
この記事は、インテル® デベロッパー・ゾーンに公開されている「Intel® Advisor Cookbook」の「Model Performance of a C++ App Ported to a GPU」(https://www.intel.com/content/www/us/en/develop/documentation/advisor-cookbook/top/use-cli-to-model-gpu-performance.html) の日本語参考訳です。原文は更新される可能性があります。原文と翻訳文の内容が異なる場合は原文を優先してください。
このレシピでは、コマンドライン・インターフェイス (CLI) からインテル® Advisor の Offload Modeling パースペクティブを使用して、アプリケーションを GPU アクセラレーターにオフロードする利点を確認する方法を紹介します。
Offload Modeling パースペクティブ (英語) では、インテル® Advisor はベースライン CPU と GPU でアプリケーションを実行して、指定したターゲット GPU 上でのアプリケーションのパフォーマンスと動作をモデル化します。ターゲット GPU デバイス上でのアプリケーション・パフォーマンスのモデル化には、次の 3 つのワークフローを使用できます。
- CPU 上で実行するネイティブ・アプリケーション (C、C++、Fortran) 向けの CPU から GPU へのモデル化
- CPU にオフロードする SYCL*、OpenMP* ターゲット、および OpenCL* アプリケーション向けの CPU から GPU へのモデル化
- GPU 上で実行する SYCL*、OpenMP* ターゲット、および OpenCL* アプリケーション向けの GPU から GPU へのモデル化
このレシピでは、インテル® Advisor の CLI を使用して Offload Modeling パースペクティブで C++ および SYCL* アプリケーションのパフォーマンスを解析し、インテル® Iris® Xe グラフィックス (gen12_tgl 構成) へアプリケーションをオフロードする利点を予測します。
手順:
シナリオ
ワークフローに応じて、Offload Modeling には次の手順が含まれます。
CPU から GPU へのモデル化 |
GPU から GPU へのモデル化 |
|---|---|
|
|
インテル® Advisor では、特別な「コマンドライン・プリセット」を使用して、Offload Modeling パースペクティブのすべての解析を 1 つのコマンドで実行できます。「精度レベル」を選択することで、実行する解析を制御することが可能です。
コンポーネント
ここでは、このレシピで示す結果を得るために使用したハードウェアとソフトウェアをリストします。
- パフォーマンス解析ツール: インテル® Advisor 2021
スタンドアロン版 (英語) またはインテル® oneAPI ベース・ツールキット (英語) の一部としてダウンロードできます。 - アプリケーション: マンデルブロは、行列の初期化によってフラクタル画像を生成し、ピクセルに依存しない計算を実行するアプリケーションです。2 つの実装を利用できます。
- ネイティブ C++ 実装の MandelbrotOMP (英語)
- SYCL* 実装の Mandelbrot (英語)
- コンパイラー:
- インテル® C++ コンパイラー・クラシック 2021 (
icpc)
スタンドアロン版 (英語) またはインテル® oneAPI HPC ツールキット (英語) の一部としてダウンロードできます。 - インテル® oneAPI DPC++/C++ コンパイラー 2021 (
dpcpp)
スタンドアロン版 (英語) またはインテル® oneAPI ベース・ツールキット (英語) の一部としてダウンロードできます。
- インテル® C++ コンパイラー・クラシック 2021 (
- オペレーティング・システム: Ubuntu* 20.04.2 LTS
- CPU: インテル® Core™ i7-8559U プロセッサー。ターゲット GPU 上での CPU アプリケーション・パフォーマンスのモデル化に使用します (CPU から GPU へのモデル化フロー)。
- GPU: インテル® Iris® Plus グラフィックス 655。異なるターゲット GPU 上での GPU アプリケーション・パフォーマンスのモデル化に使用します (GPU から GPU へのモデル化フロー)。
マンデルブロ・アプリケーションの事前収集されたオフロードのモデル化レポートをダウンロード (英語) し、このレシピの手順に従って解析結果を調べることもできます。
必要条件
- oneAPI ツールの環境変数を設定します。以下に例を示します。
source /setvars.sh
- アプリケーションをコンパイルします。
- マンデルブロ・アプリケーションのネイティブ C++ 実装をコンパイルします。
cd MandelbrotOMP/ && make - マンデルブロ・アプリケーションの SYCL* 実装をコンパイルします。
cd mandelbot/ && mkdir build && cd build && cmake .. && make -j
- マンデルブロ・アプリケーションのネイティブ C++ 実装をコンパイルします。
- GPU 上で実行する SYCL* 実装向け: GPU カーネルを解析するため、システムを設定 (英語) します。
オフロード候補の調査
Offload Modeling 収集プリセットを「medium」精度で実行します。
「medium」精度はデフォルトであるため、追加のオプションを指定する必要はありません。「medium」精度でパフォーマンス・データを収集してアプリケーション・パフォーマンスをモデル化するには、ワークフローに応じて次のいずれかのコマンドを実行します。
