
この記事は、インテル® デベロッパー・ゾーンに公開されている「Integrated Roofline Model with Intel® Advisor」(https://software.intel.com/en-us/articles/integrated-roofline-model-with-intel-advisor) の日本語参考訳です。
はじめに
インテル® Advisor はコードの特性を評価するため、キャッシュを考慮したルーフライン・モデル (CARM) の生成を完全に自動化したツールであり、ドメイン・エキスパートや HPC パフォーマンス・エキスパート向けの統合パフォーマンスのモデル化に役立ちます。ルーフライン・グラフを使用したパフォーマンスの分類により、プラットフォームの計算とメモリー能力のピークに対してアプリケーション・カーネルをプロットした総合的なグラフを提供します。CARM モデルは、アプリケーションで使用されるコードのタイプと注目すべきルーフ上のドットに対する基本的な計算やメモリーの制限に関する概要を示します。演算強度スケールの左端と右端に位置する計算集約型のコードとメモリー集約型のコードを簡単に特定できます。
キャッシュを考慮したルーフライン・モデル (CARM) は、アプリケーション・カーネルの累積 (L1 + L2 + LLC + DRAM) トラフィック・ベースの演算強度を表します。メモリーの移動はインストルメントによって検出され、インテル® Advisor はデータをレジスターに移動する命令を監視します。この方法では、データが DRAM とキャッシュレベルのどちらからもたらされるかは関係ありません。演算強度 (AI) は、特定のコードとプラットフォームの組み合わせにおいて不変です。CARM には許容可能なオーバーヘッド (およそ 7 倍) がありますが、結果の解釈はさまざまな理由で難しいことがあります。CARM を効率良く解釈するには、ユーザーはアプリケーションを深く理解している必要があります。特定のカーネルでパフォーマンスがルーフラインから離れている場合、さまざまな原因が考えられます (L2、L3、DRAM のボトルネック、非効率なベクトル化やスレッド化)。そして、ユーザーはアプリケーションの特性に基づいて CARM の解釈を変更する必要があります。アプリケーションを最適化する上で CARM の解釈が難しい場合であっても、演算強度はアルゴリズムを最適化しても安定しているため、特定のプラットフォームでアルゴリズムの特徴を理解する上で有用なツールとなります。
統合ルーフライン・モデルは、さらに詳しい解析を行いボトルネックの発生源を直接示します。
この記事で紹介するすべての機能は、記事の執筆時点では開発中のものであり、将来のインテル® Advisor では変更される可能性がありことに注意してください。この記事で紹介する手順は、インテル® Advisor 2019 Gold リリースを対象としています。
どのような仕組みか?
統合ルーフライン・モデルでは、インテル® Advisor はキャッシュ・シミュレーションによりすべてのタイプのトラフィック・データを収集します: CPU <-> メモリー・サブシステム (L1 + NTS メモリーアクセス)、L1 キャッシュ <-> L2 キャッシュ、LLC <-> DRAM。キャッシュのデフォルト設定は、解析を実行するシステムの構成が適用されます。そして、キャッシュヒット、ミス、排出は、階層内のすべてのキャッシュレベルでシミュレートされます。このデータを基に、インテル® Advisor は特定のキャッシュレベルのデータ転送量をカウントし、それぞれのループと各メモリーレベルの AI を計算します。この解析には時間がかかることから、オーバーヘッドを軽減するためインテル® Advisor はキャッシュシステム全体をシミュレートしません。シミュレーションは、キャッシュ全体のサブセットのみで行われます。シミュレーション後、インテル® Advisor はキャッシュ全体の結果を推測します。
