

この記事は、インテル® ソフトウェア・サイトに掲載されている「Deferred Mode Image Processing Framework: Simple and efficient use of Intel® multi-core technology and many–core architectures with Intel® Integrated Performance Primitives」(http://software.intel.com/en-us/articles/deferred-mode-image-processing-framework-simple-and-efficient-use-of-intel-multi-core-technology-and-manycore-architectures-with-intel-integrated-performance-primitives/) の日本語参考訳です。
はじめに
この数年でイメージセンサーの解像度は大幅に向上しましたが、イメージ処理アルゴリズムの効率はそれほど向上していません。ほぼすべてのイメージ処理アルゴリズムでは、メモリーアクセスがボトルネックになっており、イメージデータが L2 キャッシュの外部に存在する場合、アクセス時間が大幅に増加します。より多くの計算能力が利用可能であっても、イメージサイズの増加とともにキャッシュミスが増加するため、パフォーマンスを引き出すことができません。
イメージ処理アプリケーションのパフォーマンスを向上させるには、データが可能な限り L2 キャッシュに格納されることを保証した上で、L2 キャッシュサイズに相当するスライスサイズを使用してイメージ処理を並列に実行する必要があります。インテル® インテグレーテッド・パフォーマンス・プリミティブ (インテル® IPP) で利用可能な遅延モード画像処理 (DMIP) は、この課題に対する効率良いソフトウェア・ソリューションを提供します。
DMIP は、近年の (マルチコアおよびメニーコア) インテル® アーキテクチャーで利用可能な計算能力をイメージ処理タスクでフル活用できるようにインテル® IPP に追加された機能で、データ並列化とタスク並列化のフレームワークを提供します。
インテル® IPP 6.1 の DMIP
インテル® IPP 6.1 では、次のイメージ処理操作で DMIP コンポーネントをサポートしています。
- 基本的な単項および二項算術演算 (+、-、*、/、Abs、Ln、Min、Max、Sqrt、その他)
- 論理演算 (&、|、~、その他)
- しきい値演算
- イメージタイプとチャネル変換
- カラー変換
- 統計演算
- イメージフィルター:
- 汎用フィルター
- 特殊フィルター (ボックス、ミニマム、マックス、メディアン、その他)
- カーネルフィルター (Sobel、Prewitt、Schar、その他)
- モルフォロジー (エロージョン、ダイレーション)
- 線形変換 DFT/FFT
- ポリアディック計算 (引数は 5 つまで)
DMIP には、これらの操作をサポートする 30 を超える組込みノードが用意されており、さまざまなデータ型やカラーチャネルの約 1800 のアトム操作 (IPP 関数) をイメージ処理タスクに利用できます。組込みノードに加えて、ユーザー定義ノードを DMIP に追加することができます。
DMIP の動作を確認するため、単純なイメージ処理タスク (微分オペレーターを使用したエッジ検出) について考えてみましょう。
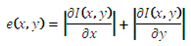
I(x,y) はソースイメージで、e(x,y) は検出されたエッジを含むデスティネーション・イメージです。このケースでは、ソースイメージは 3 チャンネル 8 ビットのイメージで、出力イメージは 8 ビットのグレースケール・イメージであるため、ソースイメージのカラー変換が必要になります。偏微分の計算には、Sobel オペレーターを使用します。
まず最初に、次のインテル® IPP コードによる Sobel オペレーターのエッジ検出器を考えてみます。