- ネイティブ・マンデルブロ・アプリケーションの CPU から GPU へのモデル化を実行する場合:
advisor --collect=offload --config=gen12_tgl --project-dir=./cpu2gpu_offload_modeling -- ./release/Mandelbrot 1 - マンデルブロ・アプリケーションの SYCL* 実装の GPU から GPU へのモデル化を実行する場合:
advisor --collect=offload --gpu --accuracy=low --project-dir=./gpu2gpu_offload_modeling -- ./src/Mandelbrot
注:
--config オプションで異なる値を指定することで、モデル化するターゲット GPU を変更できます。詳細とオプションの一覧は、config (英語) を参照してください。
「high」精度では、インテル® Advisor は次の解析を実行します。
- Survey
- Characterization ― トリップカウントと FLOP 収集、キャッシュ・シミュレーション、およびデータ転送のモデル化
- Performance Modeling
「medium」精度で実行される解析を確認するには、実行コマンドで --dry-run オプションを指定します。
advisor --collect=offload --config=gen12_tgl --dry-run --project-dir=./cpu2gpu_offload_modeling -- ./release/Mandelbrot 1GPU から GPU へのモデル化のコマンドを生成するには、上記のコマンドに --gpu オプションを追加します。
コマンドはターミナルに出力されます。
advisor --collect=survey --auto-finalize --static-instruction-mix --project-dir=./cpu2gpu_offload_modeling -- ./release/Mandelbrot 1 advisor --collect=tripcounts --flop --stacks --auto-finalize --enable-cache-simulation --data-transfer=light --target-device=gen12_tgl --project-dir=./cpu2gpu_offload_modeling -- ./release/Mandelbrot 1 advisor --collect=projection --no-assume-dependencies --config=gen12_tgl --project-dir=./cpu2gpu_offload_modeling -- ./release/Mandelbrot 1
結果の表示
インテル® Advisor は、--project-dir オプションで指定した cpu2gpu_offload_modeling および gpu2gpu_offload_modeling ディレクトリーに解析設定と解析結果を保存します。収集結果はいくつかの出力形式で表示できます。
ターミナルで結果サマリーを表示
コマンドを実行すると、結果のサマリーがターミナルに出力されます。サマリーには、ベースラインとターゲットデバイスのタイミング情報、合計予測スピードアップ、および最も大きなスピードアップが得られる上位 5 つのオフロード候補ごとのメトリックのテーブルが含まれます。
ネイティブ C++ マンデルブロ・アプリケーションの CPU から GPU への Offload Modeling の結果サマリー:

SYCL* マンデルブロ・アプリケーションの GPU から GPU への Offload Modeling の結果サマリー:

インテル® Advisor の GUI で結果を表示
インテル® Advisor のグラフィカル・ユーザー・インターフェイス (GUI) がシステムにインストールされている場合、GUI で結果を開くことができます。この場合、追加のファイルやレポートを作成することなく、既存のインテル® Advisor の結果を開くことができます。
CPU から GPU へのモデル化の結果をインテル® Advisor の GUI で開くには、次のコマンドを実行します。
advisor-gui ./cpu2gpu_offload_modelingウェブブラウザーでインタラクティブな HTML レポートを表示
インテル® Advisor の CLI で Offload Modeling を実行すると、インタラクティブな HTML レポートが自動生成されます。このレポートは任意のウェブブラウザーで表示でき、インテル® Advisor の GUI をインストールする必要はありません。
HTML レポートは <project-dir>/e<NNN>/report ディレクトリーに生成され、advisor-report.html という名前です。
マンデルブロ・アプリケーションでは、./cpu2gpu_offload_modeling/e000/report/ にレポートがあります。レポートの場所は、Offload Modeling の CLI 出力にも表示されます。
… Info: Results will be stored at '/localdisk/cpu2gpu_offload_modeling/e000/pp000/data.0'. See interactive HTML report in '/localdisk/adv_offload_modeling/e000/report' … advisor: The report is saved in '/localdisk/cpu2gpu_offload_modeling/e000/report/advisor-report.html'.
