

この記事は、インテル® デベロッパー・ゾーンに公開されている「A Walk-Through of Distributed Processing Using Intel® DAAL」(https://software.intel.com/en-us/articles/a-walk-through-of-distributed-processing-using-intel-daal/) の日本語参考訳です。
概要
インテル® Data Analytics Acceleration Library (インテル® DAAL) は、データマイニング、統計分析、およびマシン・ラーニング・アプリケーションを対象とした新たな高度に最適化されたライブラリーです。オフライン、ストリーミング、および分散分析向けにすべてのデータ分析ステージ (前処理、変換、分析、モデル化、意思決定) をサポートする高度なビルディング・ブロックを提供します。インテル® DAAL は、MPI ベースのクラスター環境、Hadoop*/Spark* ベースのクラスター環境、低レベルデータ交換プロトコルなどを含む、各種クラスター・プラットフォームで分散データ分析をサポートします。
Apache Spark* は、ラージスケール・データ処理向けの高速で最も人気のあるビッグデータ・プラットフォームです。ユーザープログラムがデータをクラスターの分散メモリーへロードし、繰り返し照会することを可能にすることで、Spark* はマシンラーニングのアルゴリズムに適しています。この記事は、インテル® DAAL パッケージの samples/spark フォルダーにある主成分分析 (PCA) サンプルを通して、インテル® DAAL を使用して Spark* クラスター上で分散データ分析を行う方法を説明します。
ソフトウェア: インテル® DAAL 2016、Hadoop* v2.1.0、Apache Spark* v1.2.0
ハードウェア: 1 ドライブノード + 4 サーバーノード
ドライブノード: インテル® Xeon® プロセッサー E5-2680 @ 2.70GHz、2×8 コア x2 (HT 有効)、計 32 論理プロセッサー、128GB RAM
サーバーノード: インテル® Xeon® プロセッサー E5-2699 @ 2.30GHz、45MB LLC、2×18 コア x2 (HT 有効)、計 72 論理プロセッサー、ノード当たり 128GB RAM
オペレーティング・システム: Ubuntu* 12.04.2 LTS x86_64
主成分分析 (Principal Component Analysis – PCA) サンプル
インテル® DAAL は、広範囲なインテル® アーキテクチャー (IA) ベースのシステム向けに高度に最適化された事前ビルド済みアルゴリズムによって、データ分析問題を解決します。伝統的なバッチ処理モードに加え、インテル® DAAL はストリーミング処理と分散データ処理に特化した機能をサポートします。現在のリリースに含まれるストリーミングと分散処理のアルゴリズムは、統計モーメント、分散共分散行列、特異値分解 (SVD)、QR、主成分分析 (PCA)、K 平均、線形回帰、単純ベイズなどがあります。ここでは、サンプルとして PCA を使用します。
主成分分析 (PCA) は、探索データ解析のためのメソッドです。PCA は、相関変数の観測値のセットを主成分と呼ばれる新しいセットに変換します。主なコンポーネントは、最大分散の方向です。PCA は、次元をリダクションする強力な技術の 1 つです。
与えられた n 個の次元 p のベクトル X1= (x11,…,x1p), …, Xn= (xn1,…,xnp) または、p x p 相関行列 Cor は、データセットの主成分を計算するため、ライブラリーは行優先と対応する固有値のベクトルで、固有ベクトルが含まれる変換行列 T を返します。新しい次元 d < p を選択し、変換 Td を適用 するため結果を使用できます: ルール Yi = TdXi^T に応じて設定されたオリジナルデータへの Xi -> Yi には、行列 Td が d の最大値に対応する d の固有ベクトルが含まれる部分行列があります。
