
この記事は、インテル® デベロッパー・ゾーンに公開されている「Intel® Advisor Cookbook」の「Analyze Vectorization and Memory Aspects of an MPI Application」(https://software.intel.com/en-us/advisor-cookbook-analyze-vectorization-and-memory-aspects-of-mpi-application) の章の日本語参考訳です。
分散型 HPC アプリケーションは、複数の固有ノードの集合で実行されるため、ノード間およびノード内の MPI 通信の最適化に加え、ノードごとにベクトル化などの最適化を考慮する必要があります。このレシピでは、インテル® Advisor のベクトル化とメモリー固有の機能、および推奨事項を適用して MPI アプリケーションを解析する方法を説明します。
インテル® Advisor で MPI アプリケーションを解析するには、次の操作を行います。
- 必要条件
- ターゲット・アプリケーションのサーベイ
- トリップカウントと FLOP データを収集して結果を確認
- ルーフライン・グラフを確認
- [オプション] 依存関係解析を実行
- [オプション] メモリー・アクセス・パターン解析を実行
シナリオ
MPI アプリケーションのデータはインテル® Advisor CLI でのみ収集できますが、収集された結果はスタンドアロン GUI とコマンドラインの両方で表示できます。GUI から必要なコマンドラインを生成することもできます。この機能の詳細は、インテル® Advisor ユーザーズガイドの [対応する advixe-cl コマンドオプション] ダイアログボックスを参照してください。
このレシピでは、天気予報向けの一般的な MPI ベースの数値アプリケーションである気象研究と予測 (WRF) モデル (英語) を解析するワークフローの例を紹介します。MPI アプリケーションのタイプに応じて、異なるランク数でデータを収集できます。
- WRF のような SPMD (Single Program Multiple Data) フレームワークで記述された MPI アプリケーションのプロファイルでは、すべてのランクが異なるデータのサブセットに対して同一コードを実行するため、単一の MPI ランクでデータを収集するだけで済みます。これはまた、収集のオーバーヘッドを軽減します。
インテル® VTune™ プロファイラーのアプリケーション・パフォーマンス・スナップショット (英語) を使用して、外れ値ランクを検出し選択的に解析できます。
- MPMD (Multiple Program Multiple Data) アプリケーションでは、すべての MPI ランクで解析を行う必要があります。
コンポーネント
