
この記事は、インテル® デベロッパー・ゾーンに公開されている「Intel® Advisor Cookbook」の「Estimate the C++ Application Speedup on a Target GPU」(https://software.intel.com/content/www/us/en/develop/documentation/advisor-cookbook/top/model-cpp-application-performance-on-a-target-gpu.html) の日本語参考訳です。
バージョン: 2021.1 (最終更新日: 2021 年 5 月 19 日)
このレシピでは、インテル® Advisor を使用して、C++ アプリケーションをターゲット GPU デバイスへオフロードする利点があるかどうかチェックする方法を紹介します。
シナリオ
オフロードのモデル化ワークフローは次の 2 つのステップで構成されます。
- CPU 上でのアプリケーション特性メトリックの収集: サーベイ解析、トリップカウント & FLOP 解析、そしてオプションで依存関係解析を実行します。
- 収集されたメトリックを基に、解析モデルを使用して GPU 上でのアプリケーションの実行時間を予測します。
並列ループのみ GPU へオフロードすることができるため、ループ伝搬依存関係の情報はアプリケーションのパフォーマンスをモデル化する上で重要です。インテル® Advisor は、インテル® コンパイラー、アプリケーションのコールスタック・ツリー、依存解析結果からこの情報を取得します。依存関係解析では、パフォーマンスのモデル化フローに高いオーバーヘッドが生じます。
このレシピでは、まずループに依存関係が存在しないと想定してオフロードのモデル化を実行し、GPU へのオフロードにより利点が得られるループのみ依存関係解析を実行して依存関係がないことを確認します。
オフロードのモデル化は、インテル® Advisor のグラフィカル・ユーザー・インターフェイス (GUI)、インテル® Advisor のコマンドライン・インターフェイス (CLI) (英語)、または製品に同梱の Python* スクリプト (英語) を使用して実行できます。このレシピでは、CLI で解析を実行して、GUI で結果を表示して調査します。
コンポーネント
ここでは、このレシピで示される特定の結果を得るために使用したハードウェアとソフトウェアをリストします。
- パフォーマンス解析ツール: インテル® Advisor 2021
https://software.intel.com/content/www/us/en/develop/articles/oneapi-standalone-components.html (英語) からスタンドアロン版、または https://software.intel.com/content/www/us/en/develop/tools/oneapi/base-toolkit/download.html (英語) からインテル® oneAPI ベース・ツールキットの一部としてダウンロードできます。
- アプリケーション: マンデルブロは、行列の初期化によってフラクタル画像を生成し、ピクセルに依存しない計算を実行するアプリケーションです。
2 つの実装を利用できます。
- ネイティブ C++ 実装 (英語): オフロードのモデル化を使用して解析できます。
- DPC++ 実装 (英語): GPU 上で実行して、インテル® Advisor の予測と実際のパフォーマンスを比較できます。
注
SYCL_DEVICE_TYPE=<CPU|GPU|FPGA|HOST> 環境変数を設定して、アプリケーションを実行するデバイスを選択します。
- コンパイラー: インテル® C++ コンパイラー・クラシック 2021 およびインテル® oneAPI DPC++/C++ コンパイラー 2021