一方のレベルから他方のレベルへのトラフィックの変化を観察し、これらのレベルで可能な限り高い帯域幅を表すルーフと比較することで、カーネルのメモリー階層のボトルネックを特定し、最適化の方針を決定します。

統合ルーフライン・モデルの利点は、それぞれのループを異なるキャッシュレベルで観察でき、演算強度と比較してパフォーマンスの低下がどこで発生しているか判断できることです。ただし、キャッシュ・シミュレーションを行うと、デフォルトの CARM モードに比べ解析が大幅に遅くなります。
インテル® Advisor で統合ルーフライン解析を実行

環境変数 ADVIXE_EXPERIMENTAL=int_roofline を設定して、インテル® Advisor が統合ルーフラインを取得する試験的な機能を有効にします。インテル® Advisor の試験的なルーフライン機能では、キャッシュ・シミュレーション技術に基づいて、ループや関数ごとのメモリー・トラフィックを推測します。ADVIXE_EXPERIMENTAL 環境変数を設定してインテル® Advisor の GUI を起動すると、インテル® Advisor の [プロジェクト・プロパティー] の [トリップカウント] セクションにあるチェックボックスを選択することで、キャッシュ・シミュレーションを有効にできます。
コマンドラインのトリップカウント解析で -enable-cache-simulation フラグを追加します (ADVIXE_EXPERIMENTAL=int_roofline を設定するのと同等)。-cache-config=yourconfighere フラグを使用して設定を指定できます。キャッシュ構成が設定されていないと、インテル® Advisor は使用中のシステムのキャッシュ構成を適用します。オプションで、特定のキャッシュ構成のシミュレーションを設定できます。その場合、レベル 1 から始まる「/」で区切ったそれぞれのキャッシュレベルを指定します。キャッシュ階層の設定は、GUI と CLI インターフェイスで同じ形式を使用します。各レベルは、[カウント:ウェイ:サイズ] の形式で指定します。
例えば、4:8w:32k/4:4w:256k/16w:6m は、次の構成を示します。
- 4 つの 8 ウェイ 32KB レベル 1 キャッシュ
- 4 つの 4 ウェイ 256KB レベル 2 キャッシュ
- (1 つの) 16 ウェイ 6MB レベル 3 キャッシュ
すべてのキャッシュのセット数は、64 の倍数でなければなりません (これはハードウェアの制限でもあります)。
このような高度な設定により、将来のハードウェア上のさまざまなメモリー階層におけるアプリケーションのメモリー・トラフィックの分散を調査するため、可能な限り多くの新しい解析が可能になります。
これらの設定により、CLI と GUI でルーフライン解析を実行できます。GUI 解析の場合、[ワークフロー] ウィンドウの [ルーフラインを実行] にある [Collect] ボタンをクリックします。CLI 解析では次のコマンドラインを使用します。
