

この記事は、インテル® デベロッパー・ゾーンに公開されている「Getting the Most out of your Intel® Compiler with the New Optimization Reports」(https://software.intel.com/en-us/articles/getting-the-most-out-of-your-intel-compiler-with-the-new-optimization-reports) の日本語参考訳です。
最適化レポートを理解して適切に対処することで、コンパイラーの最適化によりアプリケーションのパフォーマンスを改善できます。幸いなことに、最新のインテル® コンパイラーを使用することで簡単に行うことができます。現代の最適化コンパイラーは、アプリケーションのパフォーマンスを大幅に改善するためコード変換を行いますが、これは元のコードがどのように記述されているか、そしてコンパイラーに対しどの程度の情報が提供されているかに依存します。インテル® コンパイラーの最適化レポートは、プログラマーに対し適用された最適化を通知し、適用されなかった最適化の理由を示します。プログラマーはこのフィードバックを、コンパイラーの最適化を有効にし、アプリケーションのパフォーマンスをさらに高めるためのチューニングに利用することができます。
インテル® コンパイラーの以前のバージョン (14.x) では、価値のある多くの潜在的な情報を一連の異なるレポートで提供しましたが、メッセージが論理的に配置されておらず、時にインライン展開やコンパイラーが生成する複数バージョンのループは特に難解で、暗号のようであると言われていました。一部の情報は、プログラマーがアクションを取りにくかったり、すぐに役立てることはできませんでした。単一のレポートストリームは理解するのが難しく、他のツールからアクセスするのも困難であり、ビルド時間を短縮するため複数のプロセッサーを利用する並列ビルドには不向きでした。
インテル® Parallel Studio XE 2015 に含まれる最新のバージョン 15.0 コンパイラーから、最適化レポートは、個々のレポートを 1 つに統合し、ユーザーが使いやすく、これまでの制限に対処するため全体的に再設計されました。この記事では、新しい最適化レポートの機能を紹介し、さらにコンパイラーが適用した最適化や適用できなかった最適化を理解して、さらにアプリケーションをチューニングする方法を説明します。
レポートの有効化と制御
Windows*、Linux* および OS X* 版のインテル® コンパイラーで最適化レポートを有効にして、表 1b に示す新しい最適化レポートのレベルを制御するには、コマンドライン・オプションを使用します。Linux* や OS X* 環境では、大部分のオプションは -q で始まり、Windows* では /Q で始まります。オプションは C/C++ と Fortran コンパイラーで共通です。
| Linux* および OS X* | Windows* | 機能 |
| -qopt-report[=N] | /Qopt-report[:N] | レポートを有効にする: N=1-5 で詳細レベルを指定します。デフォルトは N=2 です。 |
| -qopt-report-file=stdout | stderr | ファイル名 | /Qopt-report-file:stdout | stderr | ファイル名 | レポートの出力先を指定します。デフォルトは、拡張子 .optrpt を持つファイルです。 |
| /Qopt-report-format:vs | Microsoft* Visual Studio* で表示できるフォーマットにします。 | |
| -qopt-report-routine=fn1[,fn2,…] | /Qopt-report-routine:fn1[,fn2,…] | fn1 [or fn2…] で指定された関数名、もしくはその文字列を含む関数のレポートを取得します。 |
| -qopt-report-filter=“filename,ln1-ln2” | /Qopt-report-filter=“filename,ln1-ln2” | filename で指定されたファイルの行番号 ln1 – ln2 のみのレポートを取得します。 |
| -qopt-report-phase=phase1[,phase2,…] | /Qopt-report-phase:phase1[,phase2,…] | 指定したフェーズの最適化レポートのみを取得します。 |
表 1a
| 最適化フェーズ | 説明 |
| vec | SIMD 命令による自動および明示的なベクトル化 |
| par | コンパイラーによる自動並列化 |
| loop | メモリー、キャッシュ利用およびその他のループ最適化 |
| openmp | OpenMP* 宣言子による明示的なスレッド化 |
| ipo | インライン展開を含むプロシージャー間の最適化 |
| pgo | プロファイルに基ずく最適化 (ランタイム・フィードバックを適用) |
| cg | コード生成時の最適化 |
| offload | インテル® Xeon Phi™ コプロセッサーへのオフロードとデータ転送 |
| all | すべての最適化フェーズをレポート (デフォルト) |
表 1b
出力されるレポート
