
この記事は、インテル® デベロッパー・ゾーンに掲載されている「Integer Roofline Modeling in Intel® Advisor」(https://software.intel.com/en-us/articles/a-brief-overview-of-integer-roofline-modeling-in-intel-advisor) の日本語参考訳です。
概要
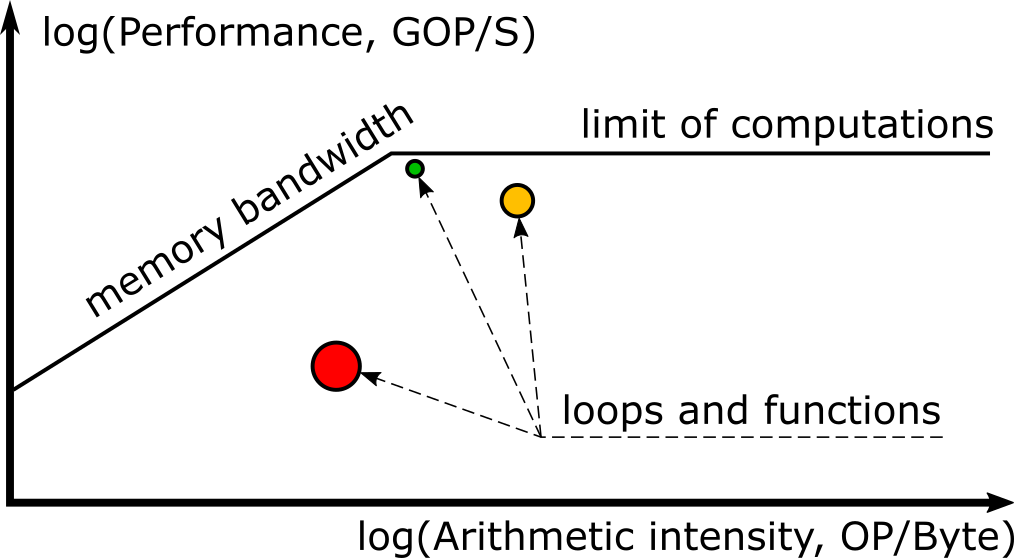
ルーフライン・グラフは、メモリー帯域幅や計算ピークを含む、ハードウェアの制限に関連したアプリケーションのパフォーマンスを視覚的に表現する機能です[1]。ルーフラインは、X 軸を演算強度 (操作/バイト)、Y 軸をパフォーマンス (ギガ単位の操作/秒) として、対数スケールで表現されます。グラフには、処理能力 (水平線) とメモリー帯域幅 (斜線) の上限を示す「ルーフ」と、アプリケーションのパフォーマンスを示すドットが表示されます。インテル® Advisor は、この情報を収集してインタラクティブなルーフライン・グラフに自動的に描画します。
最初にリリースされたルーフラインでは、浮動小数点計算の測定のみをサポートしていたため、利用できないアプリケーションもありました[2,3]。整数計算を多用するアプリケーション (マシンラーニングやビッグデータ主動のアプリケーション、データベース・アプリケーション、暗号化コインなどの金融アプリケーションなど) では、この強力な機能を利用できませんでした。
インテル® Advisor 2019[7] では、整数データを使用するアプリケーションを解析し、整数ベースのスカラーおよびベクトル計算ピークに関するルーフラインを生成する機能が追加されました。
整数ルーフライン・モデルの基本
メトリック
インテル® Advisor の整数ルーフラインは 2 つのメトリックをベースにしています。縦軸はパフォーマンスを示します。1 秒あたりの INT または INT + FLOAT 操作の数 (OPS) として計算される単純なメトリックです。横軸は演算強度 (AI) を示します。
整数計算
整数ルーフラインは継続して改良が行われており、INT 操作の厳密な定義は変わる可能性があります。現在は、ADD、ADC、SUB、MUL、IMUL、DIV、IDIV、INC/DEC、シフト、ローテ―トなどが、INT 操作としてカウントされています。厳密には計算ではないループカウンター操作 (INC/DEC、シフト、ローテ―ト) を除外して整数操作をカウントする場合、次の環境変数を設定します。
1 | ADVIXE_EXPERIMENTAL=intops_strict |
これにより、ADD、MUL、IDIV、および SUB 操作のみがカウントされます。
演算強度
演算強度[4] は、メモリーからリードされるデータと、そのデータに対する算術演算の関係を示します。アプリケーションが、合計 A バイトのメモリーをリードして、B のスカラー算術演算を行った場合、演算強度は次のように計算できます。
1 | 演算強度 = B/A |
例:
- アプリケーションは、2 つの 32 ビット整数 (a と b) をリードし、a + b を計算します。
演算強度 = 1 整数操作 / (2 メモリー操作 * 4 バイト) = 0.125 INTOP/バイト123
MOV eax, a//4 バイト・リードMOV ebx, b//4 バイト・リードADD eax, ebx//INTOP: eax = a + b - 2. アプリケーションは、3 つの 32 ビット整数 (a、b および c) をリードし、(a + c) * (a + b) を計算します。
演算強度 = 3 整数操作 / (3 メモリー操作 * 4 バイト) = 0.25 INTOP/バイト123456
MOV eax, a//4 バイト・リードMOV ebx, b//4 バイト・リードADD ebx, eax//INTOP: ebx = a + bMOV edx, c//4 バイト・リードADD eax, edx//INTOP: eax = a + cMUL ebx//INTOP: eax = (a + c) * (a + b)
ドットとライン

