
この記事は、Tech.Decoded に掲載されている「Remove Memory Bottlenecks Using Intel® Advisor」(https://techdecoded.intel.io/resources/remove-memory-bottlenecks-using-intel-advisor/) の日本語参考訳です。
プログラムがどのようにメモリーにアクセスするかを理解することは、ハードウェアから多くの利点を得ることにつながります
アプリケーションがメモリーにアクセスする方法は、パフォーマンスに大きく影響します。スレッド化とベクトル化により、アプリケーションの並列性を高めるだけでは十分ではありません。メモリー帯域幅を効率良く利用することが重要です。しかし、ソフトウェア開発者はこれを理解していないことがあります。メモリーのレイテンシーを最小化し、帯域幅を増加させるのに役立つツールは、パフォーマンスのボトルネックを特定して、その原因を診断するのに有用です。そのようなツールの 1 つにインテル® Advisor があり、メモリーアクセスを最適化し、メモリーのボトルネックを排除するのに役立つ機能を備えています。
- 新たに統合されたルーフライン機能のルーフライン解析
- メモリー・アクセス・パターン (MAP) 解析
- メモリー・フットプリント解析
最高のパフォーマンスを達成
アプリケーションのパフォーマンスを最大限に引き出すには、すべてのシステムリソースをどれくらい効率良く利用しているか理解する必要があります。インテル® Advisor のサマリービュー (図 1) で、プログラム全体の有用なメトリックを確認できます。これは、アプリケーションがどの程度ベクトル化されているかを示しています。
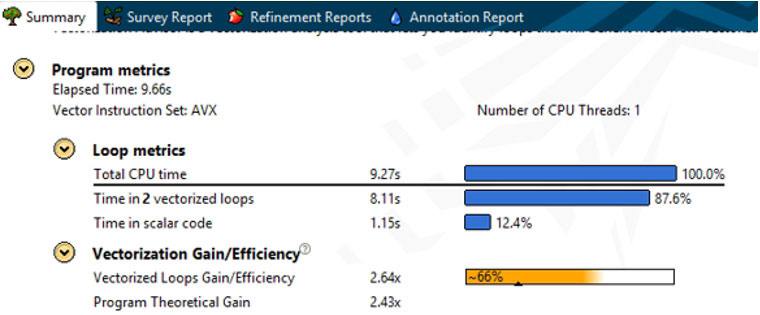
図 1 – インテル® Advisor のサマリービュー
また、プログラム内で最も時間がかかるループを体系的に調査する必要があります。ここで重要なメトリックはベクトル化効率です (図 2)。この例では、インテル® Advisor はベクトル化によるゲインが 2.19 倍であることを示しています。しかし、ベクトル化効率のスコアは 55% のみです。残りの 45% はどこで失われているのでしょう? 非効率なベクトル化の要因は多数あります。

図 2 – インテル® Advisor のベクトル化効率ビュー
パフォーマンスの問題
不適切なアクセスパターン
間接メモリーアクセスは、速度を低下させる典型的な要因です。次のコード例では、最初に B[i] をデコードしないと A をデコードできないことに注意してください。
1 2 | for (i = 0; i < N; i++) A[B[i]] = C[i] * D[i]; |
これは不規則なアクセスパターンにつながります。gather/scatter が使用できる命令セットでは、コンパイラーはこの命令を使用して上記のコードをベクトル化できます。これは、ループをベクトル化できるという面では優れていますが、シーケンシャルなアクセスほど高速ではないため好ましくありません。コードを高速化するため、データがユニットストライドでアクセスされるようにデータ構造を調整することが重要です (この情報を表示するインテル® Advisor の機能については後述します)。
