
この記事は、インテル® AI Blog に公開されている「Accelerating TensorFlow* Inference with Intel® Deep Learning Boost on 2nd Gen Intel® Xeon® Scalable Processors」の日本語参考訳です。
インテルは、ディープラーニング・アプリケーションを高速化するように設計された新しい組込みプロセッサー・テクノロジーのインテル® Deep Learning Boost (インテル® DL Boost) (英語) を発表しました。インテル® DL Boost には、8 ビット精度で計算を実行する新しい Vector Neural Network Instructions (VNNI) が含まれます。これは、メモリー使用量を 1/4 に減らし、浮動小数点精度と比較して毎秒実行される算術演算の割合を増やします。浮動小数点精度の事前トレーニング済みのモデルを使用して、ここではモデルの量子化バージョンを入手し、インテル® DL Boost 命令による推論パフォーマンスの向上を調査します。次に、ディープ・ニューラル・ネットワーク向けインテル® マス・カーネル・ライブラリー (インテル® MKL-DNN) (英語) を使用して、TensorFlow* で 8 ビット精度の推論ワークについてまとめます。
TensorFlow* における量子化
第 2 世代インテル® Xeon® スケーラブル・プロセッサーでインテル® DL Boost を有効にするため、32 ビット浮動小数点を使用するモデルで、ライブラリーを使用することなく 8 ビット推論をシームレスに使用できるようにインテル® Optimization for TensorFlow* を拡張しました。
また、事前トレーニング済みの 32 ビット浮動小数点モデルを 8 ビット推論を使用する量子化モデルに変換するオフライン・ツール、インテル® Optimization for TensorFlow* Quantization ツールを開発しました。モデルの量子化の詳細な説明とガイドラインは、インテル® AI Quantization Tools for TensorFlow* (英語) を参照してください。これらのツールを使用して、表 1 に示すように、高い精度を維持しつつ、畳み込みニューラル・ネットワークとフィードフォワード・ニューラル・ネットワークを含む一般的なディープラーニング・モデルを量子化することができました。すぐに使用できるように、Intel-model-zoo (英語) にいくつかの量子化モデルを公開しています。
モデルの量子化
ここでは、post-training モデルの量子化を有効にします。つまり、ユーザーは、事前トレーニング済みの浮動小数点モデルを量子化できます。これは、浮動小数点の活性化と重みを 8 ビット整数に変換して、計算グラフ中の浮動小数点演算を量子化バージョンに置き換えます。インテルのツールを使用して最適化済みの量子化モデルを取得する主なステップは次のとおりです。
- fp32 推論モデルをシリアル化された TensorFlow* GraphDef としてエクスポート: これには、推論グラフを protobuf 形式で保存し、冗長なノードの削除 (例: Identity、CheckNumerics など)、定数の畳み込み、バッチ正規化の畳み込みを適用するグラフ変換が含まれます。
- fp32 グラフを量子化グラフに変換: このステップは、fp32 操作を融合量子化操作に置き換えて、活性化に必要な変換操作を追加します (例: ‘QuantizeV2’、’Requanitze’ など)。重みの量子化もこのステップで行われます。