インタラクティブな HTML レポートの構造は、インテル® Advisor の GUI で開いた結果に似ています。Offload Modeling レポートは、レポートサマリー、詳細なパフォーマンス・メトリック、ソース、ログのタブで構成されます。
ターゲット GPU 上のパフォーマンス・スピードアップの検証
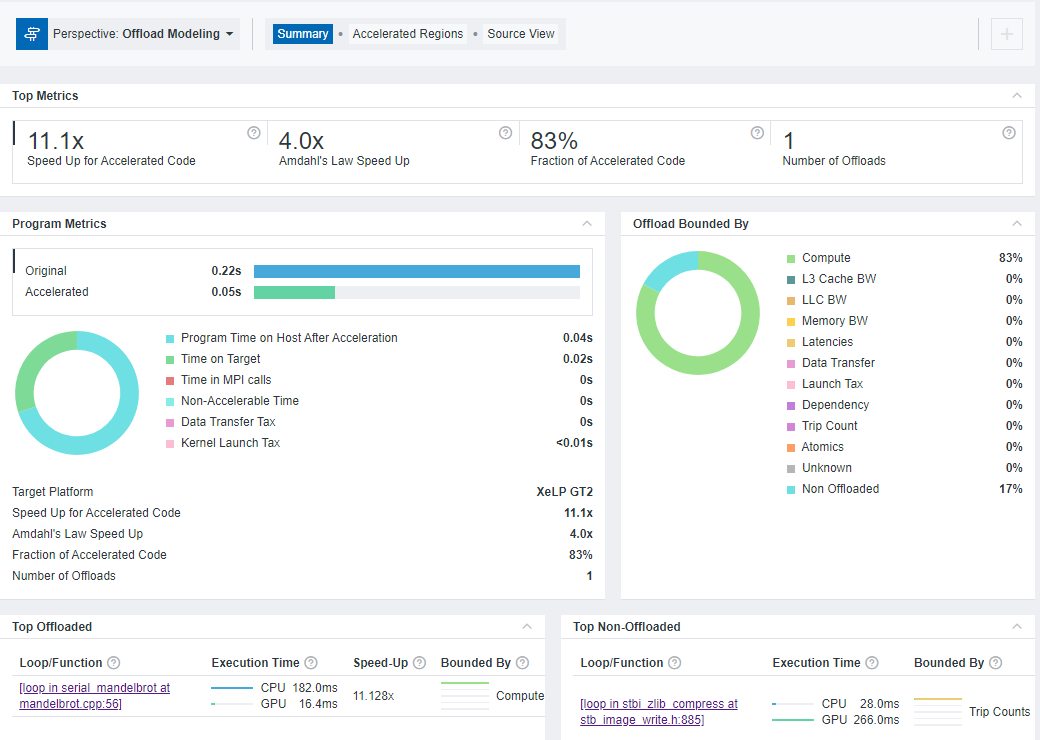
デフォルトでは、最初に [Summary] タブが開きます。モデル化の結果のサマリーが表示されます。
[Top Metrics] ペインと [Program Metrics] ペインは、プログラムごとのパフォーマンス予測と、ベースライン・デバイスのパフォーマンスとの比較を表示します。ネイティブ C++ マンデルブロ・アプリケーションでは、1 つのループをオフロードすることで、11.1 倍の予測スピードアップを達成できます。ベースライン・デバイス上での実行時間は 0.22 秒で、ターゲットデバイス上での予測実行時間は 0.05 秒です。
[Offload Bounded By] ペインは、コード領域のパフォーマンスを制限する要因を示します。ネイティブ C++ マンデルブロ・アプリケーションは、ほとんどが計算依存です。
[Top Offloaded] ペインは、選択したターゲットデバイスへのオフロードが推奨される上位 5 つの領域を示します。ネイティブ C++ マンデルブロ・アプリケーションでは、
mandelbrot.cpp:56のserial_mandelbrotにある 1 つのループのオフロードが推奨されています。[Top Non-Offloaded] ペインは、上位 5 つの非オフロード領域とターゲットデバイス上での実行を推奨しない理由を示します。ネイティブ C++ マンデルブロ・アプリケーションでは、
stb_image_write.h:885のstbi_zilb_compressにある 1 つのループがオフロード非推奨です。これは、ターゲットデバイス上での予測実行時間のほうが、ベースライン・デバイス上で測定された実行時間よりも長いためです。注:
[Top Non-Offloaded] ペインのデータは、CPU から GPU へのモデル化ワークフローでのみ利用できます。
詳細を取得するには、[Accelerated Regions] タブに切り替えます。
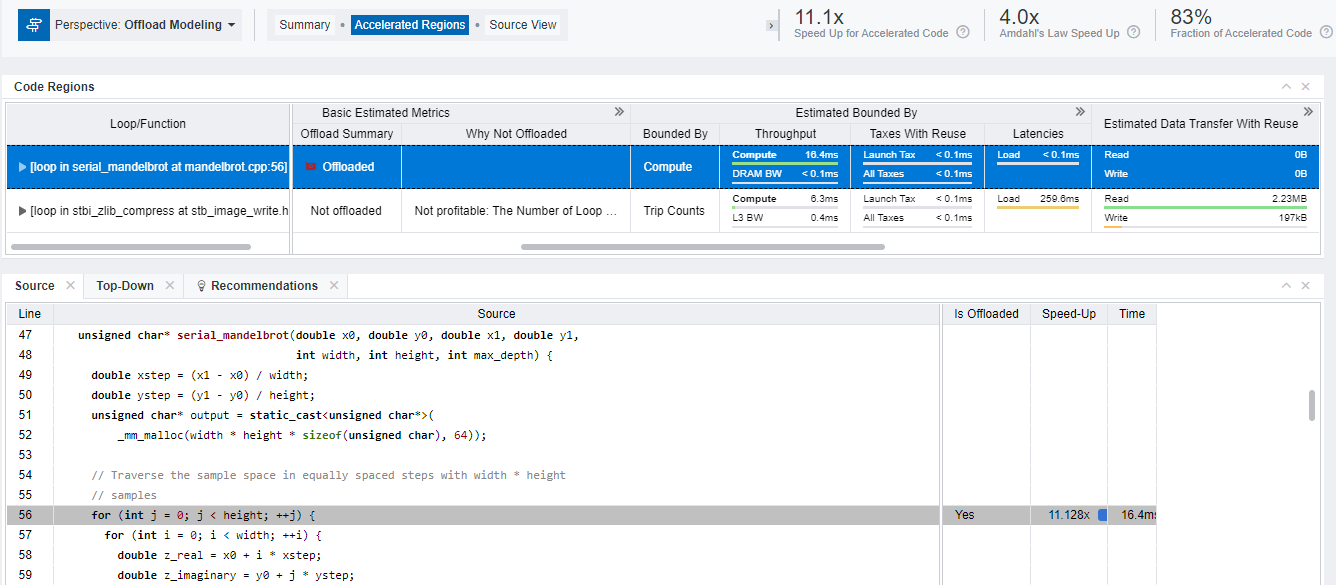
コード領域のモデル化の結果を可視化する [Code Regions] テーブルを調査します。このテーブルには、ベースライン CPU または GPU プラットフォームで測定されたパフォーマンス・メトリックと、ターゲット GPU プラットフォーム上でアプリケーションの動作をモデル化した際に予測されたメトリックが含まれます。データカラムを展開したり、グリッドをスクロールして追加のメトリックを確認できます。
- 各ループ/関数のスピードアップや実行時間とアプリケーションのソースコードを表示します。次のいずれかの操作を行います。
- [Code Regions] テーブルで注目する領域をクリックして、テーブルの下にある [Source] タブを確認します。
- [Code Regions] テーブルで注目する領域を右クリックして [View Source] を選択し、レポートの [Source View] タブに切り替えて完全なソースコードを調査できます。
別の方法
low、medium、または high のいずれかの精度レベルでコマンドライン収集プリセットを使用して、Offload Modeling パースペクティブを実行できます。高い精度レベルでは、ランタイムオーバーヘッドが増えますが、より精度の高い結果が生成されます。
low 精度で Offload Modelin を実行
「low」精度でパフォーマンス・データを収集してアプリケーション・パフォーマンスをモデル化するには、ワークフローに応じて次のいずれかのコマンドを実行します。
