
この記事は、The Parallel Universe Magazine 52 号に掲載されている「Optimize Transformer Model Inference on Intel® Processors」の日本語参考訳です。原文は更新される可能性があります。原文と翻訳文の内容が異なる場合は原文を優先してください。

Transformer モデルは、自然言語処理 (NLP) で最も人気のあるモデルの 1 つです (図 1)。2017年に Google によって公開 (英語) されて以来、ほかの多くの NLP モデルで採用されており、非 NLP モデルにも拡張されています。言語翻訳は Transformer の一般的な用途であり、その優れた精度と並列処理により、従来の LSTM モデルに大きく取って代わるものです。BERT (英語) モデルは Transformer に基づいているため、Transformer を最適化すると、多くの NLP モデルおよび非 NLP モデルを改善できます。
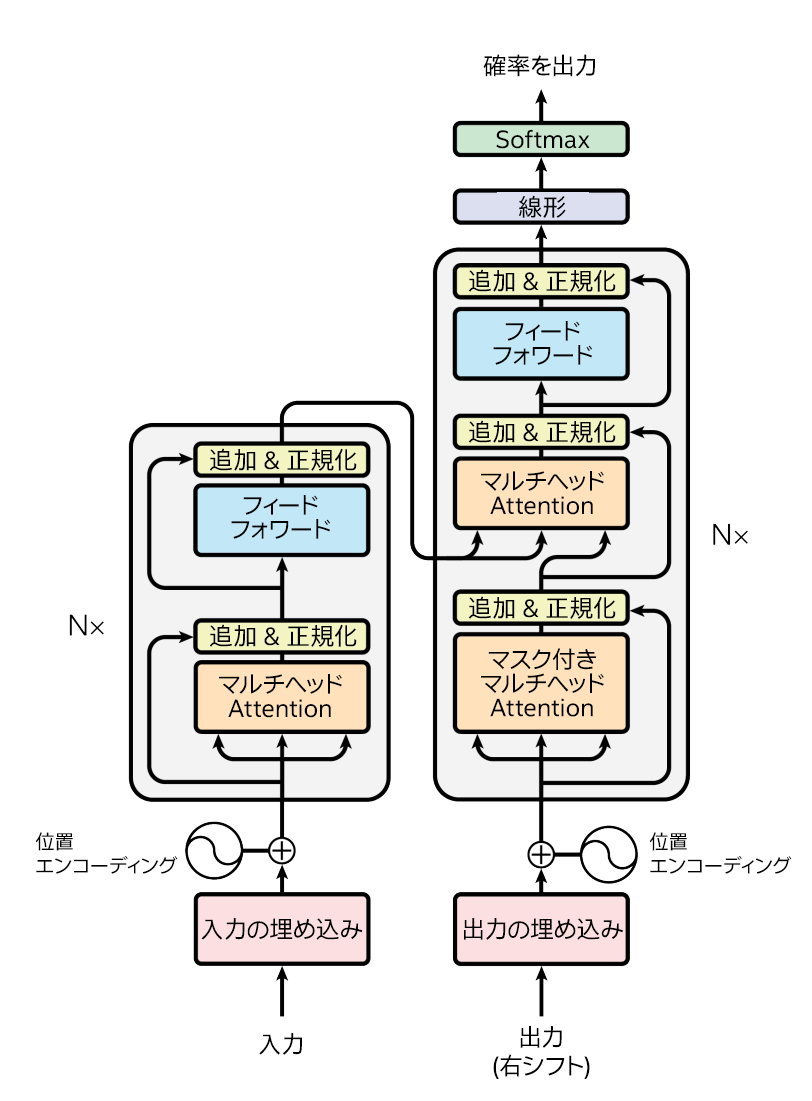
図 1. Transformer モデル・アーキテクチャー (出典: Vaswani ほか、Attention Is All You Need (英語))
インテルは、MLCommons v0.5 (英語) の Transformer のトレーニングおよび評価コードを始め、インテル® Xeon® スケーラブル・プロセッサーでの推論向けにモデルを最適化しています。これらの最適化により、推論のスループットとレイテンシーのどちらもパフォーマンスが大幅に向上しました。最適化されたモデルは、インテル® アーキテクチャー向け Model Zoo (英語) に追加されています。
モデルのトレーニング
推論の最適化を試みる前に、トレーニング済みモデルを入手する必要があります。MLPerf* Transformer モデル (v0.5) を使用し、MLPerf* が推奨する精度でトレーニングしました。このモデルにはチェックポイントがあり、必要に応じて、さらにトレーニングすることで精度を少し向上できます。トレーニング済みのチェックポイントから推論を行うこともできますが、チェックポイントには推論に必要のないトレーニング・ノードが含まれているためサイズが大きく、通常、モデルをデプロイする方法としては最適ではありません。また、チェックポイントから推論を実行すると、重みをロードするオーバーヘッドが発生します。
推論パフォーマンスを最適化するため、トレーニング済みチェックポイントを使用する代わりに、トレーニング済みモデルのチェックポイントを、推論グラフとモデルの重みだけを含むグラフに固定しました。その結果、MLPerf* Transformer モデルのサイズは、チェックポイントを使用した場合の 1GB 以上から約 800MB に減りました。固定したグラフは、モデルを int8 に量子化してさらにパフォーマンスを向上する場合にも必要になります。グラフを固定するスクリプトは、インテル® アーキテクチャー向け Model Zoo にあります。