advixe-cl –collect roofline -enable-cache-simulation -- application_executable
複雑な起動スクリプトや設定が必要なアプリケーションでは、ショートカット・コマンド「-collect roofline」が常に使用できるとは限りません。また、このコマンドはインテル® MPI アプリケーションのデータ収集には使用できません。サーベイと FLOPS は個別に収集する必要があります。以下は、サーベイと FLOPS 解析をそれぞれ実行して統合ルーフライン・データを取得するコマンドシーケンスです。
advixe-cl -collect survey -project-dir MyResults – application_executable advixe-cl -collect tripcounts -enable-cache-simulation -flop -project-dir MyResults -- application_executable
以下は、インテル® MPI アプリケーションで統合ルーフライン解析を実行するコマンドラインの例です。
mpirun -n 1 -gtool "advixe-cl -collect survey -project-dir MyResults:0" application_executable mpirun -n 1 -gtool "advixe-cl -collect tripcounts -enable-cache-simulation -flop -project-dir MyResults:0" application_executable
結果を確認: ルーフラインとループ解析のトラフィック、帯域幅、ロードとストア
キャッシュ・シミュレーションに基づく統合ルーフライン解析は、アプリケーション内のメモリー操作に関する次のメトリックを提供します。この解析の基本的な考えは、主要な研究機関と米国の国立研究所および業界によって共同開発された論文「パフォーマンス特性を評価する新しい複数レベルの統合ルーフライン・モデルによるアプローチ」 (https://crd.lbl.gov/assets/Uploads/ISC18-RooflineAdvisor-final.pdf) で詳しく説明されています。
統合ルーフラインにおけるループ解析法
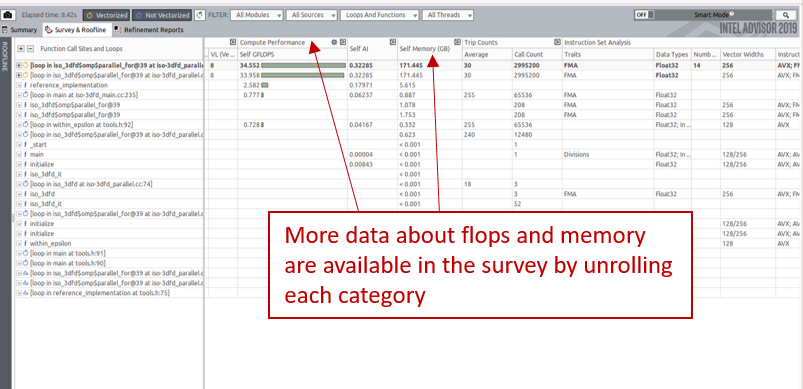
単一のループでは、関連する計算操作、1 秒あたりの操作、演算強度 (FLOP セクション)、ループのデータ転送、インスタンスと反復 (データ転送と帯域幅セクション) などの詳しい統計を取得できます。異なるメモリーレベル間の正確にシミュレートされたトラフィック数を確認します。

次の図に示すように、それぞれのカーネル固有のその他のデータもサーベイグリッドに表示できます。例えば、L2 にロードされたデータや L3 にストアされたデータ量を表示できます。
結果の解釈
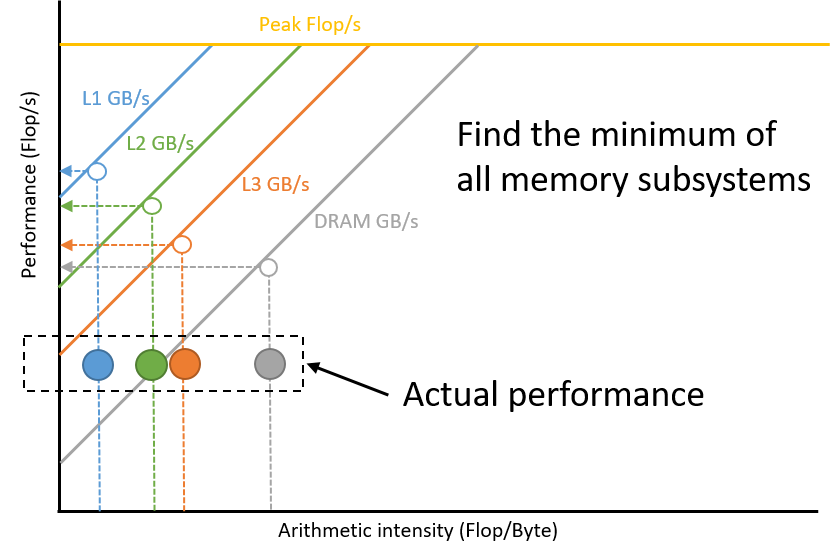
現時点のパフォーマンスの上限を見極めるには、各メモリー・サブシステムを調査して、適切なルーフラインの演算強度を予測します。パフォーマンスの上限は、すべての予測の最小値です。この手順はインテル® Advisor にまだ実装されていませんが、次の図に示すようにルーフライン・モデルを調べることで実行できます。パフォーマンスを制限するメモリー・サブシステムへのアクセスを最適化することで、より高いパフォーマンスを達成できます。例えば、DRAM によって制限されている場合、DRAM と L3 間の転送を最適化することで DRAM の演算強度が向上します。