メモリー・サブシステムのレイテンシー/スループット
システムの持つパフォーマンスを最大限に引き出すためには、コードを各階層のメモリーキャッシュに収め、データを再利用して活用することが不可欠です。次の例は、インデックス i を使用して非常に大規模なデータにアクセスします。このデータはキャッシュに収めるには大きすぎます。さらに 2 次元配列であることから大きさは 2 倍になります。
1 2 | for (i = 0; i < VERY_BIG; i++) c[i] = z * A[i][j]; |
A[i][j] と A[i+1][j] の参照は、メモリー上で隣接していません。そのため、新しい参照先を取得するたびに、新しいキャッシュラインを取り込みます。このとき既存のキャッシュラインが排出される可能性があります。この「キャッシュのスラッシング」は、パフォーマンスに悪影響を与えます。キャッシュ・ブロッキングなど、キャッシュに収まるように考慮された小さな範囲でインデックスを操作する内部ループを新たに追加する手法は、この種のアプリケーションの最適化に有効です。
分岐の多いコード
多くの分岐を持つアプリケーション (if(cond(i) を含む次の for ループ) は、条件が当てはまらない SIMD レーンをブロックするため、マスクレジスターを使用してベクトル化できます。これらの反復では、SIMD レーンは有用なワークを行いません。インテル® Advisor はマスク利用率メトリックを使用します (図 3)。以下の例では、3 つの要素が抑制されているため、5/8 = 62.5% のマスク利用率となります。
1 2 3 | for (i = 0; i < MAX; i++) if (cond(i)) C[i] = A[i] + B[i]; |
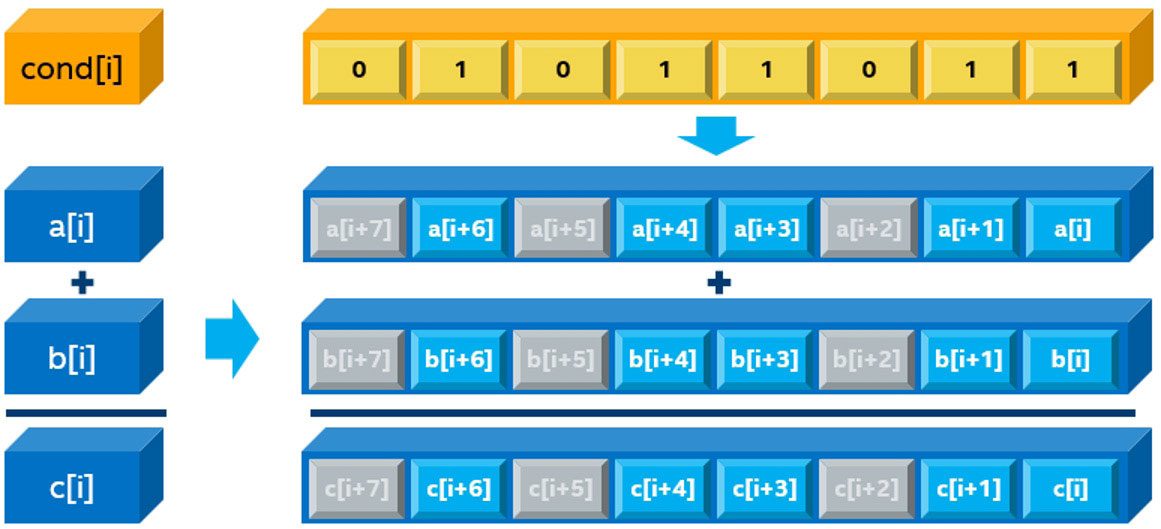
図 3 -マスク利用率メトリック
ユニットストライドでデータにアクセスし、高いベクトル化効率を達成できますが、マスク利用率が低いため十分なパフォーマンスが得られません (図 4)。表 1 はメモリー・アクセス・タイプを示します。
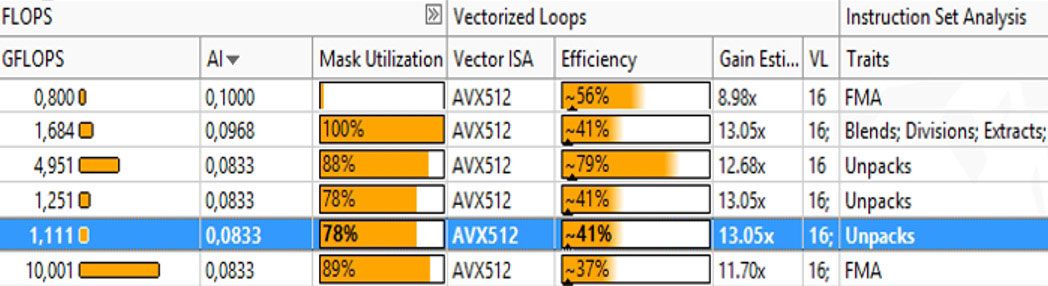
図 4 – マスク利用率と効率
表 1. メモリー・アクセス・タイプ
| アクセスパターン | 小さなメモリー容量 | 大きなメモリー容量 |
| ユニットストライド |
|
|
| 定数ストライド |
|
|
| 不規則なアクセス、 ギャザー/スキャッター |
|
|
CPU/VPU またはメモリー依存か?
アプリケーションがメモリー依存である場合、インテル® Advisor は最適化に役立ついくつかの機能を提供します。最初に、アプリケーションがメモリー依存であるか、CPU/VPU 依存のどちらであるかを特定する必要があります。これは、アプリケーションを構成する命令セットを調査することで簡単に判断できます。インテル® Advisor の [コード解析] ウィンドウ (図 5) は、コードが実行する命令ミックスを確認するための基本的な方法を提供します。

図 5 – [コード解析] ウィンドウ