- 量子化グラフのキャリブレーションと最適化: このステップでは、前のステップで取得した量子化グラフをトレーニング・データの小さなサブセット (キャリブレーション・データ) で実行して、活性化の範囲を固定します。結果グラフは、‘Requanitze’ 操作を融合することでさらに最適化されます。
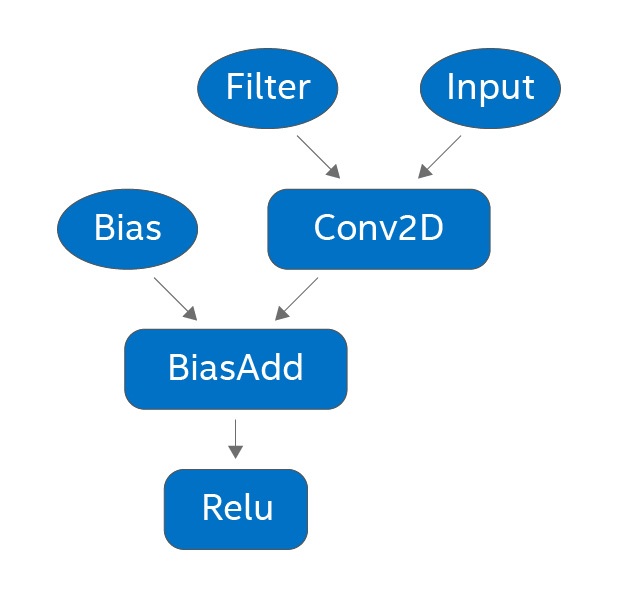
上記のステップを説明するため、図 1 に各ステップで生成されるサブグラフを示します。広く使用されている CNN (例: ResNet、Inception など) は、conv2d → バッチ正規化 → ReLU 操作シーケンスを繰り返します。バッチ正規化の畳み込み終わると、図 1(a) のようなサブグラフが生成され、このサブグラフは図 1(b) の融合量子化演算子で置き換えられます。キャリブレーション後に図 1(c) に示すさらなる最適化が行われます。ほとんどの畳み込みは、ReLU が先行する操作であることから非負の正規化された入力を受け取るため、量子化畳み込みは符号なし 8 ビット整数の入力と符号付き 8 ビット整数のフィルターを受け取ります。必要な算術演算はインテル® DL Boost の VPDPBUSD 命令で効率良く行うことができるため (詳細はこちら (英語) を参照)、この符号なしと符号付きの組み合わせはパフォーマンスにとっても重要です。
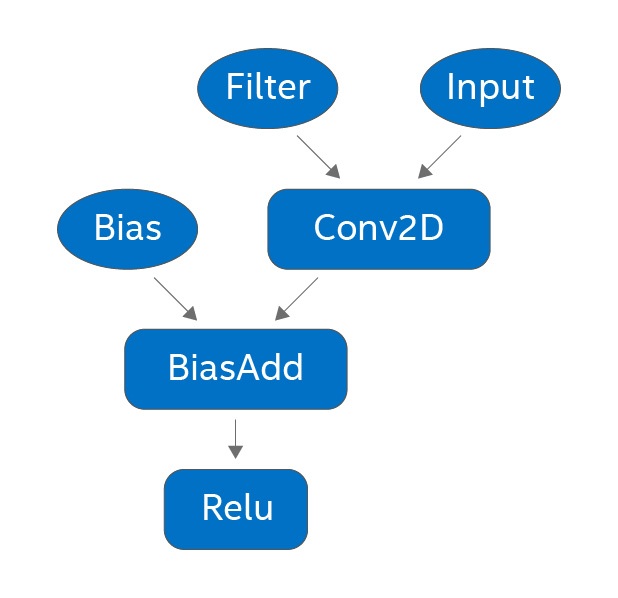
図 1 (a): fp32 サブグラフ
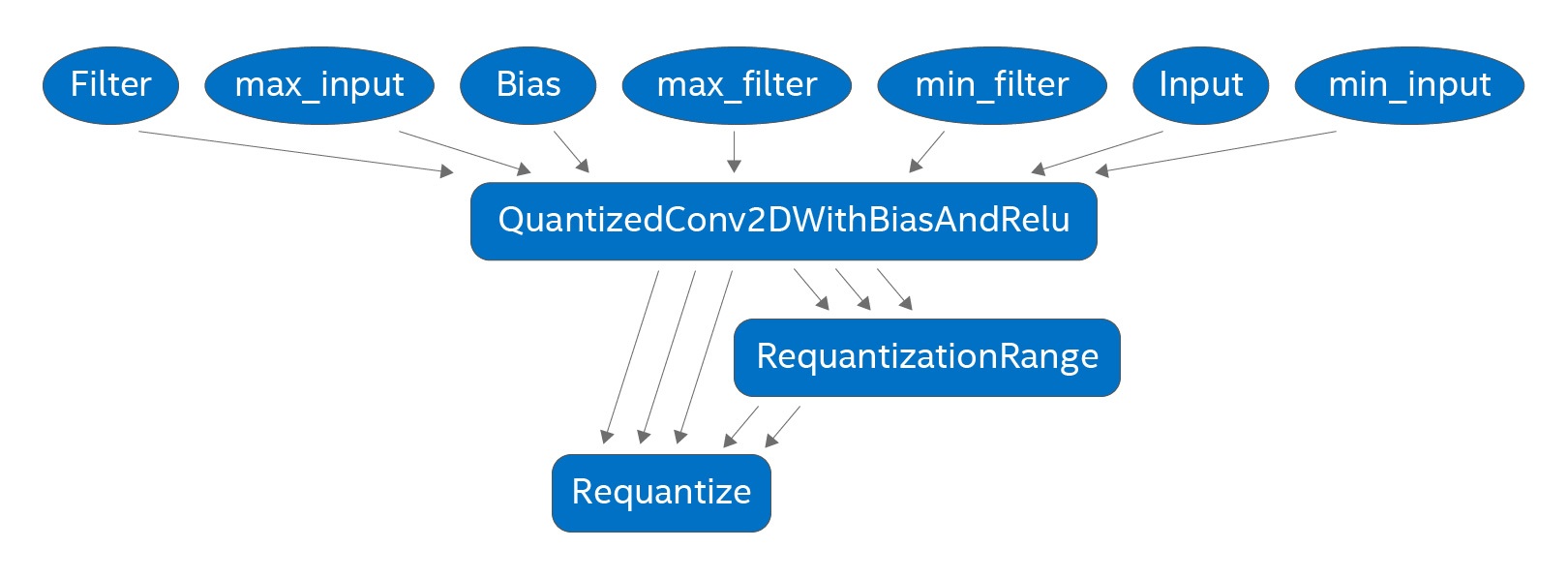
図 1(b): 8 ビット量子化サブグラフ

図 1 (c): キャリブレーション済み 8 ビット量子化サブグラフ
インテル® DL Boost 命令を利用できる conv2D および matmul 操作のほかに、メモリー帯域幅のボトルネックを大幅に軽減し、不要な量子化/逆量子化を回避する pooling と concat 操作があります。最高のパフォーマンスを達成するには、可能な限り連続して 8 ビット精度の操作を使用することを推奨します。
一部の事前トレーニング済みモデル (例: MobileNet) は、異なるチャネルで重みテンソルのデータ分布が異なります。そのような場合、重みテンソルの量子化に単一のスケール・パラメーターを使用すると、精度が大幅に低下する可能性があります。この問題は、’RequantizePerChannel’ や ‘RequantizationRangePerChannel’ などの新しい演算子を追加することで緩和できます。このようにモデル量子化ツールをチャネルごとに拡張することで、Mobilenet 関連のモデルの精度低下を回復することができました。
精度とパフォーマンス
ここでは、画像分類、オブジェクト検出、推奨システム向けのいくつかの一般的なディープラーニング・モデルで 8 ビットの推論を可能にします。表 1 は、第 2 世代インテル® Xeon® スケーラブル・プロセッサー上でのいくつかの CNN モデルの精度とパフォーマンスの向上を示しています。表から分かるように、インテル® DL Boost は fp32 モデルに近い精度を維持しつつ推論を大幅にスピードアップします。[1]
| モデル | Top 1 精度 (%) | スループットのスピードアップ | |
|---|---|---|---|
| FP32 (インテル® Xeon® スケーラブル・プロセッサー) |
INT8 (第 2 世代インテル® Xeon® スケーラブル・プロセッサー) |
第 2 世代インテル® Xeon® スケーラブル・プロセッサー |
|
| ResNet-50 | 74.30 | 73.75 | 3.9 倍 |
| ResNet-101 | 76.40 | 75.66 | 4.0 倍 |
| Inception-v3 | 76.75 | 76.51 | 3.1 倍 |
表 1: 浮動小数点モデルと量子化モデルの精度とパフォーマンス