インテル® DAAL は、2 種類の PCA アルゴリズムをサポートします: 相関法 (Cor) と SVD 法。通常、パフォーマンスの観点で優れている PCA Cor を使用します。
このサンプルは、インテル® DAAL のインストール・ディレクトリーにあります。
~/intel/daal/samples/java/spark/sources/
SamplePcaCor.java
SparkPcaCor.java
DistributedHDFSDataSet.java
分散処理 – データ入力
効率良いデータ管理は、データ分析アプリケーションのパフォーマンスの重要な構成要素の 1 つです。インテル® DAAL において、データ管理は効率良く次の操作を行う必要があります。
- データ・ソース・インターフェイスを備えた Raw データ収集、フィルター処理および正規化。
- 数値テーブル向けの数値表現へのデータ変換。
- 数値テーブルからアルゴリズムへのデータ・ストリーミング
図 1 は、インテル® DAAL を使用した一般的なデータフローです。
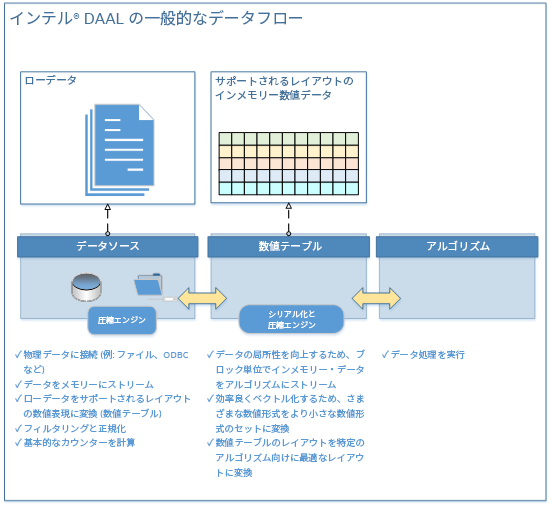
元の raw 入力データには、メモリーやファイルまたはデータベースに保存されたウェブデータ、グラフ、ストリームデータ、テキストデータ、および画像/動画/音声を利用できます。インテル® DAAL は、ローカルおよび分散データソースの入力として、インファイルとインメモリーの CSV、MySQL*、HDFS および Apache Spark* など向けの耐障害性分散データセット (RDD) をサポートします。
インテル® DAAL には、次のような raw 形式のデータを表現するデータコンポーネントを実装する複数のクラスが含まれます。
DistributedDataSet – 分散型の raw 形式データを表現するデータ管理コンポーネントへのインターフェイスを定義する抽象化クラス。
StringDataSource – java.io.Strings 形式のテキストとして保存されたデータにアクセスするためのメソッドを指定します。
クラスを基にユーザーは独自のデータ・ソース・コンポーネントを定義できます。これらのクラスは、raw 形式のデータをメモリー内の数値テーブルに変換する役割を持ちます。
ここでは、PCA の入力データセットは Hadoop* 分散ファイルシステム (HDFS) 分散メモリーに格納されていることを前提としています。サンプルでは、 csv ファイルに保存されています。
~/intel/daal/samples/java/spark/data
PcaCor_Normalized_1.csv
PcaCor_Normalized_2.csv
PcaCor_Normalized_3.csv<
PcaCor_Normalized_4.csv
//# putting input data on HDFS
>hadoop fs -put data/${sample}*.csv /Spark/${sample}/data/
サンプル DistributedHDFSDataSet.java と SamplePcaCor.java には、StringDataSource クラス、DistributedHDFSDataSet クラス、および JavaPairRDD テンプレートなど、事前ビルドされたコネクターとデータパーサーが付属しています。SamplePcaCor.java の 13 行と 14 行 で、数値クラス HomogenNumericTable に入力データを読み込みます。これによりインテル® DAAL は高効率の計算が可能になります。DistributedHDFSDataSet クラスのメンバー関数 getAsPairRDD は、DistributedHDFSDataSet.java に実装されています。これによりすべての入力データは、RDD と Spark* ワーカーによって扱われます。
