
この記事は、インテル® デベロッパー・ゾーンに公開されている「Intel® Advisor Tutorial: Use the Automated Roofline Chart to Make Optimization Decisions」の「Address Compute Capacity Bottlenecks」の日本語参考訳です。
バージョン: 2021.1 (更新日: 12/04/2020)
このトピックは、自動ルーフライン・グラフを使用して、優先度の高い最適化を決定する方法を紹介するチュートリアルの一部です。
以下のステップを実行します。
このトピックでは、以下について説明します。
- 演算強度 (ルーフライン・グラフの x 軸) = アクセスされるバイトあたりの浮動小数点操作数。すべてのアルゴリズムに演算強度があります。理論的には、このメトリックはアルゴリズム自体の特性であるため、最適化により変化することはありません。つまり、ルーフライン・グラフ上のドットは、パフォーマンスの変化に応じて上下には移動しますが、左右に移動することはめったにありません。
- ループを最適化しただけでは、対応するドットを次のルーフラインに移動できません。ループが最適化を上手く利用している必要があります。非効率なベクトル化や孤立した FMA (Fused Multiply Add) を最適化しただけでは十分ではありません。
- 適切な状況下では、データレイアウトとメモリーアクセスを最適化することで、計算能力とメモリー帯域幅の両方の制限を解決できます。
- [Recommendations] タブで「how-can-I-fix-this-issue?」にあるコード固有の推奨事項を利用できます。
注
時間とハードウェア依存性を考慮して、ここでは事前に収集された解析結果を使用します。
結果のスナップショットを開く
次のいずれかの操作を行います。
- スタンドアロン GUI: [File] > [Open] > [Result] から Result2.advixeexpz 結果を選択します。
- Visual Studio* IDE: [File] > [Open] から Result2.advixeexpz 結果を選択します。
最も興味のあるルーフライン・グラフのデータに注目
- 表示の切り替えを使用して、ルーフライン・グラフとサーベイレポートを並べて表示します。
- インテル® Advisor ツールバーの [Loops And Functions] フィルター・ドロップダウンから [Loops] を選択します。
![インテル® Advisor: [Filters]](https://www.isus.jp/wp-content/uploads/image/854_advisor-tutorial-roofline_compute_capacity_figure1.jpeg)
- ルーフライン・グラフで次の操作を行います。
- [Use Single-Threaded Loops] チェックボックスをオンにします。
![インテル® Advisor: [Roofline] メニュー](https://www.isus.jp/wp-content/uploads/image/854_advisor-tutorial-roofline_compute_capacity_figure2.gif) コントロールをクリックして、すべての SP… ループの [Visibility] チェックボックスをオンにします (このサンプルコードの変数はすべて倍精度であるため、単精度のルーフラインを非表示にします)。
コントロールをクリックして、すべての SP… ループの [Visibility] チェックボックスをオンにします (このサンプルコードの変数はすべて倍精度であるため、単精度のルーフラインを非表示にします)。![インテル® Advisor: [Roofline] メニュー](https://www.isus.jp/wp-content/uploads/image/854_advisor-tutorial-roofline_compute_capacity_figure3.jpeg)
[Point Colorization] セクションで [Vectiorized/Scalar] を選択して、ランタイム (赤、黄、緑) の代わりに、スカラー (青)/ベクトル (オレンジ) で色分けします。
 をクリックして変更を保存します。
をクリックして変更を保存します。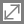 コントロールをクリックします。x 軸のフィールドで既存の値を Backspace キーで消去し、0.1 と 0.8 を入力します。y 軸のフィールドで既存の値を Backspace キーで消去し、3.1 と 45.5 を入力します。
コントロールをクリックします。x 軸のフィールドで既存の値を Backspace キーで消去し、0.1 と 0.8 を入力します。y 軸のフィールドで既存の値を Backspace キーで消去し、3.1 と 45.5 を入力します。![インテル® Advisor: [Save] コントロール](https://www.isus.jp/wp-content/uploads/image/854_advisor-tutorial-roofline_compute_capacity_figure6.gif) ボタンをクリックして変更を保存します。
ボタンをクリックして変更を保存します。
ルーフライン・グラフのデータの解釈
ルーフライン・グラフで、roofline.cpp:221 の main にあるループを表す青いドットは、Vector Add Peak ルーフラインと Scalar Add Peak ルーフラインの下にあります。
その原因は、ドットの色が示すように、ループがベクトル化されていないためであると考えられます。これは、サーベイレポートの最初の列にあるスカラーの状態でも確認できます (青いアイコン = スカラー、オレンジのアイコン = ベクトル)。このチュートリアルでは、ディレクティブを使用してループがベクトル化されないようにしています。インテル® Advisor には、ループがベクトル化されなかった理由を診断するさまざまなツールがあり、実際に問題があった場合はこれらのツールを使用できます。
roofline.cpp:247 の main にあるループは、roofline.cpp:221 の main にあるループのベクトル化されたバージョンです。
ルーフライン・グラフでは、このループを表す一番下のオレンジのドットの位置が、演算強度軸上で左へ移動しています。これは、理論的にはありえないことです。演算強度は転送されたバイトあたりの浮動小数点操作数を示すもので、すべてのアルゴリズムには演算強度があり、このメトリックはアルゴリズム自体の特性であるため、最適化により変化しません。つまり、ルーフライン・グラフ上のドットは、パフォーマンスが向上すると上方向に移動しますが、通常は左右に移動することはありません。
コンパイラーの最適化により、roofline.cpp:247 の main にあるループの演算強度が変わっています。
何が起きたのでしょうか?