経験則として、多くのメモリー操作を行うアプリケーションはメモリーに制限され、また多くの計算を実行するアプリケーションは計算に制限される傾向があります。図 5 で詳細を確認します。スカラー命令とベクトル命令の比率は特に重要です。可能な限り多くのベクトル命令が実行されるようにします。
もう 1 つの手法として、少し複雑ですがインテル® Advisor のサーベイビューの [特性] カラムを参照する方法があります (図 6)。
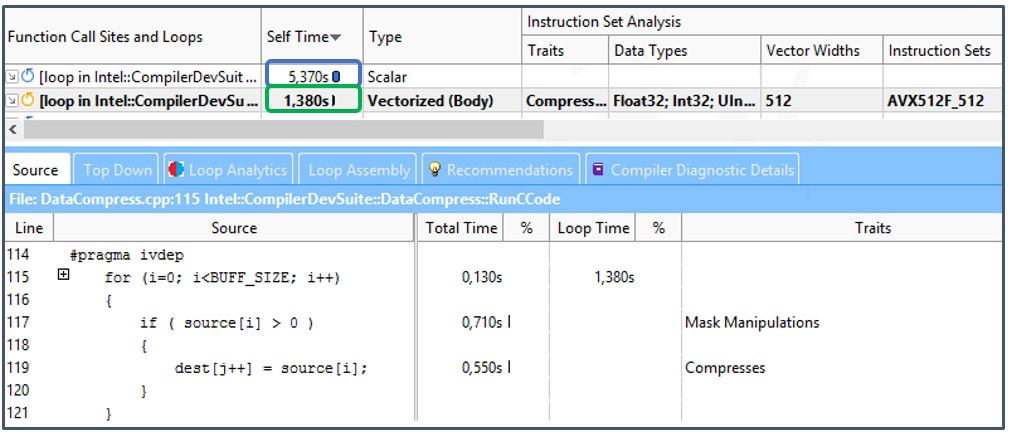
図 6 – インテル® Advisor サーベイビューの [特性] カラム
特性は、ループをベクトル化するためにコンパイラーがすべきことを示しています。インテル® アドバンスト・ベクトル・エクステンション 512 (インテル® AVX-512) などの最新のベクトル命令セットには、コンパイラーがコードをベクトル化する際に利用できる多数の新しい命令とイディオムがあります。図 6 に示すレジスターマスクや圧縮命令などの手法により、これまで不可能であったアプリケーションのベクトル化が可能になりますが、状況によってはコストが発生します。データ構造をベクトル化に適用させるためコンパイラーが行うべきことは (メモリー操作など)、[特性] カラムに示されます。多くの場合、これらの特性には、メモリー・アクセス・パターン解析で調査可能な問題が提示されます。
有用な最適化機能
ルーフライン解析
ルーフライン・グラフは、メモリー帯域幅や計算ピークを含む、ハードウェアの制限に関連したアプリケーションのパフォーマンスを視覚的に表現するものです。これは、カリフォルニア大学バークレー校の 2008 年の論文『ルーフライン: マルチコア・アーキテクチャー向けの優れた可視化パフォーマンス・モデル』(英語) で最初に提案されました。2014 年に、このモデルはリスボン工科大学の研究者によって発表された論文『キャッシュを考慮したルーフライン・モデル: ロフトをアップグレードする』(英語) で拡張されました。これまで、ルーフライン・グラフは、手動で計算され描画されてきました。インテル® Advisor は、自動的にルーフラインを構築してグラフ化します。
ルーフラインは次の情報を提供します。
- どこがパフォーマンスのボトルネックであるか
- それらがどれくらいパフォーマンスを損ねているか
- どのボトルネックが対処可能であり、対処する価値があるものはどれか
- なぜこれらのボトルネックが発生するのか
- 次のステップとして何をすべきか
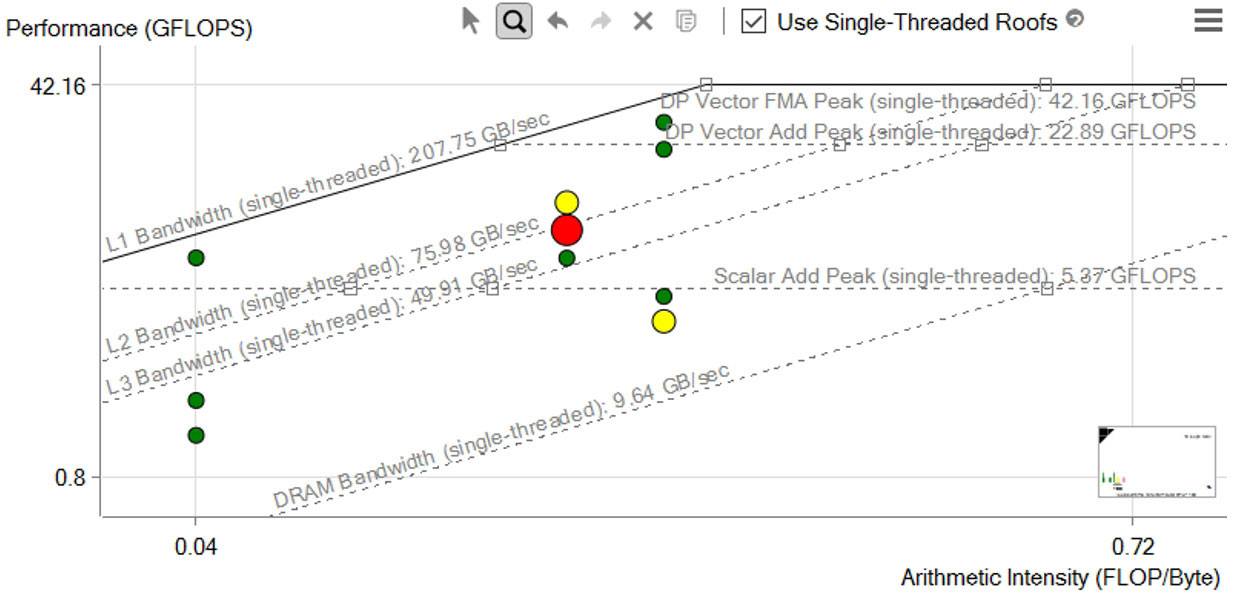
図 7 – ルーフライン解析
図 7 の水平ラインは、特定のハードウェアが一定の時間内に実行可能な浮動小数点計算または整数計算の数を表します。斜めのラインは、特定のメモリー・サブシステムが 1 秒あたりに供給できるデータ (バイト数) を表します。それぞれのドットは、プログラム内のループや関数に相当し、その位置はパフォーマンスを示しています。パフォーマンスは、最適化と演算強度 (AI) に影響されます。
インテル® Advisor 統合ルーフライン
統合ルーフライン・モデルは、さらに詳しい解析を行い、ボトルネックの発生源を直接示します。インテル® Advisor は、キャッシュ・シミュレーションによりすべてのメモリータイプのデータを収集します (図 8)。
