

この記事は、インテル® デベロッパー・ゾーンに掲載されている「Full Pipeline Optimization for Immersive Video in Tencent QQ*」(https://software.intel.com/en-us/articles/full-pipeline-optimization-for-immersive-video) の日本語参考訳です。
概要
Tencent* 社 (Tencent Technology Company Ltd.) は、ビデオ会議アプリケーション QQ* のパフォーマンスを最適化し、消費電力を削減するため、インテル® Media SDK を導入しました。その結果、最大解像度 480p で低フレームレートの処理を行っていたアプリケーションが、従来の消費電力のたった 35% で最大解像度 720p、15 ~ 30fps を実現できました。さらに、4 ウェイのビデオ会議をサポートし、CPU 使用率を 80% から 20% 以下に下げ、消費電力を 14w から 6w に減らし、RAM 使用量を半分にすることができました。Z
インテル® グラフィックスのハードウェア・アクセラレーション機能により、カメラ撮影からデコード、エンコード、最終イメージの描画までパイプライン全体を最適化する手法は、ほかのメディア・アプリケーションでも利用できます。
はじめに
Tencent* QQ* は、携帯端末とコンピューター向けのインスタント・メッセージ・サービスを提供し、世界中に 10 億を超える登録ユーザーを有し、特に中国で人気があります。常時 1 億を超えるユーザーがログインし、ビデオ通話、音声チャット、リッチ・テキスト・メール、ビルトイン翻訳 (テキスト) に加えて、ファイル/写真共有を利用しています。
インターネット上のすべてのビデオと同様に、QQ* は利用可能なデータ帯域幅が十分に確保できる場合に効率良く動作できますが、ビデオ会議は双方向なのでアップリンクとダウンロードの両方の速度が重要になります。中国を含む多くの国では、アップリンク速度が 512kbps しかありません。顧客を満足させるため、Tencent* はマルチタスクに必要な CPU と RAM 帯域幅を残しつつ、優れた圧縮処理と低レイテンシーを実現しなければなりませんでした。さらに、端末が高温にならないようし、優れた電力効率を保持しつつ、利用可能な帯域幅でできるだけ高品質を提供する必要もありました。
Tencent* では、インテルのエンジニア Youwei Wang と協力して、最初にアプリケーションのボトルネックと消費電力を診断してから、データフロー・パイプラインのパフォーマンスの最適化に取り組みました。CPU と GPU を並列に利用することでパフォーマンスを向上し、メモリー処理を変更することでメモリー使用量を減らして、消費電力を大幅に削減しました。
この記事では、インテル® Media SDK とインテル® ストリーミング SIMD 拡張命令 4 (インテル® SSE4) により、インテル® プロセッサーの特別な機能を利用してアプリケーションを改善した方法を詳しく説明します。
パフォーマンスおよび電力解析ツール
データの収集と解析は、インターネットから無料のツールを入手して行うことができます。Tencent* では、以下の機能を含む Microsoft* の Windows* アセスメント & デプロイメント キット (Windows* ADK) (http://go.microsoft.com/fwlink/p/?LinkID=293840) を利用しました。
- Windows* パフォーマンス アナライザー (WPA)
- Windows* パフォーマンス ツールキット (WPT)
- GPUView
- Windows* パフォーマンス レコーダー(WPR)
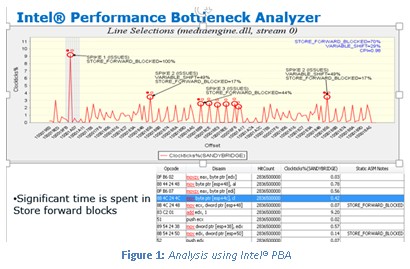
また、以下のインテル・ツールも利用しました。
