
この記事は、インテル® デベロッパー・ゾーンに公開されている「Intel® Advisor Cookbook」の「Identify Code Regions to Offload to GPU and Visualize GPU Usage」(https://software.intel.com/en-us/advisor-cookbook-design-and-optimize-application-with-offload-advisor) の章の日本語参考訳です。
このレシピでは、インテル® Advisor のオフロード・アドバイザーと GPU ルーフライン解析機能を使用して、GPU にオフロードする領域を特定し、GPU カーネルのパフォーマンスを可視化してアプリケーションのボトルネックを特定する方法を説明します。
シナリオ
人工知能、シミュレーション、モデリングなど、今日のコンピューター・サイエンス分野で最も一般的な問題には、行列乗算が含まれます。次のアルゴリズムは、反復ごとに乗算と加算を行う 3 重に入れ子になったループです。非常に計算負荷が高いだけでなく、多くのメモリーにアクセスします。
for(i=0; i<msize; i++) {
for(j=0; j<msize; j++) {
for(k=0; k<msize; k++) {
c[i][j] = c[i][j] + a[i][k] * b[k][j];
}
}
}
コンポーネント
ここでは、このレシピで示される特定の結果を得るために使用したハードウェアとソフトウェアをリストします。
- パフォーマンス解析ツール: インテル® oneAPI ベース・ツールキットに含まれるインテル® Advisor
最新バージョンは、https://software.intel.com/en-us/oneapi/advisor (英語) からダウンロードできます。 - アプリケーション: シナリオで説明されている標準 C++ 行列乗算。
ダウンロードは提供されません。 - コンパイラー: インテル® oneAPI HPC ツールキットに含まれるインテル® C++ コンパイラーとインテル® oneAPI ベース・ツールキットに含まれるインテル® oneAPI DPC++ コンパイラー
インテル® C++ コンパイラーの最新バージョンは、https://software.intel.com/en-us/c-compilers/choose-download (英語) からダウンロードできます。
インテル® oneAPI DPC++ コンパイラーの最新バージョンは、https://software.intel.com/en-us/oneapi/dpc-compiler (英語) からダウンロードできます。 - オペレーティング・システム: Ubuntu* 18.04
- CPU: インテル® Core™ i7-7500U プロセッサー
オフロード・アドバイザーを使用して GPU にオフロードする領域を特定
オフロード・アドバイザーは、インテル® Advisor で提供される機能であり、GPU へオフロードすることで恩恵が得られるコード領域を特定できます。また、GPU で実行した場合のパフォーマンスを予測することで、アクセラレーターの構成パラメーターを調整する可能性を示します。
オフロード・アドバイザーは、上限とボトルネックのパフォーマンス・モデルを使用して、速度向上の上限を示します。測定された x86 CPU メトリックとアプリケーション特性を入力として受け取り、解析モデルを適用することでターゲット GPU 上の実行時間と特性を推測します。
必要条件: 次のコマンドを実行してインテル® Advisor の環境変数を設定します。