データセットは計算ノードにまたがって複数のブロックに分散されます。ユーザーは、データがどのノードにあり、どのように通信するか考慮する必要はありません。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 | /* file: SamplePcaCor.java */// Principal Component Analysis computation example programpublic class SamplePcaCor { public static void main(String[] args) { DaalContext context = new DaalContext(); /* Create a JavaSparkContext that loads defaults from system properties and the classpath and sets the name */ JavaSparkContext sc = new JavaSparkContext( new SparkConf().setAppName("Spark PCA(COR)")); /* Read from distributed HDFS data set from path */ StringDataSource templateDataSource = new StringDataSource( context, "" ); DistributedHDFSDataSet dd = new DistributedHDFSDataSet( "/Spark/PcaCor/data/", templateDataSource ); JavaPairRDD<Integer, HomogenNumericTable> dataRDD = dd.getAsPairRDD(sc); /* Compute PCA for dataRDD using Correlation method */ SparkPcaCor.PCAResult result = SparkPcaCor.runPCA(context, dataRDD); /* Print results */ HomogenNumericTable EigenValues = result.eigenValues; HomogenNumericTable EigenVectors = result.eigenVectors; printNumericTable("Eigen Values:", EigenValues ); printNumericTable("Eigen Vectors:", EigenVectors); context.dispose(); } |
分散処理 – アルゴリズム
分散処理モードでは、インテル® DAAL のアルゴリズムは複数のデバイス (計算ノード) 間に分散されたデータセットを操作し、各ノードで生成された部分結果を最終的にマスターノードでマージします。分散処理モードでの PCA 相関法は、インテル® DAAL ユーザー・リファレンス・ガイドのアルゴリズムに記載された一般スキーマに従います。
SamplePcaCor.java のコードでは、計算は runPCA 関数で行われます。
1 2 | /* Compute PCA for dataRDD using Correlation method */SparkPcaCor.PCAResult result = SparkPcaCor.runPCA(context, dataRDD); |
関数は、SparkPcaCor.java に定義。
1 2 3 4 5 6 | public static PCAResult runPCA(DaalContext context, JavaPairRDD<Integer, HomogenNumericTable> dataRDD) { computestep1Local(dataRDD); finalizeMergeOnMasterNode(context); return result;} |