IppiSize roi; // 入力イメージと出力イメージのサイズ Ipp8u* pSrcImg; int srcImgStep; // 入力 C3, 8u イメージ (IPP イメージ・フォーマット) Ipp8u* pDstImg; int dstImgStep; // 出力 C1, 8u イメージ (IPP イメージ・フォーマット) Ipp8u* pGrayData; int grayDataStep; // 入力グレースケール・イメージ Ipp16s* pIntBuffer; int IntBufferStep; // 中間バッファー Ipp8u* pSBuffer; int SBufferSize; // Sobel 操作の一時メモリー // グレースケール変換したイメージのメモリーを割り当てる pGrayData = ippiMalloc_8u_C1(roi.width,roi.height,&NewSrcStep); // 一時フィルターのメモリーを計算して割り当てる ippiFilterSobelHorizGetBufferSize_8u16s_C1R(roi,ippMskSize3x3,&SBufferSize); ippiFilterSobelVertGetBufferSize_8u16s_C1R(roi,ippMskSize3x3,&SBufferSize); SBufferSize = SBufferSize < SBufferSize1 ? SBufferSize1 : SBufferSize; pSBuffer = ippsMalloc_8u(SBufferSize); // 中間バッファーのメモリーを割り当てる // イメージサイズの 2 倍のサイズで、dx と dy の格納に使用 pIntBuffer = ippiMalloc_16s_C1(roi.width,roi.height*2,&IntBufferStep); // 入力イメージをグレースケール・イメージに変換 ippiRGBToGray_8u_C3C1R((const Ipp8u*)pSrcImg, srcImgStep, pGrayData, grayDataStep, roi); // dx を計算 ippiFilterSobelHorizBorder_8u16s_C1R((const Ipp8u*) pGrayData, grayDataStep, IntBuffer, IntBufferStep, roi, ippMskSize3x3, ippBorderRepl, 0, pSBuffer); // dy を計算 ippiFilterSobelVertBorder_8u16s_C1R((const Ipp8u*) pGrayData, grayDataStep, pIntBuffer+roi.height*(IntBufferStep/2), IntBufferStep, roi, ippMskSize3x3, ippBorderRepl, 0, pSBuffer); // dx と dy の絶対値をとる ippiAbs_16s_C1IR(pIntBuffer, IntBufferStep, roi);ippiAbs_16s_C1IR(pIntBuffer+roi.height*(IntBufferStep/2), IntBufferStep, roi); // 絶対値を追加してエッジを検出 ippiAdd_16s_C1IRSfs((const Ipp16s*) pIntBuffer+roi.height*(IntBufferStep/2), IntBufferStep, pIntBuffer,IntBufferStep, roi, 0); // イメージとエッジを変換 (dst イメージ・フォーマット) ippiConvert_16s8u_C1R( pIntBuffer, IntBufferStep, (Ipp8u*)pDstImg, dstImgStep, roi ); // リソースを解放 ippiFree(pGrayData); ippiFree(pIntBuffer); ippsFree(pSBuffer);
リスト 1. インテル® IPP の Sobel エッジ検出器コード
このアプローチは、イメージ全体の処理に、高度に最適化され、並列化されたインテル® IPP 関数を使用します。dx と dy の計算を格納する 2 つの中間バッファーが必要になるため、中間メモリーはイメージサイズに比例して大きくなります。操作はそれぞれ独立して行われ、各操作が完了した後にインテル® IPP の内部スレッドが同期されます。リスト 1 の Sobel エッジ検出器には、タスクごとに 7 つの同期ポイントがあり、大量のキャッシュミスが発生しています。
キャッシュミスを最小限に抑えてパフォーマンスを向上させるため、DMIP で同じタスクを実行します。図 1 は、Sobel エッジ検出器のタスクグラフを示しています。グラフの円は操作を、矢印はデータフローを表します。
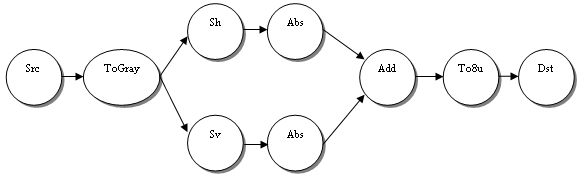