第 2 世代インテル® Xeon® スケーラブル・プロセッサー上のインテル® DL Boost は、コンピューター・ビジョン、自然言語処理、音声処理で使用されるディープモデルの高速化において有益な結果をもたらします。インテルが開発したツールセットを使用して、ほかのライブラリーに依存することなく fp32 モデルを量子化して TensorFlow* で推論パフォーマンスを向上できます。量子化ツールの詳細とダウンロードは、intel-quantization-tool (英語) を参照してください。
関連ドキュメント
- インテル® AI ブログ: 数値精度を低くすることでディープラーニングのパフォーマンスを向上
https://www.intel.ai/lowering-numerical-precision-increase-deep-learning-performance/#gs.2txg3m - TensorFlow* でニューラル・ネットワークを量子化する方法
- 効率良い整数演算のみの推論向けニューラル・ネットワークの量子化とトレーニング
[1] パフォーマンスは、合成データとサイズ 128 のミニバッチで測定されました。
その他の協力者
Ashraf Bhuiyan、Mahmoud Abuzaina、Niranjan Hasabnis、Niroop Ammbashankar、Karen Wu、Ramesh AG、Clayne Robison、Bhavani Subramanian、Srinivasan Narayanamoorthy、Cui Xiaoming、Mandy Li、Guozhong Zhuang、Lakshay Tokas、Wei Wang、Jiang Zhoulong、Wenxi Zhu、Guizi Li、Yiqiang Li、Rajesh Poornachandran、Rajendrakumar Chinnaiyan。
謝辞
Huma Abidi、Jayaram Bobba、Banky Elesha、Dina Jones、Moonjung Kyung、Karthik Vadla、Wafaa Taie、Jitendra Patil、Melanie Buehler、Lukasz Durka、Michal Lukasziewski、Abolfazl Shahbazi、Steven Robertson、Preethi Venkatesh、Nathan Greeneltch、Emily Hutson、Anthony Sarah、Evarist M Fomenko、Vadim Pirogov、Roma Dubstov。
Google* 社の Tatiana Shpeisman 氏、Thiru Palanisamy 氏、Penporn Koanantakool 氏。
法務上の注意書きと最適化に関する注意事項
性能に関するテストに使用されるソフトウェアとワークロードは、性能がインテル® マイクロプロセッサー用に最適化されていることがあります。
SYSmark* や MobileMark* などの性能テストは、特定のコンピューター・システム、コンポーネント、ソフトウェア、操作、機能に基づいて行ったものです。結果はこれらの要因によって異なります。製品の購入を検討される場合は、他の製品と組み合わせた場合の本製品の性能など、ほかの情報や性能テストも参考にして、パフォーマンスを総合的に評価することをお勧めします。詳細については、www.intel.com/benchmarks (英語) を参照してください。
パフォーマンス結果は 2019 年 3 月 1 日時点のテスト結果に基づいたものであり、公開されている利用可能なすべてのセキュリティー・アップデートが適用されていない可能性があります。絶対的なセキュリティーを提供できる製品またはコンポーネントはありません。
システム構成