インテル® oneAPI HPC ツールキットの一部として https://software.intel.com/content/www/us/en/develop/tools/oneapi/hpc-toolkit/download.html (英語) からダウンロードできます。
- オペレーティング・システム: Microsoft* Windows* 10 Enterprise
- CPU: インテル® Core™ i7-8665U プロセッサー
- GPU: インテル® UHD グラフィックス 620 (Gen9 GT2 アーキテクチャー構成)
必要条件
ツールの環境変数を設定します。
&lt;oneapi-install-dir&gt;\setvars.bat
C++ マンデルブロ・サンプルをコンパイル
マンデルブロ・サンプルの C++ バージョンをコンパイルする際には、以下の点を考慮してください。
- ベンチマーク・コードは、計算を実行するメインのソースファイル (mandelbrot.cpp) と 2 つのヘルパーファイル (main.cpp と timer.cpp) で構成されています。3 つのソースファイルをすべてターゲット実行ファイルに含める必要があります。
- 次の推奨オプションを使用してアプリケーションをコンパイルします。
- /O2: 適度な最適化レベルを要求して、最大の速度でコードを最適化します。
- /Zi: 特性メトリックの収集に必要なデバッグ情報を有効にします。
その他の推奨オプションの詳細は、『インテル® Advisor ユーザーガイド』 (英語) を参照してください。
次のコマンドを実行して、マンデルブロ・サンプルの C++ バージョンをコンパイルします。
icx.exe /c /Qm64 /Zi /nologo /W3 /O2 /Ob1 /Oi /D NDEBUG /D _CONSOLE /D _UNICODE /D UNICODE /EHsc /MD /GS /Gy /Zc:forScope /Fo&quot;x64\Release\\&quot; /TP src\main.cpp src\mandelbrot.cpp src\timer.cpp
インテル® C++ コンパイラー・クラシック・オプションの詳細は、『インテル® C++ コンパイラー・クラシック・デベロッパー・ガイドおよびリファレンス』 (英語) を参照してください。
依存関係解析なしでオフロードのモデル化を実行
最初に、潜在的なループ伝搬依存関係を無視するパフォーマンス・モデルの操作モードで、大まかなパフォーマンス予測を取得します。CLI で –no-assume-dependencies コマンドライン・オプションを使用してこのモードを有効にします。
Gen9 GT2 構成のターゲット GPU 上でマンデルブロ・サンプルのパフォーマンスをモデル化するには、次の操作を行います。
- サーベイ解析を実行して、ベースライン・パフォーマンス・データを取得します。
advisor --collect=survey --stackwalk-mode=online --static-instruction-mix --project-dir=.\advisor_results --search-dir sym=.\x64\Release --search-dir bin=.\x64\Release --search-dir src=. -- .\x64\Release\mandelbrot_base.exe
- トリップカウント & FLOP 解析を実行して、呼び出し回数データを取得し Gen9 GT2 構成のキャッシュをモデル化します。
advisor --collect=tripcounts --flop --stacks --enable-cache-simulation --data-transfer=light --target-device=gen9_gt2 --project-dir=.\advisor_results --search-dir sym=.\x64\Release --search-dir bin=.\x64\Release --search-dir src=. -- .\x64\Release\mandelbrot_base.exe