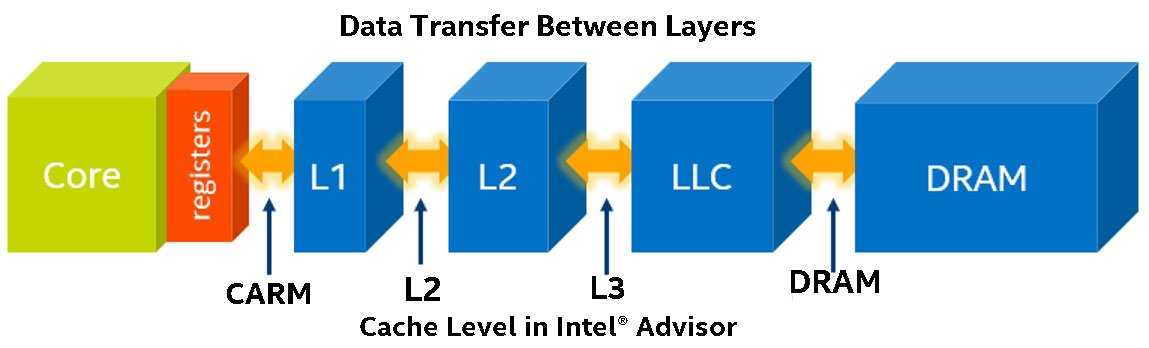
図 8 – インテル® Advisor のキャッシュ・シミュレーション
このデータを基に、インテル® Advisor は特定のキャッシュレベルのデータ転送数をカウントし、それぞれのループと各メモリーレベルの AI を計算します。一方のレベルから他方のレベルへのトラフィックの変化を観察し、これらのレベルで達成可能な最大帯域幅を表すルーフと比較することで、カーネルのメモリー階層のボトルネックを特定し、最適化の方針を決定します (図 9)。

図 9 – メモリー階層のボトルネックをピンポイントで特定
メモリー・アクセス・パターン (MAP) 解析
インテル® Advisor の MAP 解析により、メモリーアクセスに関する詳しい情報が得られます。メモリー・アクセス・パターンは、ベクトル化の効率と最終的に達成可能なメモリー帯域幅の両方に影響します。MAP 収集は実行中のデータアクセスを監視し、メモリーアクセスを行う命令を検出します。収集後に解析されたデータは、[リファインメント] ウィンドウの [メモリー・アクセス・パターン・レポート] タブに表示されます。
GUI から MAP 解析を実行するには (図 10)、[サーベイ & ルーフライン] レポートのチェックボックスを使用してループを選択し、[メモリー・アクセス・パターンの確認] を実行します。
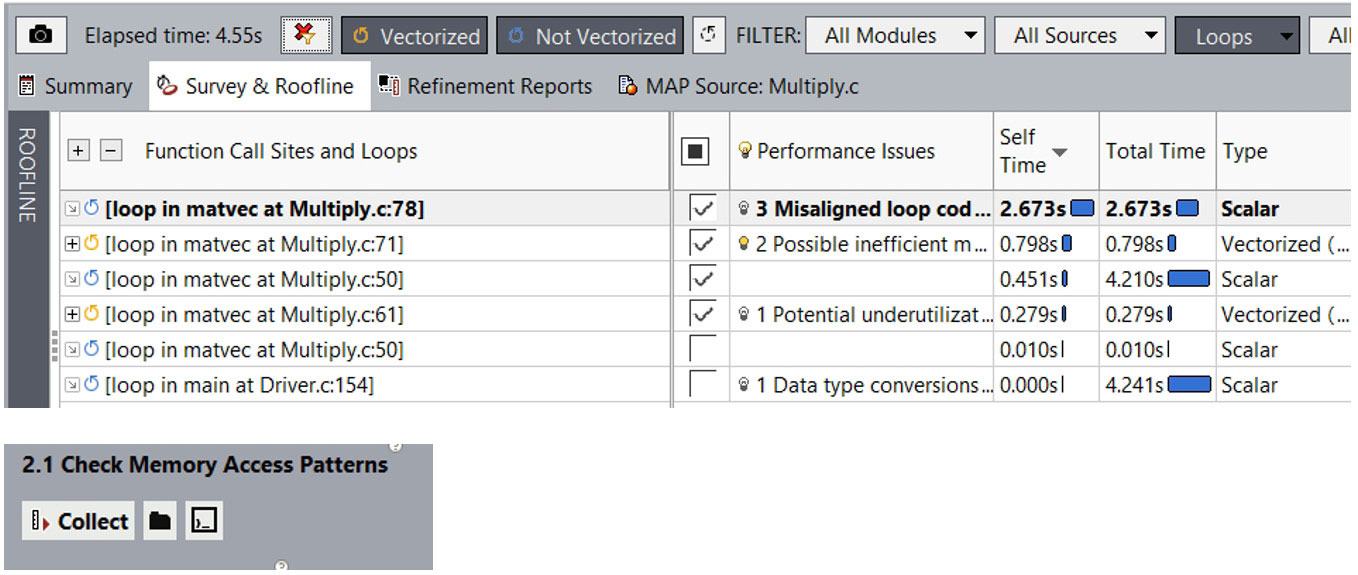
図 10 – メモリー・アクセス・パターン (MAP) レポート
コマンドラインからも MAP 収集を実行できます。-mark-up-list オプションを使用して、解析するループを選択できます。
1 2 3 | advixe-cl -collect map -mark-up-list=Multiply.c:78,Multiply.c:71,Multiply.c:50,Multiply.c:61 -project-dir C:/my_advisor_project -- my_application.exe |
メモリー・アクセス・パターン・レポートは、ループで実行されたメモリーアクセス操作のストライドタイプを示します。図 11 では、インテル® Advisor は、ユニット/ユニフォーム・ストライドと定数ストライドの両方をレポートしています。
ユニット/ユニフォーム・ストライド・タイプ
- ユニットストライド (ストライド 1) 命令は反復ごとに 1 要素ずつ変化するメモリーにアクセスします。
- ユニフォーム・ストライド 0 命令は各反復で同じメモリーにアクセスします。
- 定数ストライド (ストライド N) 命令は反復ごとに N 要素 (N>1) ずつ変化するメモリーにアクセスします。
可変ストライドタイプ
- 不規則なストライド命令は反復ごとに予測できない要素数で変化するメモリーにアクセスします。
- ギャザー (不規則) ストライドは、インテル® AVX2 命令セット・アーキテクチャーの
v(p)gather*命令を検出します。
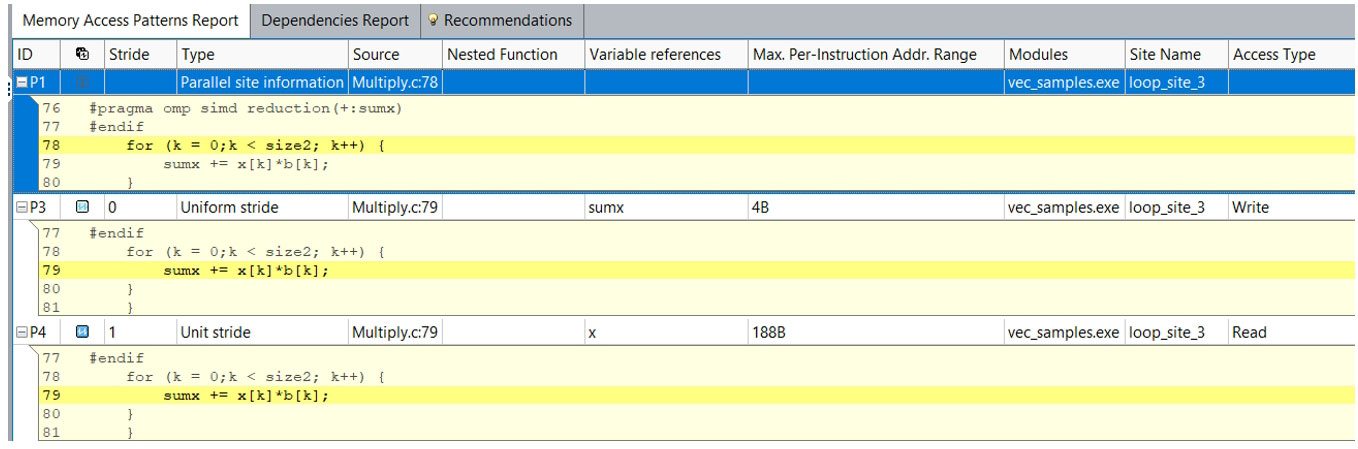
図 11 – ストライドタイプ
