

この記事は、インテル® デベロッパー・ゾーンに掲載されている「Performance Interactions of OpenCL* Code and Intel® Quick Sync Video on Intel® HD Graphics 4000」(http://software.intel.com/en-us/articles/performance-interactions-of-opencl-code-and-intel-quick-sync-video-on-intel-hd-graphics) の日本語参考訳です。
はじめに
ビデオ編集や作成もしくはビデオのフレームを処理し、その後インテル® クイック・シンク・ビデオでそれらをエンコードするアプリケーションの開発者にとって、OpenCL* を使用してフレーム処理を CPU からインテル® HD グラフィックスへ移行する際、パフォーマンスの利点を得ることは容易ではないかもしれません。この記事では、その理由とパフォーマンスを向上するワークロードの識別方法を説明し、開発者が OpenCL* コードを効率良く記述できるよう支援します。
想定外の問題
第 3 世代インテル® Core™ プロセッサーのリリースに向けて、インテル® プロセッサー・グラフィックスへの OpenCL* の対応準備を進める中、私はビデオ編集アプリケーション向けの OpenCL* カーネルの最適化に取り組みました。 当初、ビデオのエフェクト処理を CPU からインテル® プロセッサー・グラフィックスに移行することで、アプリケーションのパフォーマンスが大幅に向上することが期待されました。
実際、ユニットテストで OpenCL* カーネルのパフォーマンスは、同じエフェクトの高度に最適化されたコードをシングル CPU コアで実行する場合よりも平均で 3 倍向上し、一部のカーネルでは同等の CPU コードと比べて最大 20 倍も向上しました! これはパフォーマンス向上の良い前兆だと思われました。事実、OpenCL* カーネルをアプリケーションに統合したところ、一部のワークロードでパフォーマンスが向上しました。
しかし、多くのワークロードでは、パフォーマンスが良かった同一カーネルのパフォーマンスが向上せず、同等の CPU コードよりも遅くなってしまいました。
何が問題なのでしょうか?
背景
使用したビデオ編集アプリケーションは、プロセッサーの並列性を活用するようにコーディングされていました。ビデオエフェクトに SIMD 命令が用いられ、(4 コアの CPU で) 4 スレッドを使用して各ビデオフレームが個別に処理されていました。また、インテル® クイック・シンク・ビデオにより、エフェクトを適用する前のビデオのデコーディングと適用後の再エンコーディングが高速化されていました。
OpenCL* をできるだけ高速に実行するには、通常 4 つのスレッドのうち 1 つを、OpenCL* を使って GPU でエフェクトカーネルを起動するのに専用にするため、CPU でエフェクトを処理するスレッド数が減ります。個別のテストにおいて、GPU 上のOpenCL* カーネルの処理速度は 1 CPU スレッドよりも格段に高速だったため、これは許容範囲のトレードオフと判断されました。つまり、CPU スレッドが 1 つ減ることによるパフォーマンスの低下よりも、OpenCL* GPU スレッドによりもたらされるパフォーマンス向上のほうが大きいことが予想されました。
しかし、実際には、OpenCL* を使って CPU スレッドから GPU スレッドへエフェクト処理を移行しても、パフォーマンスは向上せず、多くの場合低下することが分かりました。
使用した開発ツール
問題を特定し、アプリケーションを最適化するため、インテルの Visual Computing Source で提供されている無料のビジュアル・コンピューティング向け開発ツールを利用しました。インテル® クイック・シンク・ビデオを用いたハードウェア支援によるビデオ・エンコーディングにはインテル® Media SDK を、OpenCL* アプリケーションの開発にはインテル® SDK for OpenCL* Applications を、そしてメディアとグラフィックスの最適化にはインテル® グラフィックス・パフォーマンス・アナライザー (インテル® GPA) を使用しました。
問題を特定する
