

 |
2017 年 9 月に発表されたインテル® C++ コンパイラー バージョン 18.0 で、インテル® Cilk™ Plus のサポートが将来のインテル® C++ コンパイラーのバージョンでは打ち切られることが正式になりました (V18 ではインテル® Cilk™ Plus の構文を含むソースをコンパイルすると、コンパイラーから警告が出ます))。 |
そして、OpenMP* やインテル® スレッディング・ビルディング・ブロック (インテル® TBB) など他のテクノロジーへの移行が推奨されるようになりました。gcc のブランチにあるインテル® Cilk™ Plus のサポートがどうなるかは不明ですが、日本で唯一のインテル® Cilk™ Plus 書籍 (たぶん) の著者としては若干複雑な思いです。
本稿では、4 回に分けてインテル® Cilk™ Plus のすべての機能が既存の他のテクノロジーへ移行が可能であるか検討しています。第 2 回目では、インテル® Cilk™ Plus の 3 つの キーワードとレデューサーを使用しているケースを検討しました。第 3 回目は、配列表記 (Array Section) とヘルパー関数を使用するケースを検討していきます。
「さよなら Cilk Plus」移行の手順 – 明日のためのその 2
配列表記とは
Array Section (部分配列) は、本来 Array Notation と呼ばれていましたが、ここでは両方とも配列表記と呼ぶことにします。配列表記は、配列へのアクセスをシンプルにしてコンパイラーのベクトル化を支援する意図で設計されました。FORTRAN 90 の Array Notation と同様の機能を持ちます。
通常 C/C++ で配列にアクセスする場合、memcpy や memset で値を設定するほかは、ループとインデックスを使用して記述することがほとんどです。
1 2 | for(int i=0; i<MAX; i++) a[i] = 0; |
これを配列表記で記述すると、a[:] = 0 と 1 行にできます。インテル® Cilk™ Plus の配列表記は、配列のインデックス部分を次のような 3 つのセクションで記述できます。
A [ [開始要素位置]: [終了要素位置] : [スキップする要素数]] ([] 内は省略可能)
A [:] は配列の全要素を意味します。
つまり A[10 : 20] = 1 と記述すると、配列 A の 10 番目の要素から 20 番目の要素に 1 を設定、A[10 : 20: 2] = 1 とすると配列 A の 10 番目の要素から 20 番目の要素に 2 つ飛ばしで 1 を設定、など配列を簡単に操作できます。もちろん式の右辺で記述して読み出し操作にも利用できます。また、開始位置、終了位置、ストライドには、即値の代わりに変数を使用することができます。配列表記を使用するオペランド同士で演算を行う場合、左辺と右辺の配列表記のランク数とレングスが同じであれば、C/C++ でサポートされるほぼすべての演算子を利用できます。a[:]++ や -–a[:] といった操作も可能です。以下に利用できる演算子を示します。
+、-、*、/、%、<、==、>、<=、!=、>=、++、–、|、&、^、&&、||、!、- (単項演算)、+ (単項演算)、+=、-=、*=、/=、* (ポインター参照)
また、インテル® C++ コンパイラーでは、配列表記をサポートするヘルパー関数が提供されています。これらの関数を使用すると、sum = __sec_reduce_add(A[:][:]) (配列 A 全体の合計を sum に生成) のように配列のリダクション演算を実に簡素に表現できます。インテル® Cilk™ Plus の廃止とともにこれらの関数もなくなる予定です。
| 関数プロトタイプ | 説明 |
|---|---|
| __sec_reduce(fun, identity, a[:]) | 汎用リダクション関数。identity を初期値として、配列a[:] に fun を実行します。 |
| __sec_reduce_add(a[:]) | 配列として渡された値を加算します。 |
| __sec_reduce_mul(a[:]) | 配列として渡された値を乗算します。 |