[Code Analytics] タブで、青いドットとオレンジのドットの両方のループの [GFLOPS] ドロップダウンをチェックします。
![インテル® Advisor: [Code Analytics] タブ](https://www.isus.jp/wp-content/uploads/image/854_advisor-tutorial-roofline_compute_capacity_figure8.jpeg)
両方のループの統計を並べて確認すると、ベクトル化されたループの反復ごとのセルフ FLOP に違いが見られます。ループのベクトル長は 4 であるため、8*4=32 でこれは理にかなっています。合計と反復ごとのデータ転送値が変わっています。256 という値はベクトル化によって説明できません。ベクトル化により変わったのであれば、48*4=192 となり、256 にはなりません。
| メトリック | スカラーループ (青いドット) | ベクトル化されたループ (一番下のオレンジのドット) |
|---|---|---|
| 反復ごとのセルフ FLOP | 8 | 32 |
| データ転送: 合計ギガバイト | 318.720 | 424.960 |
| データ転送: ループ反復ごとのバイト数 | 48 | 256 |
この統計から、コンパイラーによってメモリーアクセスが変更されたことが分かります。[Code Analytics] タブからも分かるように、新しいアンパック命令と挿入命令がメモリー計算に影響を与えている可能性があります。
roofline.cpp:247 の main にあるループに関してもう 1 つ気になることは、ルーフライン・グラフで、ループを表す一番下のオレンジのドットが Scalar Add Peak ルーフラインのすぐ上にあることです。
原因として、ループが効率良くベクトル化されていない可能性が考えられます。
これを検証するため、以下の操作を行います。
サーベイレポートで、[Vectorized Loops/Efficiency] の値を確認すると 31% です。ベクトル化が十分ではないため、ループは Vector Add Peak ルーフラインに近づくことができません。ループを効率良くベクトル化する必要があります。
[Efficiency] 値が非常に低い原因として、非効率なメモリーアクセスにより、VPU/SIMD リソースが最大限に活用されていない可能性が考えられます。これは、構造体配列 (AOS) データレイアウトでよくある問題です。メモリー・アクセス・パターン・レポートを確認します。
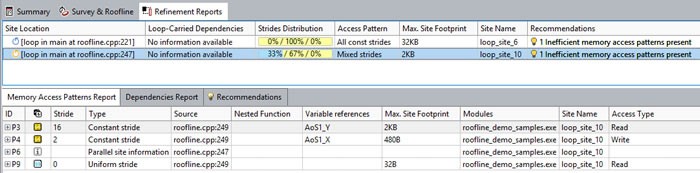
メモリーアクセスの問題が確認されました。ほとんどのメモリーアクセスが均一ストライドではありません ([Code Analytics] タブの挿入操作からもこれを確認できます)。これは、ベクトル化の非効率性を助長します。
ベクトル化の効率を改善するため、次の操作を行います。
構造体配列 (AOS) の代わりに、配列構造体 (SOA) データレイアウトを使用するようにコードを再構成します。これは、最適化のアドバイスとして、[Recommendations] タブにも記載されています。
![インテル® Advisor: [Recommendations] タブ](https://www.isus.jp/wp-content/uploads/image/854_advisor-tutorial-roofline_compute_capacity_figure10.jpeg)
roofline.cpp:260 の main にあるループ (真ん中のオレンジのドット) にこの変更を適用しました。
このトッドは、Vector Add Peak ルーフラインのすぐ下にあります。サーベイレポート で、[Vectorize Loops/Efficiency] の値を確認すると 100% です。
このドットは L3 キャッシュによって制限されることがなく、L2 キャッシュによる制限もごくわずかであるため、メモリー帯域幅ルーフラインもスキップしています。
このため、SOA データレイアウトに変更することで、計算能力とメモリー帯域幅の両方のボトルネックが解決されました。
最後に、roofline.cpp:273 の main にあるループ (一番上のオレンジのドット) を見てみましょう。ドットが Vector Add Peak ルーフラインの上にある理由を考えてみてください。
ヒント
[Assembly] タブで、一番上と真ん中のオレンジのドットで表される 2 つのループの命令を比較してみてください。
製品および性能に関する情報
1 性能は、使用状況、構成、その他の要因によって異なります。詳細については、www.Intel.com/PerformanceIndex/ (英語) を参照してください。
