インテル® Advisor 2019 Update5
概要:
- インテル® Advisor は、最新のサードパーティー・コンポーネントを含むように更新されました。これには、最新の機能およびセキュリティー・アップデートが含まれます。最新バージョンにアップデートすることを強く推奨します。
- コード解析でルーフラインのガイドが提供されるようになりました。この機能を使用することで、ルーフライン・グラフが見やすくなります。
- Visual Studio* 2019 Update 1 への統合がサポートされました。
- ルーフライン・グラフのカスタマイズを容易にするため、設定メニューが改良されました。
- コマンドライン・へルプの内容が更新されました。
インテル® Advisor 2019 Update4
概要:
- インテル® Advisor は、最新のサードパーティー・コンポーネントを含むように更新されました。これには、最新の機能およびセキュリティー・アップデートが含まれます。最新バージョンにアップデートすることを強く推奨します。
- ファイルシステムの flock 操作の要件がなくなりました。以前のバージョンでは、flock が無効になっているとインテル® Advisor は失敗し、プロジェクトをローカルに保存する必要がありました。Lustre* などのファイルシステムでも問題なく動作するはずです。
- [サマリー] ペインで、ループおよびアプリケーションごとの推奨事項が表示されるようになりました。これは、Update3 で削除された「上位 5 つの推奨事項」に代わるもので、これを拡張したものです。
- [サーベイ] と [コード] 解析は、ニューラル・ネットワーク・アプリケーションで使用される VNNI (開発コード名 Cascade Lake でサポート) を使用するループ/関数を識別できるようになりました。
- カラム設定が [トップダウン] ペインに拡張されました。これまでは、[サーベイ] ペインのカスタマイズに限定されていました。
- FLOPS とトリップカウント収集は、既存のデータを置き換えるのではなく拡張するようになりました。例えば、トリップカウントが収集され、その後 FLOPS のみを収集するため 2 回目の解析が行われた場合、FLOPS データはトリップカウントを置き換えることなく結果に追加されます。
- 新しいプレビュー機能: コード解析におけるルーフラインのガイド。この機能を使用することで、ルーフライン・グラフが見やすくなります。この機能を有効にするには、環境変数に ADVIXE_EXPERIMENTAL=roofline_guidance を設定します。
- Microsoft* Visual Studio* 2019 をサポート。
- フローグラフ・アナライザー:
- Red Hat* Enterprise Linux* 7 のサポートが復活しました。
- 階層ビューの操作後にグラフのプロパティーを復元するバグを修正しました。
- グラフ全体でエッジの使用をサポートしました。これはデフォルトでは制限されていますが、[Preferences] ダイアログで有効にできます。
インテル® Advisor 2019 Update1
新機能:
- 整数ルーフライン解析を使用した整数計算の最適化