- インテル® Performance Bottleneck Analyzer:
https://software.intel.com/en-us/articles/intel-performance-bottleneck-analyzer (英語) - グラフィックス・パフォーマンス・アナライザー:
https://www.isus.jp/article/idz/vc/intel-gpa/ - インテル® Power Gadget:
https://software.intel.com/en-us/articles/intel-power-gadget-20 (英語) - Battery Life Analyzer:
https://downloadcenter.intel.com/Detail_Desc.aspx?agr=Y&DwnldID=19351 (英語)
インテル® Media Software Development Kit (インテル® Media SDK)
インテル® Media SDK は、ビデオ編集/処理、メディア変換、再生、ビデオ会議機能を含むクロスプラットフォーム API です。この SDK を利用することで、第 2 世代インテル® Core™ プロセッサーを始め、最新のインテル® Celeron® プロセッサーとインテル® Atom™ プロセッサーで利用可能なインテル® HD グラフィックスのハードウェア・アクセラレーション向けにアプリケーションを最適化できます。
インテル® Media SDK は、次のような機能を提供します。
- 低レイテンシーのエンコード/デコード
- UI からフィルター設定を使用してビットレートを動的に制御:
mfxVideoParam::AsyncDepth(内部フレームバッファー処理を制限し、フレームごとの同期を強制)mfxInfoMFX::GopRefDist(B フレームの使用を停止)mfxInfoMFX::NumRefFrame(以前の P フレームのみを使用するように設定可能)mfxExtCodingOption::MaxDecFrameBuffering
(バッファーを拡張し、直ちにフレームを表示するように設定可能) - ビットレートと解像度の動的制御
- 常時、実際の帯域幅に合わせてターゲットと最大 Kbps を調整、または Constant Quantization Parameter (CQP) DataFlag により 1 フレームあたりのエンコード・ビットレートをカスタマイズ
- リファレンス・リストの選択
- クライアント側のフレーム受信時のフィードバックに応じて参照フレームを調整し、信頼性とエラーに対する柔軟性を向上
- 3 種類のリストを提供: Preferred (優先)、Rejected (拒否)、および Long Term (長期)
- 参照画像マーキングを繰り返すための SEI メッセージ
- 以前にデコードした画像の復号参照画像マーキング構文構造を繰り返すことで、フレームが失われた場合でも参照画像バッファーと参照画像リストを保持
- 長期参照
- 異なるフレームレートのレイヤーにより一時的なスケーラビリティーを提供
- MJPEG デコーダー
- H.264 エンコード/デコードとビデオ処理フィルターを高速化 NV12 および RGB4 でデコードされたビデオフレームの配信を許可
- ビットブロック転送 (blit) 処理
- 複数の入力ビデオサンプルを 1 つの出力フレームにまとめ、後処理で (描画前に) イメージバッファーにフィルターを適用し、デインターレース、色空間変換、サブストリーム・ミキシングを行うことが可能
- Microsoft* DirectX*、DirectX* ビデオ アクセラレータ (DVXA) API ベースのハードウェアにより高速化され、ソフトウェアにより最適化されたメディア・ライブラリーとプラットフォーム・グラフィックス・ドライバー
ビデオ・パイプラインの仕組み