ここでは、このレシピで示される特定の結果を得るために使用されたハードウェアとソフトウェアをリストします。
- パフォーマンス解析ツール: インテル® Advisor 2020 Gold
最新バージョンは、https://www.isus.jp/intel-advisor-xe/ からダウンロードできます。 - アプリケーション: 気象研究と予測 (WRF) モデル、バージョン 3.9.1.1。使用する WRF ワークロードは Conus12km です。
アプリケーションは、https://www.mmm.ucar.edu/weather-research-and-forecasting-model (英語) からダウンロードできます。重要
依存関係がある次のコンポーネントもインストールする必要があります: zlib-1.2.11、zip-2.1.1、hdf5-1.8.21、netcdf-c-4.6.3 および netcdf-fortran-4.4.5。
- コンパイラー:
- インテル® C++ コンパイラー 2019 Update 5
最新バージョンは、https://www.isus.jp/c-compilers/ からダウンロードできます。 - インテル® Fortran コンパイラー 2019 Update 5
最新バージョンは、https://www.isus.jp/fortran-compilers/ からダウンロードできます。
- インテル® C++ コンパイラー 2019 Update 5
- その他のツール: インテル® MPI ライブラリー 2019 Update 6
最新バージョンは、https://www.isus.jp/intel-mpi-library/ からダウンロードできます。 - オペレーティング・システム: CentOS* 7
データは、SSH 接続された Windows* システムでインテル® Advisor CLI を使用して、CentOS* 7 システムでリモート収集されました。収集された結果は Windows* システムに移動され、インテル® Advisor GUI を使用して解析されました。 - CPU: 次の構成のインテル® Xeon® Platinum 8260L プロセッサー
===== Processor composition ===== Processor name : Intel(R) Xeon(R) Platinum 8260L Packages(sockets) : 2 Cores : 48 Processors(CPUs) : 96 Cores per package : 24 Threads per core : 2
注
プロセッサーの構成を表示するには、インテル® MPI ライブラリーの mpivars.sh スクリプトをソースして、cpuinfo -g コマンドを実行します。
必要条件
- 使用するソフトウェアの環境を設定します。
