
この記事は、インテル® デベロッパー・ゾーンに掲載されている「OpenMP* 5.0 support in Intel® Compiler 18.0」(https://software.intel.com/en-us/articles/openmp-50-support-in-180) の日本語参考訳です。
OpenMP* 5.0 は OpenMP* 仕様の次のバージョンであり、2018 年に正式リリースが予定されています。テクニカルレポート 4 (TR4) が、OpenMP* 5.0 API のプレビューとしてリリースされており、ここではその言語機能について説明します。インテル® コンパイラー 18.0 は、OpenMP* に追加された主要機能の 1 つであるタスク間のリダクションをサポートします。
リダクション操作は、次のような方法でそれぞれのループ反復間で変数を更新することで行われます。
変数 = オペレーター(変数, 式)
オペレーターは、変数を更新する可換で結合可能なオペレーターであり、変数は式に現れてはいけないことに注意してください。この種のループの並列化では、変数が共有され、それぞれの反復で更新されるためデータ競合が発生します。この競合を回避するには排他的なアクセスが必要になります。
リダクションには一般に 3 つのタイプがあります: for ループ、while ループ、および再帰的。for ループのリダクションでは、リダクションは for ループのボディーと反復空間に含まれることが知られています。これは、大規模な配列データの各要素や数学ソルバーを更新する科学アプリケーションで利用されます。このリダクション・タイプは、既存の OpenMP* 仕様の reduction 節でサポートされています。しかし、反復空間が不明であったり、while ループでリダクションが使用されるアルゴリズムも存在します (例えば、グラフ検索アルゴリズムなど)。再帰的なリダクションは、組み合わせ最適化などのバックトラック法を使用するアルゴリズムで使用され、コンパクトでエレガントな数式を可能にします。明示的なタスクの並列化は OpenMP* 3.0 で導入され、while ループと再帰的な表現の平行性を可能にしましたが、リダクションはサポートされていませんでした。OpenMP* 5.0 の新しい機能は、タスク間の並列リダクションを提供します。
これをサポートするため、新しい節が仕様に追加されました。リダクションのスコープ節である task_reduction は、タスクによってリダクション計算される範囲を定義します。
C++: #pragma omp taskgroup task_reduction ( operator : list )
Fortran: !$OMP TASKGROUP TASK_REDUCTION ( operator | intrinsic : list )
各リスト項目向けに、taskgroup は in_reduction(x) でタスクごとに x のコピーを保持します。taskgroup の最初で x のすべてのコピーは、op に応じて初期化されます。そして、最後にすべての x のコピーが、オリジナルの x にレデュースされます。新しいリダクション節は、タスクがリダクションに参加することを明示します。
C++: #pragma omp task in_reduction ( operator : list )
Fortran: !$OMP TASK IN_REDUCTION ( operator | intrinsic : list )
それぞれのリスト項目 x に対し、タスクは taskgroup からその x のコピーへのポインター p を要求します。入れ子になっている場合、もっとも内側の taskgroup の task_reduction 節がその要求に応答します。タスクボディー内のすべての x へのアクセスは、*p に置き換えられます。次の簡単な例について考えてみます。
int sum=init_sum(), A[100]=init_A();
#pragma omp parallel
#pragma omp single
{
#pragma omp taskgroup task_reduction(+:sum)
{
#pragma omp task in_reduction(+:sum)
for (i=0; i<50; i++) sum += A[i];
#pragma omp task in_reduction(+:sum)
for (i=50; i<100; i++) sum += A[i];
} // タスクグループのすべてのタスクが完了するのを待機
print(sum);
}
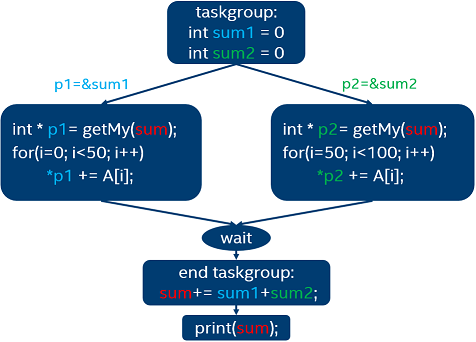
ここのリダクション操作を行う 2 つのタスクがあります。しかし、sum を更新するタスクはすべて、明確にする必要があります。そのため、タスクグループ内のリダクションを行うタスクが task_reduction 節を持つように囲む必要があります。これは、このタスクグループのタスクは、sum のリダクションを行う可能性があることを示します。リダクションに参加するすべてのタスクは、in_reduction 節でマークしなければいけません。つまり、リダクションに参加しないタスクもあるかもしれないということです。この例のタスクは同時に実行されることに注意してください。次の図は、何が起こっているかを表しています。

OpenMP* 4.5 仕様で追加された新しい taskloop ディレクティブには、同様の節が用意されています。
taskloop は、ループのワークを共有するタスクを生成します。そして、それらを含む暗黙の taskgroup を作成します。taskloop リダクション (参加と範囲) 節は、次のように記述します。
C++: #pragma omp taskloop reduction ( operator : list )
Fortran: !$OMP TASKLOOP REDUCTION ( operator | intrinsic : list )
taskloop のすべてのタスクは、in_reduction 節でマッチングを取得し、暗黙の taskgroup は task_reduction 節でマッチングを取得します。
また、in_reduction 節で taskloop を指定することもできます。この場合、暗黙の taskloop は task_reduction 節のマッチングを持たず、明示的な taskgroup は taskloop を内在し、task_reduction 節のマッチングを持つ必要があります。
C++: #pragma omp taskloop in_reduction ( operator : list )
Fortran: !$OMP TASKLOOP IN_REDUCTION ( operator | intrinsic : list )
taskloop のすべてのタスクが in_reduction 節に関連します。
コンパイラーの最適化に関する詳細は、最適化に関する注意事項を参照してください。