デバイス間のビデオデータの送信は、想像以上に複雑な処理です。図 3 は、QQ* アプリがカメラ (デバイス A) からユーザーの画面 (デバイス B) へビデオデータを送信するまでの主なステップです。
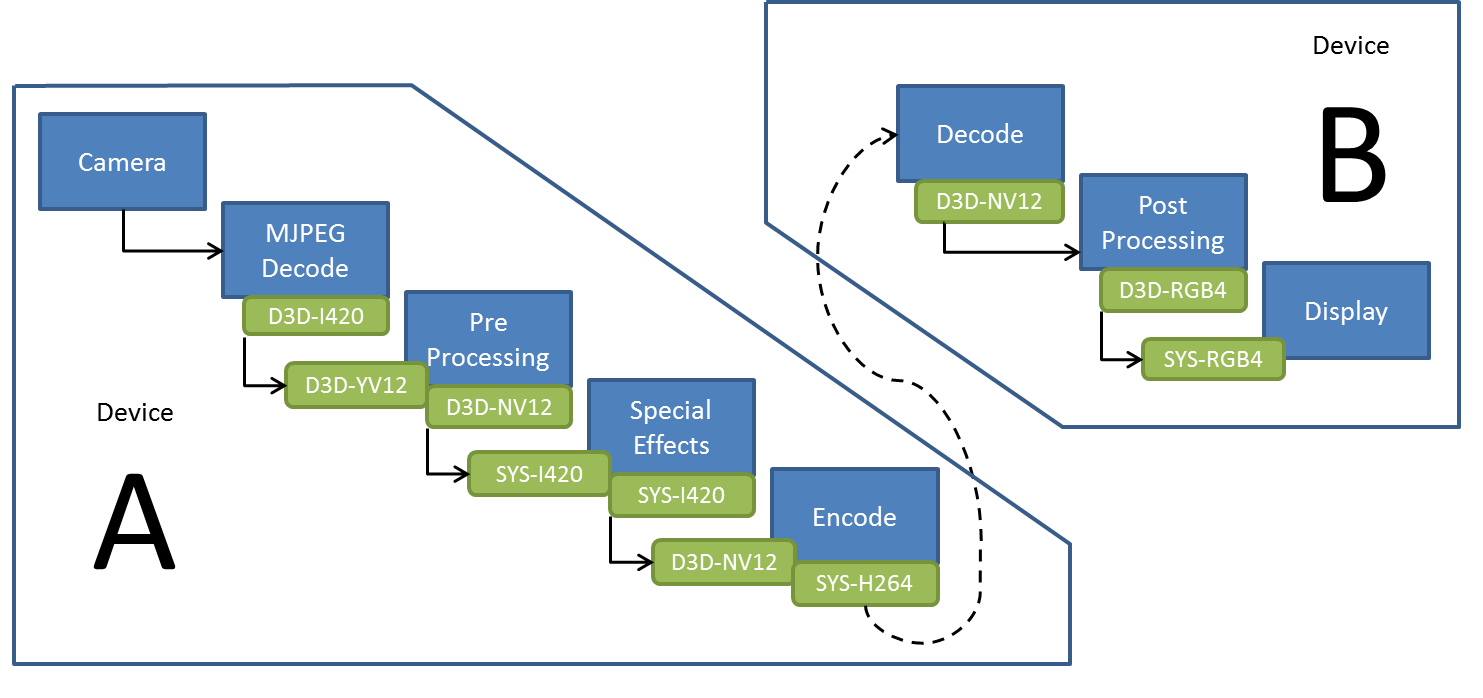
図 3: シリアル処理
図から分かるように、多くのステップでデータ・フォーマットの変換または ‘データの置き換え (swizzle)’ が必要になります。これらのステップを CPU でシリアルに処理すると、大量のレイテンシーが生じます。最適化前の QQ* アプリにはわずかながら前処理と後処理が含まれていました。しかし、個々のデータパケットは互いに独立しているため、インテル® Media SDK によりタスクを並列化し、CPU と GPU に分配して、処理フローを最適化できました。
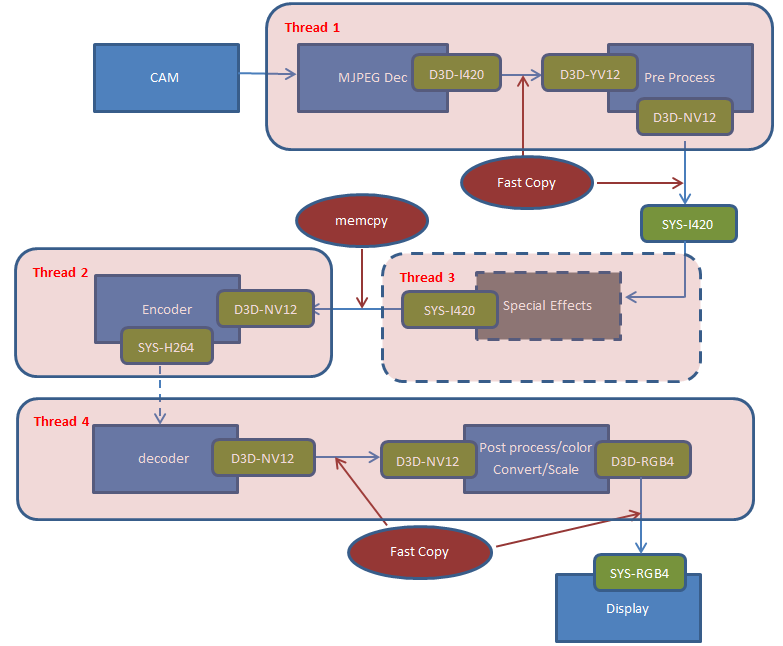
図 4: 最適化されたマルチスレッド処理フロー
SIMD 命令の変更
大幅なパフォーマンスの向上をもたらしたもう 1 つの要因は、古い SIMD 命令セット (MMX®) をインテル® ストリーミング SIMD 拡張命令 4 (インテル® SSE4) に置き換えたことです。これにより、64 ビットの浮動小数点レジスター (同時に 2 つの 32 ビット整数を処理することが可能) の代わりに 128 ビットレジスター (_mm_stream_load_si128 と _mm_store_si128 組込み関数を使用) を使用できるようになり、スループットが 2 倍になりました。レジスター幅が増えたことに加え、インテル® SSE では浮動小数点レジスターとデータ・ポイント・レジスターが分かれています。つまり、プロセッサーは 1 CPU サイクルで複数のデータセットを処理することができるため、データ・スループットと実行効率が大幅に向上します。MMX® からインテル® SSE4 への変更だけで、QQ* のパフォーマンスは 10 倍も向上しました。(インテル® SSE4 を使用して copy 関数を書き直す方法と SIMD 命令の変換の詳細は、記事の最後にある「関連情報」を参照してください。)
さらに、Tencent* は C ライブラリーを使用して各フレームの大量のメモリーコピー操作を行っていたため、HD ビデオでは処理に非常に時間がかかっていました。そこで、D3D サーフェスがすべてのセッション/スレッドを処理するように、ソフトウェア・パイプラインとハードウェア・パイプラインにのみシステムメモリーを使用するようにコードを変更しました。システムメモリーと D3D サーフェス間のコピーにインテル® SSE とインテル® アドバンスト・ベクトル・エクステンション 2 (インテル® AVX2) を使用することで、パイプラインでメモリーコピーを軽減しました。
インテル® Media SDK の動的機能の使用
エンコード時に適切なコーデックレベルを使用するための (GPU で MJPEG デコードを行うための) 変更も行いました。インテル® Media SDK の動的バッファー、動的ビットレート、動的フレームレートを使用することで、レイテンシーとバッファーの使用を軽減しました。また、ハードウェアで前処理と後処理を行うことで、効率良く圧縮できるようになり、低帯域幅ネットワークにおけるパフォーマンスが向上しました。
さらに、ユーザー・エクスペリエンスを向上するため、前処理にノイズ除去を追加し、後処理で色彩調整 (色相/彩度/コントラスト) を行うようにしました。肌色検出と顔色調整もユーザー・エクスペリエンスを大幅に向上するのに役立ちました。

図 5: 最適化された肌色
参照フレームの変更