まず、OpenCL* によりパフォーマンスが向上したワークロードとパフォーマンスが低下したワークロードの大きな違いは、後者はインテル® クイック・シンク・ビデオを使用してビデオを AVC ビデオ (H.264/MPEG4 Part 10) にエンコードしていることでした。また、インテル® クイック・シンク・ビデオを使用しないとアプリケーションのパフォーマンスが大幅に低下しますが、いくつかのエフェクト処理を CPU スレッドから GPU に移行することで、(インテル® クイック・シンク・ビデオを用いた場合のパフォーマンスを超えるほどではありませんが)、パフォーマンスが多少向上することも分かりました。
次に、何が起こっているかを把握するため、インテルのパフォーマンス解析ツールを利用しました。インテル® グラフィックス・パフォーマンス・アナライザー (インテル® GPA) のパフォーマンス・モニターでプログラム可能なグラフィックス処理をトレースし、その結果をプラットフォーム・アナライザーで表示します。実行時間全体にわたる GPU 上の処理がグラフで表示され、バーの数と幅からおおよその GPU 処理の数と間隔を把握できます。バーの範囲を選択して、その範囲の正確な合計時間と処理時間を取得し、かなり正確な GPU 使用率を算出することもできます。
図 1 は、高度に最適化されたビデオエフェクトを含むワークロードを 4 コアの CPU で実行した場合の約 2 秒間の内蔵 GPU のアクティビティーを示したものです。この例では、OpenCL* またはインテル® クイック・シンク・ビデオは使用せず、AVC (H.264 part 10) へのエンコードも CPU で実行されています。

図 1 – インテル® GPA のパフォーマンス・モニターによるトレース情報 – GPU 側でのワークなし
上記の画面では、GPGPU (GPU による汎用計算) 処理はわずかしかなく (使用率の1% 未満)、これは少量のオンスクリーン・グラフィック・アニメーション (プログレスバーなど) の更新によるものと考えられます。
次の画面は、同じワークロードで、すべての AVC エンコーディングにインテル® クイック・シンク・ビデオを用いた場合の結果です。“GPU Unknown” 行はほぼ同じで、ビデオエンコード処理に関連した行が 3 つ追加されています。“04: GPU: ENCODE” 行と “GPU: VPP” 行は内蔵 GPU での実行、最後の行 “06: GPU: ENCODE” は (GPGPU ではなく) ハードウェアによるモーション推定のような専用の機能ユニットでのエンコード処理を示します。

図 2 – インテル® クイック・シンク・ビデオを用いたエンコードのインテル® GPA トレース情報
ここで重要なのは、ビデオエンコードがプロセッサー・グラフィックスのすべての実行時間を占めているわけではないことです。つまり、GPGPU 実行時間を示すバーをすべてまとめても、合計実行時間 (インテル® GPA により測定されたアクティブな GPU 実行時間の量) の 40% ほどにしかなりません。“GPU EU Queue” 行は、GPU で実行するタスクが、GPU がビジーなためキューで待機した時間を示します。バーの間の空白は GPU のタスクキューが空だったことを意味します。
上記の画面から、プログラム可能なグラフィックス実行ユニットにはビデオエフェクトを処理するだけの時間があり、インテル® プロセッサー・グラフィックスで OpenCL* を使って全体のスループットを向上できる可能性があることが分かります。
次の画面は、同じワークロードで、すべての AVC エンコーディングにインテル® クイック・シンク・ビデオを用い、GPU で OpenCL* を使ってビデオエフェクトを実装した場合の約 2 秒間のアクティビティーを示しています。4 つの CPU スレッドのうち 3 つは引き続きビデオエフェクトを処理しますが、残り 1 つは GPU でビデオエフェクトを実行するために使用されます (画面では 2 行目に表示され、GPGPU アクティビティーが多発していることが分かります)。

図 3 – OpenCL* エフェクト処理を追加した場合のトレース情報