メモリー・アクセス・パターン・レポートの行をダブルクリックすると、その操作を行うソースコードを表示できます (図 12)。
ソースビューと詳細ビュー (図 13) はどちらもインテル® Advisor の別のメモリー機能であるメモリー容量の詳細を提供します。
メモリー容量解析
メモリー容量は、基本的に特定のループがアクセスするメモリー範囲を示します。このメモリー容量はメモリー帯域幅の重要な指標となります。メモリーのアクセス範囲が大きくなると、キャッシュに収まらない可能性が生じます。キャッシュ・ブロッキングなどの最適化手法は、このような場合に大きな違いをもたらす可能性があります。インテル® Advisor は、3 つの異なるメモリー容量メトリックを提供します (図 14)。
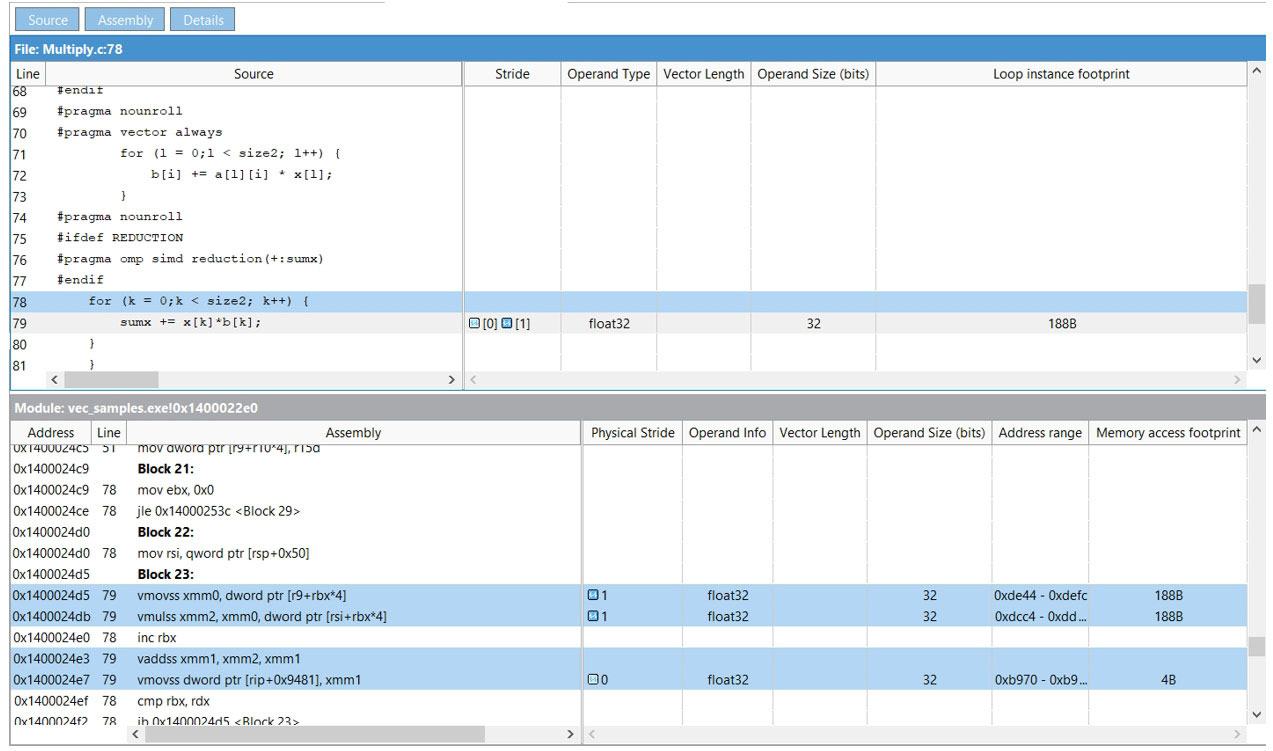
図 12 – 選択した操作のソースコードを表示
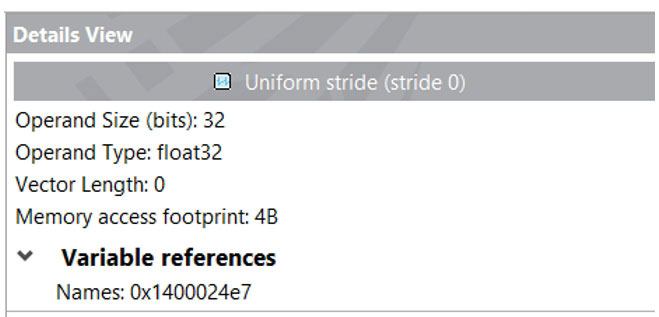
図 13 – 詳細ビュー

図 14 – メモリー容量メトリック
2 つの基本的な容量メトリックは、メモリー使用量の一部を表しています。これらのメトリックは、メモリー・アクセス・パターン (MAP) 解析ではデフォルトで収集されます。
- 命令ごとの最大アドレス範囲は、ループ内の命令がアクセスする最小メモリーアドレスと最大メモリーアドレス間の最大距離を表します。それぞれのメモリーアクセス命令の最小および最大アクセスアドレスが記録され、ループ内のすべての命令に対するアドレスの最大範囲がレポートされます。これは、フィルター処理された複数のインスタンスをカバーしているため、インテル® Advisor は確信のないメトリックを灰色で表示することがあります。
- 最初のインスタンス・サイトの容量は、ループ反復のアドレス範囲のオーバーラップやループがアクセスするアドレス範囲のギャップを認識するため、より正確なメモリー容量を示しますが、ループの最初のインスタンス (呼び出し) に対してのみ計算されます。
シミュレートされたメモリー容量と呼ばれる、キャッシュ・シミュレーションに基づいて計算される高度な容量があります。このメトリックは、単一スレッドにのみ適用されますが、すべてのループ・インスタンスのオーバーラップを考慮した要約情報を示します。これは、キャッシュ・シミュレーション中にアクセスされた一意のキャッシュラインの数にキャッシュ・ライン・サイズを掛けた値として計算されます。これを GUI で有効にするには、[プロジェクトのプロパティー] の [メモリー・アクセス・パターン解析] で、[CPU キャッシュのシミュレーションを有効にする] をオンにして、[キャッシュ・シミュレーション・モード] ドロップダウン・リストで、[キャッシュミス・モデルとループ・フットプリント] を選択します (図 15)。そして、[サーベイ] ビューで解析するループのチェックボックスを選択して MAP 解析を実行します。
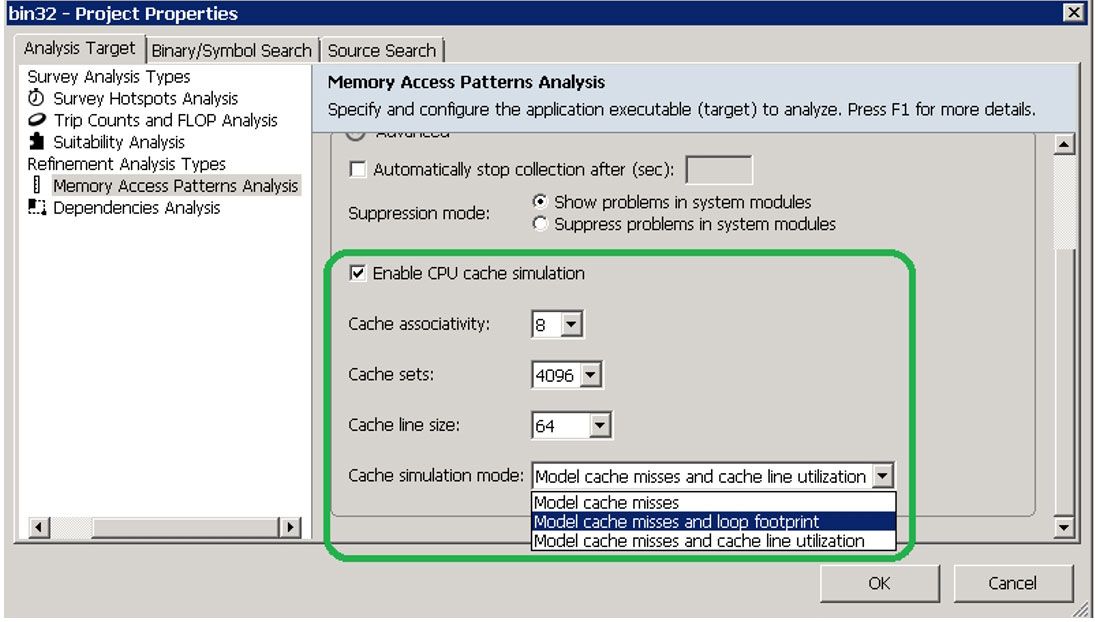
図 15 – シミュレートされたメモリー容量
コマンドラインからシミュレーションを有効にするには、前述の MAP コマンドに -enable-cache-simulation と -cachesim-mode=footprint オプションを追加して実行します。