インテル® Advisor の整数ルーフライン・モデルは、アプリケーションを解析する前にいくつかのベンチマークを実行し、さまざまなメモリー階層レベルの帯域幅や計算上の制限など、システム・ハードウェアの制限を表示します。これらは、ルーフとしてグラフ上に表示され、最適化なしでマシンが提供できる最大パフォーマンスを示します。例えば、スカラー加算ピークは、ベクトル化なしで 1 秒間に処理できる加算演算の最大数を表します。

ルーフは利用されたコア数に比例します。デフォルトで、インテル® Advisor はアプリケーションが使用するスレッド数を自動的に検出して、適切なコア数を描画するようルーフラインを設定します。ユーザーは、必要に応じて GUI のドロップダウン・メニューから手動でスケーリングを設定できます。
グラフ上の各ドットは、解析したプログラムのループや関数に相当し、ルーフライン上の位置はそれぞれのパフォーマンスと演算強度を示します。また、ルーフラインに表示されるドットの大きさと色は、ループや関数が費やすプログラム時間を表しています。小さな緑のドットは消費時間が少ないため、最適化する必要はないと考えられます。大きな赤色のドットは最も時間を消費しており、特に最上部のルーフとの間に距離がある場合 (改善の余地が多い)、それらは最初に取り組むべき最適化の候補であると言えます。
整数ルーフライン解析を実行
ルーフライン・データの収集は、計算の種類にかかわらず同じく行われます。インテル® Advisor ユーザーズガイドにルーフライン・インターフェイスの機能とともに記載されています[5]。ルーフラインを収集する CLI コマンドと GUI のボタンがありますが、これらはサーベイ解析を行い、その後トリップカウントと FLOP 解析を行うショートカットです。データ収集が完了すると、サーベイとルーフラインにはデフォルトで浮動小数点の情報が表示されます。ルーフライン・グラフ上部のドロップダウン・メニューから、[INT] または [INT+FLOAT] データ表示に切り替えることができます。
整数ルーフラインの最適化
インテル® Advisor の整数ルーフラインを使用して、行列乗算関数を最適化してみましょう。低いパフォーマンスが予測されるループや関数は、ルーフライン・グラフの下の部分に表示されるため、まずここから調査を開始します。このサンプル・アプリケーションは、ほぼ乗算関数で構成されているため、ループを表すドットは大きくそして赤く表示され、最適化の過程を通してこの傾向は変わりません。実際のプログラムの一部として乗算関数が実行される場合、最適化の過程で全体の実行時間が短くなるのに比例して、ドットは小さくなると予想されます。