図 1. Sobel エッジ検出器のタスクグラフ
リスト 2 は、シンボリック API の DMIP コードを示します。
Image Src(pSrcImg, Ipp8u, IppC3…); // ソースイメージ (DMIP フォーマット) Image Dst(pDstImg, Ipp8u, IppC1…); // デスティネーション・イメージ (DMIP フォーマット) Kernel Kh(idmFilterSobelHoriz,ippMskSize3x3,ipp8u,ipp16s); // dx オペレーター Kernel Kv(idmFilterSobelVert,ippMskSize3x3,ipp8u,ipp16s); // dy オペレーター Graph O = ToGray(Src); // 一般式として検出 // コンパイルしてタスクを実行 Dst = To8u(Abs(O*Kh)+ Abs(O*Kv));
リスト 2. Sobel エッジ検出器の DMIP 実装
デフォルトで、DMIP エンジンは L2 キャッシュに収まる最適なスライスサイズを決定します。開発者が必要な設定に合わせて最適なスライスサイズに変更することもできます。リスト 3 は、個別のコンパイルと実行プロセスにシンボリック API を使用して、入力イメージのスライスサイズの制御とスレッド数の制限を行う DMIP コードを示しています。
Image Src(pSrcImg, Ipp8u, IppC3…); // ソースイメージ (DMIP フォーマット) Image Dst(pDstImg, Ipp8u, IppC1…); // デスティネーション・イメージ (DMIP フォーマット) Kernel Kh(idmFilterSobelHoriz,ippMskSize3x3,ipp8u,ipp16s); // dx オペレーター Kernel Kv(idmFilterSobelVert,ippMskSize3x3,ipp8u,ipp16s); // dy オペレーター Graph O = ToGray(Src); // 一般式として検出 // タスクグラフのビルド Graph G = (To8u(Abs(O*Kh)+ Abs(O*Kv))) >> Dst; // コンパイル G.Compile(slice size); // タスクを実行 G.Execute(threads number);
リスト 3. 修正後の DMIP Sobel エッジ検出器
DMIP は、コンパイラーを使用してイメージを小さなデータ部分 (スライス) に分割した後、リスト 1 と同じインテル® IPP 関数を呼び出します。コンパイルプロセスと実行プロセスについては、論文「Deferred Image Processing in Intel® IPP Library」(2008 年の Computer Graphics and Imaging Conference で発表) および記事「A Landmark in Image Processing: DMIP」(http://software.intel.com/en-us/articles/a-landmark-in-image-processing-dmip/) の説明を参照してください。
ここで、イメージ処理タスクを確認しましょう。イメージ処理は、フィルターで始まり (Flt 操作)、フィルターされたデータ型を符号なし char に変換します (To8u 操作)。「Src」はソース・イメージ・バッファーからの読み取り操作を指し、「Dst」はデスティネーション・イメージ・バッファーへの書き込み操作を指します。図 2 に示されているように、並列実行アルゴリズムは、スライスをサブスライスに分割して、利用可能な CPU でサブスライスを並列に処理できるようにします。DMIP はスレッドの依存性を解析しないため、データ競合状態を回避するには、各操作の後でスレッドを同期しなければなりません。
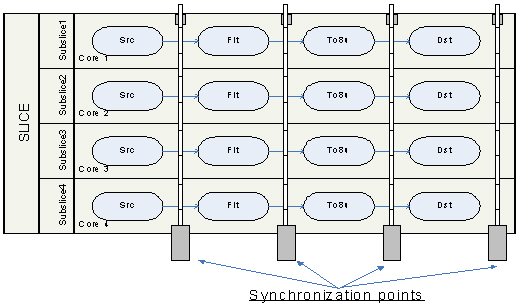
図 2. 並列スライス実行
グラフ最適化手法
この DMIP アルゴリズムのパフォーマンスを解析したところ、図 2 の並列スライス実行は、2 コアのシステムでは効率良く動作しましたが、同期ポイントが増加する 4 コア以上のシステムではスケールしませんでした。前の例では、並列スライス実行中に、スライスあたり 9 個 (8 個は中間、1 個はスライス間) の同期ポイントがあるため、タスクあたりの同期ポイントは 9 x スライス数になります。アルゴリズム解析全体に DMIP のグラフ最適化手法を使用することで、同期ポイントの数が減り、マルチコアおよびメニーコアシステムのパフォーマンスが大幅に向上します。
