
この記事は、インテル® デベロッパー・ゾーンに公開されている「Workflow for a CUDA* to SYCL* Migration」の日本語参考訳です。原文は更新される可能性があります。原文と翻訳文の内容が異なる場合は原文を優先してください。
概要
基本ワークフローを使用して、CUDA* アプリケーションのコードベース全体を SYCL* に移行し、インテル® GPU カーネル向けにコードを最適化します。
対象者
CUDA* 開発に精通しているソフトウェア開発者。
必要条件
インテル® デベロッパー・クラウド (英語) にアクセスできる必要があります。インテル® デベロッパー・クラウドは、インテル® GPU とインテル® oneAPI ソフトウェア・ツール (インテル® oneAPI ベース・ツールキットなど) にアクセスできる無料の仮想サンドボックスです。
ローカルの開発システムを使用する場合、以下が必要です。
インテル® GPU。「インテル® oneAPI ベース・ツールキットによる GPU アプリケーションの最適化」を参照してください。
インテル® oneAPI ベース・ツールキット (ベースキット)。ベースキットは、多様なアーキテクチャー向けにハイパフォーマンスなアプリケーションを開発するコアツールとライブラリーを提供します。CUDA* ソースの移行を支援するインテル® DPC++ 互換性ツール (インテル® DPCT) が含まれています。
移行に役立つ情報は、「CUDA* から C++ with SYCL* へのコード移行」を参照してください。
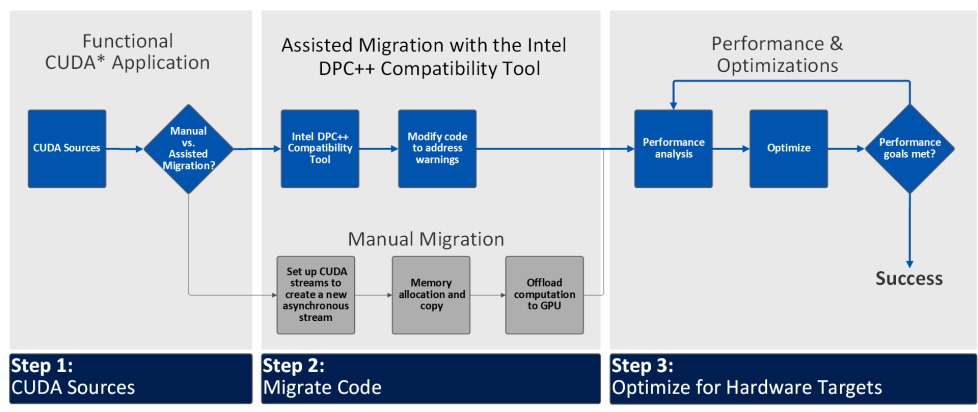
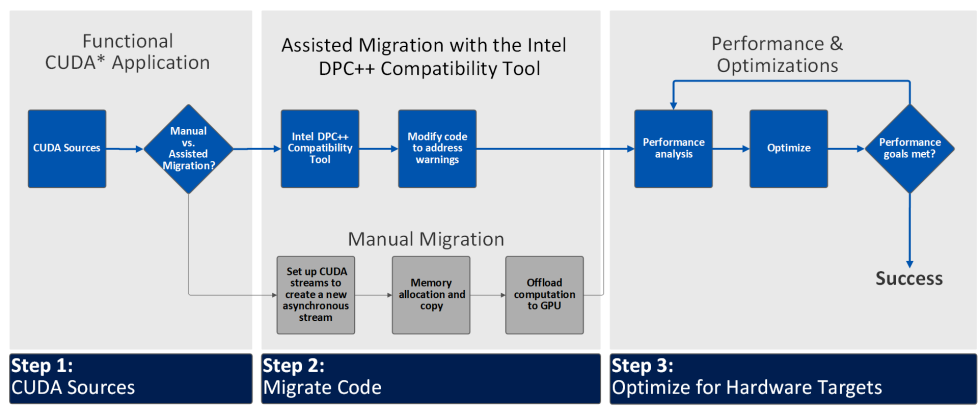
移行ワークフロー
ステップ 1: CUDA* ソースの移行方法を決定する
ステップ 2: コードを移行する
ステップ 3: ターゲット・ハードウェア向けに最適化する
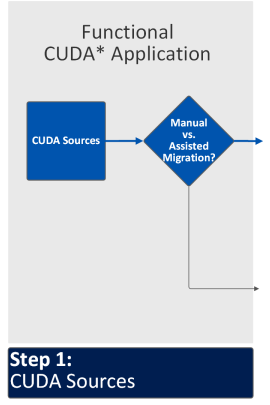
ステップ 1: CUDA* ソースの移行方法を決定する
|
|
SYCL* に移行するには、CUDA* アプリケーションが問題なく動作することを確認します。CUDA* ソースは、次のいずれかの方法で移行できます。
インテル® DPCT は通常、コードの 90% ~ 95% を移行し、移行を完了するため手作業が必要なコード領域について警告を生成します1。 インテル® DPCT は <dpct/dpct.hpp> ヘッダーファイルで定義されたヘルパー関数を使用します。これは、一部の SYCL* 呼び出しが dpct ヘルパー関数を補助するため追加のレイヤーでラップされているためです。手動で移行した SYCL* コードでは、CUDA* 呼び出しに直接マップされた SYCL* 呼び出しと構文が使用されます。 単純な Vector Add サンプル (英語) をダウンロードして、移行してみてください。 1 2021年9月現在のインテルによる推定。Rodinia、Scalable Heterogeneous Computing (SHOC)、Pennant など、70 種類の HPC ベンチマークとサンプルの測定結果に基づいています。結果は異なることがあります。 |
ステップ 2: コードを移行する
|
|
このステップでは、手動またはインテル® DPCT を使用してソースコードを SYCL* に移行します。移行が完了したら、SYCL* ソースコードの開発作業を続行します。 |
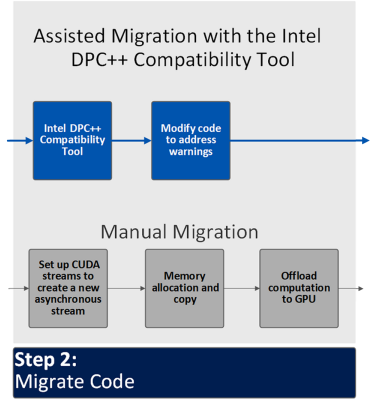
インテル® DPCT を使用した移行
インテル® DPCT を使用して、既存の CUDA* コードを SYCL* に移行します。このツールは、CUDA* 言語カーネルとライブラリー API 呼び出しを移植し、CUDA* コードの大部分を多様なアーキテクチャーとベンダーに移植可能な SYCL* コードに移行します。
サンプルコードで学ぶ
CUDA* ソースの移行方法を決定するため、以下のリソースを利用できます。
Jacobi サンプルの移行ガイド: ヤコビ反復法の CUDA* から SYCL* への移行 (英語)。