注: このルーフライン・グラフは、アプリケーションが 2 つのスレッドで構成されることを示していますが、実際の計算は 1 つのスレッドに集中しているため (一方はマスターでありスレッドの起動と設定を行う)、ルーフは 1 コアでスケールされています。
メトリックの計算
これらの数値の根拠を調査しましょう。グラフ上のドットは、multiply.cpp の 34 行目にあるループを示しています。
| 行 | ソース |
|---|---|
31 |
int i,j,k; |
msize は 2048 ですが、これはアンロールやベクトル化により実際のループ反復回数とは異なることがあります。アセンブリー命令を数えることで、インテル® Advisor と同じ方法で演算強度と GINTOPS を計算できます。
| アドレス | ソース 行 |
アセンブリー | コメント |
|---|---|---|---|
...15c3 |
35 |
movsxd r15, r15d |
4 バイト・リード |
このループは、24 バイトのデータにアクセスし、反復ごとに 8 つの整数計算を行っています。このコードが何回実行されたか、および実行に何秒かかったかが分かれば、いくつかのメトリックを計算できます。

必要な情報はサーベイレポートに示されます (トリップカウントはオプションであり、[トリップカウントと FLOP] 解析を選択して収集した場合にのみ表示されます)。1024 トリップ (ループ呼び出しあたりの反復回数) と 4,194,304 ループ呼び出しで、このコードの実行回数は合計 4,294,967,296 回です。
8 INTOP / 24 バイト = 0.333 INTOP/バイト (演算強度)
4,294,967,296 * 24 バイト = 103,079,215,104 バイト = 103.079GB アクセス
4,294,967,296 * 8 INTOP = 34,359,738,368 INTOP = 34.360 GINTOP
34.360 GINTOP / 157.378 秒 = 0.218 GINTOPS
これは、インテル® Advisor によって示される数値と同じであり、インテル® Advisor も同様の計算を行っていることが分かります。
ステップ 1: ベクトル化
インテル® Advisor がパフォーマンス・データを取得する方法が分かったので、コードの最適化を始めましょう。表示されるドットの上にあるラインは潜在的なボトルネックであり、ドットがラインに近づくと顕著になります。単純にルーフライン・グラフを見ると、DRAM 帯域幅を最初に検討すべきことが分かりますが、スカラーピークもかなり近いため、これもボトルネックとして検討する価値があります。ベクトル化は今後の最適化にも影響する可能性があり、サーベイレポートはこのループがスカラー (ベクトル化されていない) ことをすでに示しています。[推奨事項] タブは、この最適化は比較的容易であることを示しているため、最初に解決しておくことをお勧めします。

依存関係解析を実行すると、[読み取り後の書き込み] と [書き込み後の書き込み] 依存関係が示され、[推奨事項] タブにいくつかの解決方法が表示されます。そのうち 1 つがここで適用できます。

依存関係はリダクション・パターンによるものであるため、プラグマをコードに追加するとループがベクトル化できるようになります。これにより、SIMD (単一命令複数データ) 命令を使用して、多くのデータを処理できます。
1 2 3 4 5 6 7 8 9 | int i,j,kfor (i=0; i<msize; i++) { for (j=0; j<msize; j++) { #pragma omp simd reduction(+:c[i][j]) for (k=0; k<msize; k++) { c[i][j] += a[i][k] * b[k][j]; } }} |
注: 複数の SIMD 命令セットがありますが、最新の命令セットはインテル® アドバンスト・ベクトル・エクステンション 512 (インテル® AVX-512) です。これは、ベクトルレジスターの選択したレーンに対して SIMD 命令を実行する演算マスクレジスターを備えています。整数ルーフラインは開発が進められている機能であり、このリリースではインテル® AVX-512 命令の “マスク利用率” 情報のみが取得され、インテル® AVX-512 をサポートするハードウェアのみで機能します。
ステップ 2: 行列転置

ヒント: サーベイとルーフラインは、並べて表示できます。ルーフラインでドットをクリックすると、サーベイレポートの対応するループが強調表示されます。その逆も同様です。