1 2 3 4 | advixe-cl -collect map -mark-up-list=tiling_inter.cpp:56,output.c:1073 -enable-cache-simulation -cachesim-mode=footprint -project-dirC:\my_advisor_project -- my_application.exe |
解析結果は、インテル® Advisor GUI の [リファインメント・レポート] で確認できます (図 16)。メモリーロードとストア、キャッシュミス、およびキャッシュ・シミュレートされたメモリー容量の合計数など、キャッシュに関連する詳細なメトリックを見ることで、メモリーに対するループの動作を詳しく調査することができます。表 2 は、インテル® Advisor の容量メトリックの適用範囲、制限、および各種コードタイプの解析の関連性を示しています。
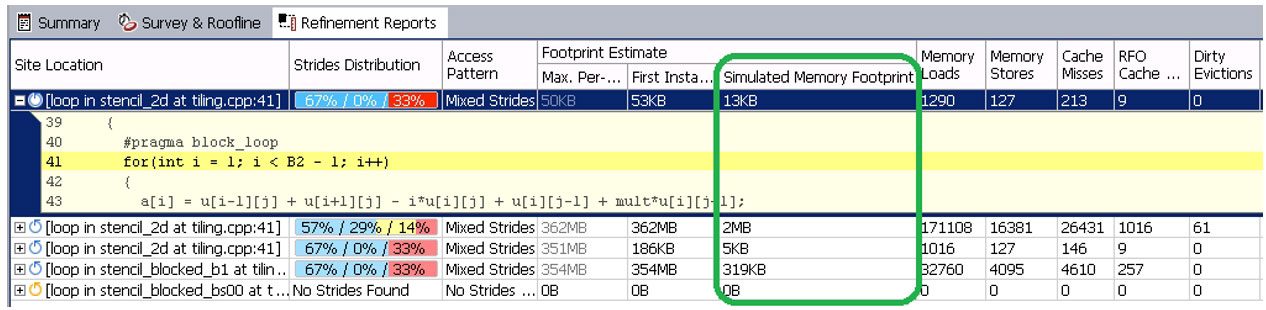
図 16 – インテル® Advisor GUI のリファインメント・レポート・ビュー
表 2. インテル® Advisor の容量メトリック
| 命令ごとの最大アドレス範囲 | 最初のインスタンスのサイト容量 | シミュレートされたメモリー容量 | |
| ループ/サイトのスレッド解析 | 1 | 1 | 1 |
| 解析されたループ・インスタンス | すべてのインスタンス (省略形あり) | 1、最初のインスタンスのみ | [ループ呼び出し回数の制限] オプションに依存 |
| アドレス範囲のオーバーラップを認識するか? | いいえ | はい | はい |
| ランダム・メモリー・アクセスを伴うコードへの適合性 | いいえ | いいえ | はい |
実際の例
一般的な科学技術計算では行列乗算が多用されます。行列を使用する計算分野はほぼ無限ですが、人工知能、シミュレーション、モデリングはその代表的な分野です。次のサンプルコードは、反復ごとに乗算と加算を行う 3 重の入れ子になったループです。計算量が多いだけでなく、大量のメモリーアクセスを伴います。インテル® Advisor を使用して観察してみましょう。
1 2 3 4 5 6 7 | for(i=0; i<msize; i++) { for(j=0; j<msize; j++) { for(k=0; k<msize; k++) { c[i][j] = c[i][j] + a[i][k] * b[k][j]; } }} |
ベースラインの作成
最初の実行の経過時間は 53.94 秒でした。図 17 は、キャシュを意識したルーフライン・グラフです。赤く示されるドットは、ここで注目する計算主体のループです。これは DRAM 帯域幅を下回り、ここで達成しようとする最大帯域幅である L1 帯域幅は、はるか上方にあります。[サーベイ] ビューの [コード解析] タブで、ループがメモリー階層の各レベルで達成している正確な帯域幅を確認できます (図 18)。