1 行目の “GPU EU Queue” がほぼ 1 つのバーになり、GPGPU がフル活用に近い状態のため、ほぼ必ず実行を待機しているタスクがあることが分かります。また、やや分かりづらいですが、”GPU: Unknown”、”GPU: Encode”、”GPU: VPP” 行をすべてまとめると、GPGPU 実行ユニットのフル活用に近いバーになります。実際、インテル® GPA で GPGPU 使用率は 95% を示しており、これは 55% の向上を意味します。つまり、GPU 処理能力を限界近くまで利用していることになります。(一部の GPGPU 実行は、GPU でスレッドを開始するためのオーバーヘッドに費やされます。)
しかし、このアプリケーション・ワークロードの実際のパフォーマンスは悪く、実行時間が 20% も長くなりました。図 3 と図 2 の最後の行 (GPU: ENCODE) を比べると、図 3 ではビデオフレームのエンコード数を示すバーがかなり少なくなっているのが分かるでしょう。これは、すべてのフレームが GPU でエンコードされるため、フレームのスループット・レートが低いことを示します。(多くの場合、アプリケーション・コードからフレームレートを特定することができます。そして、算出したフレームレートとインテル® GPA により提供される GPU 使用率を基に、1 フレームあたりのビデオエンコード処理時間の平均を確認できます。)
問題の原因
最も可能性の高い原因として、CPU で実行するよりも GPU で実行したほうが、ビデオエフェクトのアルゴリズムの処理に時間がかかることが考えられます。しかし、ビデオエフェクトを個別にテストしたところ、特定のエフェクトは (すべての GPGPU 実行ユニットを使って) CPU よりも 2 倍以上高速に実行できました。したがって、GPU のほうが CPU スレッドよりも速くなるはずです。
しかし、前述したように、そして図 4 に示すように、GPGPU 実行時間の 40% はインテル® クイック・シンク・ビデオが占めており (4 つの CPU スレッドがそれぞれのエフェクト処理に 10% ずつ使用しています)、55% は GPGPU 上のエフェクト処理が占めています。つまり、GPGPU エフェクト処理がオリジナルの CPU スレッドと同等のパフォーマンスを達成するには、約 2 倍速くなければいけません。(CPU でビデオエンコードを行うと全体的にさらに遅くなるため、この選択肢は選べません。)
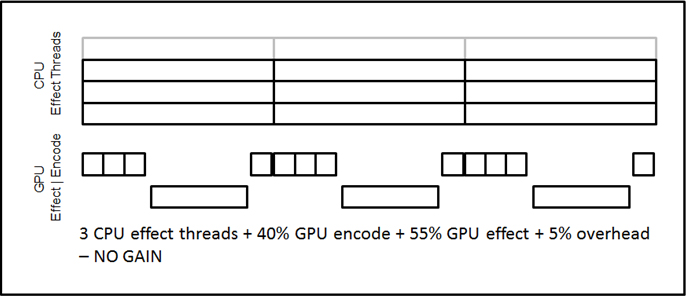
図 4 – 実行時間全体にわたる CPU および GPU のエフェクト処理とビデオエンコード
さらに、エンコードにより実行ユニット時間に占める時間の割合は異なります。実行ユニットのビデオエンコードによってパフォーマンスが制限される場合 (CPU エフェクト・アルゴリズムが非常に高速な場合など)、エンコードが GPU 実行ユニット時間の 100% を占めることもあります。4 つのスレッドでビデオエフェクトを並列処理すると、1 フレームあたりのエンコード時間の平均は CPU エフェクト時間の 1/4 になります。つまり、GPGPU ビデオエンコードが絶対的な制限要因にならないように、CPU エフェクト時間は 1 ビデオフレームのエンコードに必要な時間よりも 4 倍以上長くなければいけません。
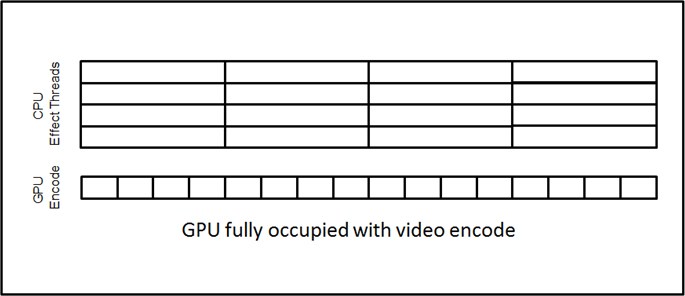
図 5 – エンコードが GPU 実行ユニット時間の 100% を占める場合
前述の「問題の特定」で説明したように、この GPGPU エンコード時間の平均は 5 ミリ秒です。ただし、この値はエンコード・パラメーターとその他の要因に依存します。つまり、20 ミリ秒 (4 × エンコード時間 5 ミリ秒) 以下の CPU エフェクト処理はビデオエンコードにより制限され、GPGPU でエフェクト処理を行ってもパフォーマンスの向上は見込めません。サンプル・アプリケーションでは、エフェクト処理の半分近くがこの条件に当てはまります。
ただし、パフォーマンスが向上しない理由はこれだけではありません。GPGPU でエフェクト処理を行うことで、パフォーマンスを例えば 25% 向上したいとします。パフォーマンスを 25% 向上するには、一度に 5 フレームをエンコードする必要があります。そのためには、CPU エフェクト時間が GPGPU エンコード時間よりも少なくとも 5 倍長くなければいけません (エンコード時間が 5 ミリ秒の場合、エフェクト時間は 25 ミリ秒以上)。