- ネイティブ・マンデルブロ・アプリケーションの CPU から GPU へのモデル化を実行する場合:
advisor --collect=offload --config=gen12_tgl --accuracy=low --project-dir=./cpu2gpu_offload_modeling -- ./release/Mandelbrot 1 - マンデルブロ・アプリケーションの SYCL* 実装の GPU から GPU へのモデル化を実行する場合:
advisor --collect=offload --gpu --config=gen12_tgl --accuracy=low --project-dir=./gpu2gpu_offload_modeling -- ./src/Mandelbrot
注:
--config オプションで異なる値を指定することで、モデル化するターゲット GPU を変更できます。詳細とオプションの一覧は、config (英語) を参照してください。
「high」精度では、インテル® Advisor は次の解析を実行します。
- Survey
- Characterization ― トリップカウントと FLOP 収集
- Performance Modeling
「low」精度で実行される解析を確認するには、実行コマンドで --dry-run オプションを指定します。
advisor --collect=offload --config=gen12_tgl --accuracy=low --dry-run --project-dir=./cpu2gpu_offload_modeling -- ./release/Mandelbrot 1GPU から GPU へのモデル化のコマンドを生成するには、上記のコマンドに --gpu オプションを追加します。
コマンドはターミナルに出力されます。
advisor --collect=survey --auto-finalize --static-instruction-mix --project-dir=./cpu2gpu_offload_modeling -- ./release/Mandelbrot 1 advisor --collect=tripcounts --flop --stacks --auto-finalize --target-device=gen12_tgl --project-dir=./cpu2gpu_offload_modeling -- ./release/Mandelbrot 1 advisor --collect=projection --no-assume-dependencies --config=gen12_tgl --project-dir=./cpu2gpu_offload_modeling -- ./release/Mandelbrot 1
high 精度で Offload Modelin を実行
「high」精度でパフォーマンス・データを収集してアプリケーション・パフォーマンスをモデル化するには、ワークフローに応じて次のいずれかのコマンドを実行します。
- ネイティブ・マンデルブロ・アプリケーションの CPU から GPU へのモデル化を実行する場合:
advisor --collect=offload --config=gen12_tgl --accuracy=high --project-dir=./cpu2gpu_offload_modeling -- ./release/Mandelbrot 1 - マンデルブロ・アプリケーションの SYCL* 実装の GPU から GPU へのモデル化を実行する場合:
advisor --collect=offload --gpu --config=gen12_tgl --accuracy=high --project-dir=./gpu2gpu_offload_modeling -- ./src/Mandelbrot
注:
--config オプションで異なる値を指定することで、モデル化するターゲット GPU を変更できます。詳細とオプションの一覧は、config (英語) を参照してください。