パフォーマンスが低い原因は? どのように改善できるか? インテル® Advisor は、これらの問いに答えることができます。最初に、[サーベイ] ビュー (図 19) を調査して、何が起こっているのか、インテル® Advisor が何らかの推奨事項を示していないか確認します。インテル® Advisor は、非効率なメモリー・アクセス・パターンがあること、そして依存関係が想定されるためループがベクトル化されていないことを指摘しています。メモリー・アクセス・パターンを調べるには、メモリー・アクセス・パターン (MAP) 解析を実行します (図 20)。
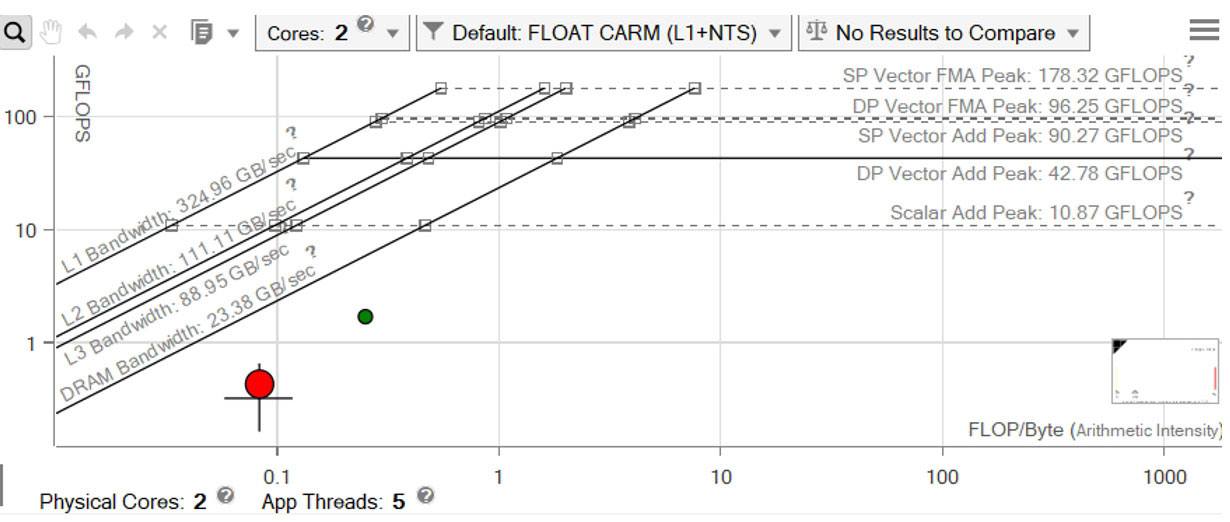
図 17 – キャシュを意識したルーフライン・グラフ
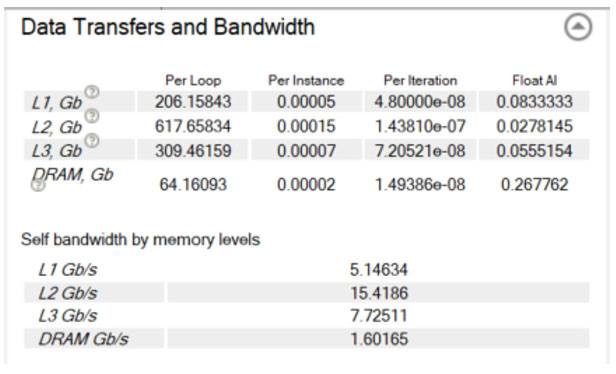
図 18 – データ転送と帯域幅

図 19 – サーベイビュー

図 20 – メモリー・アクセス・パターン (MAP) 解析
インテル® Advisor は、読み取りアクセスが定数ストライドで、書き込みアクセスが 0 のユニフォーム・ストライドであることを検出しました。アクセスされるメモリー範囲は 32MB であり、キャッシュサイズをはるかに上回っています (図 21)。また、MAP レポートでキャッシュがどの程度効率良く機能しているか確認できます (図 22)。ここでは、2300 を超えるキャッシュライン・ミスが観察されているため、パフォーマンスが低いのは当然です。この問題を解決するにはいくつかの方法があります。

図 21 – ストライド分散
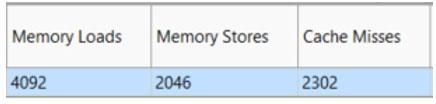
図 22 – MAP レポート
ステップ 1
ループ交換を行うと、定数ストライドが不要になり、また広範囲のメモリーにアクセスする必要もなくなります。また、#pragma ivdep を追加してコンパイラーにベクトル化を妨げる依存関係がないことを通知することで、ループをベクトル化することも可能です。
1 2 3 4 5 6 7 8 | for(i=tidx; i<msize; i=i+numt) { for(k=0; k<msize; k++) {#pragma ivdep for(j=0; j<msize; j++) { c[i][j] = c[i][j] + a[i][k] * b[k][j]; } }} |
経過時間は 4.12 秒となり、12 倍以上高速化されています。なぜパフォーマンスがこれほど向上したのでしょうか? まず、統合ルーフライン・グラフを調査します (図 23)。赤いドットはそれぞれ対応するメモリー階層の帯域幅を表します: L1、L2、L3、および DRAM。計算ループの L1 メモリー帯域幅を示す左端の赤いドットは、95GB/秒になりました。[サーベイ] ビュー (図 24) から、インテル® AVX2 命令を使用して 100% の効率でベクトル化されていることも確認できます。
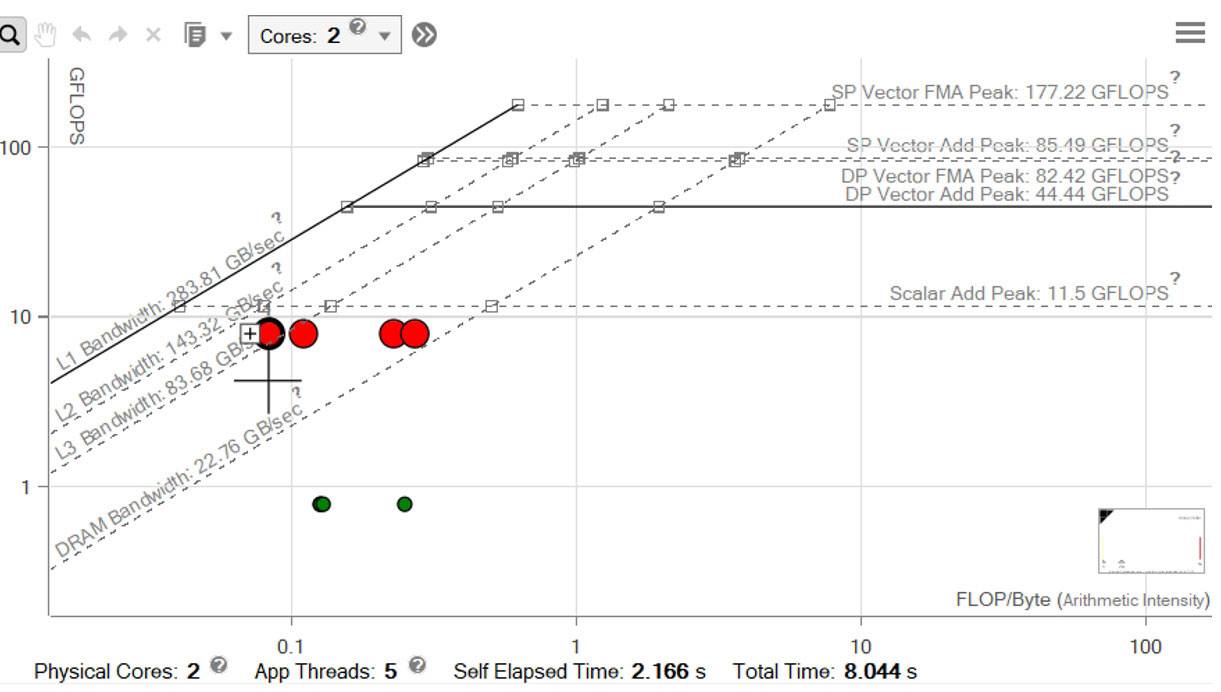
図 23 – 統合ルーフライン・グラフ

図 24 – サーベイビュー
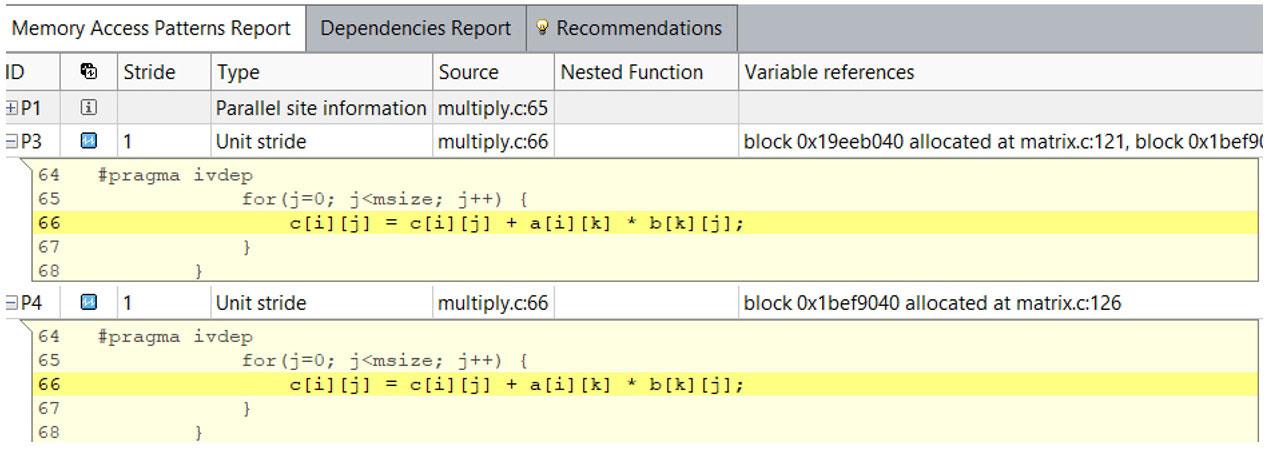
図 25 – MAP レポート
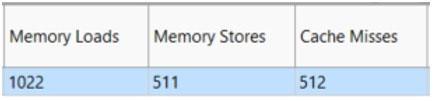
図 26 – キャッシュのパフォーマンス
ステップ 2
