
この記事は、インテル® デベロッパー・ゾーンに公開されている「Optimize Linear Regression Model with Intel® DAAL」(https://software.intel.com/content/www/us/en/develop/articles/optimizing-linear-regression-method-with-intel-data-analytics-acceleration-library.html) の日本語参考訳です。
この記事の PDF 版はこちらからご利用になれます。
企業は、売上を伸ばすため、将来の広告費をどのように予測しているのでしょうか? 同様に、生産性を向上させるため、研修プログラムにどれぐらい投資すべきでしょうか?
どちらの場合も、これまでの変数の関係、例えば前者の場合は将来の結果を予測するため売上と広告費の関係に依存します。
これは、マシンラーニングでうまく解決できる典型的な回帰問題です1。
この記事では、線形回帰2 と呼ばれる一般的な回帰分析について説明し、インテル® データ・アナリティクス・アクセラレーション・ライブラリー (インテル® DAAL)3 を使用してこのアルゴリズムをインテル® Xeon® プロセッサー・ベースのシステム向けに最適化する方法を紹介します。
線形回帰とは?
線形回帰 (LR) は、予測分析に使用される最も基本的な回帰です。LR は、変数間の線形関係と、ある変数が 1 つまたは複数の変数によってどのような影響を受けるかを示します。ほかの変数によって影響を受ける変数は従属変数、応答変数、または結果変数と呼ばれ、ほかの変数は独立変数、説明変数、または予測変数と呼ばれます。
LR 分析を使用するため、LR がこのデータセットに適しているか検証する必要があります。そのためには、データの分布を確認します。次の 2 つのグラフについて考えます。

図 1. データポイントを通り抜ける直線を描ける場合

図 2. データポイントを通り抜ける直線が描けない場合
図 1 ではデータポイントを通り抜ける直線を描くことができますが、図 2 では (直線ではなく) 曲線のみ描くことができます。そのため、図 1 のデータセットでは線形回帰分析を行うことができますが、図 2 のデータセットではできません。
独立変数の数に応じて、LR は単純線形回帰 (SLR) と多重線形回帰 (MLR) に分けられます。
LR は、独立変数が 1 つの場合は SLR と呼ばれ、複数の場合は MLR と呼ばれます。
1 つの従属変数と 1 つの独立変数を持つ方程式の最も単純な形式は、次のように定義できます。
y = Ax + B (1)
説明:
y: 従属変数
x: 独立変数
A: 回帰係数または線の傾き
B: 定数
問題は、従属変数 (y) の観測値と予測値の差が最小になる最適な線をどのように見つけるかです。つまり、方程式 (1) で |yobserved – ypredicted| が最小となる A と B を見つけます。
最適な線は、最小 2 乗法を使用して見つけることができます4。各データポイントから線までの垂直方向の差 (観測値と予測値の差) の 2 乗和を最小化することで、最適な線を求めます。垂直方向の差は残差とも呼ばれます。