統合ルーフライン・データの表示
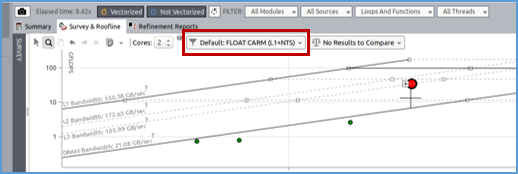
統合ルーフラインでは、データ転送が観測されたメモリーレベルで単一カーネルに複数のドットを表示できます。次の図の赤く囲まれたドロップダウン・メニューをクリックすると、GUI で特定のメモリーレベルを選択できます。
次に、カーネルの演算強度の計算に使用するメモリー・サブシステムを選択できます。
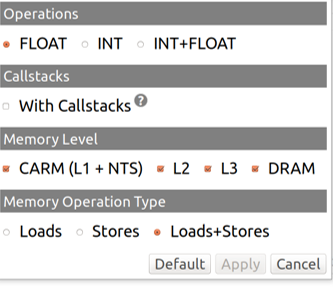
カーネルごとに複数のドットを表示でき、各ドットは異なるキャッシュレベルのトラフィックを基に計算された AI を持ちます。
異なるキャッシュレベルに基づくカーネルの演算強度を比較すると、以降で説明するように興味深い情報が得られます。
異なるキャッシュレベルに対し同時に要求を行うと視覚表示が複雑になるため、フィルター処理により対象のカーネルに絞り込むことができます。これは、対象のカーネルを右キリックして、[選択をフィルターイン] を選択して実行できます。この操作を行うと、インテル® Advisor は選択したカーネルに関連するデータのみを表示します。フィルターを解除するには、ルーフライン・モデルのグラフを右クリックして [フィルターをクリア] を選択します。
統合ルーフライン・モデルを注意深く観察すると、いくつかのボトルネックが分かります。
ベクトル化とスレッド化による改善の可能性
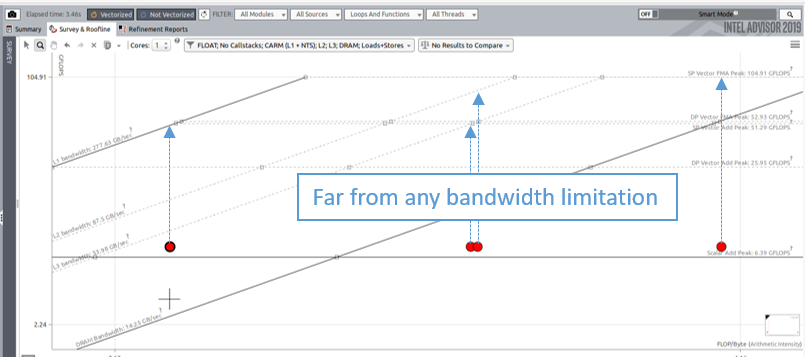
次の図は、ベクトル化またはスレッド化に関連する問題を示しています。あるカーネルのすべてのドットがそれぞれの帯域幅の上限から十分に離れている場合、スレッド化やベクトル化によって改善できる可能性があることを意味します。ベクトル化の場合、インテル® Advisor のサーベイは、より効率良いベクトル化を実現する方法に関する詳細情報を提供します。
キャッシュ・ブロッキングによる最適化
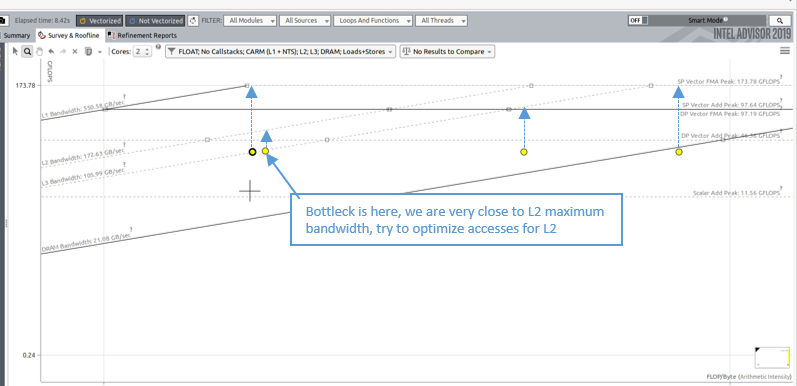
統合ルーフライン・モデルにより、アプリケーションのキャッシュの問題を検出できます。どのキャッシュレベルがボトルネックであるか検出することも可能です。次の図は、L2 上のデータアクセスによって制限されるパフォーマンスの例を示しています。このドットの演算強度を改善すると、パフォーマンスを向上する余地が増えます。L2 演算強度の改善は、L1 のデータを再利用するようにキャッシュ・ブロッキングを実装することで達成できます (この例の場合)。
統合ルーフラインのデータからヒントを得た、適用可能なメモリー最適化のガイドを示します。ループ・ブロッキング手法の詳細については、「ループ・ブロッキングによる 32 ビットインテル® アーキテクチャーのメモリー使用を最適化する方法」の記事をご覧ください。
| L1 パフォーマンスの最大化 | L2 パフォーマンスの最大化 | L3 パフォーマンスの最大化 | DRAM パフォーマンスの最大化 |
| 通常 CARM ルーフラインに近いとアルゴリズムは完全に最適化されており、それ以上の最適化によるパフォーマンス向上の余地は少ないことを意味します。
(CARM) |
