
この記事は、インテル® デベロッパー・ゾーンに公開されている「Intel® Advisor Cookbook」の「Optimize Memory Access Patterns using Loop Interchange and Cache Blocking Techniques」(https://software.intel.com/en-us/advisor-cookbook-optimize-memory-access-patterns-using-loop-interchange-and-cache-blocking-techniques) の章の日本語参考訳です。
アプリケーションがどのようにデータにアクセスするか、およびそのデータがキャッシュにどのように格納されるかを理解することは、コードのパフォーマンスを最適化する重要な手順です。このレシピでは、ループ交換やキャッシュ・ブロッキングなどの手法により、メモリー・アクセス・パターン解析と推奨事項を参照して一般的なメモリー・ボトルネックを特定して対処する方法を紹介します。
シナリオ
人工知能、シミュレーション、モデリングなど、今日のコンピューター・サイエンス分野で最も一般的な問題には、行列の乗算が含まれます。次のサンプルコードは、反復ごとに乗算と加算を行う 3 重に入れ子になったループです。計算量が多いだけでなく、大量のメモリーアクセスを伴います。
for(i=0; i<msize; i++) {
for(j=0; j<msize; j++) {
for(k=0; k<msize; k++) {
c[i][j] = c[i][j] + a[i][k] * b[k][j];
}
}
}
コンポーネント
ここでは、このレシピで示される特定の結果を得るために使用されたハードウェアとソフトウェアをリストします。
- パフォーマンス解析ツール: インテル® Advisor 2019 Update 3
最新バージョンは、https://www.isus.jp/intel-advisor-xe/ からダウンロードできます。 - アプリケーション: シナリオで説明されている標準 C++ 行列乗算。
ダウンロードは提供されません。 - コンパイラー: インテル® C++ コンパイラー 2019 Update 3
最新バージョンは、https://www.isus.jp/c-compilers/ からダウンロードできます。 - オペレーティング・システム: Microsoft* Windows* 10 Enterprise
- CPU: インテル® Core™ i5-6300U プロセッサー
ベースラインを確定する
- インテル® Advisor CLI でルーフライン解析を実行します。
advixe-cl --collect=roofline --project-dir=/user/test/matrix_project -- /user/test/matrix
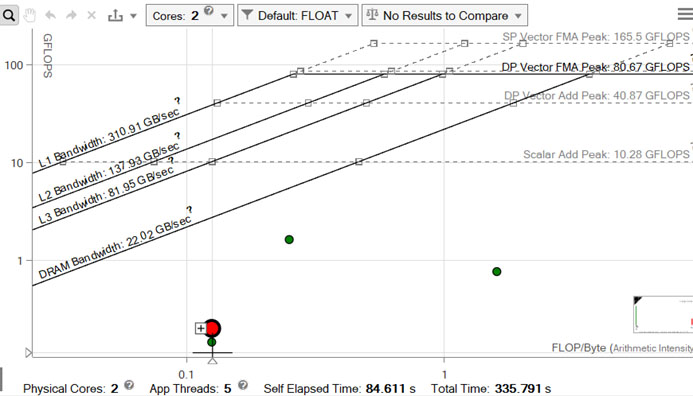
行列乗算アプリケーション (matrix) を実行すると、151.36 秒で実行を完了しました。 - インテル® Advisor GUI で [ルーフライン] グラフを開き、パフォーマンスを可視化します。
赤く示されるドットは、ここで注目するメインの計算ループです。最も下の対角線で示される DRAM 最大帯域幅を大幅に下回っています。これは、ループにメモリーアクセスに関連する潜在的な問題があることを示しています。
- インテル® Advisor GUI で [サーベイ] レポートを開いて、問題の可能性と推奨事項を確認します。
[パフォーマンスの問題] に非効率なメモリー・アクセス・パターンがあり、[効率] が 49% であることに注目してください。


- 次の手順でメモリー帯域幅の問題を調査します。
- インテル® Advisor CLI でメモリー・アクセス・パターン解析を実行します。
advixe-cl --mark-up-loops --select=multiply.c.c,21 --project-dir=/user/test/matrix_project -- /user/test/matrix advixe-cl --collect=map --project-dir=/user/test/matrix_project -- /user/test/matrix