ループはベクトル化されていますが、効率バーは灰色で、スカラーのセルフ値と比較してスピードアップがそれほど高くないことを示しています。推奨事項は、アクセスパターンが悪くベクトル効率が低下している可能性があることを示しています。さらに、これにより過度のキャッシュミスが引き起こされる可能性があるため、メモリーとベクトル化の両方のボトルネックになることが考えられます。メモリー・アクセス・パターン (MAP) 解析を実行して、問題を確認します。
これは驚くべきことではありません。行列乗算には、ある行列の行と別の行列の列の読み取りが含まれます。C/C++ では、データは行優先で格納されるため、1 つの要素をロードすると後続のいくつかの要素がキャッシュに格納され高速にアクセスできます。そのため、行から後続の要素を読み取るのが効率的です。しかし、列から後続の要素を読み取るのには時間がかかります。ある行の連続した要素をキャッシュに格納しても、次のロードが別の行から行われるためです。Fortran では、データは列優先で格納されるため、状況は逆になりますが、最終的な結果は同じです。行列の 1 要素が非効率な順番で横断されます。この問題を解決するには、列が行になるように非効率な行列を転置することです。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 | int i,j,kfor (i=0; i<msize; i++) { for (j=0; j<msize; j++) { t[i][j] = b[j][i] }}for (i=0; i<msize; i++) { for (j=0; j<msize; j++) { #pragma omp simd reduction(+:c[i][j]) for (k=0; k<msize; k++) { c[i][j] += a[i][k] * t[j][k]; } }} |
ステップ 3: 改善された命令を使用


行列転置はパフォーマンスを大きく向上させました。そして、ベクトル化されていないにもかかわらず、ループはスカラー加算ピークに位置しています。インテル® Advisor は、このマシンで利用可能な最上位の命令セットを使用していないことを通知しています。ベクトル効率は 98% を示していますが、この値は命令セットに合わせて調整されます。このコードをコンパイルした際に、命令セットが指定されていないためデフォルトのインテル® ストリーミング SIMD 拡張命令 2 (インテル® SSE2) が使用されています。これは、スカラーに対して整数ループが最大 4 倍高速化される利点があります。このマシンで利用可能な最上位のインテル® AVX2 命令セットでは、その 2 倍のパフォーマンスを提供できます。コードをコンパイルする際に適切なオプションを使用するだけでこれを活用できます。
ステップ 4: キャッシュ・ブロッキング

一見すると、この変更はループの演算強度と GINTOPS の両方を低下させているため、パフォーマンスに悪影響を与えているように思われますが、セルフ時間はループが高速化されていることを示しています (現在は 4.280 秒、以前は 5.021 秒)。これは、インテル® SSE2 命令は 1 回の操作で 4 つの整数を処理するのに対し、インテル® AVX2 は 8 つの整数を処理できるため、命令数が減少したことを意味します。バイト数は同一であるため、演算強度が低下しています。さらに、これらの命令はインテル® SSE2 命令よりもわずかに遅くなりますが、インテル® SSE2 よりも多くの処理を行います。ワークは高速になりますが、1 秒あたりに処理される命令数が減るため、GINTOPS は低くなります。

ここまでスカラー加算ピークについて触れましたが、次に調査する必要があるメモリー帯域幅について考えてみましょう。また、別の MAP 解析は、メモリー使用量がまだ理想からはかけ離れていることを示しています。ここでは、それほどストライドは離れていません。

単純に行列全体を順番に処理するだけでは、同じデータが必要以上に再ロードされます。これは、単純なアニメーションで証明できます。この例では、各ラインに 2 つの要素を保持する 10 個の小さなキャッシュラインを保持できる縮小キャッシュを使用して、4×4 行列を乗算します。この例の行は、参照されてから時間が経過すると排出されます。