- 想定される依存関係を無視して Gen9 GT2 構成の GPU 上でアプリケーションのパフォーマンスをモデル化します。
advisor --collect=projection --config=gen9_gt2 --no-assume-dependencies --project-dir=.\advisor_results
–no-assume-dependencies オプションを使用すると、依存関係のない並列ループであると想定して処理時間を最小限に抑えることができます。
収集結果は、GUI で開くことができる advisor_results プロジェクトに格納されます。
予測パフォーマンスを表示
結果を GUI で表示するには、次の操作を行います。
- コマンドプロンプトで次のコマンドを実行してインテル® Advisor の GUI を開きます。
advisor-gui
- [File] > [Open] > [Project…] を選択して、結果を格納した advisor_results プロジェクト・ディレクトリーに参照して、.advixeproj プロジェクト・ファイルを開きます。
- オフロードのモデル化レポートが開かない場合は、[Welcome] ペインで [Show Result] をクリックします。
advisor_results の収集結果の [Summary] が表示されます。
注
インテル® Advisor GUI がインストールされていない環境で結果を確認する必要がある場合は、.\advisor_results\e000\pp000\data.0\report.html にある HTML レポートを開きます。HTML レポートの詳細は、「GPU へオフロードするコード領域の特定と GPU 利用率の視覚化」 (https://software.intel.com/content/www/us/en/develop/documentation/advisor-cookbook/top/design-and-optimize-application-with-offload-advisor.html#design-and-optimize-application-with-offload-advisor_OPTIMIZE) を参照してください。
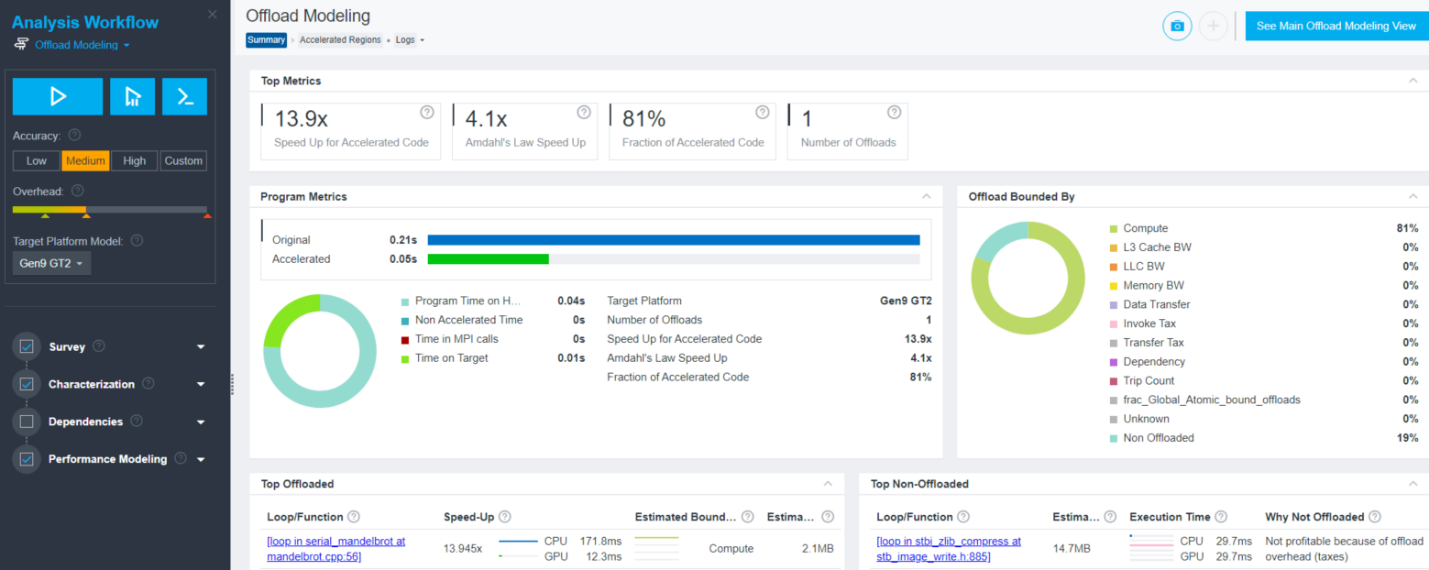
オフロードのモデル化サマリーを調査
オフロードのモデル化レポートの [Summary] タブは、モデル化結果のいくつかのビューを提供します。
- [Top Metrics] と [Program Metrics] ペインでは、プログラムごとのパフォーマンス予測を確認して、CPU 上のベースライン・アプリケーション・パフォーマンスと比較できます。
- [Offload Bounded By] ペインでは、実行時間に関連する特性メトリックと領域のパフォーマンスを制限する要因を確認できます。
- [Top Offloaded] ペインでは、選択したターゲットデバイスへのオフロードが推奨される上位 5 つの領域を確認できます。
- [Top Non-Offloaded] ペインでは、上位 5 つの非オフロード領域とターゲット上でそれらの実行が推奨されない理由を確認できます。
マンデルブロ・アプリケーションでは、次のデータを考慮します。
- ターゲット GPU 上で予測される実行時間は 0.05 秒です。
- mandelbrot.cpp:56 のループは GPU へのオフロードが推奨されます。
- このループの実行時間はアプリケーション全体の実行時間の 81% です ([Fraction of Accelerated Code] を参照)。