- 正確なメモリー使用量を取得し、キャッシュ・シミュレーションを使用して複数のハードウェア構成をチェック
- Linux* や Windows* 上で収集されたデータを macOS* ユーザー・インターフェイスで表示して解析
- フローグラフ・アナライザーによるグラフ・アルゴリズムのプロトタイプ作成
- 新しい推奨事項: C++ と Parallel STL の標準アルゴリズムを最適化
2018 以降の新機能:
- ルーフラインの拡張
- コールスタック付きのルーフラインが利用可能になりました (詳細は https://software.intel.com/en-us/articles/roofline-with-callstacks)
- ルーフラインの動的 HTML コピーのエクスポートによって結果を共有:
advixe-cl –report roofline –report-output=path/to/output.html - 複雑なグラフの解析を簡素化し、選択したドットをビットマップとして保存するため、ルーフライン・グラフ上の任意のドットのサブセットをフィルター処理できます
- アプリケーションの実用パフォーマンスの限界を見るため、カスタムスレッド数にルーフラインを調整する機能
- ループラインのベンチマークが複数ランクの MPI アプリケーションで同期されるようになったため、同じ物理ノードで実行されるすべてのランクでルーフの値が同じになります
- 同じグラフで複数のルーフライン結果を比較する機能
- 単一の CLI コマンドでルーフライン・データを収集: advixe-cl –collect roofline
- 選択可能なプロファイルを使用して高速に解析結果を得るためオーバーヘッドを軽減
- プロジェクトのプロパティーでループ呼び出しカウントを制限し、解析時間を設定することで、メモリー・アクセス・パターンと依存関係解析のオーバーヘッドを軽減
- 解析範囲を狭めてオーバーヘッドを軽減するため、ルーフライン、FLOPS とトリップカウント収集でプロファイルを選択する機能を追加
- ユーザビリティーの向上
- オプションメニューでフォントサイズをカスタマイズできるようになりました。これは、SSH の X 転送セッションで GUI の表示を調整するのに役立ちます
- コマンドラインから、ソースファイルと行レベルでループを選択する機能:
advixe-cl –mark-up-loops –select main.cpp:12,other.cpp:198 - Pythoin* を使用して簡単に HTML レポートを作成:
advixe-python to_html.py ProjectDir
- 推奨事項タブの改善:
- 推奨事項タブを一新し使いやすいレイアウトに
- 推奨される特定のアンロール係数値や、インライン展開される関数名など、ユーザーコード固有の推奨事項のパラメーター
- 新たな推奨事項: メモリー依存のアプリケーションのパフォーマンスを改善する、非テンポラルストア (NTS) 命令の使用
プレビュー機能:
- 各ループでボトルネックとなっているメモリー階層を正確に示す統合ルーフライン。この機能を有効にするには、環境変数 ADVIXE_EXPERIMENTAL=int_roofline を設定します。(新規)