エンコード/デコード処理の効率に関係なく、ネットワーク接続が絶え間なくデータを配信できなければ、ビデオ会議のユーザー・エクスペリエンスは低下します。データがない場合 (差分フレームが後で届く場合や紛失した場合)、デコーダーはそのフレームをスキップして新しい参照フレームに進みます。安定したビットストリーム転送には、フレームタイプの選択と正確なビットレートの制御が必要です。Tencent* では、I フレームを帯域幅の 30% に設定すると最適なバランスが取れることが分かりました。さらに、インテル® Media SDK により B フレームを排除することで、最大フレームサイズと最大バッファーサイズが向上しました。
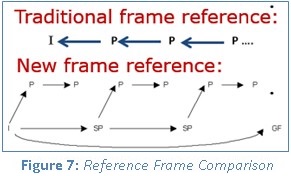
I イントラフレームと P インターフレームだけでなく、H.264 の新しい SP フレームを使用すると、イントラフレームなしで異なるビットレートのストリームを切り替えることができます。Tencent* では、P フレームと P フレームの間に SP フレームを使用することで (P フレームの重要性を下げ)、ネットワークの状態とビデオ品質の最適なバランスを動的に調整できるようになりました。
消費電力の削減
パフォーマンス向上に加えて、メモリーコピー操作、参照フレーム、後処理の変更は、アプリケーションの消費電力の削減にもつながりました。同じ作業量をより短時間で行えるようになったため、これは当然のことと言えるでしょう。Tencent* では、実際に処理を行っていない場合、プロセッサー・コアを低電力ステートに移行させることで、消費電力のさらなる削減に成功しました。消費電力テストの結果を基に、不要にプロセッサーをアクティブな状態にしているコードを見直し、変更しました。ビデオ会議アプリケーションでは、ネットワークから継続的にデータが供給されるわけではなく、画面のリフレッシュレートよりも速く新しいフレームを描画しても意味がないため、CPU を継続的に実行する必要がありません。Tencent* は、Windows* API の Sleep と WaitforSingleObject 関数を使って、短い時限付き低電力ステートを追加しました。WaitforSingleObject 関数は、ネットワークでデータを受信した場合などのイベントにより呼び出されます。図 8 は、この変更により得られた消費電力の削減結果です。
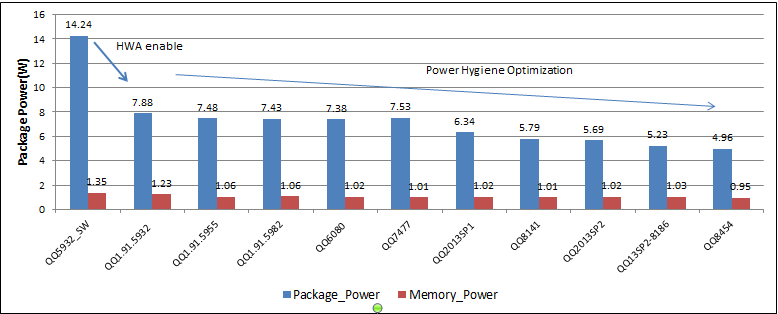
図 8: リリースごとの消費電力の推移
QQ* の改善点のまとめ
インテル® Media SDK を使用し、インテル® SSE4 命令セットに変更することで、Tencent* は QQ* アプリで次のことを改善できました。
- H.264 および MJPEG エンコード/デコードタスクを GPU へオフロード
- (可能な場合は) 前処理と後処理タスクをハードウェアへ移動
- CPU と GPU を同時に使用
- メモリーコピーを削減
- プロセッサーが高電力ステートで費やす時間を削減 (Sleep 呼び出し、WaitForSingleObject、タイマー)
- MMX® 命令をインテル® SSE4 命令に置き換え
- 最適化された参照フレームフロー

図 9: 最適化前の 640×480 と最適化後の 1280×720
まとめ
Tencent* QQ* のパフォーマンスは、インテル® Media SDK の主要機能を利用することで大幅に向上しました。QQ* は DSL 回線を利用して解像度 480p のイメージを低フレームレートで処理するアプリケーションから、同じ DSL 回線で解像度 720p のイメージを 30fps で処理し、4 ウェイのビデオ会議をサポートするアプリケーションに生まれ変わりました。
インテル® Media SDK により主な処理をハードウェアに移行した結果、QQ* の消費電力は従来の 50% になりました。そして、プロセッサーの電力ステートを最適化した結果、さらに従来の 35% の消費電力を削減することができました。この大幅な消費電力削減により、QQ* ユーザーは最適化前と比べて倍以上も長くアプリケーションを実行できるようになりました。顧客満足度を向上する一方、QQ* はインテル® Media SDK を利用することで、より高性能な (そして環境にやさしい) アプリケーションになりました。