これは、次の 2 つのステップを含みます。
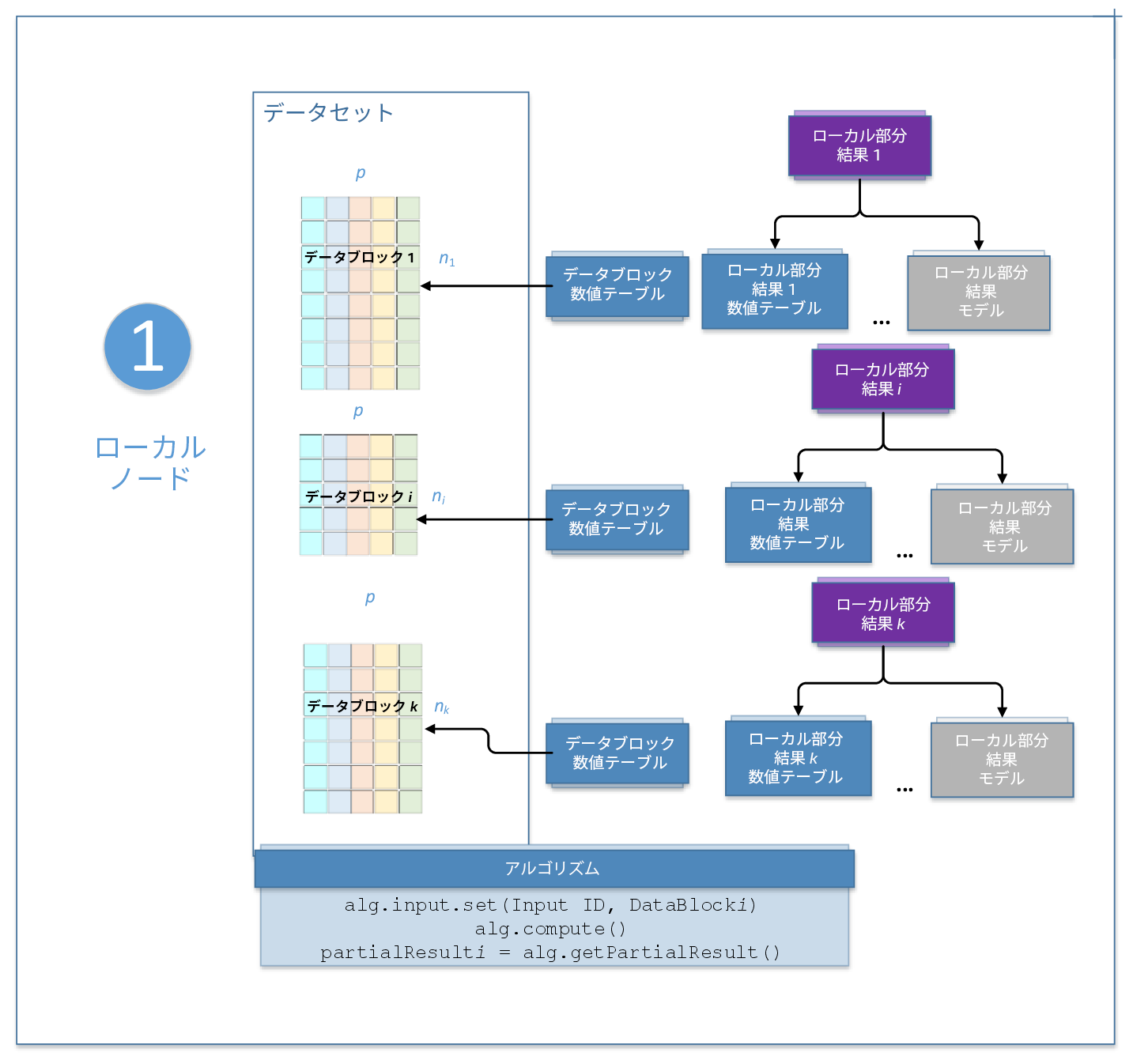
ステップ 1 – ローカルノード: Computestep1Local(dataRDD)
このステップでは、PCA アルゴリズムはローカルノードで実行されます。ここでは、ローカル入力データのブロックを受け取り、各ノードでローカルな部分結果を計算し、次のステップへパラメーターとして結果 ID を渡します。コードは、SparkPcaCor.java にあります。詳細については、図 2 とアルゴリズムをご覧ください。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 | private static void computestep1Local(JavaPairRDD<Integer, HomogenNumericTable> dataRDD) { partsRDD = dataRDD.mapToPair( new PairFunction<Tuple2<Integer, HomogenNumericTable>, Integer, PartialResult>() { public Tuple2<Integer, PartialResult> call(Tuple2<Integer, HomogenNumericTable> tup) { DaalContext context = new DaalContext(); /* Create algorithm to calculate PCA decomposition using Correlation method on local nodes*/ DistributedStep1Local pcaLocal = new DistributedStep1Local(context, Double.class, Method.correlationDense); /* Set input data on local node */ tup._2.unpack(context); pcaLocal.input.set( InputId.data, tup._2 ); /* Compute PCA on local node */ PartialResult pres = pcaLocal.compute(); pres.pack(); context.dispose(); return new Tuple2<Integer, PartialResult>(tup._1, pres); } } } |
ステップ 2 – マスターノード: finalizeMergeOnMasterNode
このステップでは、PCA アルゴリズムはマスターノードで実行されます。ここでは、最初にローカルのノードから結果を収集し、その後 MasterInputId へ追加します。 Alg.compute() は、部分結果に基づく計算を実行します。その後、計算を完了し、固有値を含む数値テーブル ResultId.eigenValues と固有ベクトルを含む数値テーブル ResultId.eigenVectors から PCA の結果を取得します。ローカルノードとマスターノードのすべての通信は、Hadoop* もしくは Spark* によって扱われます。アルゴリズムのダイアグラムとコード (SparkPcaCor.java) を以下に示します。詳細は、下記のアルゴリズムを参照してください。
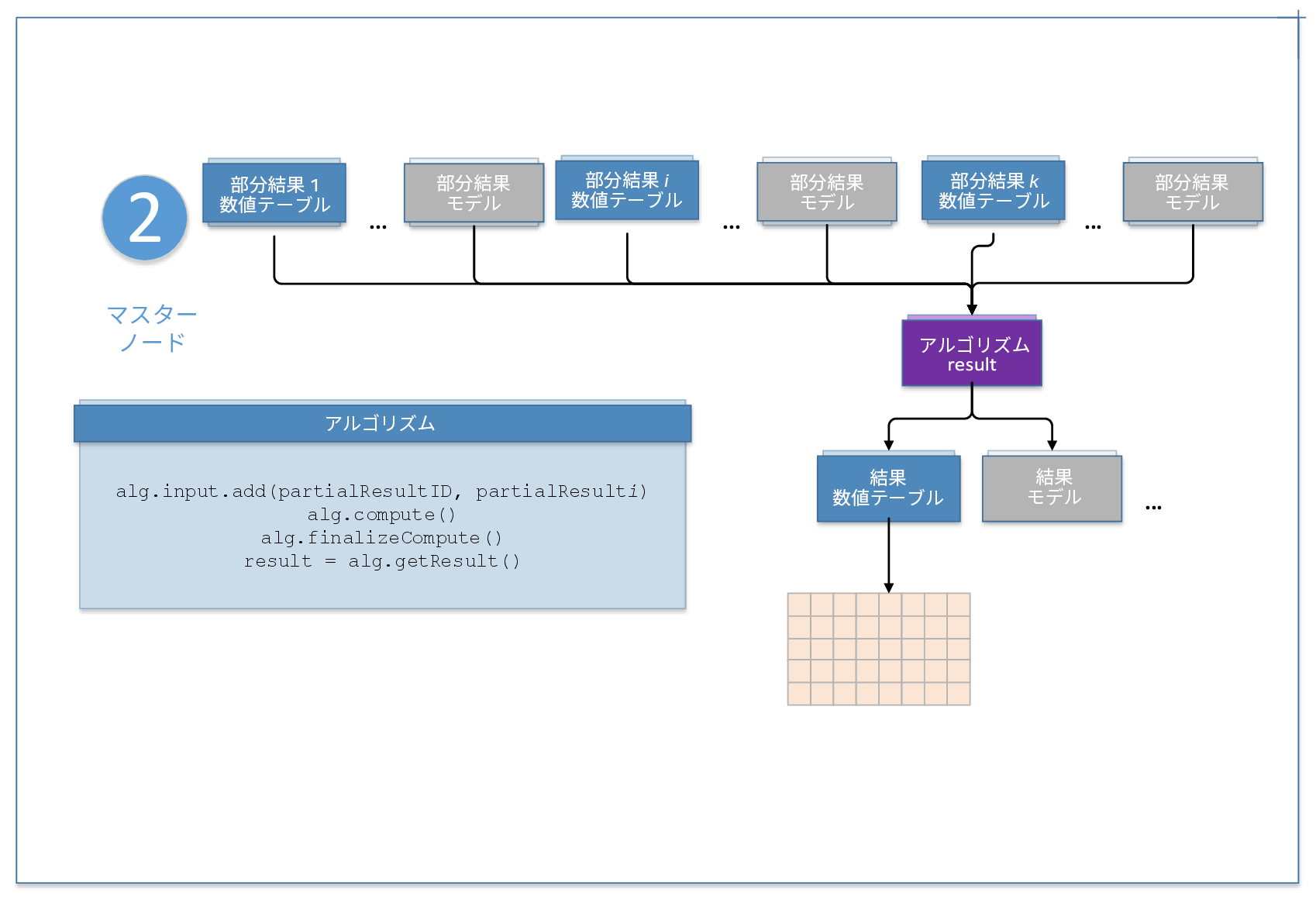