DMIP は、タスク全体の解析にグラフの内部表現を使用した、4 レベルのグラフ最適化を行います。各レベルは特定のワークロード用に設計されており、一般に、同期ポイントの数を減らすことを目的としています。DMIP は、最適化モードの開発中に、タスクグラフで制限のない有向非巡回グラフとして表現される、任意のイメージ処理タスクを実行するように設計されました。
DMIP のグラフ最適化は次のモードをサポートしています。
0. ノーマルモード - 単純な並列実行です。図 2 を参照してください。
1. ライト最適化モード - ノードのリニアチェーンで分岐を抽出します。
2. ミディアム最適化モード - マルチレイヤー形式でグラフを表現して、独立している操作またはローカルに独立している操作を抽出します。このモードは、タスク並列用の操作を提供します。
3. ハイ最適化モード - グラフレイヤーをマージします。
4. アグレッシブ最適化モード - スライス間の同期ポイントを削除します。
ノーマルモード (0) では、タスクはそのまま (つまり、各操作の後に同期されてシーケンシャルに) 実行されます。
ライト最適化モード (1) では、DMIP グラフ・コンパイラーはノードのチェーンを抽出し、チェーンを組み合わせてコンテナー (スーパーノード) に格納します。抽出されたリニアチェーンのノードは、中間同期なしで、ノードの数および同期ポイントの数を減らして実行されます。Sobel エッジ検出器の例では、4 つのリニアチェーンが抽出されます。
1. Src->ToGray
2. Sv->Abs
3. Sh->Abs
4. Add->To8u->Dst
これには、制限が 1 つあります。フィルター操作は、(サブスライス・レベルで完全に処理されたデータスライスをフィルターする前に、境界ピクセルを準備する必要がある) リニアチェーンの最初のノードでなければなりません。
ミディアム最適化モード (2) では、DMIP グラフ・コンパイラーは、リニアチェーンを使用してローカルに独立している操作 (つまり、レイヤー) を抽出します。同じレイヤーのノードはすべて独立しているため、各ノードを 1) 並列 (タスクの並列化) または 2) シーケンシャルに同期ポイントなしで実行できます。タスク実行手法はターゲットのマイクロアーキテクチャーに依存します。モード (2) では、タスクの高さとタスクの幅という 2 つの重要なタスク特性が採用されています。
定義: タスクの高さ - レイヤーの数。
定義: タスクの幅 - レイヤー内の最大ノード数。
定義: 小さなタスク - タスクの幅が 1。
より広く平坦なグラフはより並列に処理できるため、シーケンシャル・コードを減らすことができます。小さなタスクはタスク内に並列領域がないため、モード (2) を使用してスピードアップできません。Sobel エッジ検出器の例では、タスクの高さは 3 で、タスクの幅は 2 です。最初の SuperNode、Src->ToGray は最初のレイヤーに属しています。2 番目と 3 番目の SuperNode、Sv->Abs および Sh->Abs は 2 番目のレイヤーに属し、2 つのタスク並列領域を形成しています (図 1 を参照)。最後の SuperNode、Add->To8u->Dst は 3 番目のレイヤーに属しています。
ほかの 2 つのグラフ最適化モード (ハイおよびアグレッシブ) は通常、「小さな」タスクのスピードアップに利用されます。これらのモードの実行中に、タスクのフィルター操作の使用が解析され、マージできるレイヤーと、中間スレッド同期なしでスライスを実行できるかどうかが決定されます。
グラフの最適化モードを制御する DMIP API:
// 最適化モードを設定 idmStatus Control::SetGraphOptLevel(int level); // 現在のグラフ最適化モードを取得 int Control::GetGraphOptLevel(void);
各 DMIP モードで達成できるパフォーマンスはワークロードのグラフ構成に依存します。場合によっては、特にピクセル単位のワークロードでは、タスクは中間同期ポイントなしで実行できます。図 3 は、各 DMIP 最適化モード用に実装された Sobel エッジ検出器の同期ポイントの数を比較したものです。図 4 は、アグレッシブ最適化モードで実装された Sobel エッジ検出器のスピードアップを示しています。
| モード | 同期ポイント数 |
| ノーマル | スライスあたり 9 個 |