source <advisor_install_dir>/env/vars.sh
オフロード・アドバイザーでコードを解析するには、次の操作を行います。
- collect.py を使用してアプリケーションのパフォーマンス・メトリックを収集します。
advixe-python $APM/collect.py advisor_project --config gen9 -- /home/test/matrix
- analyze.py を使用して GPU 上のアプリケーションのパフォーマンスを予測します。
advixe-python $APM/analyze.py advisor_project --config gen9 --out-dir /home/test/analyze
- ウェブブラウザーで /home/test/analyze ディレクトリーに生成された report.html ファイルを開き、パフォーマンスの予測結果を確認します。
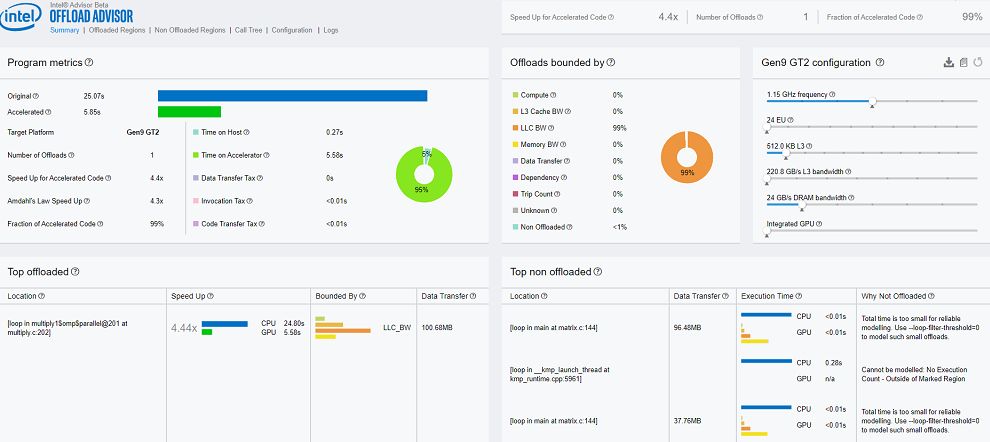
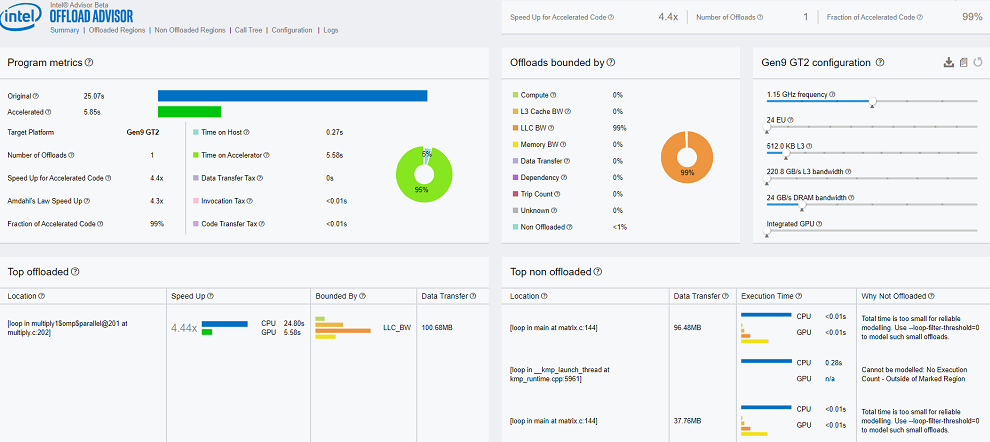
レポートの [サマリー] セクションの次の点に注意してください。
- 元の CPU 実行時間、GPU アクセラレーター上での予測実行時間、オフロード領域の数、および [プログラムメトリック] ペインのスピードアップ。
- オフロードを制限するもの。この例では、オフロードはラスト・レベル・キャッシュ (LLC) 帯域幅によって 99% 制限されています。
- GPU へオフロードすることで恩恵が得られる上位のオフロードコード領域のソース行。この例では、1 行のみがオフロードに適していると推奨されています。
- さまざまな理由でオフロードに適さない上位の非オフロードコード領域のソース行。この例では、ループの実行を正確にモデル化するには時間が短すぎ、オフロード向けにマークされたループの 1 つはコード領域外にあります。
これらの情報を基に、DPC++ で行列乗算アプリケーションを書き直します。
データ並列 C++ (DPC++) で行列乗算コードを書き直す
オフロード・アドバイザーは、行列乗算コード領域を GPU にオフロードすることを推奨しています。これを可能にするには、データ並列 C++ (DPC++) で行列乗算コードを書き直す必要があります。
行列乗算コードを書き直すには、以下に示す手順に従ってください。
- デバイスを選択します。
- デバイスキューを宣言します。
- 行列を保持するバッファーを宣言します。
- ジョブをデバイスキューへ送信します。
- 行列乗算を並列に実行します。
void multiply1(int msize, int tidx, int numt, TYPE a[][NUM], TYPE b[][NUM], TYPE c[][NUM], TYPE t[][NUM])
{
int i,j,k;
// デバイスを選択
cl::sycl::gpu_selector device;
// deviceQueue を宣言
cl::sycl::queue deviceQueue(device);
// 2 次元の範囲を宣言
cl::sycl::range<2> matrix_range{NUM, NUM};
// 3 つのバッファーを宣言して初期化
cl::sycl::buffer<TYPE, 2> bufferA((TYPE*)a, matrix_range);
cl::sycl::buffer<TYPE, 2> bufferB((TYPE*)b, matrix_range);