メディア・ソフトウェア開発において、インテル® Media SDK は、限られた帯域幅でも効率良いデータフロー・パイプライン、優れたビデオ品質、ユーザー・エクスペリエンスを提供することで、アプリケーションのパフォーマンス向上とメモリー使用および消費電力の削減を支援します。インテルには、このほかにも問題やボトルネックの検出/特定を支援する各種ツールがあります。
関連情報
- インテル® Media SDK: https://www.isus.jp/article/intel-software-dev-products/intel-media-sdk/
- インテル® Media SDK の機能: https://software.intel.com/en-us/articles/video-conferencing-features-of-intel-media-software-development-kit (英語)
- インテル® Media SDK ビデオ会議サンプル: https://software.intel.com/en-us/vcsource/samples/video-conferencing-using-media-sdk (英語)
- 高速なビデオ・デコード・フレーム・バッファーのコピー: https://software.intel.com/en-us/articles/copying-accelerated-video-decode-frame-buffers (英語)
- インテル® SSE4 命令ガイド: https://software.intel.com/sites/landingpage/IntrinsicsGuide (英語)
- ooVoo* ビデオ会議のケーススタディー: https://software.intel.com/en-us/articles/oovoo-intel-enabling-hd-video-conferencing (英語)
- Windows* パフォーマンス アナライザー: http://go.microsoft.com/fwlink/?LinkID=293840
- QQ* 公式サイト: http://www.imqq.com (英語)
著者紹介
Colleen Culbertso
インテル コーポレーション デベロッパー・リレーション部門スケール・イネーブリング・チームのアプリケーション・エンジニアで、オレゴンオフィスに勤務しています。15 年以上にわたり、インテルにおいて さまざまなチームと顧客とともにコードの最適化に取り組んでいます。
Youwei Wang
インテル コーポレーション デベロッパー・リレーション部門クライアント・イネーブリング・チームのアプリケーション・エンジニアで、上海オフィスに勤務しています。10 年以上にわたり、インテルにおいて ISV とともにアプリケーションのパフォーマンスと消費電力の最適化に取り組んでいます。
テストシステム構成
一部の測定値は Tencent* により提供されました。インテル社内のデータは、第 4 世代インテル® Core™ モバイル・プロセッサーとインテル® HD グラフィックス 4400 搭載の Lenovo* Yoga 2 Pro 2-in-1 プラットフォームでの測定値です。
Intel、インテル、Intel ロゴ、Celeron、Intel Atom、Intel Core、MMX は、アメリカ合衆国および / またはその他の国における Intel Corporation の商標です。
© 2014 Intel Corporation. 無断での引用、転載を禁じます。
* その他の社名、製品名などは、一般に各社の表示、商標または登録商標です。
コンパイラーの最適化に関する詳細は、最適化に関する注意事項を参照してください。