| ライト | スライスあたり 4 個 |
| ミディアム | スライスあたり 3 個 |
| ハイ | スライスあたり 2 個 |
| アグレッシブ | スライスあたり 1 個 |
図 3. モード別の中間同期ポイント数
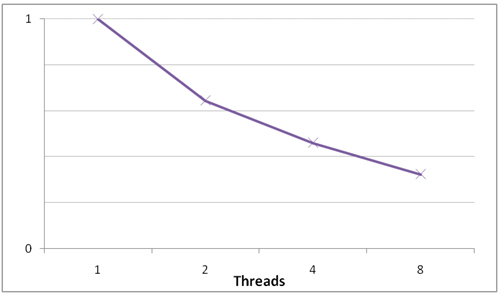
図 4. アグレッシブ最適化モードを使用した Sobel エッジ検出器のスピードアップ
グレースケール入力イメージの場合、グラフ実行の前にイメージ境界ピクセルを準備すると、Sobel ベースのエッジ検出器のパフォーマンスが向上していることが分かります。
Image SrcI(pSrcImg, Ipp8u, IppC1…); // ソースイメージ (DMIP フォーマット) Image DstI(pDstImg, Ipp8u, IppC1…); // デスティネーション・イメージ (DMIP フォーマット) Kernel Kh(idmFilterSobelHoriz,ippMskSize3x3,ipp8u,ipp16s); // dx オペレーター Kernel Kv(idmFilterSobelVert,ippMskSize3x3,ipp8u,ipp16s); // dy オペレーター SrcI.CopyBorder(…); // イメージの境界を作成 Graph O = Src(SrcI); // 一般式として検出 // コンパイルしてタスクを実行 DstI = To8u(Abs(O*Kh)+ Abs(O*Kv));
この例では、事前に計算された境界ピクセルを含むフィルターノードを SrcNode の直後に実行しているため、アグレッシブ最適化モードは中間同期ポイントなしでタスク全体を実行します。
DMIP タスクの例
インテル® IPP の DMIP コンポーネントには、インテル® IPP を使用した従来のタスク実装に対する DMIP の利点を示す、単純なコンソールベースの例 "dmip_bench" が含まれています。DMIP ワークロードの 1 つは、最適化の点から下記のように見なされます。
Harmonization フィルター
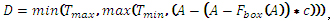
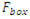 はボックスフィルター、
はボックスフィルター、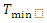 および
および 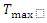 はしきい値、c は定数。
はしきい値、c は定数。
DMIP コード:
Image A(…); // ソースイメージ (DMIP フォーマット) Image D(…); // デスティネーション・イメージ (DMIP フォーマット) Kernel K(idmFilterBox,…); // ボックスフィルターのカーネル Ipp32f c;Ipp8u Tmax, Tmin; Graph O = To32f(A); // 一般式として検出 // コンパイルしてタスクを実行 D = Max(Min(To8u(O-(O-O*k)*c),Tmax),Tmin);
このタスクには 3 つのリニアチェーンがあります。最も長いリニアチェーン内部のノードの数は 5 操作です。タスクの幅が 1 でタスクの高さが 4 のローカルに独立した操作がない小さなタスクであるため、ミディアム最適化モードではメリットが得られません。ボックスフィルターは 2 番目のレイヤーに存在するため、スライス間の最適化は実行できません。ハイ最適化モードを使用すると、ボックスフィルター操作後の同期ポイントが削除され、スライスあたりの同期ポイントが 1 つになるため、図 5 に示すようにタスクがスピードアップします。
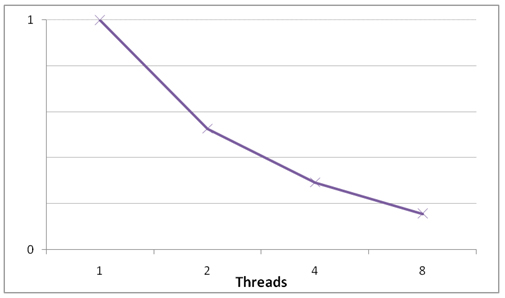
図 5. ハイ最適化モードを使用した Harmonization フィルターのスピードアップ
指数明るさ補正
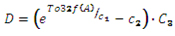
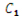 、
、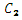 、
、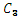 は定数。
は定数。