- このループをターゲット GPU 上で実行すると、CPU 上で実行するよりも 13.9 倍高速です ([Speed Up for Accelerated Code] を参照)。
- このループをオフロードすると、アムダールの法則によりアプリケーション全体の実行時間が 4.1 倍高速になります ([Amdahl’s Law Speed Up] を参照)。
- stb_image_write.h:885 のループは、オーバーヘッドが高いため GPU へのオフロードにより利点が得られません。
高速化された領域レポートを調査
完全なオフロードのモデル化レポートを表示するには、次のいずれかの操作を行います。
- レポートの上部にある [Accelerated Regions] タブをクリックします。
- [Top Offloaded] または [Top Non-Offloaded] ペインでループ/関数名のハイパーリンクをクリックします。
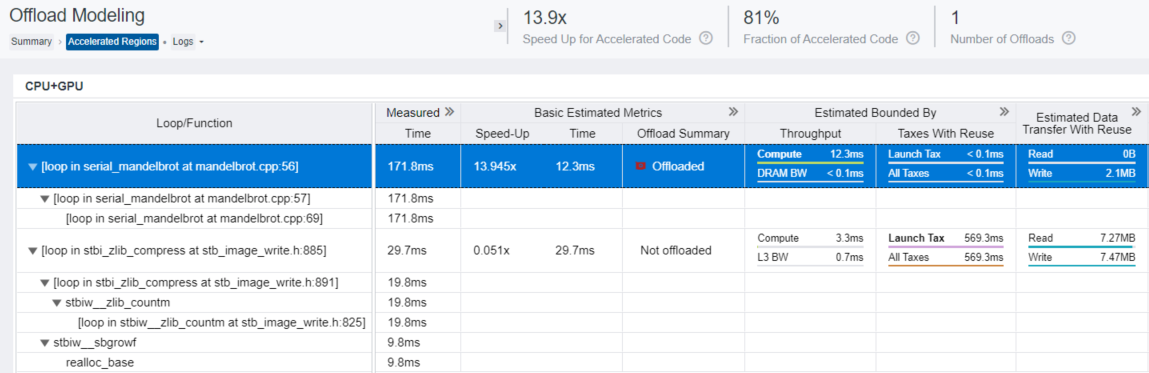
高速化された領域レポートは、すべてのオフロードコード領域と非オフロードコード領域の詳細を表示します。次のペインのデータを確認します。
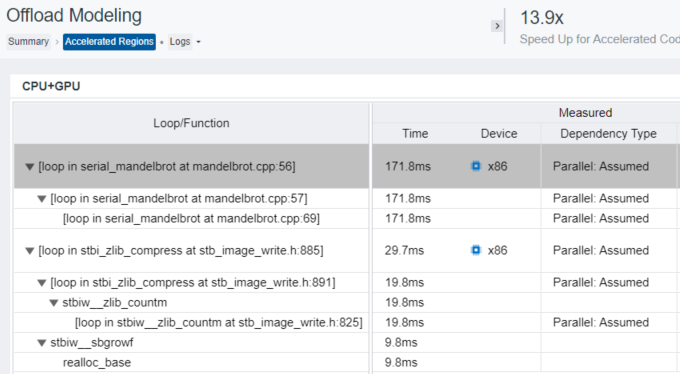
- [CPU+GPU] テーブルは、GPU 上で各コード領域の実行をモデル化した結果を表示します。ベースライン CPU プラットフォーム上で測定されたパフォーマンス・メトリックとターゲット GPU 上でモデル化されたアプリケーション・パフォーマンスの予測メトリック (予測実行時間やボトルネックの内容―コード領域が計算依存かメモリー依存か―など) をレポートします。データカラムを展開したり、グリッドをスクロールして追加の予測メトリックを確認できます。
マンデルブロ・アプリケーションでは、mandelbrot.cpp:56 のループが GPU へのオフロードに推奨されます。このループは計算依存であり、Gen9 GT2 GPU 上での予測実行時間は 12.3 ミリ秒です。この領域は 2.1MB のデータを転送し、そのほとんどは GPU から CPU への書き込みデータ転送ですが、内蔵 GPU であるためオーバーヘッドが発生しません。
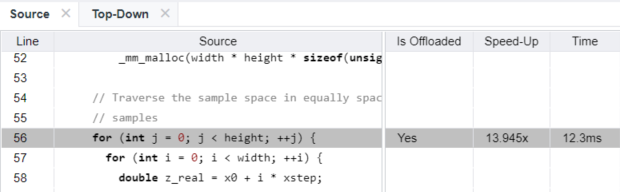
- [CPU+GPU] テーブルで mandelbrot.cpp:56 コード領域をクリックして、対応するソースコードとオフロード・パラメーターを [Source] ビューで確認できます。
- [Top-Down] タブに切り替えてアプリケーションの呼び出しツリーで mandelbrot.cpp:56 領域を見つけます。このペインを使用してループメトリックとコールスタックを確認します。
![測定されたメトリックと予測メトリック示す C++ マンデルブロ・サンプルの [Top-Down] ビュー](https://www.isus.jp/wp-content/uploads/image/824_figure4.png)
依存関係解析を含むオフロードのモデル化を実行
依存関係解析は、ループの並列処理と GPU へのオフロードを妨げるループ伝搬依存関係を検出します。この解析はオーバーヘッドが高く、ターゲット・アプリケーションの実行時間が 5-100 倍遅くなります。依存関係解析は、コードが効率良くベクトル化または並列化されない場合に実行します。
- [CPU+GPU] テーブルで mandelbrot.cpp:56 のループを展開して子ループを表示します。
- [Measured] カラムグループを展開します。
[Dependency Type] カラムは、mandelbrot.cpp:56 と子ループに対して Parallel: Assumed を報告しています。これは、–no-assume-dependencies オプションを指定してパフォーマンスをモデル化したため、インテル® Advisor はこれらのループを並列と見なしましたが、実際の依存関係タイプに関する情報がないことを意味します。