source <compilers_installdir>/bin/compilervars.sh intel64 source <mpi_library_installdir>/intel64/bin/mpivars.sh source <advisor_installdir>/advixe-vars.sh
ツールが正しく設定されていることを確認するには、次のコマンドを実行します。正しく設定されている場合は製品のバージョンが表示されます。
mpiicc -v mpiifort -v mpiexec -V advixe-cl --version
- WRF アプリケーションに必要な環境変数を設定します。
export LD_LIBRARY_PATH=/path_to_IO_libs/lib:$LD_LIBRARY_PATH ulimit -s unlimited export WRFIO_NCD_LARGE_FILE_SUPPORT=1 export KMP_STACKSIZE=512M export OMP_NUM_THREADS=1
- リリースモードでアプリケーションをビルドします。インテル® Advisor でソースレベルの解析を行えるよう、-g コンパイルオプションを指定することを推奨します。
ターゲット・アプリケーションのサーベイ
最初のステップではインテル® Advisor CLI を使用して、ターゲット・アプリケーションのサーベイ解析を実行します。この解析タイプは、ターゲット・アプリケーションの高レベルの情報を収集します。解析を実行するには、次の操作を行います。
- 収集オプションを指定した advixe-cl を引数として mpiexec ランチャーに渡します。
- -gtool オプションを使用して、プロジェクト・ディレクトリー名の後に指定するランクに解析をアタッチします。
インテル® Xeon® プロセッサーを搭載したシステムの単一ノードで 48 ランクの WRF アプリケーションを実行し、サーベイ解析をランク 0 にのみアタッチするには、次のコマンドを実行します。
mpiexec -genvall -n 48 -ppn 48 -gtool "advixe-cl --collect=survey --project-dir=<project_dir>/project1:0" ./wrf.exe
このコマンドは、サーベイデータのみを含むランク 0 の結果フォルダーを生成します。
0、10 から 15 および 47 のように、一連のランクを指定して解析を行うこともできます。
mpiexec -genvall -n 48 -ppn 48 -gtool "advixe-cl --collect=survey --project-dir=<project_dir>/project1:0,10-15,47" ./wrf.exe
インテル® Advisor を使用した MPI コマンド構文の詳細は、MPI ワークロードの解析を参照してください。