このタスクには、グラフに操作をすべて組み込んだ 1 つのリニアチェーンがあります。タスクの幅が 1 でタスクの高さが 1 の小さなタスクであるため、前のタスクと同様に、ミディアム最適化モードではメリットが得られません。ピクセル単位タスクであるため、スライス間の依存性はありません。アグレッシブ最適化モードを使用すると、スライスあたりの同期ポイントはゼロで、タスクのスピードアップは図 6 のようになります。
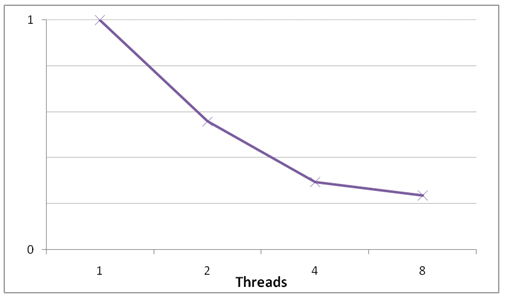
図 6. アグレッシブ最適化モードを使用した指数明るさ補正操作のスピードアップ
セピアトナー
セピアフィルターは、次の式に従ってピクセル値を計算します。
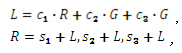
R、G、B はピクセル・カラー・トリプレット。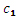 、
、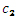 、
、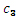 はカラー変換係数。
はカラー変換係数。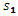 、
、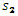 、
、 はセピア・トーン・カラー。
はセピア・トーン・カラー。

図 7. 元のイメージ (左) とセピア化されたイメージ (右)
このタスクには、グラフに 3 つの操作をすべて組み込んだ 1 つのリニアチェーンがあります。タスクの幅が 1 でタスクの高さが 1 の小さなタスクであるため、ミディアム最適化モードではメリットが得られません。ピクセル単位タスクであるため、スライス間の依存性はありません。アグレッシブ最適化モードではスライスあたりの同期ポイントがゼロになります。このタスクでは、スライスサイズ (バイト) は、RGB からグレースケール、およびグレースケールから RGB へのイメージ変換中の操作ごとに変更されます。各スライスで、操作の半分は利用可能なキャッシュサイズの 1/3 を使用します。
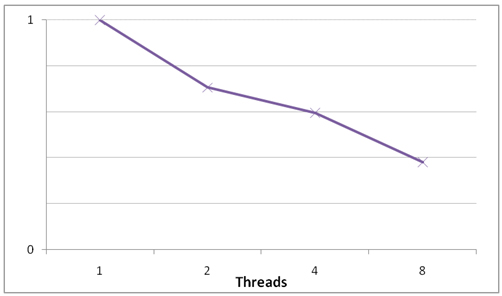
図 8. アグレッシブ最適化モードを使用したセピアトナーのスピードアップ
分離可能な 2D FFT
すべてのイメージ操作が DMIP フレームワークで効率良く処理する準備ができているとは限りません。DMIP は、操作を効率的に再構築するさまざまな手法をサポートしています。例えば、ヒストグラム計算では、プロローグ、蓄積、エピローグフェーズの抽出が必要です。DMIP の 2D FFT 変換は、列の 1D FFT 計算、転置、行 (転置した列) の 1D FFT 計算の 3 つの部分からなる、分離可能な方法で実装されます。この計算構造は、縦の FFT 計算中のメモリーの移動を減らすためにパイプラインを使用します。図 9 は、スレッド化されたインテル® IPP プリミティブを使用した DMIP 2D FFT 変換のパフォーマンスの比較を示しています。
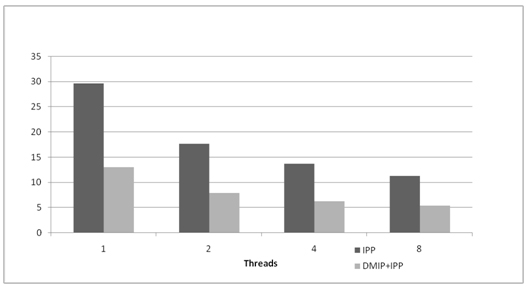
図 9. 2D 順方向 FFT 変換のスピードアップ。インテル® IPP と DMIP+インテル® IPP、要素あたりの CPU クロック数 (クロック数の少ないほうがパフォーマンスが高い)
アーキテクチャー・トポロジーの利用
効率良い操作のため、DMIP はマイクロプロセッサーで検出された利用可能な情報 (CPU の種類、物理コアの数、インテル® ハイパースレッディング・テクノロジー (インテル® HT テクノロジー) の有無、同じキャッシュを共有するコアの数、その他) を使用します。例えば、スライスサイズは、キャッシュサイズや同じキャッシュを共有するスレッド数の情報を使用して設定されます。
DMIP は常に、キャッシュから退避するデータとフルキャッシュ/コア使用のバランスをとります。スレッド・アフィニティーは、スレッド・コンテキスト保存/復元および OS スレッド・マイグレーションのコストを最小限に抑えるために使用されます。各作業スレッドは、キャッシュ間のデータ・マイグレーションを最小限にするため、対応するコアに割り当てられます。例えば、2 ソケットのインテル® Core™2 Quad プロセッサー・ベースのアーキテクチャーは、8 つの物理コアがあるため、DMIP 作業スレッドは連続する順でコアに割り当てられます。