cl::sycl::buffer<TYPE, 2> bufferC((TYPE*)c, matrix_range);
// ジョブをキューへ送信
deviceQueue.submit([&](cl::sycl::handler& cgh) {
// バッファーのアクセサーを宣言。最初の 2 つは read 属性、最後の 1 つは read_write 属性
auto accessorA = bufferA.template get_access<sycl_read>(cgh);
auto accessorB = bufferB.template get_access<sycl_read>(cgh);
auto accessorC = bufferC.template get_access<sycl_read_write>(cgh);
// matrix_range の行列乗算コードを並列に実行
// Ind はこの範囲のインデックス
cgh.parallel_for<class Matrix<TYPE>>(matrix_range,
[=](cl::sycl::id<2> ind) {
int k;
for(k=0; k<NUM; k++) {
// 計算を実行。ind[0] は行、ind[1] は列
accessorC[ind[0]][ind[1]] += accessorA[ind[0]][k] * accessorB[k][ind[1]];
}
});
});
}
GPU ルーフライン解析を実行
行列乗算アプリケーションの GPU バージョンのパフォーマンスを推測するには、GPU ルーフライン解析機能を利用できます。インテル® Advisor は、インテル® GPU で実行されるカーネルのルーフライン・モデルを生成できます。ルーフライン・モデルは、カーネルを特徴付けて、理想的なパフォーマンスの上限からどれくらい離れているか、ビジュアルなグラフを示す非常に優れた機能を提供します。
必要条件: GPU 上でルーフライン解析を実行する前に、システムが適切に設定されていることを確認します。
- video グループにユーザー名を追加します。video グループに属しているか確認するには、次のコマンドを実行します。
groups | grep video
video グループにまだ属していない場合は、次のようにユーザー名を追加します。
sudo usermod -a -G video <username>
- GPU メトリックの収集を有効にします。
sudo su echo 0 > /proc/sys/kernel/perf_stream_paranoid
GPU 上のルーフライン・モデルはテクニカルプレビュー機能で、デフォルトでは無効になっています。有効にするには次の操作を行います。
- DPC++ コードが GPU 上で適切に実行されていることを確認します。コードが実行されているハードウェアを確認するには、DPC++ コードに次の行を追加して実行します。
Cl::sycl::default_selector selector; Cl::sycl::queue queue(delector); auto d = queue.get_device(); std::cout<<”Running on :”<<d.get_info<cl::sycl::info::device::name>()<<std::endl;
- インテル® Advisor の環境を設定します。
source <advisor_install_dir>/env/vars.sh
- GPU プロファイルを有効にします。
export ADVIXE_EXPERIMENTAL=gpu-profiling