レポートはデフォルトでは無効であり、-qopt-report (/Qopt-report) オプションで有効にします。デフォルトでは、並列ビルドにおける互換性のため、各オブジェクト・ファイルごとに .optrpt 拡張子を持った個別のレポートが生成されます。-qopt-report-file (/Qopt-report-file) オプションを使用して、出力先をファイル、stderr もしくは stdout に変更することができます。
デバッグビルド (Linux* と OS X* では -g、Windows* では /Zi オプションを使用した) では、アセンブリー・コードとオブジェクト・ファイルにループ最適化情報が埋め込まれます。これにより、アセンブリー・コードにおけるループ構造を理解するのが容易になり、他のソフトウェア・ツールがコンパイラーが提供する最適化情報を利用できるようになります。
最適化レポートは、状況によって非常に大きくなります。そのため、-qopt-report-routine (/Qopt-report-routine) オプションで特定の関数に注目したり、-qopt-report-filter (/Qopt-report-filter) オプションでソースの行範囲を特定し、必要とするレポートのみを取得できます。
ループ関連レポートの構成
入れ子になったループに関連する最適化レポートのメッセージは、図 1 に示すように階層的に表示されます。コンパイラーは、生成したコード行と列番号に対応する各ループの先頭に「LOOP BEGIN」というメッセージを生成し、ループの終わりには「LOOP END」を生成します。入れ子構造を明確にするためインデントを使用しています。単一のソースのループからコンパイラーによって複数のループが生成されることがあり、この場合入れ子構造はソースコードとは異なることがあります。ループは、2 つ以上に「分散 (分割)」されることもあります。図 1 示す部分レポートでは、ソースコードの 6 行目にある外部ループが最適化されたコードでは 2 つの内部ループに変換されています。
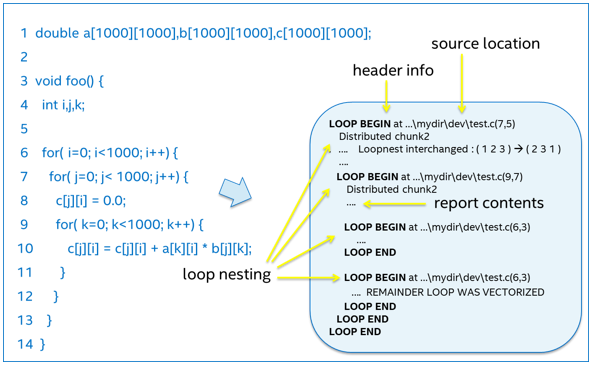
図 1
この階層表示は、コンパイラーの最適化が適用されたコード内の特定ループに直接関連付けられます。
ベクトルループ内の SIMD ロード命令は、SIMD レジスター幅の倍数でアライメントされたメモリー位置から読み込みを行う際に最も効率が良くなります。そのため、コンパイラーはベクトル化されたループのカーネル部分がアライメントされたデータにアクセスできるよう、初めのループ反復を “peel (ピール: 皮むき)” します。ベクトル化されたカーネルが処理できなかった残りの反復を処理するため、”remainder (余剰)” ループとして最適化されます。図 2 は、「ピール」と「リマインダー」ループを最適化レポートで特定する方法を示します。
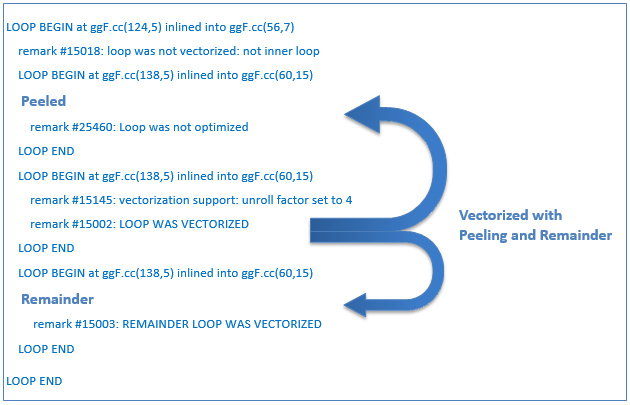
図 2
ループとベクトル化レポートを利用
新しい最適化レポートの目的は、コンパイラーが行った最適化を分かりやすくするだけではなく、遭遇した障害を理解し上手く対処できるように支援することです。コード 1 に C で記述された簡単な例を示します (レポートの内容とその解釈方法は C と Fortran で同様です)。関数 foo() のループは、配列 theta を入力し数値演算関数を利用して計算を行い、結果を配列 sth に格納します。
1 2 3 4 5 6 | #include <math.h>void foo (float * theta, float * sth) { int i; for (i = 0; i < 128; i++) sth[i] = sin(theta[i]+3.1415927);} |
コード 1
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 | $ icc -c -qopt-report=2 -qopt-report-phase=loop,vec -qopt-report-file=stderr foo.cBegin optimization report for: foo(float *, float *) Report from: Loop nest & Vector optimizations [loop, vec]LOOP BEGIN at foo.c(4,3)<Multiversioned v1> remark #25228: Loop multiversioned for Data Dependence remark #15399: vectorization support: unroll factor set to 2 remark #15300: LOOP WAS VECTORIZEDLOOP ENDLOOP BEGIN at foo.c(4,3)<Multiversioned v2> remark #15304: loop was not vectorized: non-vectorizable loop instance from multiversioningLOOP END |
レポート 1