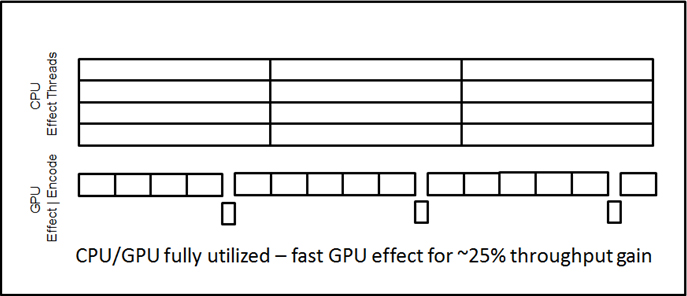
図 6 – GPGPU でエフェクト処理を行うことで、パフォーマンスを例えば 25% 向上した場合
さらに、OpenCL* GPGPU エフェクトカーネル処理を実行する時間も必要です。これはやや複雑なので、複数の例をもとに期待されるパフォーマンスへの影響を算出してみましょう。
CPU から GPGPU へエフェクト処理をオフロードする例
GPGPU ビデオエンコード時間は 5 ミリ秒、CPU エフェクト処理時間は 30 ミリ秒とします。(前述のようにパフォーマンスを 25% 向上するためには) 5 フレームのエンコードに 25 ミリ秒かかるため、GPGPU エフェクト処理に費やせる時間は 5 ミリ秒です。CPU スレッドのうち 1 つは使用できないため、CPU は 30 ミリ秒で 3 フレームしか生成できず、残りの 2 フレームは GPU で対応する必要があります。オーバーヘッドが 5% だと仮定すると、GPGPU OpenCL* カーネルは 1 フレームを 2 ミリ秒で処理する必要があります。つまり、同じアルゴリズムをシングル CPU スレッドよりも 15 倍高速に処理しなければいけません! これは不可能ではありませんが、このような向上を達成できるのはかなりまれなケースでしょう。

図 7 – 3並列の 30ms の CPU エフェクト、5x5ms GPU エンコード、2x2ms GPU エフェクト
サンプル・アプリケーションで、シングル CPU スレッドと比べた GPGPU スピードアップの平均は約 3 倍です。より合理的な GPGPU エフェクト処理時間 20 ミリ秒と CPU エフェクト時間 60 ミリ秒で考えてみましょう。60 ミリ秒の間に、CPU で 3 フレームと GPU で “X” フレームがエンコードされ、GPGPU 実行時間の 5% はオーバーヘッドに費やされます。次の式を使って X を解き、60 ミリ秒間に GPGPU で処理およびエンコード可能なフレーム数を特定することができます。
式 1 – GPGPU で処理およびエンコード可能なフレーム数
上記の式を解くと、GPGPU でエフェクト処理されるフレーム数 X は 1.2 になります。つまり、GPGPU エフェクト処理を用いた場合、60 ミリ秒間に 4 フレームではなく (1.2 + 3) = 4.2 フレーム生成することができ、3 倍のカーネル・スピードアップと比べて 1.05 倍 (5%) パフォーマンスを向上できます。
では、パフォーマンスを 25% 向上するにはどうしたら良いでしょうか? 上記の式では X = 2 になるようにする必要があります。つまり、CPU スレッドごとに 1 フレーム、そして GPU で 2 フレーム生成して、同じ時間内に 4 フレームではなく 5 フレーム生成する必要があります。5 フレームの合計エンコード時間は 25 ミリ秒です (5 フレーム × 1 フレームあたりのエンコード時間 5 ミリ秒)。CPU エフェクト時間を 60 ミリ秒とし、GPGPU エフェクト時間 (そのうち 5% または 3 ミリ秒はオーバーヘッド) を Y とすると、新しい式は次のようになります。
式 2 – 新しい式
この式を解くと、GPGPU エフェクト処理時間 Y は 1 フレームあたり 16 ミリ秒になります。つまり、アプリケーション・レベルで 25% スピードアップするには、GPGPU OpenCL* カーネルが CPU カーネルよりも 3.75 倍高速でなければいけません。これは達成できない値ではありません。
アプリケーション・レベルで 2 倍のスピードアップを達成することは可能でしょうか? 4 フレームの CPU エフェクト処理時間を 60 ミリ秒とすると、出力フレーム数は 8 (GPGPU 処理が 5 フレーム、CPU が 3 フレーム) になります。
式 3 – アプリケーション・レベルで 2 倍のスピードアップを達成することは可能性
この式を解くと、GPGPU エフェクト処理時間 Y は 1 フレームあたり 3.4 ミリ秒、または 17.6 倍高速になります。前述のように、CPU と比べて GPGPU でこれだけのパフォーマンスの向上を達成できるのはかなりまれです。
CPU エフェクト処理時間を 100 ミリ秒に変更すると、式は次のようになります (オーバーヘッドは 5% = 5 ミリ秒)。