インテル® Advisor CLI で GPU ルーフライン解析を実行するには、次の操作を行います。
- –enable-gpu-profiling オプションを使用してサーベイ解析を実行します。
advixe-cl --collect=survey --enable-gpu-profiling --project-dir=<my_project_directory> --search-dir src:r=<my_source_directory> -- /home/test/matrix [app_parameters]
- –enable-gpu-profiling オプションを使用してトリップカウントと FLOP 解析を実行します。
advixe-cl --collect=tripcounts --stacks --flop --enable-gpu-profiling --project-dir=<my_project_directory> --search-dir src:r=<my_source_directory> -- /home/test/matrix [app_parameters]
- GPU ルーフライン・レポートを生成します。
advixe-cl --report=roofline --gpu --project-dir=<my_project_directory> --report-output=roofline.html
- ウェブブラウザーで生成された roofline.html を開き、GPU パフォーマンスを可視化します。
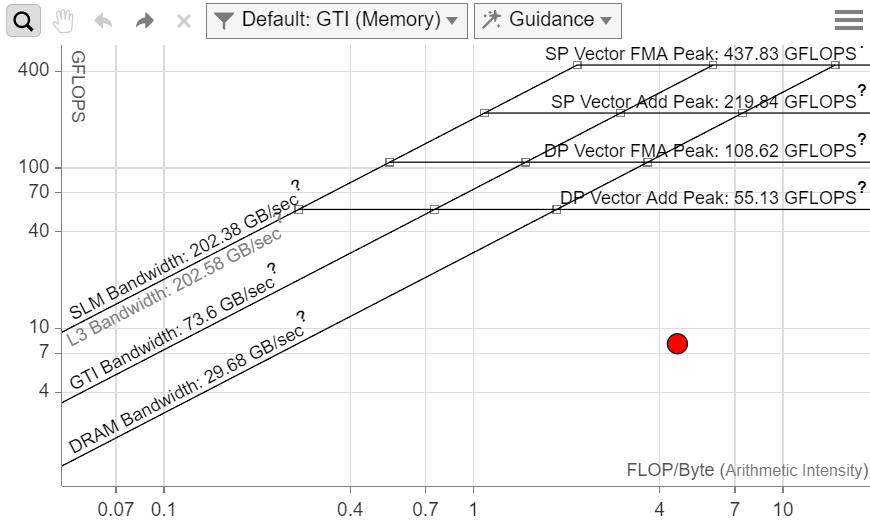
- メモリーに関連するさまざまな詳細情報を取得するには、演算強度の計算に使用されるメモリー・サブシステムを基に、異なるドット表示を選択します。この例では、GTI (メモリー) と L3 + SLM メモリーレベルを選択しています。
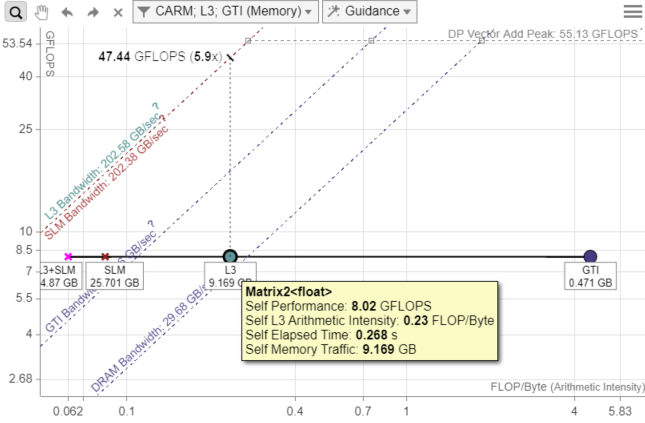
- 詳しい情報を見るには、ドット (点) をダブルクリックします。GPU ルーフライン・グラフの次の点に注意してください。
- L3 のドットは L3 最大帯域幅に接近しています。FLOPS を向上させるには、キャッシュの最適化を行う必要があります。キャッシュ・ブロッキングによる最適化手法は、メモリーをさらに効率良く利用し、パフォーマンスの向上につながると考えられます。
- GPU、GPU アンコア (LLC)、およびメインメモリー間とのトラフィックを示す GTI ドットは、GTI ルーフラインからかなり離れています。ここでは、CPU と GPU 間の転送コストは問題になりません。
- メモリーに関連するさまざまな詳細情報を取得するには、演算強度の計算に使用されるメモリー・サブシステムを基に、異なるドット表示を選択します。この例では、GTI (メモリー) と L3 + SLM メモリーレベルを選択しています。
次のステップ
DPC++ コードのメモリーアクセスを改善するためコードを変更します。パフォーマンスを大幅に向上させるには、キャッシュ・ブロッキング手法が効果的です。
要約
- インテル® Advisor は、GPU にオフロードする最適なコード領域の候補を見つけ、GPU への移植による結果を推測し、パフォーマンスのボトルネックを特定するのに役立ちます。
- インテル® Advisor の GPU ルーフライン機能は、すでに GPU に移行したコードのボトルネックを特定して、パフォーマンスがシステムの最大値にどれだけ接近しているか確認します。
関連情報
コンパイラーの最適化に関する詳細は、最適化に関する注意事項を参照してください。