L1 向けのキャッシュ・ブロッキング最適化により L2 AI を高めます。 | L2 向けのキャッシュ・ブロッキング最適化により L3 AI を高めます。 | データアクセスの改善 (ユニットストライド)、L3 キャッシュ・ブロッキングの改善 |
すべてのコードが、キャッシュを効率良く使用するループのブロッキングやタイリングが可能なわけではありません。
非効率的なアクセスパターン
統合ルーフライン・モデルを実行し、1 つのカーネルのすべてのキャッシュレベルを同時に表示すると、左から右に次の AI が表示されます。
- CARM 演算強度
- L2 演算強度
- L3 演算強度
- DRAM 演算強度
アプリケーションのメモリーアクセスが非効率であると、この左から右への順番 (CARM、L1、L2、L3、DRAM) で表示されないことがあります。その場合、L2 のドットは CARM のドットよりも左に現われる可能性があります。例えば、ランダム・メモリー・アクセスを行っている場合、すべてのアクセスが L1 キャッシュに存在しないと、L1 にキャッシュラインを格納する必要が生じます。このキャッシュラインの 1 つの要素のみを使用すると、レジスターに転送されるよりも多くのデータが L1 と L2 間でカウントされることが予測されます。統合ルーフライン・モデルでこの動作を観察する場合、インテル® Advisor のメモリー・アクセス・パターン解析 (MAP) を実行して、メモリーアクセスのタイプを特定できます。
非テンポラルストア (NTS) を多用すると、メモリー・サブシステムの演算強度が異なる順番で表示される可能性があります。
非テンポラルストア
キャッシュラインにデータを書き込む前に、プロセッサーはキャッシュラインを読み取ってキャッシュの一貫性を維持する必要があります。状況によっては、書き込むデータが近い将来に使用されないことが明確である場合、読み取る必要はありません。この場合、コンパイラーは非テンポラルストア命令 (NTS) を生成します。次に、キャッシュラインにデータを書き込む代わりに、データはメモリーに直接書き込まれます。NTS を使用すると、メモリー・サブシステムの演算強度も変わります。データの書き込みはキャッシュレベルではなく、CARM および DRAM レベルでのみ行われます。その結果、L3 AI よりも DRAM AI が低くなる可能性があります。
カーネルによっては、インテル® Advisor は NTS の使用を推奨することがあります。これは、推奨事項タブで確認できます。
まとめ
ホットなループや関数が、メモリー階層全体をどのように利用しているか解析することは、統計的な観察 (カウント、サンプリング) またはシミュレーションで解決できる重要なプログラミングの作業です。AI スケール (http://crd.lbl.gov/departments/computer-science/PAR/research/roofline/introduction/) で [中] または [低] レベルの演算強度を持つような多くのコードでは、最適化の方針を決定する上で、コードの特定の部分がメモリー・サブシステムをどのように使用しているか理解することが重要です。現在のハードウェアまたは将来のハードウェア・メモリー階層すべてのメモリーレベル間のトラフィックを推測する試験的な統合ルーフラインは、インテル® Advisor ルーフラインへ追加された役立つ機能です。この強力なツールにより、ユーザーは取り組む価値のある最適なボトルネックを特定できます。
コンパイラーの最適化に関する詳細は、最適化に関する注意事項を参照してください。