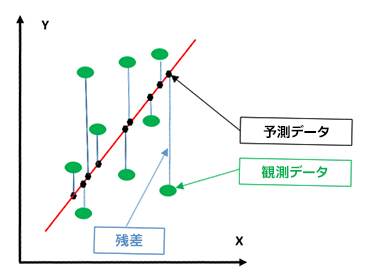
図 3. 線形回帰グラフ
図 3 の緑の点は実際のデータポイントを示します。黒い点は、回帰線 (赤い線) へのデータポイントの垂直投影 (垂線ではない) を示します。黒い点は予測データとも呼ばれます。実際のデータと予測データの垂直方向の差は残差と呼ばれます。
線形回帰の使用例
以下は、線形回帰の使用例です。
- 将来の販売予測
- 製品の販売におけるマーケティング効果と価格設定の分析
- 金融サービスや保険のリスク評価
- 自動車における試験データからのエンジン性能の調査
線形回帰のメリットとデメリット
以下は、LR のメリットとデメリットです。
- メリット
- 独立変数と従属変数の関係がほぼ線形である場合に最適な結果が得られます。
- デメリット
- LR は外れ値に対して非常に敏感です。
- 非線形関係のモデル化には適していません。
- 線形回帰は、数値出力の予測に限定されます。
インテル® DAAL
インテル® DAAL は、データ解析とマシンラーニング向けに最適化された多くの基本ビルディング・ブロックからなるライブラリーです。これらの基本ビルディング・ブロックは、最新のインテル® プロセッサーの機能向けに高度に最適化されています。LR は、インテル® DAAL が提供する予測アルゴリズムの 1 つです。この記事では、インテル® DAAL の Python* API を使用して基本的な LR 予測子を作成します。インテル® DAAL をインストールするには、「Linux* でインテル® DAAL の Python* バージョンをインストールする方法」 (https://software.intel.com/content/www/us/en/develop/articles/how-to-install-the-python-version-of-intel-daal-in-linux.html)5 の手順に従ってください。
インテル® DAAL の線形回帰アルゴリズムを使用する
このセクションでは、インテル® DAAL の Python* 線形回帰アルゴリズム6 を呼び出す方法を示します。
アプリケーションのテストに使用可能な無料のデータセットへのリンク7 は、「関連情報」セクションにあります。
次のステップに従って、インテル® DAAL から線形回帰アルゴリズムを呼び出します。
- from コマンドと import コマンドを使用して、必要なパッケージをインポートします。
次のコマンドを実行して NumPy* をインポートします。
import numpy as np次のコマンドを実行して、インテル® DAAL の数値テーブルをインポートします。
from daal.data_management import HomogenNumericTableデータを格納するため、数値テーブルに必要な関数をインポートします。
from daal.data_management import ( DataSourceIface, FileDataSource, HomogenNumericTable, MergeNumericTable, NumericTableIface)次のコマンドを実行して、LR アルゴリズムをインポートします。
from daal.algorithms.linear_regression import training, prediction
データ入力が .csv ファイルからの場合、ファイル・データ・ソースを初期化します。
trainDataSet = FileDataSource(
trainDatasetFileName, DataSourceIface.notAllocateNumericTable,
DataSourceIface.doDictionaryFromContext
)トレーニング・データと従属変数の数値テーブルを作成します。
trainInput = HomogenNumericTable(nIndependentVar, 0, NumericTableIface.notAllocate)
trainDependentVariables = HomogenNumericTable(nDependentVariables, 0, NumericTableIface.notAllocate)
mergedData = MergedNumericTable(trainData, trainDependentVariables)入力データをロードします。
trainDataSet.loadDataBlock(mergedData)- モデルをトレーニングする関数を作成します。
最初に、次のコマンドを実行して、モデルをトレーニングするアルゴリズム・オブジェクトを作成します。
algorithm = training.Batch_Float64NormEqDense()注: このアルゴリズムは、線形最小 2 乗問題を解くため正規方程式を使用します。インテル® DAAL は、QR 分解/因数分解もサポートしています。
次のコマンドを実行して、トレーニング・データセットと従属変数をアルゴリズムに渡します。
algorithm.input.set(training.data, trainInput)
algorithm.input.set(training.dependentVariables, trainDependentVariables)説明:
algorithm: 上記のステップで定義したアルゴリズム・オブジェクト。
trainInput: トレーニング・データ
trainDependentVariables: トレーニング従属変数次のコマンドを実行して、モデルをトレーニングします。
trainResult = algorithm.compute()説明:
algorithm: 上記のステップで定義したアルゴリズム・オブジェクト。
- モデルをテストする関数を作成します。
- 上記のステップ 2、3、および 4 と同様に、テスト・データセットを作成する必要があります。
testDataSet = FileDataSource(
testDatasetFileName, DataSourceIface.doAllocateNumericTable,
DataSourceIface.doDictionaryFromContext
)testInput = HomogenNumericTable(nIndependentVar, 0, NumericTableIface.notAllocate)
testTruthValues = HomogenNumericTable(nDependentVariables, 0, NumericTableIface.notAllocate)
mergedData = MergedNumericTable(testDataSet, testTruthValues)testDataSet.loadDataBlock(mergedData)
次のコマンドを実行して、モデルをテスト/予測するアルゴリズム・オブジェクトを作成します。
algorithm = prediction.Batch()次のコマンドを実行して、テストデータとトレーニング済みモデルをモデルに渡します。
algorithm.input.setTable(prediction.data, testInput)
algorithm.input.setModel(prediction.model, trainResult.get(training.model))説明:
algorithm: 上記のステップで定義したアルゴリズム・オブジェクト。
testInput: テストデータ。次のコマンド実行して、モデルをテスト/予測します。
Prediction = algorithm.compute()
- 上記のステップ 2、3、および 4 と同様に、テスト・データセットを作成する必要があります。
まとめ
線形回帰は、非常に一般的な予測アルゴリズムです。インテル® DAAL の線形回帰アルゴリズムは最適化されています。インテル® DAAL を使用することで、アプリケーションを変更せずに、インテル® DAAL の最新バージョンにリンクするだけで、将来の世代のインテル® Xeon® プロセッサーの新機能を利用できます。
関連情報
- Wikipedia – 機械学習
- 線形回帰
- インテル® DAAL の概要 (https://software.intel.com/en-us/blogs/daal)
- 最小 2 乗法
- Linux* でインテル® DAAL の Python* バージョンをインストールする方法 (https://software.intel.com/content/www/us/en/develop/articles/how-to-install-the-python-version-of-intel-daal-in-linux.html)
- Python* ウェブサイト (英語)
- 一般的なデータセットのリスト (https://archive.ics.uci.edu/ml/datasets.php)
製品とパフォーマンス情報
1 インテル® コンパイラーでは、インテル® マイクロプロセッサーに限定されない最適化に関して、他社製マイクロプロセッサー用に同等の最適化を行えないことがあります。これには、インテル® ストリーミング SIMD 拡張命令 2、インテル® ストリーミング SIMD 拡張命令 3、インテル® ストリーミング SIMD 拡張命令 3 補足命令などの最適化が該当します。インテルは、他社製マイクロプロセッサーに関して、いかなる最適化の利用、機能、または効果も保証いたしません。本製品のマイクロプロセッサー依存の最適化は、インテル® マイクロプロセッサーでの使用を前提としています。インテル® マイクロアーキテクチャーに限定されない最適化のなかにも、インテル® マイクロプロセッサー用のものがあります。この注意事項で言及した命令セットの詳細については、該当する製品のユーザー・リファレンス・ガイドを参照してください。
注意事項の改訂 #20110804