オペレーティング・システムのサポート:
- Fedora* 28 (新規)
- Red Hat* Enterprise Linux* 7.5 (新規)
- SUSE* Linux* Enterprise Server 15 (新規)
- macOS*: 10.11.x、10.12.x、および 10.13.x (新規)
- Microsoft* Windows® 10 ビルド 17134
- Ubuntu* 18.04
- SUSE* Linux* Enterprise Server 12 SP3
詳細:

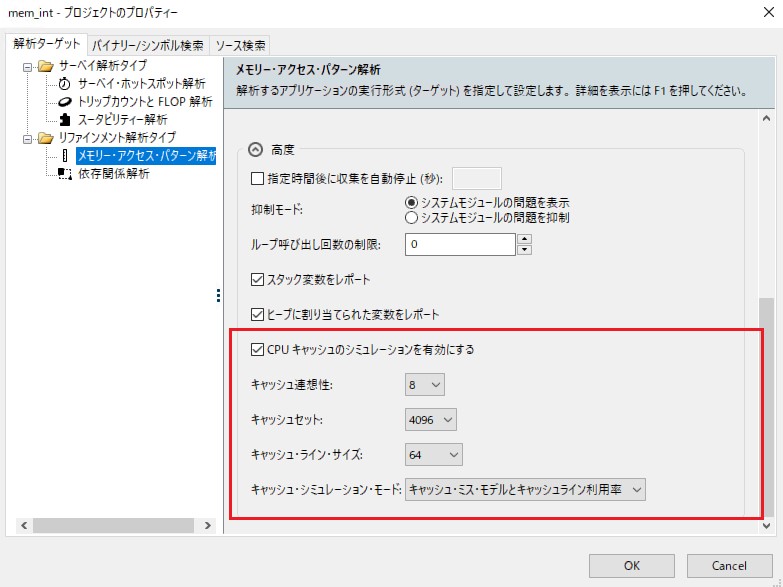
インテル® Advisor にキャッシュ・シミュレーター機能が追加されました。これにより、正確なメモリー使用量と失われたアプリケーションの情報が得られます。この機能を有効にして、[プロジェクトのプロパティー] の [メモリー・アクセス・パターン解析] でキャッシュの構成を設定できます。シミュレーターは、モデルミスと、キャッシュラインの利用率または利用量のいずれかに設定できます。コマンドラインで次のフラグを使用して、MAP 解析中のキャッシュ・シミュレーターを制御します。
- -enable-cache-simulation
- -cachesim-mode=<footprint/cache-misses/utilization>
- -cachesim-associativity=<数値>
- -cachesim-sets=<数値>
- -cachesim-cacheline-size=<数値>
環境変数 ADVIXE_EXPERIMENTAL=int_roofline を設定すると、キャッシュ・シミュレーション機能が拡張され、統合ルーフライン・ビューの機能が有効になります。このバージョンのキャッシュ・シミュレーターは、各ループでロードおよびストアされたバイト数などのデータに対する複数レベルのキャッシュをモデル化します。オプションで、特定のキャッシュ構成のシミュレーションを設定できます。構成の形式は、レベル 1 から始まる「/」で区切ったそれぞれのキャッシュレベルを指示します。各レベルは、「カウント:ウェイ:サイズ」の形式で指定します。
例えば、4:8w:32k/4:4w:256k/16w:6m は、次の構成を示します。
- 4 つの 8 ウェイ 32KB レベル 1 キャッシュ、
- 4 つの 8 ウェイ 256KB レベル 2 キャッシュ、
- (1 つの) 16 ウェイ 6MB レベル 3 キャッシュ
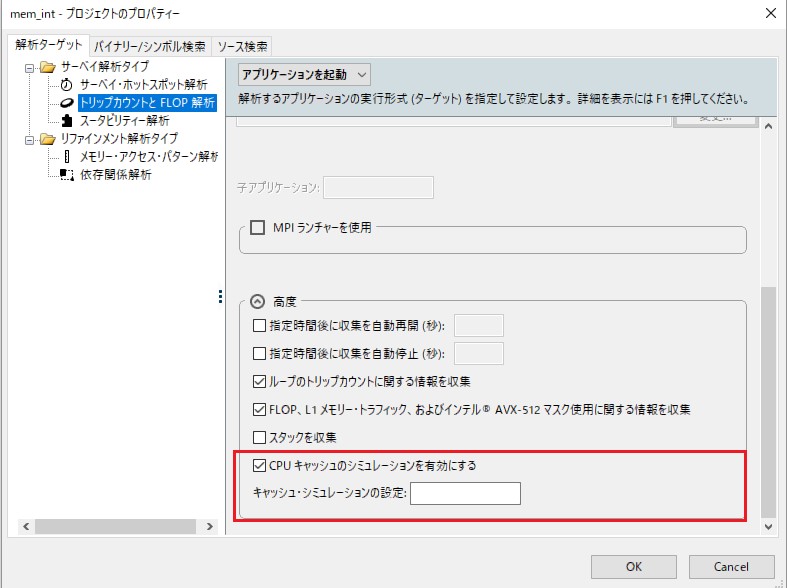
拡張されたキャッシュ・シミュレーターは、インテル® Advisor の [プロジェクト・プロパティー] の [トリップカウントと FLOP 解析] にあるチェックボックスをオンにすることで、GUI 上で有効にできます。入力フィールドはキャッシュの設定にも用意されています。コマンドラインで、トリップカウント解析中に -enable-cache-simulation フラグを追加します。-cache-config=yourconfighere フラグを使用して設定できます。

整数ルーフライン
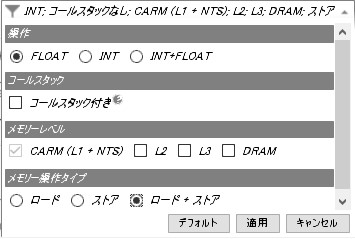