注
現在、インテル® Advisor は複数ランクで収集された結果をマージできません。複数ランクで解析を実行すると、インテル® Advisor は解析したランクごとに結果フォルダーを作成します。
トリップカウントと FLOP データを収集して結果を確認
サーベイ解析を行った後、収集されたサーベイデータを表示したり、トリップカウントと FLOP に関する追加データを収集することができます。WRF アプリケーションのランク 0 のみで、トリップカウントと FLOP 解析を実行するには、次のコマンドを実行します。
mpiexec -genvall -n 48 -ppn 48 -gtool "advixe-cl --collect=tripcounts --flop --project-dir=<project_dir>/project1:0" ./wrf.exe
このコマンドは、収集されたサーベイデータを読み取り、トリップカウントと FLOP の詳細を追加します。
収集された結果はリモートマシンで表示するか、ローカルマシンに移動してインテル® Advisor GUI で表示できます。ローカルマシンで結果を表示するには、次の操作を行います。
- 結果ファイル、対応するソースおよびバイナリーを .advixeexpz 拡張子の単一のスナップショット・ファイルにパックします。
advixe-cl --snapshot --project-dir=<project_dir>/project1 --pack --cache-sources --cache-binaries -- <snapshot_name>
- このスナップショットをローカルマシンに移動して、インテル® Advisor GUI で開きます。
生成された結果の次の点に注意してください。
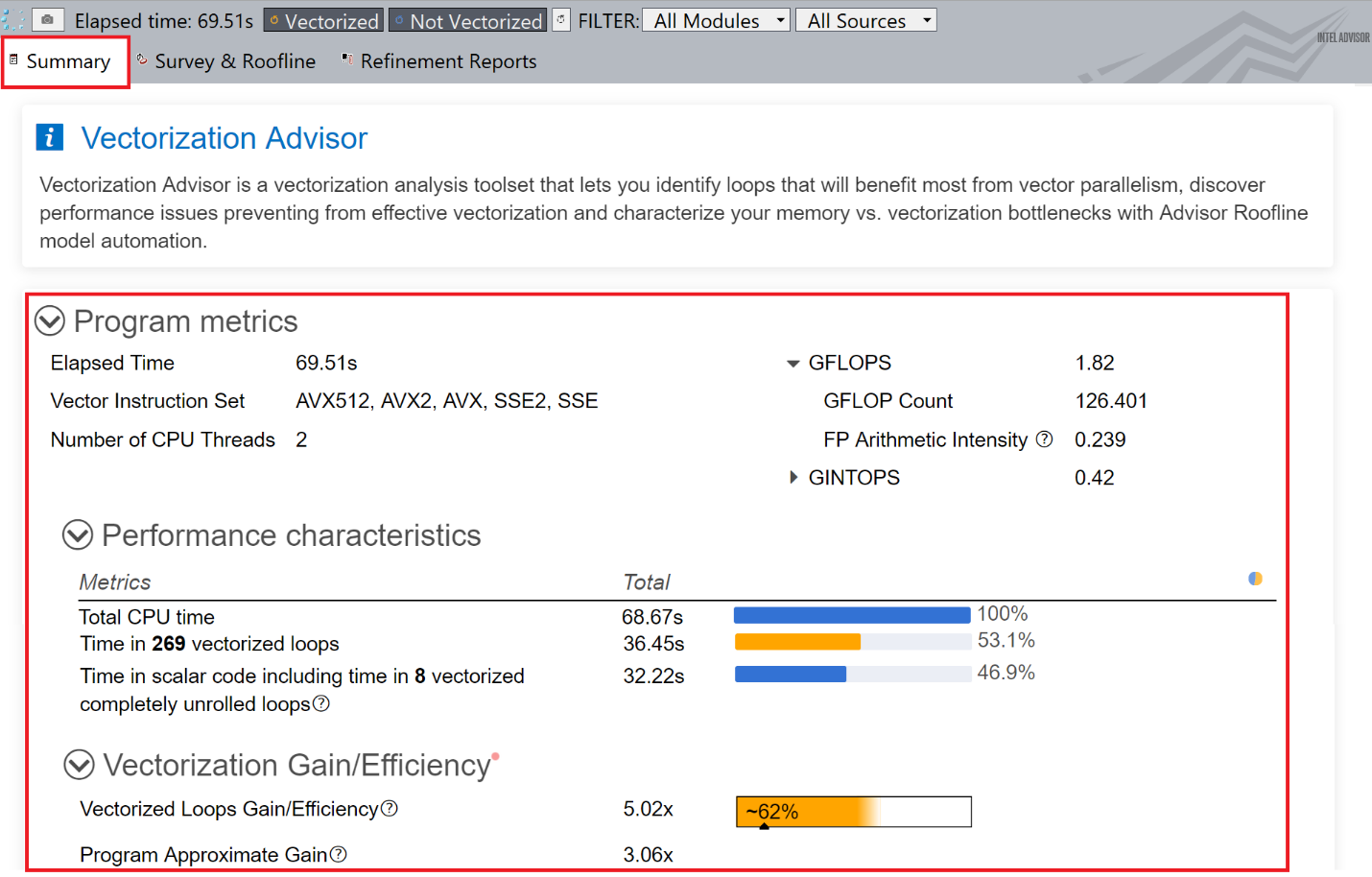
- サーベイレポートの [サマリー] タブで、経過時間、ベクトル化されたループの数、使用されたベクトル命令セット、GFLOPS などのプログラムメトリックを確認します。
![[サマリー] タブに表示された WRF アプリケーションのプログラムメトリック](https://www.isus.jp/wp-content/uploads/image/5E56D42C-74BF-48E9-829E-FAD07E7DF082.png)
- [サーベイ & ルーフライン] タブで、アプリケーションのパフォーマンスに関連する詳細を確認します。ループ/関数リストには、最も時間を費やしているループ/関数が上位に表示されます。[パフォーマンスの問題] と [ベクトル化されない理由] カラムのメッセージを参照して、アプリケーションのパフォーマンス向上につながる次のステップを特定します。
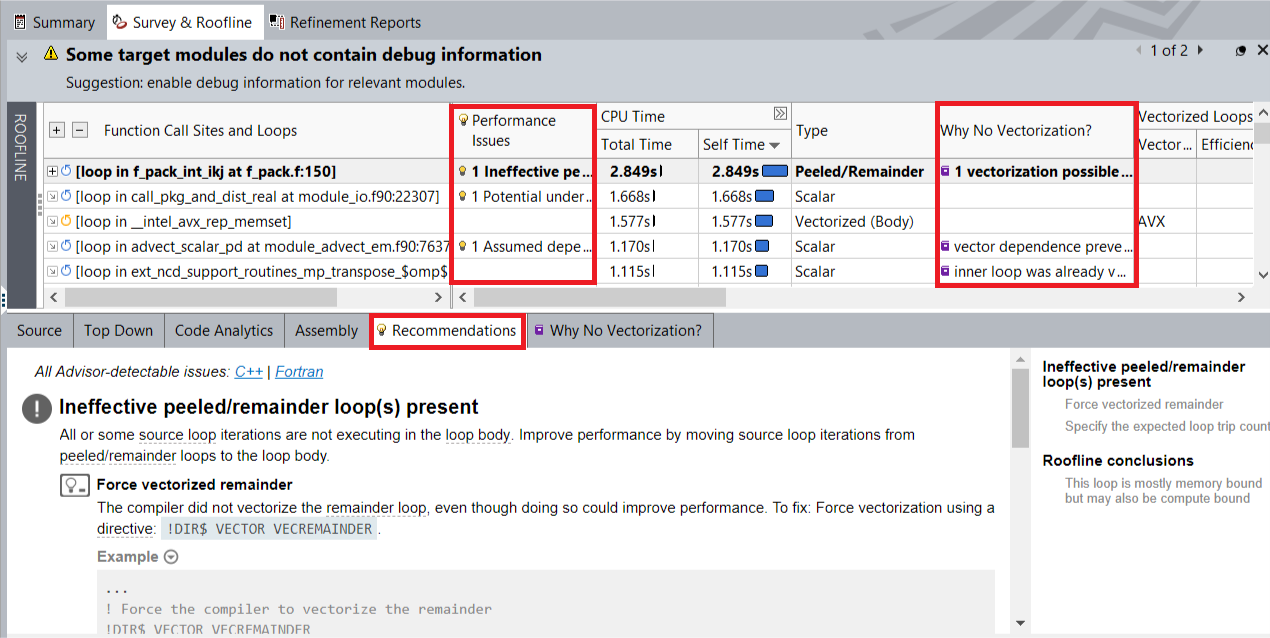
ルーフライン・グラフを確認