注
アプリケーション内のループが並列であることが確実である場合、依存関係解析はスキップできます。そのようなループは、[Dependency Type] カラムに Parallel: <reason> 値が表示されます。ここで、<value> は Explicit、Proven、Programming Model、または Workload です。 - ループに実際の依存関係があるかどうかをチェックするには、依存関係解析を実行します。
- 依存関係解析のオーバーヘッドを最小限に抑えるには、ループ ID を使用して依存関係タイプ値が Parallel: Assumed のループを選択します。次のコマンドを実行してループの ID を取得できます。
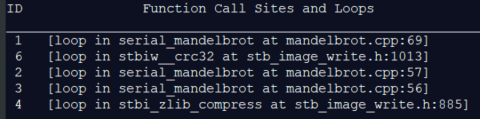
advisor --report=survey --project-dir=.\advisor_results -- .\x64\Release\mandelbrot_base.exe
このコマンドは、サーベイ解析結果とループ ID をコマンドプロンプトに出力します。mandelbrot.cpp:57 と mandelbrot.cpp:56 ループの ID はそれぞれ 2 と 3 です。
- –mark-up-list=2,3 オプションを指定して依存関係解析を実行し、注目するループのみ解析します。
advisor --collect=dependencies --mark-up-list=2,3 --loop-call-count-limit=16 --filter-reductions --project-dir=.\advisor_results -- .\x64\Release\mandelbrot_base.exe
- 依存関係解析のオーバーヘッドを最小限に抑えるには、ループ ID を使用して依存関係タイプ値が Parallel: Assumed のループを選択します。次のコマンドを実行してループの ID を取得できます。
- パフォーマンスのモデル化を再度実行して、より精度の高いパフォーマンス予測を取得します。
advisor --collect=projection --config=gen9_gt2 --project-dir=.\advisor_results
- GUI で結果が格納された advisor_results プロジェクトを開きます。
advisor-gui .\advisor_results
注
依存関係解析とオフロードのモデル化の結果は、それ以前に収集されたサーベイ解析とトリップカウント & FLOP 解析データに基づきます。
[Accelerated Regions] レポートで mandelbrot.cpp:56 ループと子ループは、[Dependency Type] カラムの値が Parallel: Workload です。これは、インテル® Advisor がループ伝搬依存関係を検出しなかったため、これらのループは GPU へオフロードして実行できることを意味します。
データ並列 C++ でコードを書き直す
DPC++ プログラミング・モデルを使用して、インテル® Advisor が GPU 上での実行を推奨した mandelbrot.cpp:56 のコード領域を書き直すことができます。
DPC++ コードには、次のアクションを含める必要があります。
- デバイスの選択
- デバイスキューの宣言
- データバッファーの宣言
- デバイスキューへのジョブ送信
- 計算の並列実行
DPC++ で書き直したコードは、次に示す DPC++ バージョンのマンデルブロ・サンプル (英語) のコードのようになります。
using namespace sycl;
