
この記事は、インテル® デベロッパー・ゾーンに公開されている「Intel® Advisor Tutorial: Use the Automated Roofline Chart to Make Optimization Decisions」の「Run a Roofline Analysis」の日本語参考訳です。
バージョン: 2021.1 (更新日: 12/04/2020)
このトピックは、自動ルーフライン・グラフを使用して、優先度の高い最適化を決定する方法を紹介するチュートリアルの一部です。
以下のステップを実行します。
このトピックでは、以下について説明します。
- ルーフライン解析は、サーベイ解析と続けて実行されるトリップカウント & FLOP 解析の組み合わせです。トリップカウント & FLOP 解析の実行には、サーベイ解析の 3 ~ 4 倍の時間がかかる場合があります。
- ルーフライン・グラフの各ドットの大きさと色は、各ループ/関数の相対実行時間を表しています。大きな赤いドットは最も多くの時間を費やしており、小さな緑のドットは実行時間が短いことを示します。
- ルーフライン・グラフの水平ライン (ルーフライン) は、計算能力の上限を示しており、最適化なしではループ/関数のパフォーマンスをこれ以上高めることはできません。
- ルーフライン・グラフの斜めのラインはメモリー帯域幅の上限を示しており、最適化なしではこれ以上のパフォーマンスは期待できません。
- 最上部のルーフラインはマシンの最大能力を示すため、ドットはこれを超えることはありません。また、すべてのループがマシンの最大能力を利用できるわけではありません。
- パフォーマンスを最大限に向上させる最良の候補は、最上部の達成可能なルーフラインから最も離れた大きな赤いドットです。
- ルーフライン・グラフには、外観を設定したり、興味のあるデータに注目するための各種コントロールがあります。
ルーフライン解析の実行
[Vectorization Workflow] ペインで [Run Roofline] の下にある ![インテル® Advisor コントロール: [Run Roofline]](https://www.isus.jp/wp-content/uploads/image/852_advisor-tutorial-roofline_run_analysis_figure1.gif) コントロールをクリックして、ターゲット・アプリケーションを 2 回実行します。
コントロールをクリックして、ターゲット・アプリケーションを 2 回実行します。
- サーベイ解析でマシンのハードウェア制限を測定し、ループ/関数のタイミング情報を収集します。
- トリップカウント & FLOP 解析で FLOP データを収集します。この収集には、サーベイ解析の 3 ~ 4 倍の時間がかかります。
完了すると、インテル® Advisor は ルーフライン・グラフを表示します。
注
Visual Studio* IDE に [Workflow] が表示されない場合: インテル® Advisor ツールバーの ![]() アイコンをクリックします (表示には数秒かかる場合があります)。
アイコンをクリックします (表示には数秒かかる場合があります)。
ルーフライン・グラフの表示/非表示
ルーフライン・グラフを表示/非表示にするコントロールがいくつかあります。
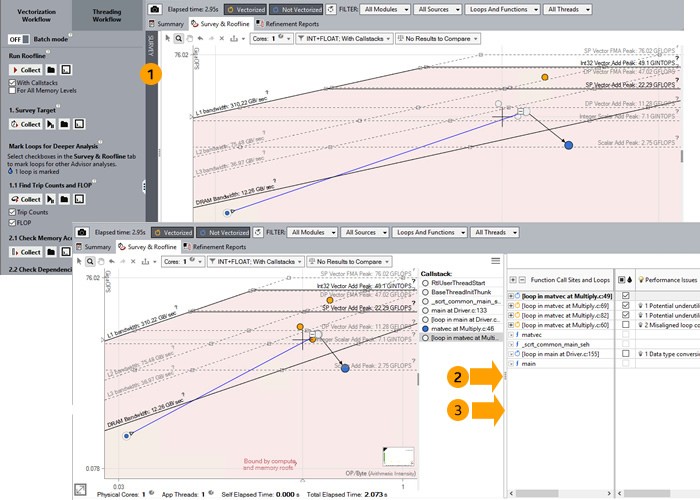
| 1 | クリックして、ルーフライン・グラフとサーベイレポートの表示を切り替えます。 |
| 2 | クリックして、ルーフライン・グラフとサーベイレポートを並べて表示/個別に表示します。 |