インテル® Advisor は、システムのピーク計算パフォーマンスとメモリー帯域幅に対するアプリケーションのパフォーマンス・レベルを相対的に表示するルーフライン・グラフを作成できます。MPI アプリケーションのルーフライン・グラフを作成するには、前のセクションで説明したように、サーベイ解析およびトリップカウントと FLOP 解析を順番に実行する必要があります。これらの解析で、MPI アプリケーションのルーフライン・グラフの作成に必要なすべてのデータを収集します。
ルーフライン・グラフを開くには、インテル® Advisor GUI で開いた解析結果の左上ペインにある [ルーフライン] トグルボタンをクリックします。次の点に注意してください。
- 水平方向のドットの位置から、WRF のループの大部分は計算とメモリー帯域幅の両方で制限されていることが分かります。
- ドットのサイズと色から、ほとんどのループは同程度の時間がかかっていることが分かります。
ルーフライン・グラフの調整
インテル® Advisor は単一のランク 0 で実行されているため、ドットはアプリケーション全体のパフォーマンスではなく、ランク 0 のパフォーマンスのみを示します。そのため、ルーフライン・グラフのループとルーフの距離 (相対ドット位置) は、実際よりも低いパフォーマンスを示しています。
ドットの位置を調整するには、ルーフライン・グラフの上部ペインのドロップダウン・リストから、コア数をアプリケーションの MPI ランクの合計数に変更します。WRF アプリケーションの場合、48 コアを選択します。コア数を変更するとシステムメモリーが調整され、それに応じてルーフライン・グラフのルーフが再計算されます。ドットの相対位置は再計算されたルーフに応じて変化しますが絶対値は変化しません。
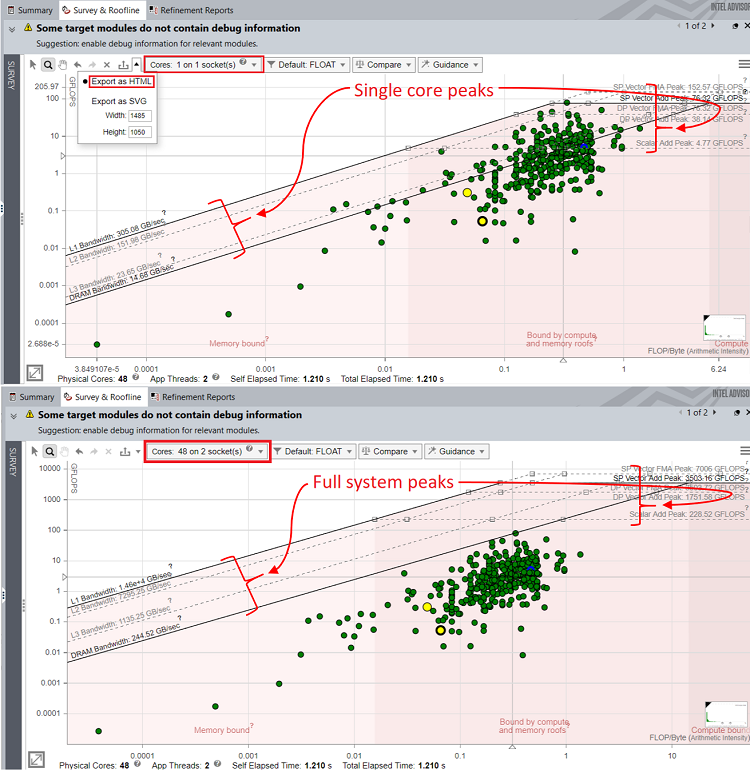
ルーフライン・グラフのエクスポート (オプション)
MPI アプリケーションで個別のルーフライン・グラフを共有するには、HTML または SVG ファイルとしてエクスポートすることを推奨します。次のいずれかの操作を行います。
- インテル® Advisor GUI で開いたルーフライン・グラフで、ツールバーの [エクスポート] ボタンをクリックし、[HTML としてエクスポート] または [SVG としてエクスポート] を選択します。
- –report=roofline オプションを指定して CLI コマンドを実行します。次に例を示します。
advixe-cl --report=roofline --project-dir=<project_dir>/project1 --report-output=./wrf_roofline.html
MPI アプリケーションでは、インテル® Advisor GUI をインストールする必要がないため、CLI コマンドを使用することを推奨します。