あるキャッシュ階層レベルにデータを収めてタイル全体で計算できるように結果行列を分割すると、一度に 1 つのタイルを計算することで、その階層レベルのキャッシュミスを最小限に抑えることができます。アニメーションの例でも、この手法の利点が分かります。いくつかの数式により、実際のタイルに最適なサイズを求めることができます。512KB の L2 キャッシュ向けにブロッキングします。
キャッシュサイズ >= データ型サイズ * (N2 + 2 * (N * 行列の幅))
524288 バイト >= 4 バイト * (N2 + 2 * (N * 2048))
131072 >= N2 + 4096N
要件を満たす N の最大数は 31 ですが、この数では行列のサイズを均等に分割できません。32 で分割すると、データセットは L2 よりもやや大きくなるものの、キャッシュミスがわずかになり、行列をタイリングすることで得られる再利用の恩恵以上のものが得られます。CHUNK_SIZE を 32 にすることで、コードがキャッシュを再利用するようにブロック化できます。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 | int i,j,k,ichunk,jchunk,ci,cj;for (i = 0; i < msize; i++) { for (j = 0; j < msize; j++) { t[i][j] = b[j][i]; }}for (ichunk = 0; ichunk < msize; ichunk += CHUNK_SIZE) { for (jchunk = 0; jchunk < msize; jchunk += CHUNK_SIZE) { for (i = 0; i < CHUNK_SIZE; i++) { ci = ichunk + i; for (j = 0; j < CHUNK_SIZE; j++) { cj = jchunk + j; #pragma omp simd reduction(+:c[ci][cj]) for (k = 0; k < msize; k++) { c[ci][cj] += a[ci][k] * t[cj][k]; } } } }} |
ステップ 5: データのアライメント

グラフ上ではそれほど改善されていないように見えるかもしれませんが、ルーフラインの軸は対数スケールであることを留意してください。ループのセルフ時間はほぼ半分になりました (4.280 秒から 2.721 秒)。しかし、ループを L2 向けにブロック化したにもかかわらず、ドットが L3 ラインの下方にあります。


[コード解析] タブには、コンパイラーの記録など多くの有用な情報が示されます。ここでは、ループ内にアライメントされていないアクセスがあることが分かります。アライメントされていないデータアクセスは回避できないわけではありませんが、多くのメモリー操作が必要になります。これは、[コード解析] タブの命令ミックスのサマリーで確認できます。この場合、2 種類の命令ミックスは同じですが、コードは異なる条件式を含む可能性があります。静的命令ミックスは単純にコード内の命令をカウントするのに対し、動的命令ミックスは実行時にループで実行された命令数をカウントします。計算に対するメモリーの一般的な比率から、どのボトルネックが適用されるか情報を得ることができます。
配列を確実にアライメントするには、_mm_malloc() または同等のコンパイラー/OS 呼び出しを使用して配列を割り当てます。また、乗算関数に渡される配列がオーバーラップしないことをコンパイラーに知らせるため、コンパイラー・オプション (/Oa や -fno-alias) を使用しても良いでしょう。ループ自体の変更は、新しいプラグマを追加するだけです。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 | int i,j,k,ichunk,jchunk,ci,cj;for (i = 0; i < msize; i++) { for (j = 0; j < msize; j++) { t[i][j] = b[j][i]; }}for (ichunk = 0; ichunk < msize; ichunk += CHUNK_SIZE) { for (jchunk = 0; jchunk < msize; jchunk += CHUNK_SIZE) { for (i = 0; i < CHUNK_SIZE; i++) { ci = ichunk + i; for (j = 0; j < CHUNK_SIZE; j++) { cj = jchunk + j; #pragma vector aligned #pragma omp simd reduction(+:c[ci][cj]) for (k = 0; k < msize; k++) { c[ci][cj] += a[ci][k] * t[cj][k]; } } } }} |
.")
データをアライメントすることで、不要なメモリー命令が排除され、ドットが L2 帯域幅ラインまで上昇しました。技術的にはまだ最適化の余地がありますが、この時点でループの実行時間は 1 秒未満です。インテル® Advisor の指示に従うことで、最初の 157.378 秒から 0.983 秒まで 160 倍のスピードアップを達成できました。

参考資料
- ルーフライン・パフォーマンス・モデル – ローレンス・バークレー国立研究所のウェブサイト (http://crd.lbl.gov/departments/computer-science/PAR/research/roofline/)
- インテル® Advisor の浮動小数点演算向けのルーフライン (英語)
- インテル® Advisor チュートリアル: 自動ルーフライン・グラフを使用して最適化を決定 (英語)
- 演算強度の測定 – 国立エネルギー研究科学計算センターのウェブサイト
(http://www.nersc.gov/users/application-performance/measuring-arithmetic-intensity/) - インテル® Advisor ウェブサイト
- インテル® Advisor リリースノート (英語)
コンパイラーの最適化に関する詳細は、最適化に関する注意事項を参照してください。