- インテル® Advisor GUI で [メモリー・アクセス・パターン] レポートを開き、データ構造レイアウトがパフォーマンスに与える影響を解析します。
ユニットストライドはベクトル化に適していますが、インテル® Advisor はこのループで 50% の一定ストライドと 50% のユニットストライドを検出しています。もう 1 つ重要なことは、読み取りアクセスが 2048 の一定ストライド、および書き込みアクセスで 0 の一定ストライドが検出され、アクセスされたメモリーの範囲が 6MB とレポートされていることです。


- インテル® Advisor CLI でメモリー・アクセス・パターン解析を実行します。
ループ交換を行う
2048 の一定ストライドは、インデックス k による配列 b[k][j] のアクセスです。
c[i][j] = c[i][j] + a[i][k] * b[k][j];
内部ループ 2 つをループ交換すると、一定ストライドがユニットストライドに変換され、広範囲にメモリーアクセスする必要がなくなります。
- 2 つの内部ループを交換するように、行列乗算アプリケーションを修正します。
for(i=0; i<msize; i++) { for(k=0; k<msize; k++) { for(j=0; j<msize; j++) { c[i][j] = c[i][j] + a[i][k] * b[k][j]; } } } - インテル® Advisor CLI で別のルーフライン解析を実行します。
advixe-cl --collect=roofline --project-dir=/user/test/matrix_project -- /user/test/matrix
行列乗算アプリケーション (matrix) を実行すると、5.53 秒で実行を完了しました。
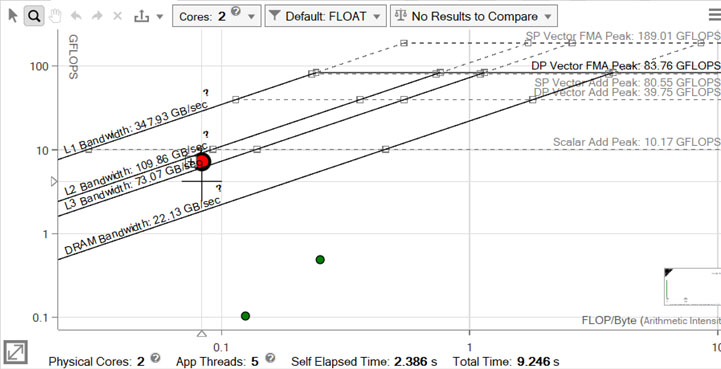
- インテル® Advisor GUI で [ルーフライン] グラフを開き、パフォーマンスを可視化します。
赤いドットで示されるループは、L2 ピーク帯域幅の直下にあります。
メモリー階層の各レベルでメモリー・トラフィックを調査する
インテル® Advisor の統合ルーフライン解析を使用して、メモリー階層の各レベルでメモリー・トラフィックを調べることもできます。
要件: 次の環境変数を設定します: ADVIXE_EXPERIMENTAL=int_roofline。
- キャッシュ・シミュレーションを有効にして、CLI で新たなルーフライン解析を実行します。
advixe-cl --collect=roofline --enable-cache-simulation --project-dir=/user/test/matrix_project -- /user/test/matrix
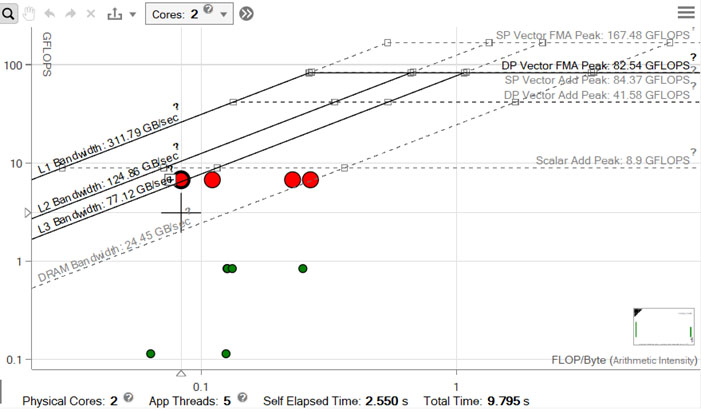
- インテル® Advisor GUI で [ルーフライン] グラフを開き、パフォーマンスを可視化します。
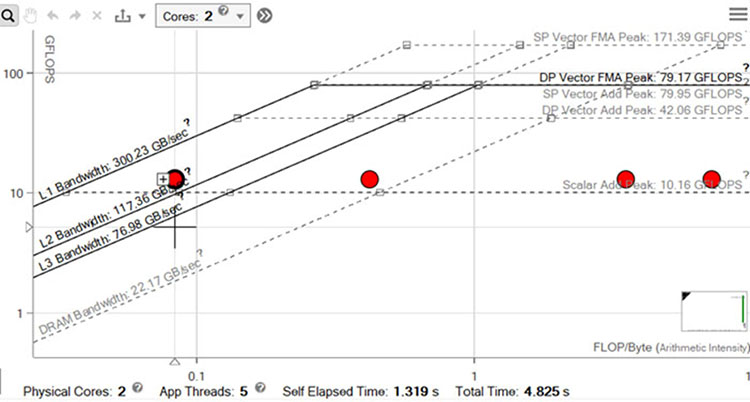
赤いドットはそれぞれ、メモリー階層の各レベルのループを示しています。左端のドットが L3 帯域幅のルーフにあることに注目すると、ループが効率良く L1 キャッシュを使用していないことは明らかです。右端のドットは DRAM 帯域幅の上限にあります。そのため、次の最適化の目標は、データをできるだけ L1 キャッシュに収めることを検討します。
- [ルーフライン] グラフの下部にある [コード解析] タブをクリックして、メモリー・トラフィックを調査します。
![[コード解析] タブのメモリー・トラフィック・メトリック](https://www.isus.jp/wp-content/uploads/D065960A-445D-40BB-965B-4A8A52AF3AA6.jpg)
- インテル® Advisor GUI で [サーベイ] レポートを開いてベクトル化の効率を調査します。
インテル® AVX2 を使用することで、ループが 96% の効率でベクトル化されていることに注目してください。