| 3 | ドラッグして、ルーフライン・グラフとサーベイレポートのサイズを調整します。 |
ヒント
このチュートリアルの以降の説明では、ルーフライン・グラフとサーベイレポートを並べて表示します。
ルーフライン・グラフのデータの理解
ルーフライン・グラフは、マシンの達成可能な最大パフォーマンスに対して、アプリケーションの実際のパフォーマンスと演算強度を視覚的に示します。
- 演算強度 (x 軸) – ループ/関数のアルゴリズムを基に、CPU/GPU とメモリー間で転送された 1 バイトあたりの浮動小数点操作数 (FLOPs) または整数操作数 (INTOPs) で測定されます。
- パフォーマンス (y 軸) – 1 秒あたりの 10 億浮動小数点演算数 (GFLOPS) または 10 整数演算数 (GINTOPS) で測定されます。
一般に、以下のことが言えます。
ルーフライン・グラフの各ドットの大きさと色は、各ループ/関数の相対実行時間を表しています。大きな赤いドットは最も多くの時間を費やしているため、最適化の最良の候補です。小さな緑のドットは実行時間が短いため、最適化の労力が無駄になるかもしれません。
- ルーフライン・グラフの斜めのラインはメモリー帯域幅の上限を示しており、最適化なしではこれ以上のパフォーマンスを達成することはできません。例えば、L1 Bandwidth ルーフラインは、ループが常に L1 キャッシュにヒットする場合にある演算強度で実行できる最大作業量を示します。ループは、データセットが L1 キャッシュを頻繁にミスする場合、L1 キャッシュの速度の恩恵を受けられず、代わりに低速な L2 キャッシュにより制限されます。L1 キャッシュを頻繁にミスして L2 キャッシュにヒットするループのドットは、L2 Bandwidth ルーフラインの下に表示されます。
- ルーフライン・グラフの水平ライン (ルーフライン) は、計算能力の上限を示しており、最適化なしではループ/関数のパフォーマンスをこれ以上向上することはできません。例えば、Scalar Add Peak は、この状況下でスカラーループが実行可能な加算命令の最大数を示します。Vector Add Peak は、この状況下でベクトルループが実行可能な加算命令の最大数を示します。そのため、ベクトル化されていないループのドットは、Scalar Add Peak ルーフラインの下に表示されます。
- 最上部のルーフラインはマシンの最大能力を示すため、ドットはこれを超えることはありません。また、すべてのループがマシンの最大能力を利用できるわけではありません。
- ドットと最上部の達成可能なルーフラインの間の距離が大きいほど、パフォーマンス向上の可能性が高くなります。
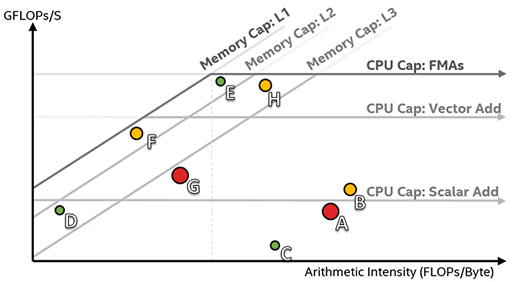
以下のルーフライン・グラフでは、ループ A と G (大きな赤いドット)、そして B (ルーフから離れている黄色のドット) が最適化の最良の候補です。ループ C、D、E (小さな緑のドット) と H (黄色のドット) は、パフォーマンス向上の余地があまりないか、パフォーマンスに大きな影響を与えるには小さすぎるため候補にはなりません。
注
ルーフライン・グラフとサーベイレポートは同期されています。ルーフライン・グラフのドットをクリックすると、サーベイレポートで対応するデータ行がハイライト表示され、サーベイレポートでデータ行をシングルクリックすると、ループに浮動小数点操作が含まれていればルーフライン・グラフで対応するドットが点滅します。浮動小数点操作を含まないループはルーフライン・グラフに表示されません。