グラフを固定する過程で、定数の畳み込み、単位元ノードの削除など、いくつかの最適化が適用されます。グラフを固定したら、既知の入力ノードと出力ノードを持つ protobuf (.pb) ファイルを取得します。固定したグラフから推論を実行するのは容易です。入力データをモデルの入力ノードに供給するだけです。実行後、モデルの出力ノードから結果を得ることができます。後でモデルをさらに最適化するアイデアを思いついた場合、モデルの重みが変わらない限り、再度トレーニングすることなく、最適化されたコードでモデルを再固定できます。
Transformer モデルには、エンコーダーとデコーダーの 2 つの主要なモジュールがあります。各モジュールには、フィード・フォワード・ネットワーク (FFN)、エンコーダー・デコーダーの Attention、ビーム検索、融合操作、埋め込み、Self-Attention など、複数のレイヤーがあります。ここでは、これらのレイヤーのいくつかに適用した最適化を紹介します。
FFN レイヤーのパディング/アンパディングの最適化
ここで最も重要な最適化は、FFN レイヤーからパディング/アンパディング・アルゴリズムを削除することです。このレイヤーへの入力は、形状 [batch_size, input_length, Hidden_size] の 3 次元パディングテンソルです。図 2 に示すように、このモデルには 2 番目の次元にパディングがあり、空白ブロックはパディング値ゼロを表します。モデルは、テンソルを密レイヤーに送る前にパディングを検出して削除し、図 3 に示すように、形状 [batch_size, number_tokens*Hidden_size] の 2 次元テンソルに再整形します。パディングの値はゼロのままなので、計算する必要はありません。しかし、密レイヤーの後、出力テンソルにパディングを追加して、元の形状に戻す必要があります (次のレイヤーの入力テンソルになるため)。
|
|
|
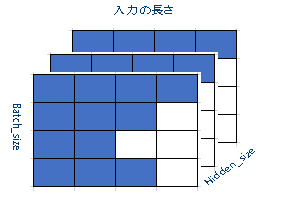
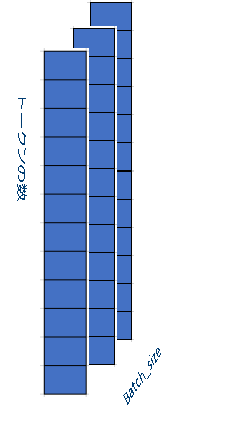
パディング/アンパディング・アルゴリズムは、より多くのメモリー操作を使用することで、計算量を減らします。計算がメモリー操作より遅い場合、パフォーマンスは向上します。しかし、最近のインテル® Xeon® スケーラブル・プロセッサーでは、このアルゴリズムの計算はメモリー操作よりも高速です。したがって、FFN レイヤーからパディング/アンパディングを削除することで、パフォーマンスが向上します。