ルーフラインの詳細は、インテル® Advisor のルーフラインを参照してください。
依存関係解析を実行 (オプション)
インテル® Advisor は、有用な推奨事項を提供するため、アプリケーションのパフォーマンスに関する詳細を要求することがあります。例えば、サーベイレポートの [パフォーマンス問題] カラムに「依存関係が想定されます」というメッセージが示されるループでは、依存関係解析を実行することを推奨します。
依存関係データを収集するには、解析するループを選択する必要があります。MPI アプリケーションでは次のいずれかを選択します。
- ループ ID ベースの収集:
- サーベイレポートを生成してループ ID を取得します。
advixe-cl --report=survey --project-dir=./<project_dir>/project1
このコマンドは、アプリケーションのすべてのループのメトリックをセルフ時間でソートした advisor-survey.txt ファイルを生成します。ループ ID はテーブルの最初のカラムにあります。
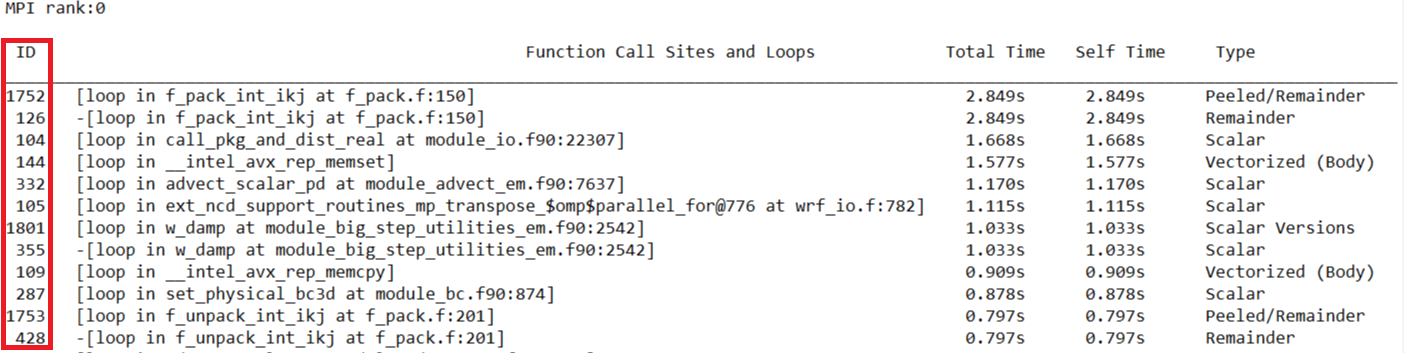
- さらに詳しく解析するループを特定します。
- WRF アプリケーションのランク 0 で選択したループの依存関係解析を実行します。この例では、235 行と 355 行にあるループを選択します。
mpiexec -genvall -n 48 -ppn 48 -gtool "advixe-cl --collect=dependencies --mark-up-list=235,355 --project-dir=<project_dir>/project1:0" ./wrf.exe
- サーベイレポートを生成してループ ID を取得します。
- ソースの位置に基づいた収集: 解析するループのソースの位置を file1:line1 形式で指定し、WRF アプリケーションのランク 0 で選択したループの依存関係解析を実行します。
mpiexec -genvall -n 48 -ppn 48 -gtool "advixe-cl --collect=dependencies --mark-up-list=module_advect_em.f90:7637,module_big_step_utilities_em.f90:2542 --project-dir=<project_dir>/project1:0" ./wrf.exe
依存関係解析を実行すると、解析結果の [リファインメント・レポート] タブに結果が追加されます。WRF アプリケーションの場合、依存関係解析により選択したループに依存関係がないことが確認され、[推奨事項] タブに関連する最適化のステップが提案されます。
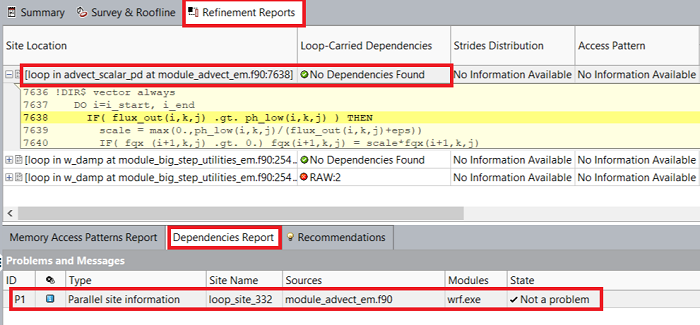