より狭い範囲のメモリーアクセスで計算できるようにキャッシュのブロッキングを実装します。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 | for (i0 = ibeg; i0 < ibound; i0 +=mblock) { for (k0 = 0; k0 < msize; k0 += mblock) { for (j0 =0; j0 < msize; j0 += mblock) { for (i = i0; i < i0 + mblock; i++) { for (k = k0; k < k0 + mblock; k++) { #pragma ivdep #ifdef ALIGNED #pragma vector aligned #endif // アライメント #pragma nounroll for (j = j0; j < 10 + mblock; j++) { c[i] [j] = c[i] [j] + a[i] [k] * b[k] [j]; } } } } }} |
上記のコードでは、計算をブロック単位で実行できるように、3 つの入れ子ループを追加しています。1 つのブロックを処理すると、次のブロックに進みます。キャッシュ・ブロッキングを実装したコードの経過時間は 2.60 秒となり、実装前から 1.58 倍高速化されています (図 27)。ループの L1 メモリー帯域幅は 182GB/秒に達し、L1 のルーフにかなり接近しています。ベクトル化とストライドに変わりはありませんが、内部ループのキャッシュミスは 15 回しかなく、アドレス範囲は 480 バイトに減少しています (表 3)。
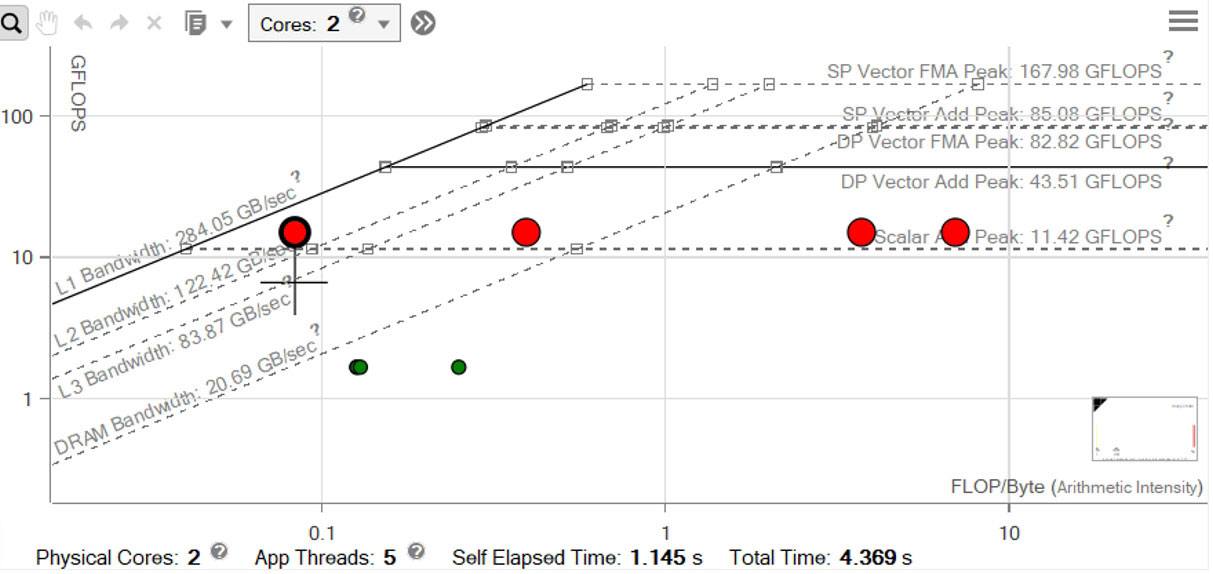
図 27 – パフォーマンスの改善
表 3. 結果のまとめ
| 実行 | 経過時間 (秒) | 合計 GFLOPS | メモリーアドレス範囲 | キャッシュミス | 改善 (時間) |
| ベースライン | 53.94 | 0.32 | 32MB | 2,302 | N/A ベースライン |
| ループ交換 | 4.19 | 4.17 | 16KB | 511 | 12.87x |
| ブロック化 | 2.6 | 6.61 | 480B | 15 | 20.74x |
メモリーアクセスの最適化
パフォーマンス向上には、プログラムのメモリーアクセスを最適化することが重要です。インテル® Advisor のようなツールを使用して、プログラムがどのようにメモリーをアクセスするか理解することは、ハードウェアのリソースを最大限に活用することにつながります。インテル® Advisor のルーフラインと統合ルーフライン機能を使用して、メモリーのボトルネックを視覚化することができます。ルーフラインとメモリー・アクセス・パターン解析を組み合わせることで、さらに多くのメモリー動作を観察することができます。
関連情報
謝辞
この記事は、インテルの技術季刊誌『The Parallel Universe』から抜粋したものです。最新のツール、ヒント、および専門知識を広げるトレーニングを提供し、ソフトウェア開発の未来を開きます。日本語版はこちらから入手できます。
コンパイラーの最適化に関する詳細は、最適化に関する注意事項を参照してください。