式 4 – CPU エフェクト処理時間を 100 ミリ秒に変更
この式を解くと、GPGPU エフェクト処理時間 Y は 1 フレームあたり 11 ミリ秒になります。パフォーマンスを 2 倍向上するには、まだ 9.1 倍のスピードアップが必要です。これは達成可能ですが、簡単ではありません。
これらの考察から、GPGPU ビデオエンコード処理時間よりも CPU エフェクト処理時間のほうが大きいほど、GPGPU に処理を移行することでパフォーマンスの向上が得られやすくなることが分かります。
CPU を常にビジー状態にする
CPU スレッドを 1 つ減らさずに GPU エフェクト処理スレッドを追加した場合どうなりますか?これは可能でしょう。GPU で OpenCL* カーネルを実行するのに必要な CPU 時間はわずかなので、カーネルが完了するのを待機することができます。利用可能なすべての CPU コアでエフェクト処理を実行すると、OpenCL* GPGPU スレッドの応答が悪くなる可能性が高くなります。GPU スレッドがカーネルの完了に応答し次のカーネルを開始する前に、CPU エフェクトスレッドのタイムスライスを終了する必要があるかもしれません。これは、GPU 実行ユニットの使用率の低下につながります。
前述の式 1 では、1 フレームあたりのエフェクト処理時間が CPU では 60 ミリ秒、GPU では 20 ミリ秒でした。次の式 5 は 、4 つの CPU スレッドでエフェクト処理を実行し、OpenCL* カーネルの処理に費やされる時間として 10% (6 ミリ秒) の GPU オーバーヘッドが追加されています (X は GPU で生成されるフレームの数)。
式 5 – 6 ミリ秒 の GPU オーバーヘッドを追加
この式を解くと、GPGPU エフェクトフレーム数 X は 0.97、つまり 約 1 フレームになります。式 1 では 60 ミリ秒間に 4.2 フレームを生成可能でしたが、この式では 5 フレームを生成できます。これは、CPU のみの場合と比べて 25%、スレッドのトレードオフがある式 1 と比べて 1.19 倍パフォーマンスが向上しています。ただし、これは CPU に対してGPGPU は 3 倍高速であり、GPGPU ビデオエンコード時間よりも CPU エフェクト時間のほうがかなり大きい場合です。CPU 時間が 30 ミリ秒のみの場合、式は次のようになります。
式 6 – CPU 時間が 30 ミリ秒のみの場合
この式を解くと、GPGPU エフェクトフレーム数 X は約 0.25、合計フレーム数は 4.25 となり、CPU のみの場合と比べて 6% しかパフォーマンスが向上しません。CPU で引き続きエフェクト処理を実行する場合も、優れたパフォーマンスを得るためには、GPGPU ビデオエンコード時間と比べて CPU エフェクト処理時間がかなり大きくなるようにする必要があります。
インテル® ターボ・モード
ここでは、関連のある興味深い要因としてインテル® ターボ・モードについて触れます。インテル® ターボ・モードは、CPU または GPU のいずれかがそれほどビジーでない場合、もう一方を高速に実行できるようにします。CPU があまりビジーでない場合、CPU 周波数の上昇を少なくすることで、GPU 周波数をほぼ 2 倍にすることが可能です。この機能はプロセッサーの温度の仕様限界により、両方の周波数を上げることはできません。両方の周波数を上げた場合、チップが熱くなりすぎてしまいます。
インテル® ターボ・モードで GPGPU でパフォーマンスを向上しようとする一方、CPU にアクティブなスレッドがある場合は、上記の単純な計算式をそのまま利用することはできません。一般に、上記の式は CPU と GPU のパフォーマンスを個別に計算した場合と比べて、GPGPU OpenCL* 処理をアプリケーションに追加することでもたらされる潜在的なパフォーマンスを過大評価する傾向にあります。
まとめ
GPGPU により高速化される OpenCL* とインテル® クイック・シンク・ビデオの両方を使用してアプリケーションのパフォーマンスをチューニングする場合、GPGPU 処理が GPU 処理リソースを消費することを理解し、いくつかの点を考慮する必要があります。