| __sec_reduce_all_zero(a[:]) | 配列要素がすべてゼロであるかテストします。 |
| __sec_reduce_all_nonzero(a[:]) | 配列要素がすべて非ゼロであるかテストします。 |
| __sec_reduce_any_nonzero(a[:]) | 非ゼロの配列要素があるかテストします。 |
| __sec_reduce_min(a[:]) | 配列要素の最小値を特定します。 |
| __sec_reduce_max(a[:]) | 配列要素の最大値を特定します。 |
| __sec_reduce_min_ind(a[:]) | 配列要素の最小値のインデックスを取得します。 |
| __sec_reduce_max_ind(a[:]) | 配列要素の最大値のインデックスを取得します。 |
ソースコード中の配列表記を見つける
例えば、配列表記を利用すると、ループを構成せずに左表のようなコードを記述できます。
| 配列表記によるコード | 等価な for ループのコード | ||||
|---|---|---|---|---|---|
|
|
このコードをインテル® C++ コンパイラーのバージョン 18.0 以降でコンパイルすると、次のような警告が表示されます。ただし /W0 オプションで警告表示を無効にしている場合は表示されません。
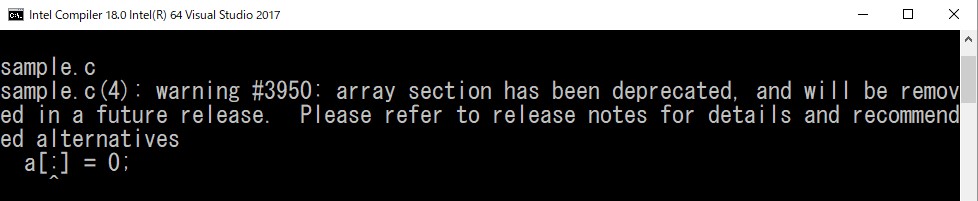
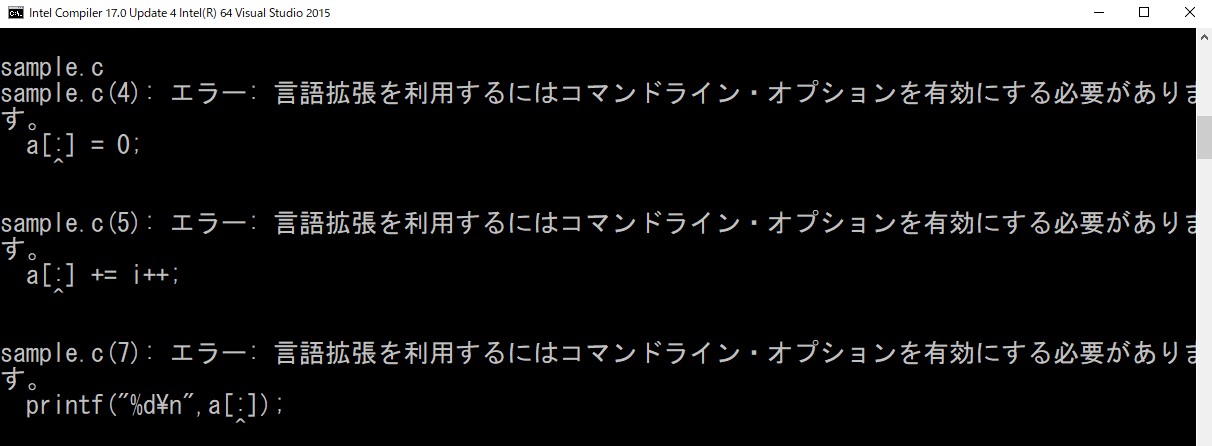
インテル® コンパイラー (V18 以前のコンパイラーでも利用可能) で、ソースコード中でインテル® Cilk™ Plus の機能を使用しているかどうかは、/Qintel-extensions- オプション (Linux* では –no-intel-extensions) を使用して確認できます (以下はバージョン 17.0.4 でコンパイルしました)。このオプションは、インテル® Cilk™ Plus の 3 つのキーワード、配列表記、#pragma simd の言語拡張を無効化するため、使用しているとエラーになります。
配列表記を代替コードに書き換える
配列表記を使用するソースコードは、すべて代替コードに書き換える必要があります。ほとんどの場合 for ループとループ・インデックスを使用した従来のコーディング・スタイルとなるでしょう。
最初に、前述の表のように、配列表記を通常のシリアル for ループ表現に置き換えて、必要に応じて #pragma omp simd によるベクトル化や、#pragma omp parallel for による並列化、または両者を適用すると良いでしょう。並列化やベクトル化を容易にするため、配列表記で表現する以外の処理をループ中に入れ込まないことが重要です。シリアル for ループへの置き換えだけであれば、リダクション関数はそのまま等価な for ループを使用した表現に置き換えるだけで良いですが、ベクトル化や並列化を適切に行うにはリダクション操作を指示する必要があります。
また、配列表記では、a[1:10] += a[2:10] といったオーバーラップする代入が可能であるため、使用する SIMD 命令のベクトル幅によっては依存関係が生じベクトル化が妨げられることがあります。特に配列表記に変数を使用する場合、コンパイラーは依存関係を検出できない恐れがあります。その場合、#pragma omp simd に safelen 節や simdlen 節を追加して安全なベクトル幅をコンパイラーに通知できます。
では、配列表記とヘルパー関数を使用した例の書き換えを検討してみましょう。
| 配列表記 | ||
|---|---|---|
|
上記は、2 次元配列 A のすべての要素をリダクション加算して、配列 sum のすべてに格納することを指示します。このコードを for ループの構成に戻すには 3 つの入れ子のループとなります。一般的に配列表記 1 つに対し for ループが 1 つ必要になると考えると良いでしょう。
| ベクトル化のみ | スレッド化とベクトル化 | ||||
|---|---|---|---|---|---|
|
|