第 2 世代インテル® Xeon® スケーラブル・プロセッサー・プラットフォーム:
2 ソケット インテル® Xeon® Platinum 8280 プロセッサー、28 コア、インテル® ハイパースレッディング・テクノロジー有効、インテル® ターボ・ブースト・テクノロジー有効、合計メモリー 384GB (12 スロット/32GB/2933MHz)、BIOS: SE5C620.86B.0D.01.0271.120720180605 (ucode:0x4000013)、CentOS* 7.6, 4.19.5-1.el7.elrepo.x86_64、ディープラーニング・フレームワーク: https://hub.docker.com/r/intelaipg/intel-optimized-tensorflow:PR25765-devel-mkl (https://github.com/tensorflow/tensorflow.git commit: 6f2eaa3b99c241a9c09c345e1029513bc4cd470a + プルリクエスト PR 25765、upstreaming の PR を送信)、コンパイラー: gcc 6.3.0、インテル® MKL-DNN バージョン: v0.17、データ型: INT8
インテル® Xeon® スケーラブル・プロセッサー・プラットフォーム:
2 ソケット インテル® Xeon® Platinum 8180 プロセッサー、28 コア、インテル® ハイパースレッディング・テクノロジー有効、インテル® ターボ・ブースト・テクノロジー有効、合計メモリー 384GB (12 スロット/32GB/2633 MHz)、BIOS: SE5C620.86B.0D.01.0286.121520181757、CentOS* 7.6, 4.19.5-1.el7.elrepo.x86_64、ディープラーニング・フレームワーク: https://hub.docker.com/r/intelaipg/intel-optimized-tensorflow:PR25765-devel-mkl (https://github.com/tensorflow/tensorflow.git commit: 6f2eaa3b99c241a9c09c345e1029513bc4cd470a + プルリクエスト PR 25765、upstreaming の PR を送信)、コンパイラー: gcc 6.3.0、インテル® MKL-DNN バージョン: v0.17、データ型: FP32
最適化に関する注意事項: インテル® コンパイラーでは、インテル® マイクロプロセッサーに限定されない最適化に関して、他社製マイクロプロセッサー用に同等の最適化を行えないことがあります。これには、インテル® ストリーミング SIMD 拡張命令 2、インテル® ストリーミング SIMD 拡張命令 3、インテル® ストリーミング SIMD 拡張命令 3 補足命令などの最適化が該当します。インテルは、他社製マイクロプロセッサーに関して、いかなる最適化の利用、機能、または効果も保証いたしません。本製品のマイクロプロセッサー依存の最適化は、インテル® マイクロプロセッサーでの使用を前提としています。インテル® マイクロアーキテクチャーに限定されない最適化のなかにも、インテル® マイクロプロセッサー用のものがあります。この注意事項で言及した命令セットの詳細については、該当する製品のユーザー・リファレンス・ガイドを参照してください。
注意事項の改訂 #20110804
Intel、インテル、Intel ロゴ、Xeon、Intel Xeon Phi は、アメリカ合衆国および / またはその他の国における Intel Corporation またはその子会社の商標です。
* その他の社名、製品名などは、一般に各社の表示、商標または登録商標です。
© Intel Corporation.