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 | private static void finalizeMergeOnMasterNode(DaalContext context) { /* Create algorithm to calculate PCA decomposition using Correlation method on master node */ DistributedStep2Master pcaMaster = new DistributedStep2Master(context, Double.class, Method.correlationDense); List<Tuple2<Integer, PartialResult>> parts_List = partsRDD.collect(); /* Add partial results computed on local nodes to the algorithm on master node */ for (Tuple2<Integer, PartialResult> value : parts_List) { value._2.unpack(context); pcaMaster.input.add( MasterInputId.partialResults, value._2 ); } /* Compute PCA on master node */ pcaMaster.compute(); /* Finalize the computations and retrieve PCA results */ Result res = pcaMaster.finalizeCompute(); result.eigenVectors = (HomogenNumericTable)res.get(ResultId.eigenVectors); result.eigenValues = (HomogenNumericTable)res.get(ResultId.eigenValues); }} |
サンプルをビルドおよび実行する
インテル® DAAL の分散アルゴリズムは、デバイス間の通信技術を抽象化するため、さまざまなマルチデバイスの計算とデータ転送で利用できます。MPI ベースのクラスター環境だけでなく、Hadoop*/Spark* ベースのクラスター、低レベルデータ交換プロトコルなどで利用できます。このサンプルでは、ノードの管理、データブロック割り当て、そして通信に Spark* クラスターを使用しました。
laucher.sh スクリプトは、
- SPARKE_HOME、HADOOP、SHAREDLIBS 環境変数を設定するのに役立ちます。次に例を示します。
1234567891011
exportJAVA_HOME=/usr/spark/pkgs/java/1.7.0.45-64/jre/exportHADOOP_CONF_DIR=/home/spark/hadoop-2.2.0/etc/hadoop/exportSPARK_HOME=/home/spark/spark-1.2-yarnexportDAALROOT=/home/spark/intel/compilers_and_libraries_2016.0.xx/linux/daalsource${DAALROOT}/bin/daalvars.sh intel64exportCLASSPATH=/home/spark/hadoop-2.2.0/share/hadoop/mapreduce/hadoop-mapreduce-client-common-2.2.0.jar:/home/spark/hadoop-2.2.0/share/hadoop/common/hadoop-common-2.2.0.jar:/home/spark/hadoop-2.2.0/share/hadoop/mapreduce/hadoop-mapreduce-client-core-2.2.0.jar:/home/spark/spark-1.2-yarn/core/target/spark-core_2.10-1.2.1-SNAPSHOT.jar:/home/spark/spark-1.2-yarn/mllib/target/spark-mllib_2.10-1.2.1-SNAPSHOT.jar:${DAALROOT}/lib/daal.jar:${CLASSPATH}exportSCALA_JARS=/home/spark/scala-2.10.4/lib/scala-library.jarexportSHAREDLIBS=${DAALROOT}/lib/${daal_ia}_lin/libJavaAPI.so, ${DAALROOT}/../tbb/lib/${daal_ia}_lin/gcc4.4/libtbb.so.2, ${DAALROOT}/../compiler/lib/${daal_ia}_lin/libiomp5.so - サンプルのビルド