左のリストはベクトル化のみを指示しています。ここで配列 sum をリダクション変数として指示しないでベクトル化を強制すると正しい結果が得られません。また、同時にスレッド化も実装する場合、最上位のループをスレッド化、2 番目の連続する配列アクセスの制御ループをベクトル化します。最上位を #pragma omp parallel for simd とすると、ベクトル化できません。この場合もリダクション変数の宣言が必須です。
最後に典型的な配列表記と対応する for ループ構造の例をいくつか紹介します。
| 配列表記によるスキャッター操作 | 等価な for ループのコード | ||||
|---|---|---|---|---|---|
|
|
配列 b に格納されるインデックスを使用して、配列 c の内容を配列 a へスキャッターして格納します。
| 配列表記によるギャザー操作 | 等価な for ループのコード | ||||
|---|---|---|---|---|---|
|
|
配列 b に格納されるインデックスを使用して、配列 a の内容を配列 c へギャザーします。
| 条件式による異なる代入 | 等価な for ループのコード | ||||
|---|---|---|---|---|---|
|
|
配列 a と b の同じインデックス位置の値を比較して、> が真であれば c[i] = a[i] – b[i] を、偽であれば d[i] = b[i] – a[i] の操作を実行します。
C/C++ の for ループで構成されるアルゴリズムを配列表記に書き換えたプログラマーの方であれば、元のコードに戻すのは容易でしょう。配列表記で記述されたコードを引き継いだプログラマーの方は、配列表記が何を行っているか理解するのに、すこし頭をひねるかもしれませんね。
OpenMP* の部分配列との違い
OpenMP* 4.0 以降では OpenMP* ディレクティブでの部分配列の仕様がサポートされており、インテル® Cilk™ Plus と配列セクションの表記に似ていますが、異なる目的で使用されます。そのため、インテル® Cilk™ Plus の配列表記を OpenMP* の配列セクションに置き換えることはできません。OpenMP* の部分配列は次のように使用します。
1 2 | #pragma omp parallel for simd reduction(+:a[:4]) private(a[5:])for(int i=0; i < MAX; i++) { …} |
これは、for ワークシェア構文の中で、配列 a の 4 番目の要素までを + 操作のリダクション変数として扱い、a[5] 以降をローカル配列とすることを意味します。構文中のデータ操作には利用できせん。使用すると、それはインテル® Cilk™ Plus の配列表記として扱われます。OpenMP* の部分配列は、reduction、private、firstprivate、lastprivate、depend など変数リストを引数とする節で利用できます。ただし、OpenMP* で使用できる部分配列は、A [ [開始要素位置] : [終了要素位置]] の形式で、ストライドはサポートされていません。
次回、最終回は SIMD プラグマと要素関数 (SIMD 対応関数) について説明します。
その他の記事
第 1 回「Cilk がやってきた」から「さよなら Cilk Plus」
第 2 回「さよなら Cilk Plus」インテル® Cilk™ Plus の 3 つのキーワードを使用するケース
第 3 回「さよなら Cilk Plus」インテル® Cilk™ Plus の配列表記 (Array Section) とヘルパー関数を使用するケース
第 4 回「さよなら Cilk Plus」インテル® Cilk™ Plus の #pragma simd と要素関数 (SIMD 対応関数) を使用するケース
- https://software.intel.com/en-us/articles/migrate-your-application-to-use-openmp-or-intelr-tbb-instead-of-intelr-cilktm-plus (英語)
上記の記事の翻訳版を以下に用意しましたので参照ください。