ルーフライン・グラフで各ルーフライン (ライン)、ピーク (長方形)、ループ (ドット) にマウスのカーソルを合わせると、各要素の説明が表示されます。
ルーフライン・グラフのコントロールの理解
以下を含む、いくつかのコントロールを利用してルーフライン・グラフの重要なデータに注目できます。
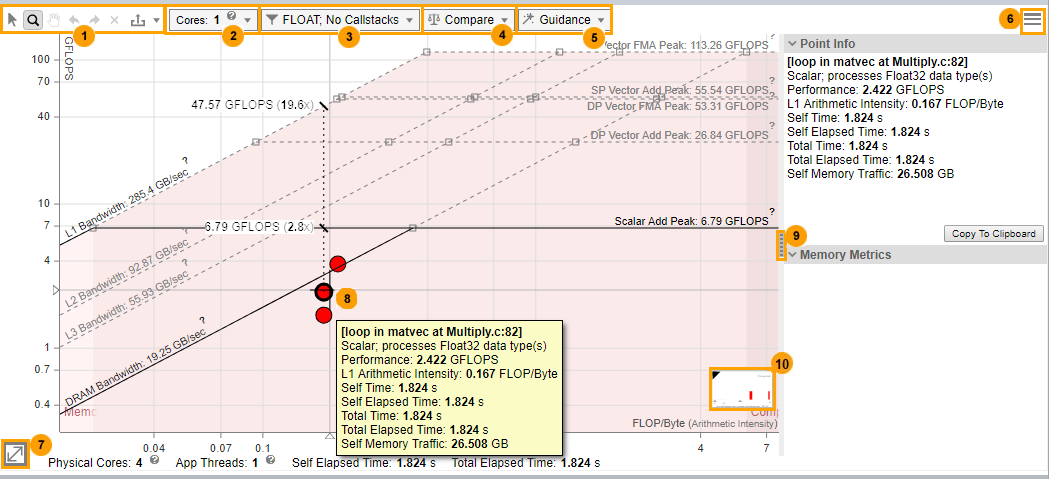
| 1 |
|
| 2 | [Cores] ドロップダウン・ツールバーを使用して、以下を行うことができます。
適切な CPU コア数を選択して、ルーフの値を増減できます。
デフォルトでは、コア数はアプリケーションで使用されるスレッド数 (偶数値) に設定されています。 コードをマルチソケット PC で実行する場合、次のオプションが表示されます。
|
| 3 |
|
| 4 | 比較のため、インテル® Advisor のほかの結果やアーカイブされていないスナップショットからルーフライン・グラフのデータを表示します。 ドロップダウン・ツールバーを使用して、次の操作を行うことができます。
現在の結果でループ/関数のドットをクリックすると、そのドットとロードされた結果/スナップショットにある対応するループ/関数のドットの関係 (矢印のライン) が表示されます。
|
| 5 | ルーフライン・グラフにビジュアル・インジケーターを追加して、パフォーマンスの制限や、ループ/関数がメモリー依存か、計算依存か、あるいは両方かなど、データを解釈しやすくします。 ドロップダウン・ツールバーを使用して、次の操作を行うことができます。
ガイダンスオプションを選択するとプレビュー画像が更新され、変更内容をルーフライン・グラフの外観に反映した状態を確認できます。変更を適用するには [Apply] をクリックし、ルーフライン・グラフの外観をデフォルトの状態に戻すには [Default] をクリックします。 ループ/関数のドットがハイライト表示されたら、ループ/関数をもう一度ダブルクリックするか、ループ/関数を選択した状態でスペースキーまたは Enter キーを押して、選択したループ/関数のドットにルーフライン・グラフをズームできます。オリジナルのルーフライン・グラフ表示に戻るまでこのアクションを繰り返します。 ラベル付けされたドットを非表示にするには、別のループ/関数を選択するか、ルーフライン・グラフの空白の領域をダブルクリックします。 |
| 6 |
ルーフの設定やドットの重み表現の設定を JSON ファイルに保存したり、カスタム設定をロードできます。 |
| 7 | 数値を使用して拡大/縮小できます。 |
| 8 | ループ/関数のドットをクリックして、次の操作を行うことができます。
ループ/関数のドットか、ルーフライン・グラフの空白の領域を右クリックして、以下のような操作を行うことができます。
|
| 9 | メトリックペインを表示/非表示にします。
|
| 10 | 各ループの重み表現カテゴリーのループの数と割合を表示します。 |
![インテル® Advisor: [Roofline Comparison]](https://www.isus.jp/wp-content/uploads/image/852_advisor-tutorial-roofline_run_analysis_figure4.jpeg)
このチュートリアルの以降の説明では、時間とハードウェア依存性を考慮して、事前に収集された解析結果を使用します。
製品および性能に関する情報
1 性能は、使用状況、構成、その他の要因によって異なります。詳細については、www.Intel.com/PerformanceIndex/ (英語) を参照してください。