このレポートでは、コンパイラーがソースコードの 1 つのループから 2 つのループを生成していることが分かり (“マルチバージョン化” と呼ばれます)、その理由がデータの依存性にあることが説明されています。コンパイラーは、コンパイル時に関数のポインター引数 theta と sth のアライメントや、ベクトル化によりデータが重複する問題が生じるポインターのオーバーラップを知ることができません。そのため、コンパイラーはベクトル化されたループとスカラーループの 2 つのバージョンを生成します。コンパイラーは、ベクトル化されたループを実行しても安全かどうか、データのオーバーラップをテストするランタイムコードを埋め込みます。安全ではないと判断された場合、スカラーループが実行されます。
2 つのポインター引数がオーバーラップしていないことが明確である場合、プログラマーは -fargument-noalias (Linux* と OS X*) や /Qalias-args- (Windows*) コンパイラー・オプション、もしくは restrict キーワードと -restrict (Linux* と OS X*)、/Qrestrict (Windows*) オプションでコンパイラーにアライメントされていないことを知らせることができます。代替手段として、#pragma ivdep や #pragma omp simd (-qopenmp や -qopenmp-simd がオプションが必要) を使用して、コンパイラーにループのベクトル化が安全であることを直接知らせることができます。これらを使用した場合、ベクトル化されたバージョンのループのみが生成され、コンパイラーはデータのオーバーラップをテストするランタイムコードを生成する必要はありません。次の例では、コマンドライン・オプションを使用してレポート 2 に示すようにレポートの詳細レベルを高めています:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 | $ icc -c -fargument-noalias -qopt-report=4 -qopt-report-phase=loop,vec -qopt-report-file=stderr foo.cBegin optimization report for: foo(float *, float *) Report from: Loop nest & Vector optimizations [loop, vec]LOOP BEGIN at foo.c(4,3) remark #15389: vectorization support: reference theta has unaligned access [ foo.c(5,14) ] remark #15389: vectorization support: reference sth has unaligned access [ foo.c(5,5) ] remark #15381: vectorization support: unaligned access used inside loop body [ foo.c(5,5) ] remark #15399: vectorization support: unroll factor set to 2 remark #15417: vectorization support: number of FP up converts: single precision to double precision 1 [ foo.c(5,14) ] remark #15418: vectorization support: number of FP down converts: double precision to single precision 1 [ foo.c(5,5) ] remark #15300: LOOP WAS VECTORIZED remark #15450: unmasked unaligned unit stride loads: 1 remark #15451: unmasked unaligned unit stride stores: 1 remark #15475: --- begin vector loop cost summary --- remark #15476: scalar loop cost: 114 remark #15477: vector loop cost: 40.750 remark #15478: estimated potential speedup: 2.790 remark #15479: lightweight vector operations: 9 remark #15480: medium-overhead vector operations: 1 remark #15481: heavy-overhead vector operations: 1 remark #15482: vectorized math library calls: 1 remark #15487: type converts: 2 remark #15488: --- end vector loop cost summary --- remark #25015: Estimate of max trip count of loop=64LOOP END |
レポート 2