// Create a queue on the default device. Set SYCL_DEVICE_TYPE environment
// variable to (CPU|GPU|FPGA|HOST) to change the device
queue q(default_selector{}, dpc_common::exception_handler);
// Declare data buffer
buffer data_buf(data(), range(rows, cols));
// Submit a command group to the queue
q.submit([&amp;](handler &amp;h) {
// Get access to the buffer
auto b = data_buf.get_access(h,write_only);
// Iterate over image and write to data buffer
h.parallel_for(range&lt;2&gt;(rows, cols), [=](auto index) {
…
b[index] = p.Point(c);
});
});
DPC++ コード (DPC++ バージョンのマンデルブロ・サンプルでは mandel.hpp) のイメージ・パラメーター値が C++ バージョンと同じであることを確認してください。
constexpr int row_size = 2048; constexpr int col_size = 1024;
詳細は、データ並列 C++ ページ (英語) および「oneAPI GPU 最適化ガイド」 (英語) を参照してください。
GPU 上での予測パフォーマンスと実際のパフォーマンスを比較
- 次のコマンドで DPC++ マンデルブロ・サンプルをコンパイルします。
dpcpp.exe /W3 /O2 /nologo /D _UNICODE /D UNICODE /Zi /WX- /EHsc /MD /c /I&quot;$(ONEAPI_ROOT)\dev-utilities\latest\include&quot; /Fo&quot;x64\Release\\&quot; src\main.cpp
- コンパイルした mandelbrot_dpcpp アプリケーションを実行します。
mandelbrot_dpcpp.exe
- コマンドプロンプトに出力されたアプリケーションの実行時間を確認します。
Parallel time: 0.0121385s
オフロードされたループのマンデルブロ計算には、GPU 上で 12.1 ミリ秒かかっています。これは、インテル® Advisor によって予測された実行時間 12.3 ミリ秒に近いです。
要約
- インテル® Advisor のオフロードのモデル化機能は、ハードウェアを入手する前に GPU 上での実行向けにアプリケーションを設計して準備するのに役立ちます。選択した GPU 上でアプリケーション・パフォーマンスをモデル化して、予測スピードアップと実行時間を計算して、オフロード候補を特定して、ターゲット・ハードウェア上での潜在的なボトルネックを見つけることができます。
- 依存関係のあるループは並列に実行したり、ターゲット GPU へオフロードすることができません。インテル® Advisor でアプリケーション・パフォーマンスをモデル化する場合、すべての潜在的な依存関係を考慮するか、無視するかを選択できます。アプリケーションが効率良くベクトル化または並列化されない場合、依存関係解析を実行することでより正確なモデル化結果が得られます。
関連情報
- ユーザーガイド: オフロードのモデル化パースペクティブ (英語)
- oneAPI GPU 最適化ガイド (英語)
製品とパフォーマンス情報
1実際の性能は利用法、構成、その他の要因によって異なります。詳細については、www.Intel.com/PerformanceIndex (英語) を参照してください。
