIRECT_CALL (Windows* の場合は /DMKL_DIRECT_CALL) または -DMKL_DIRECT_CALL_SEQ (Windows* の場合は /DMKL_DIRECT_CALL_SEQ) を追加します。インテル® Fortran コンパイラーを使用する場合は、-fpp (Windows* の場合は /fpp) を指定して Fortran プリプロセッサーによる事前処理を有効にします。PGI* Fortran コンパイラーを使用する場合は、代わりに -Mpreprocess を指定します。GNU* Fortran コンパイラーでは、この機能は使用できません。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 | # include "mkl_direct_call.fi" program DGEMM_MAIN....* Call Intel MKL DGEMM.... call sub1() stop 1 end* A subroutine that calls DGEMM subroutine sub1* Call Intel MKL DGEMM end |
制限事項
この機能の使用にはいくつかの制限事項があります。
- パフォーマンスの向上は、エラーチェックと関数のインライン展開をスキップすることによってもたらされます。関数呼び出しで正しくない引数が渡されてもエラーは出力されません。そのため、この機能はコードの開発時やデバッグ時に使用すべきではありません。配布可能なコードでのみ有効にすべきです。
- この機能によって高速なパスで処理される関数では、「verbose モード」 (インテル® 11.2 の新機能) を利用できません。
- 現在、この機能は C/ZGEMM3 関数では効果がありません。
- この機能は、CBLAS 関数呼び出しでは利用できません。
- インテル® Xeon Phi™ コプロセッサーでこの機能によってもたらされるパフォーマンスの向上はわずかです。現在、インテル® Xeon Phi™ コプロセッサーの能力を最大限に利用できるように取り組んでいます。
- CNR (条件付き数値再現性) はサポートされません。
- Fortran プログラムで、GNU* Fortran コンパイラーはサポートされていません。
コンパイラーの最適化に関する詳細は、最適化に関する注意事項を参照してください。