メモリー・アクセス・パターン解析を実行 (オプション)
連続しないメモリーアクセスやユニットストライドおよび非ユニットストライドのメモリーアクセスなど、さまざまなメモリーの問題に関して MPI アプリケーションを確認するには、メモリー・アクセス・パターン (MAP) 解析を実行します。インテル® Advisor は、サーベイレポートの [パフォーマンス問題] カラムに「非効率なメモリー・アクセス・パターンがあります」というメッセージが示されるループでは、MAP 解析を実行することを推奨します。MAP 解析を実行するには、次の操作を行います。
- さらに詳しく解析するループ ID またはソースの位置を特定します。
- WRF アプリケーションのランク 0 で、選択したループ (ここでは 155 行目と 200 行目) の MAP 解析を実行します。
mpiexec -genvall -n 48 -ppn 48 -gtool "advixe-cl --collect=map --mark-up-list=155,200 --project-dir=<project_dir>/project1:0" ./wrf.exe
MAP 解析を実行すると、解析結果の [リファインメント・レポート] タブに結果が追加されます。WRF アプリケーションの場合、MAP 解析で選択したループのすべてのストライドがランダムであり、メモリーとベクトル化のパフォーマンスが最適化されていない可能性があることが報告されます。次のステップの可能性として、[推奨事項] タブのメッセージを確認してください。
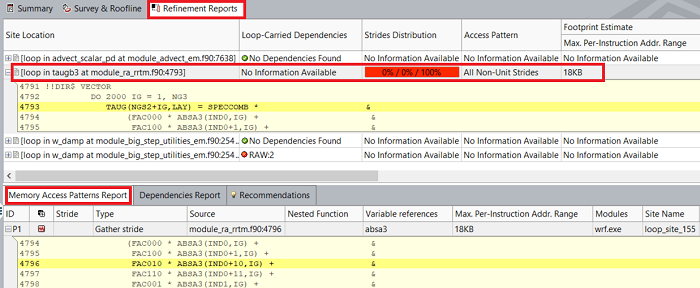
要約
- インテル® Advisor を使用して、単独、複数、またはすべてのランクの MPI アプリケーションを解析できます。このレシピでは WRF Conus12km ワークロードを使用しました。
- MPI アプリケーションのサーベイ、トリップカウントと FLOP、ルーフライン、依存関係、またはメモリー・アクセス・パターン解析はインテル® Advisor CLI でのみ実行できますが、生成された結果はインテル® Advisor GUI で表示できます。
関連情報
ここでは、レシピに関連するドキュメントとリソースへのリンクを示します。
- 気象研究と予測 (WRF) モデル (英語)
- アプリケーション・パフォーマンス・スナップショット (英語)
- リモートシステム上でパフォーマンスを解析してローカル macOS* システム上で結果を表示
- インテル® Advisor ユーザーズガイド: [対応する advixe-cl コマンドオプション] ダイアログボックス
- インテル® Advisor ユーザーズガイド: MPI ワークロードの解析
- インテル® Advisor のルーフライン
コンパイラーの最適化に関する詳細は、最適化に関する注意事項を参照してください。