移行プロセスと CUDA* から SYCL* へのマッピングの説明と、移行の詳細な分析が得られます。
オリジナルの CUDA* ソースコード: JacobiCUDAGraphs.zip (英語)。
インテルが提供する移行された SYCL* ソースコード: Jacobi 反復法ソルバー (英語)。
サンプルには、ワークフローの各段階の状態を反映した個別のソースが含まれています。
注: SYCL* の詳細とインテル® DPCT によるソースコードの変更については、「ヤコビ反復法の CUDA* から SYCL* への移行」 (英語) を参照してください。Jacobi サンプルを使用した CUDA* と SYCL* のマッピングの技術的な詳細について説明しています。
手動による移行
手動で移行した SYCL* コードは、CUDA* 呼び出しに直接マップされた SYCL* 呼び出しと構文を使用します。この方法は、クリーンで理解しやすい移行コードを提供します。CUDA* コードと SYCL* コードの機能はほぼ同じです。
SYCL* の詳細とインテル® DPCT によるソースコードの変更については、「ヤコビ反復法の CUDA* から SYCL* への移行」 (英語) を参照してください。CUDA* と SYCL* の基本概念、およびコードの移行に不可欠な用語を説明しています。
オフロード、非同期ストリームの設定、メモリー割り当てとコピーの手順は共通ですが、実際の作業はオフロード計算で行われます。CUDA* と SYCL* は、GPU 上で動作するオフロードカーネルの作成に関する基本的な概念を共有しています。類似点と相違点を考慮して以下の概念をマッピングすると、SYCL* 構文が理解しやすいでしょう。
- CUDA* スレッドブロックと SYCL* ワークグループ
- 共有ローカルメモリー (SLM) アクセス
- CUDA* スレッドブロックと SYCL* バリア同期
- CUDA* 協調グループと SYCL* サブグループ
- CUDA* ワープ・プリミティブと SYCL* グループ・アルゴリズム
- CUDA* と SYCL* のアトミック操作
関連情報
ステップ 3: ターゲット・ハードウェア向けに最適化する
|
|
この時点で、コードはコンパイルして実行できます。インテル® VTune™ プロファイラーやインテル® Advisor などのインテルのツールを使用して、移行したコードをインテル® GPU 向けに最適化します。これらのツールは、アプリケーションのパフォーマンスを最適化するため改善すべきコード領域を特定するのに役立ちます。どちらのツールにも、最適化戦略を視覚化するのに役立つグラフィカル・ユーザー・インターフェイスがあります。 |
インテル® VTune™ プロファイラーを使用したパフォーマンス解析
インテル® VTune™ プロファイラーを使用して、アプリケーション・パフォーマンス・ベースラインのスナップショットを作成し、詳しく解析する領域を特定します。
次の操作を行います。
- GPU 解析用にシステムを設定 (英語) します。
- インテル® VTune™ プロファイラーのコマンドライン・インターフェイスを起動 (英語) します。
- パフォーマンス・スナップショット解析を実行 (英語) します。
- 結果を表示します。
インテル® Advisor を使用したルーフライン解析
インテル® Advisor を使用して、GPU ルーフライン解析でオフロードコードの実際のパフォーマンスを測定します。CPU コードを評価して、パフォーマンスがハードウェアの最大能力にどれぐらい近づいているか確認できます。
次の操作を行います。
- GPU カーネルを解析するため環境を設定 (英語) します。
- ルーフライン解析を実行 (英語) します。
- 結果を確認してハードウェア・モデルに基づいてスループットを評価 (英語) します。
注: Jacobi サンプルの詳細は、「ヤコビ反復法の CUDA* から SYCL* への移行」 (英語) の「Tools for Performance Analysis」を参照してください。GitHub* にある Jacobi サンプルでは、sycl_migrated_optimized が最適化ステップの出力です。
関連情報