– マルチスレッドを実行するクアッドコアの第 3 世代インテル® Core™ プロセッサーで、インテル® HD グラフィックス 4000 内蔵 GPU へフレームをフィードしてビデオエンコードを行う場合、1 フレームの CPU 処理時間が GPU ビデオエンコード時間の 4 倍未満だと、CPU 処理を GPGPU OpenCL* カーネルにオフロードしてもパフォーマンスの向上は見込めません。 ほかのコア数でも同様です。(インテル® GPA により、プログラム可能なグラフィックス実行ユニットでビデオエンコード時間を測定できます。)
– GPGPU OpenCL* カーネルにオフロードされたワークを処理するのに十分な GPGPU 時間が確保できるように、(4 コア CPU をフル活用した場合の) 1 フレームあたりの CPU 処理時間は、GPGPU ビデオエンコード処理時間の 4 倍以上でなければいけません。一般に、良いパフォーマンス (25% 以上の向上) を得るためには、同等の GPGPU 処理時間と比べてかなり長くする必要があります。CPU 処理時間が長ければ長いほど、GPGPU 上の OpenCL* のパフォーマンスは良くなります。
– 最高のパフォーマンスを実現するには、CPU をフル活用しつつ GPGPU OpenCL* 処理を追加します。(パフォーマンスよりも省電力が優先される場合は、CPU から GPGPU へ処理を移行することを検討してください。GPGPU 処理のほうが電力効率が大幅に優れている可能性があります。)
– インテル® クイック・シンク・ビデオによるエンコードは、一部の処理を GPU で行わなければならない可能性があります。これは、GPU 上で実行可能な OpenCL* 処理量を減らしますが、CPU から処理をオフロードしてもパフォーマンス向上が得られにくくなります。
– インテル® ターボ・モードの周波数のスケーリングにより、必ずしもこの記事で示した単純な式のようにパフォーマンスが向上するとは限りません。これらの式は、達成可能なパフォーマンスの上限、あるいは GPGPU OpenCL* カーネルで特定のアプリケーション・レベルのパフォーマンスを達成するのに必要なスピードアップ要因の下限としてとらえるべきです。
これらの要因を考慮することで、インテル® クイック・シンク・ビデオのエンコードだけを使用して、またはインテルのプログラム可能なグラフィックス実行ユニットと併用してアプリケーションのパフォーマンスをチューニングする場合、大幅に時間を短縮できます。CPU スレッドで費やされた時間を測定し、インテル® GPA のメディア・パフォーマンス・アナライザーで既存の (インテル® クイック・シンク・ビデオやその他の) GPGPU 処理時間を測定することで、OpenCL* を使って CPU 処理をインテルの GPGPU に移行するとパフォーマンスが向上するかどうかを迅速に予測できます。
関連情報
インテル® SDK for OpenCL* Applications の Web サイト: https://www.isus.jp/article/intel-software-dev-products/intel-opencl/
『Intel® SDK for OpenCL* Applications – Optimization Guide』: http://software.intel.com/sites/products/documentation/ioclsdk/2013/OG/index.htm (英語)
インテル® グラフィックス・パフォーマンス・アナライザーの Web サイト: https://www.isus.jp/article/idz/vc/intel-gpa/
謝辞
この記事のレビューに協力し、貴重な意見を寄せてくれた Brijender Bharti、Eric Sardella、Jeffrey Mcallister、Chuck DeSylva に感謝します。
著者紹介
 Tom Craver
Tom Craver
インテル コーポレーションのアプリケーション・エンジニア。現在はインテル® プロセッサー・グラフィックスにおける OpenCL* アプリケーションのパフォーマンスに取り組んでいます。ビデオ/オーディオコーデック、ビデオエフェクト処理などのメディア・アプリケーション分野において、SIMD やスレッド化による並列コードのパフォーマンス向上について幅広い経験があります。
コンパイラーの最適化に関する詳細は、最適化に関する注意事項を参照してください。