「high」精度では、インテル® Advisor は次の解析を実行します。
- Survey
- Characterization ― トリップカウントと FLOP 収集、キャッシュ・シミュレーション、およびメモリー・オブジェクトへの関連付けとスタック・メモリー・アクセスの追跡を含むデータ転送のモデル化
- Dependencies
- Performance Modeling
注: Dependencies 解析は、CPU から GPU へのモデル化にのみ関連します。
「high」精度で実行される解析を確認するには、実行コマンドで --dry-run オプションを指定します。
advisor --collect=offload --config=gen12_tgl --accuracy=high--dry-run --project-dir=./cpu2gpu_offload_modeling -- ./release/Mandelbrot 1GPU から GPU へのモデル化のコマンドを生成するには、上記のコマンドに --gpu オプションを追加します。
コマンドはターミナルに出力されます。
advisor --collect=survey --auto-finalize --static-instruction-mix --project-dir=./cpu2gpu_offload_modeling -- ./release/Mandelbrot 1 advisor --collect=tripcounts --flop --stacks --auto-finalize --enable-cache-simulation --data-transfer=medium --target-device=gen12_tgl --project-dir=./cpu2gpu_offload_modeling -- ./release/Mandelbrot 1 advisor --collect=dependencies --filter-reductions --loop-call-count-limit=16 --select=markup=gpu_generic --project-dir=./cpu2gpu_offload_modeling -- ./release/Mandelbrot 1 advisor --collect=projection --config=gen12_tgl --project-dir=./cpu2gpu_offload_modeling -- ./release/Mandelbrot 1
注:
MPI アプリケーション (英語) や、特定のアプリケーション領域の浮動小数点/整数演算やトリップカウント・データを収集制御 API (英語) のみで収集するなど、特定の制限のあるアプリケーションを解析する場合、解析ごとのコマンドを 1 つずつ実行する必要があります。コマンドライン収集プリセットはそのようなアプリケーションをサポートしていません。詳細は、「コマンドラインから Offload Modeling パースペクティブを実行」 (英語) を参照してください。
要約
- アプリケーションに応じて、異なる Offload Modeling パースペクティブ・ワークフローを使用できます。
- CPU 上で実行するネイティブ C、C++、Fortran アプリケーション、または CPU にオフロードされる SYCL*、OpenMP* ターゲット、OpenCL* アプリケーションを解析するには、CPU から GPU へのモデル化を実行します。
- GPU 上で実行する SYCL*、OpenMP* ターゲット、OpenCL* アプリケーションを解析するには、GPU から GPU へのモデル化を実行します。
- CLI から Offload Modeling パースペクティブを実行するには、コマンドライン収集プリセットのいずれかを使用します。プリセットは、1 つのコマンドを使用して特定の精度レベルでパースペクティブを実行できます。