- 更新されたアクセスパターンを確認するため次の操作を行います。
- インテル® Advisor CLI で別のメモリー・アクセス・パターン解析を実行します。
advixe-cl --mark-up-loops --select=multiply.c.c,21 --project-dir=/user/test/matrix_project -- /user/test/matrix advixe-cl --collect=map --project-dir=/user/test/matrix_project -- /user/test/matrix
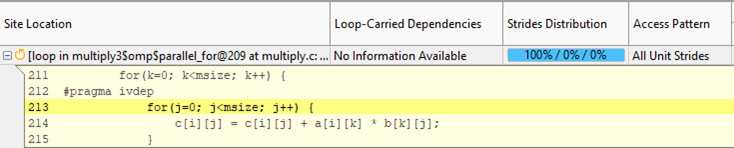
- インテル® Advisor GUI で [メモリー・アクセス・パターン] レポートを開きます。
インテル® Advisor は、すべてのアクセスがユニットストライドであることを示しています。
- インテル® Advisor CLI で別のメモリー・アクセス・パターン解析を実行します。
キャッシュ・ブロッキングを実装する
行列乗算アプリケーションは、この時点でかなり最適化されています。大量のデータを処理する際に適した改善候補として、アプリケーションのループを小さなブロックに分割して、狭い範囲のメモリーで計算を行うことができます。この技法はキャッシュ・ブロッキングと呼ばれ、ここではループを L1 キャッシュ内に収めることを目的とします。
- アプリケーションのソースを次のように編集します。
- プラグマを使用してコンパイラーに次のことを通知します。
- メモリーがアライメントされていること
- アンロールを行わないこと
- 追加された 3 つの入れ子ループの計算は、セクション (またはブロック) を連続して実行します。
for (i0 = ibeg; i0 < ibound; i0 +=mblock) { for (k0 = 0; k0 < msize; k0 += mblock) { for (j0 =0; j0 < msize; j0 += mblock) { for (i = i0; i < i0 + mblock; i++) { for (k = k0; k < k0 + mblock; k++) { #ifdef ALIGNED #pragma vector aligned #endif //ALIGNED #pragma nounroll for (j = j0; j < j0 + mblock; j++) { c[i][j] = c[i][j] + a[i][k] * b[k][j]; } } } } } } - プラグマを使用してコンパイラーに次のことを通知します。
- インテル® Advisor CLI で別のルーフライン解析を実行します。
advixe-cl --collect=roofline --enable-cache-simulation --project-dir=/user/test/matrix_project -- /user/test/matrix
行列乗算アプリケーション (matrix) を実行すると、3.29 秒で実行を完了しました。
- インテル® Advisor GUI で [ルーフライン] グラフを開き、パフォーマンスを可視化します。
左端のドットは L1 帯域幅ルーフに接近し、データが L1 キャッシュに収まるように改善されました。興味深いことに、右端のドットは DRAM 帯域幅の上限をはるかに下回っています。これは、DRAM トラフィックが低下し、L1 – L3 トラフィックが増加して、演算強度と FLOP が高くなったことに起因します。これがここでの目的です。
結果サマリー
| 実行 | 経過時間 | スピードアップ |
|---|---|---|
| ベースライン | 151.36 秒 | なし |
| ループ交換 | 5.53 | 27.37x |
| キャッシュ・ブロッキング | 3.29 | 1.68x |
要約
- メモリーの最適化により大幅なパフォーマンス向上を達成できました。
- パフォーマンス最適化の目標を達成するには以下を理解することが重要です。
- アプリケーションがデータ構造にアクセスする方法
- それらのデータがどのようにキャッシュを使用するか
コンパイラーの最適化に関する詳細は、最適化に関する注意事項を参照してください。