123456
javac -d ./_results/${sample} -sourcepath. / sources/*${sample}.java sources/DistributedHDFSDataSet.javacd_results/${sample}# Creating jarjar -cvfe spark${sample}.jar DAAL.Sample${sample} ./* >> ${sample}.log - サンプルの実行
1
/home/spark/spark-1.2-yarn/bin/spark-submit--driver-class-path \"${DAALROOT}/lib/daal.jar:${SCALA_JARS}\" --jars ${DAALROOT}/lib/daal.jar --files ${SHAREDLIBS},${DAALROOT}/lib/daal.jar -v --master yarn-cluster --deploy-mode cluster --class DAAL.Sample${sample} spark${sample}.jar"
結果はマスターノードの標準出力に表示されます。図 4 に表示結果の例を示します。
インテル® DAAL PCA Cor と Spark* MLLIB のベンチマークについては、https://software.intel.com/en-us/intel-daal/details をご覧ください。
トラブルシューティング
環境の準備ができていれば、プログラムは適切に動作すると想定されます。実行に問題が生じた場合、その多くは環境設定が原因です。
Wrong FS: hdfs://xxx/libiomp5.so, expected: viewfs://cmt/
解決策: SHAREDLIBS に定義されているすべての依存性のあるライブラリーを必要に応じて手動でコピーします。
リソースをアップロード
ファイル: /home/spark/intel/compilers_and_libraries_2016.0.107/linux/daal/lib/intel64_lin/libJavaAPI.so -> hdfs://dl-s2:9000/user/spark/.sparkStaging/application_1440055872445_0024/libJavaAPI.so
- Exception in thread “main” …. libJavaAPI.so: ELF file OS ABI invalid
- メモリー不足による実行エラー。”Total size of serialized results of 16 tasks (2.GB) is bigger than spark.driver.maxResultSize (2.0 GB)” などのメッセージが表示された場合。
解決するには、driver.maxResultSize を増やします (デフォルトは 1G)
1 | spark-submit -v --master yarn-cluster --deploy-mode cluster --class DAAL.SamplePcaCor --conf "spark.driver.maxResultSize=20g" --num-executors 10 --jars ${DAALROOT}/lib/daal.jar,${SCALA_JARS},${SHAREDLIBS} sparkpcacor.jar |
コンパイラーの最適化に関する詳細は、最適化に関する注意事項を参照してください