ルーフラインの機能に整数操作のサポートが追加されました。これまでは、浮動小数点命令 (FLOP) のみが記録されていました。ピーク整数レベルがルーフに追加され、ルーフラインは FLOP のみ、IntOP のみ、またはすべての操作をカウントするように設定できます。インテル® Advisor は、この設定に従ってドットとルーフの位置を自動的に調整します。
統合ルーフライン
環境変数 DVIXE_EXPERIMENTAL=int_roofline を設定することで、実験的機能としてキャッシュ・シミュレーションによる統合ルーフライン・モデルの実装が有効になります。これまで、インテル® Advisor のルーフライン・モデルは、すべてのメモリー・トラフィックに基づいて演算強度を計算するモデルでキャッシュを意識していました。この機能は L1/CARM 設定で維持されますが、統合ルーフラインにはキャッシュ・シミュレーターで予測される特定レベルのキャッシュ・トラフィックに基づいて演算強度を計算するグラフも含まれます。これらのグラフの組み合わせのデータポイントは、ドロップダウンを使用して同時に表示できます。
特定のレベルのグラフのデータポイントは、そのレベルのルーフに関して読み取られ、それを超えることはできません。演算強度は統合ルーフラインの非 L1 レベルでは可変であるため、これはそれほど厳格な制限ではありません。CARM では、すべてのパフォーマンス最適化はデータポイントの垂直位置を変更しますが、AI は変化しません (プログラマーまたはコンパイラーによるアルゴリズムの変更を除く)。統合ルーフラインのほかのレイヤーでは、パフォーマンスを向上させることに加えて、メモリー最適化によってデータポイントの AI を高めることができます。
これは、メモリーのボトルネックを特定するのに役立ちます。計算のボトルネックを特定する方法は以前と同様ですが (ルーフ上のメトリックを確認します)、それぞれのレベルのデータポイントをルーフと比較することで、帯域幅の制限を識別できるようになりました。ポイントが帯域幅のルーフを超えることができず、ルーフに近接するものは明らかなボトルネックであり、メモリー最適化によって演算強度を増加させることで上方向に移動することを考慮しなければいけません。
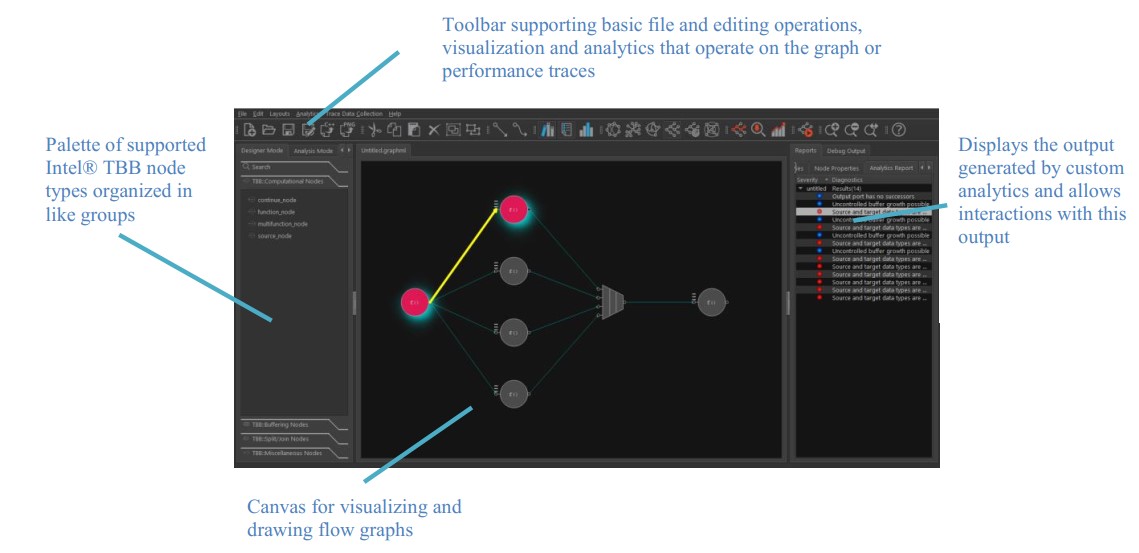
フローグラフ・アナライザー
フローグラフ・アナライザー (FGA) は、インテル® Advisor の機能として利用できます。この新しいツールは、インテル® Advisor と同じディレクトリーにインストールされ、インテル® スレッディング・ビルディング・ブロック (インテル® TBB) のフローグラフ・インターフェイスを使用する並列アプリケーションの設計と解析に有用な GUI ベースのアプローチを提供します。インテル® TBB ライブラリーは、マルチコア・アーキテクチャーとヘテロジニアス・システムの利点を活用するため、並列アプリケーションを簡単に作成できる機能を提供する、広く利用されている C++ テンプレート・ライブラリーです。フローグラフ・インターフェイスは、依存関係グラフとデータ・フローグラフを効率良く実装することで、より高レベルで並列処理を活用するため、2011 年にインテル® TBB に導入されました。