レポート 2 は、単独バージョンのループのみが生成されたことを示しています。また、コストサマリーは、ベクトル化により 2.79 倍のスピードアップが期待できることを示しています。悪くはありませんが、さらに改善することが可能です。リマークス 15417 と 15418 は、行番号 5 の列 15 と 5 で単精度と倍精度間の型変換が行われていることを通知し、サマリーでは 2 種類の変換があることが示されています。ソースコードを確認すると、配列 theta は単精度 (float) であることが分かります。しかし、定数 3.1415927 はデフォルトで倍精度 (double) です。加算の結果は倍精度であり、倍精度バージョンの sin 関数が呼び出されます。そして sth には単精度に変換して保存されます。これは、パフォーマンス上 2 つの影響があります。倍精度の sin 関数は単精度よりも結果の生成に時間がかかります。そして、倍精度データは単精度データの半分しか SIMD レジスターに格納できません。そのため、SIMD 命令は一度の計算で半分のデータしか操作できません。定数と sin 関数を明示的に短精度としてソースコードを変更できれば、
1 | sth[i] = sinf(theta[i]+3.1415927f); |
精度変換の警告はなくなり、パフォーマンスが倍精度に比べほぼ 5.4 倍スピードアップします。これは、大部分の時間がベクトル化された数値演算ライブラリー呼び出し (リマーク #15482) と、より軽量なベクトル操作 (リマーク #15479) になったためです。
次に、ベクトル化されたループの推定される最大トリップカウントが、元の 256 から 64 (リマーク #25015) になったことが分かります。そして、各ベクトル命令は 4 つの float つまり 16 バイトを操作しています。これは、デフォルトではベクトル幅が 16 バイトであるインテル® ストリーミング SIMD 拡張命令 2 (インテル® SSE2) を使用してコンパイルされるためです。32 バイトのベクトル幅を持つインテル® アドバンスト・ベクトル・エクステンション (インテル® AVX) 命令を実行できるインテル® プロセッサーが利用可能であれば、 -xavx (/QxAVX) コンパイラー・オプションを指定してコンパイルできます。すると次のようなレポートが生成されます:
1 2 3 4 | remark #15477: vector loop cost: 11.620remark #15478: estimated potential speedup: 9.440…remark #25015: Estimate of max trip count of loop=32 |
インテル® Xeon Phi™ コプロセッサーをターゲットとしている場合、最大トリップカウントは 16 でベクトル幅は 16 float もしくは 64 バイトになります。
では、アライメントに関連するメッセージに注目してみましょう。インテル® AVX 向けに 32 バイト (インテル® SSE には 16 バイト、インテル® Xeon Phi™ コプロセッサー向けには 64 バイト) でアライメントされたメモリーへのアクセスは、一般的にアライメントされていないアクセスよりも効率的です。リマーク #15381 は、ループ内でアライメントされていないメモリーアクセスが検出されたことを知らせる一般的な警告です。リマーク #15389、#15450 そして #15451 は、コンパイラーがアライメントされていないデータの theta のロードと sth へのストアを前提としていることを通知しています。theta と sth は引数として渡されるため、コンパイラーはそれらのアライメントを検知できません。__declspec(align(32)) (Windows*) や __attribute__((align(32))) (Linux* と OS X*) を使用してデータの宣言時にアライメントを確実にするか、_mm_malloc() や Posix memalign() を使用してアライメントされた割り当てを行うことができます。関数 foo() への引数がアライメントされていることが判明していれば、__assume_aligned() キーワードを使用してアライメントが確実であることをコンパイラーに知らせることができます
1 2 | __assume_aligned(theta,32);__assume_aligned(sth,32); |
これらのキーワードは、関数へのポインター引数が常にアライメントされたデータを指すことが確実な場合にのみ使用してください。ランタイム時のチェックは行われません。__assume_aligned キーワードを追加して再コンパイルすると、次のようなアライメントされたメモリーアクセスがレポートされます。
1 | remark #15388: vectorization support: reference theta has aligned access |
ベクトル化によって向上するスピードアップの推定値は 20% です:
1 2 | remark #15477: vector loop cost: 9.870remark #15478: estimated potential speedup: 11.130 |
sth はアライメントされ、コンパイラーはメモリーへ直接ストリーミング・ストア (非テンポラルとして知られています) 命令を生成できる可能性があります。ストアされたデータが近い将来 (キャッシュから追い出される前に) 再びアクセスされる可能性がある場合、これは価値があるかもしれません。これにより、キャッシュラインの「読み取りのための所有権」を避けることができます。アプリケーションが大量のデータを読み書きし、パフォーマンスがメモリー帯域によって制限されている場合に有効です。また、他の用途のためキャッシュを開放します。コンパイラーは可能性を探し、この例よりもはるかに多いデータ量 (一般的には数メガバイト) の場合にのみストリーミング・ストア命令を自動生成します。反覆回数を 200百万 (2000000) に増やすか、#pragma vector nontemporal がループに指定された場合、コンパイラーはストリーミング・ストア命令を生成し、最適化レポートに次のようなメッセージを追加します:
1 2 | remark #15467: unmasked aligned streaming stores: 1remark #15412: vectorization support: streaming store was generated for sth |
このような小さな関数でさえ、最適化レポートは有用な情報を提供します。
インライン展開における IPO レポートの例
IPO レポートは、関数にまたがる最適化の情報を提供します。ここでは、インライン展開に注目します。

図 3
図 3 から、main プログラムが小さなスタティック関数 foo() を 2 回呼び出し、結果を表示するため printf() 関数を呼び出していることが分かります。関数 foo() は、大きなスタティック関数 bar() を呼び出しています。各関数は、それぞれインライン展開レポートが報告されます。main() の本体は行番号 24 から始まり、35 行目と 36 行目で foo() がインライン展開されています。foo() は、行 21 で bar() をインライン展開します。main() は、行番号 37 で printf() を呼び出しています。printf はコンパイラーから可視なコンテキストではないため external とマークされています。 関数 bar() の本体は、行番号 3 の列 42 から始まり、関数呼び出しは含んでいません。行番号 13 列 42 から始まるスタティック関数 foo() は、呼び出し元にインライン展開されたため「DEAD SATATIC」とマークされています。外部的に呼び出すことはできないため、コンパイラーは関数のスタンドアロン・バージョンを生成する必要はありません。
間接呼び出しは、レベル 3 以上で表示され、「INDIRECT」とマークされます。高いレベルのレポートオプションでは、大小にかかわらずコンパイラーが識別できるすべての関数呼び出しが、インライン展開された関数の大きさ順と共に表示されます。
最適化レポートのインライン・フェーズの先頭には、それらを変更できるコンパイラー・オプションとインライン展開に使用された引数の値がリストされます。このレポートに基づいて、インライン展開の量を制御することができます。例えば、-inline-factor (Windows* では /Qinline-factor) の引数値を 100 から 200 に変更することで、インライン展開できる関数のサイズの制限値を倍に広げることができます。個々の関数のインライン展開は、inline、noinline、そして forceinline などのプラグマや、 対応する関数属性を __attribute__ もしくは __declspec キーワードを使用して制御することができます。詳細は、『インテル® コンパイラー・ユーザー・リファレンス・ガイド』を参照してください。
その他のレポートフェーズ
コンパイラーによる自動並列化〔スレッド化〕レポートは、ベクトル化やループのレポートと同じ構造で統合され、-qopt-report-phase=par オプションで取得できます。-qopt-report-phase=openmp オプションは、OpenMP プラグマや宣言子から生じるスレッド化構造に関するレポートを生成します。-qopt-report-phase=pgo オプションは、有用な関数に関するプロファイルを含むプロファイルに基づく最適化レポートを生成します。-qopt-report-phase=cg オプションは、組み込み関数の置き換え (低レベルへの変換) などコード生成時の最適化レポートを生成します。
-qopt-report-phase=loop オプションは、キャッシュ・ブロッキング、プリフェッチ、ループ変換などループとメモリーの最適化に関する追加情報をレポートします。-qopt-report-phase=offload オプションは、インテル® Xeon Phi™ コプロセッサー間とのデータ転送のサマリーをレポートします。
詳細については、次のインテル® Parallel Studio XE 2015 Composer Edition のコンパイラー・ユーザーズ・ガイドとリファレンス・ガイドをご覧ください:
https://software.intel.com/en-us/compiler_15.0_ug_c
https://software.intel.com/en-us/compiler_15.0_ug_f
まとめ
インテル® C/C++ と Fortran コンパイラー 15.0 の新しい統合された最適化レポートは、分かりやすく対処しやすい形式で情報を提供します。情報には導入された最適化だけでなく、導入できなかった最適化も含まれ、アプリケーションのパフォーマンスを向上するするためのチューニング・ガイドをプログラマーに提供します。
訳者注: 日本語版のコンパイラーでは、レポートは日本語で表示されます。
コンパイラーの最適化に関する詳細は、最適化に関する注意事項を参照してください