インテル® Core™ i7 マイクロプロセッサーは、インテル® HT テクノロジーが有効な 4 つの物理コアがあるため、8 つのハードウェア・スレッドをサポートします。ただし、このプロセッサーでは、DMIP はすでに高度に最適化されており、インテル® HT テクノロジー・スレッドを利用してもパフォーマンスが向上しないため、DMIP は 4 スレッドのみ使用します。
インテルでは、インテル® IPP のトポロジー抽出用 API の追加を計画しており、インテル® IPP の将来のリリースでサポートする予定です。
メニーコア・アーキテクチャーの課題
将来のインテル® アーキテクチャーでは 8 コア以上が主流になる見込みです。ほかのメニーコア・アーキテクチャーと同様に、現在開発中のメニーコアおよびマルチスレッド対応のビデオカードでは、大幅に改善されたスレッド同期と DMIP 内部処理データユニット型 (スライスまたはタイル) をサポートするため、少し異なる並列化アプローチが必要になります。スライスによるパイプライン処理がメニーコア・アーキテクチャーの一部のタスクに適していない場合、DMIP が最高のパフォーマンスを達成できるように、タスクの並列領域を抽出して、並列領域の実行にすべてのスレッドを使用します。
小さなタスク (大きなタスク) は、スライスベースのパイプラインからタイルベースのパイプラインに移行するほうが効率的です。これは、同期ポイントの数が最小限でタスクの高さと等しくなるためです。アトミック・データ・ユニットとしてのタイルでは、処理する独立した操作の数は増え、動的スレッドのロードバランスが必要になります。
まとめ
インテル® IPP の DMIP ライブラリーは、イメージ処理タスクにおいて効率良くマルチコア/メニーコア・アーキテクチャーを利用するソリューションを提供します。メニーコア・アーキテクチャーでタスクを高速化するようにアルゴリズム解析を行い、最も効率的な方法で利用可能なコアをすべて利用します。また、イメージ処理アプリケーションの開発、最適化、並列化を簡素化する、直感的な API を提供します。
オンラインリソース
- インテル® IPP Web サイト:
(http://software.intel.com/en-us/articles/intel-integrated-performance-primitives-support-resources/) (英語) - インテル® IPP フォーラム:
(http://software.intel.com/en-us/forums/intel-integrated-performance-primitives/) - インテル® IPP の DMIP マニュアル (dmipman.pdf): インテル® IPP 製品に含まれています。
- インテル® IPP の DMIP トレーニング資料
(http://software.intel.com/en-us/articles/deferred-mode-image-processing-in-Intel-ipp/) (英語) - Dr. Dobb's Journal 2009/4/26。Intel's Integrated Performance Primitives and Deferred Mode Image.(http://www.ddj.com/217100379?cid=RSSfeed_DDJ_All) (英語)
著者紹介
Igor Belyakov: ソフトウェア & サービスグループ (SSG) のインテル® IPP エンジニアリング・チームのソフトウェア・エンジニアで、マルチコア/メニーコア・アーキテクチャーにおけるイメージ処理アルゴリズムとコンピューター・ビジョン・アルゴリズムの自動最適化/並列化を専門とする DMIP プロジェクトのテクニカルリーダーです。スピーチ・コーディング・チームにも属しており、スピーチコーディングとリアルタイム・メディア・データ転送プロトコルスタックのエキスパートでもあります。モスクワ州立大学機械数学部で数学の修士号を取得しています。
Bonnie Aona: ソフトウェア & サービスグループ (SSG) のインテル® コンパイラー/言語グループのソフトウェア・エンジニアで、最新のインテルのソフトウェアおよびハードウェア機能を活用してハイパフォーマンスな並列処理を達成するため、アプリケーションの最適化とテストに取り組んでいます。これまで、コンピューター・グラフィックス、リアルタイム・システム、科学研究、製造、e コマース、航空宇宙、ヘルスケア向けの複雑なハイパフォーマンス・アプリケーションのソフトウェア設計を含むソフトウェア品質保証およびプログラム管理に携わってきました。カリフォルニア大学デービス校で電子情報工学の修士号を取得しています。
