
Codeplay 社は Linux 向けの oneAPI for NVIDIA GPU プラグインを数年前から提供していましたが、2024年末ついに Windows 版のプラグインがリリースされました。
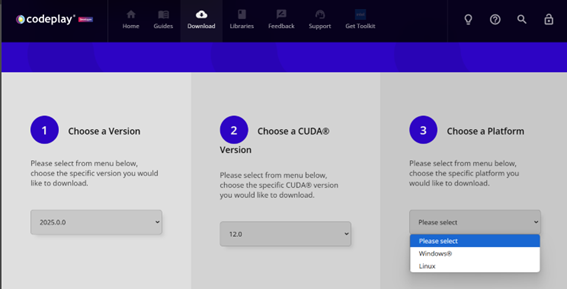
Codeplay 社のダウンロード・サイト (https://developer.codeplay.com/products/oneapi/nvidia/download (英語)) では、上記のようにプラットフォームに Linux と Windows が選択できるようになっています。Linux 版のパッケージはシェルスクリプトとして提供されますが、CUDA 12.0 向けのWindows 版はインストール・パッケージ (2025.0.0 では oneapi-for-nvidia-gpus-2025.0.0-cuda-12.0-windows.exe) として提供されます。
iSUS ではすでに 2025.0.0 バージョンの導入ガイドの日本語版を公開していますので(https://www.isus.jp/products/oneapi/oneapi-for-nvidia-gpu-get-started/)、Windows プラットフォームで要件を満たす NVIDIA GPU を搭載するシステムをお持ちであれば、oneAPI ベース・ツールキット、Visual Studio、CUDA 開発キット、およびこのプラグイン・パッケージをインストールすることで、すぐに SYCL プログラムで CPU、内蔵グラフィックス、そして NVIDIA GPU を利用することができます。
Linux 環境では、インテル® GPU (内蔵グラフィックスを含む) と NVIDIA GPU を共存させたり、ドライバーやグラフィックス・カードを入れ替えるとちょっと手間のかかる作業が必要だったりしますが、Windows 環境では必要なソフトウェアのインストール・パッケージをインストールするだけですぐにプラグインが適用されます。
まず、oneAPI for NVIDIA GPU プラグインをインストールする前に、インテル® oneAPI ベース・ツールキット、Visual Studio、CUDA 開発キットをシステムにインストールします。oneAPI for NVIDIA GPU プラグインは MSVC ビルドツールを使用するため、Visual Studio をインストールしておく必要があります。これらのツールのインストールが完了したら、「Intel oneAPI command prompt for Intel 64 for Visual Studio XXXX」 (XXXX には VS のバージョンが入ります) を開いて、sycl-ls コマンドで CPU と統合グラフィックスが識別されていることを確認してください。
当然ながら、この時点では NVIDIA GPU は表示されません。
次に入手した oneAPI for NVIDIA GPU プラグインのインストール・パッケージを起動してインストールします。
インストーラーの指示に従ってインストールを完了してください。この時点でインテル® oneAPI ベース・ツールキットに含まれるインテル® DPC++/C++ コンパイラー 2025 や CUDA 開発キットがインストールされていないと警告が表示されます。
インストールが完了したら、再び sycl-ls コマンドを実行してみます。

上記のように CUDA GPU が識別され表示されるはずです。インストールはこれだけです。以降 NVIDIA GPU やインテル® GPU のドライバーがアップデートされても、余計な作業は発生しません。
テストシステムには GeForce GTX 1060 が搭載されているため、次のような表示になっていますが、
[cuda:gpu][cuda:0] NVIDIA CUDA BACKEND, NVIDIA GeForce GTX 1060 6GB 6.1 [CUDA 12.7]
搭載される NVIDIA GPU によって表示される名称は異なります。
これで準備は完了です。後は、皆さんのプログラムでテストしてください。
ここでは、次のような簡単なプログラムを使用して、利用するデバイスのリソースを表示してみます。GPU の各種リソースにアクセスする API を使用していますので参考にしてください。
sample.cpp
#include <sycl/sycl.hpp>
#include <iostream>
using namespace sycl;
void output_dev_info( const device& dev, const std::string& selector_name) {
std::cout << selector_name << ": Selcted Device: " <<
dev.get_info<info::device::name>() << "\n";
std::cout << "-> Device Vendor: " <<
dev.get_info<info::device::vendor>() << "\n";
std::cout << "-> Number of CU: " <<
dev.get_info<info::device::max_compute_units>() << "\n";
std::cout << "-> Max work-group size: " <<
dev.get_info<sycl::info::device::max_work_group_size>() << "\n";
std::cout << "-> Max sub-group size: " <<
dev.get_info<sycl::info::device::max_num_sub_groups>() << "\n";
std::cout << "-> SubGroup size: " ;
for (const auto &s : dev.get_info<sycl::info::device::sub_group_sizes>()){
std::cout << s << " ";
}
std::cout << std::endl;
std::cout << "-> Max local mem size: " <<
dev.get_info<sycl::info::device::local_mem_size>() / 1000 << " KB\n";
std::cout << "-> Max global mem size: " <<
dev.get_info<sycl::info::device::global_mem_size>() /1000000000 << " GB\n";
std::cout << "-> Max global mem cache size: " <<
dev.get_info<sycl::info::device::global_mem_cache_size >() / 1000000 << " MB\n";
auto dev1 = sycl::device{sycl::aspect_selector(
std::vector{sycl::aspect::custom, sycl::aspect::emulated}
)};
}
int main() {
output_dev_info( device{ default_selector_v}, "default_selector" );
return 0;
}
10~13 行目の処理には、少し説明が必要ですね。CPU やインテル® グラフィックスは複数サイズの sub-group をサポートできるため、複数ある場合ループでそれぞれのサイズを取得しています。
上記の C++ ソースをコンパイルします。
$ icpx -fsycl -fsycl-targets=nvptx64-nvidia-cuda,spir64 sample.cpp -o sample.exe
デバイスセレクター環境変数 (ONEAPI_DEVICE_SELECTOR) に何も設定されていないことを確認し、プログラムを実行してみます。
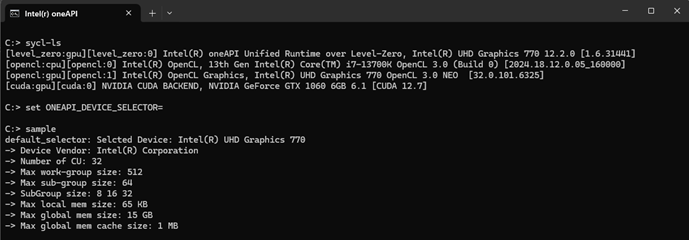
複数ターゲット (nvptx64-nvidia-cuda,spir64 ) を設定していますが、デバイスセレクターに何も設定されていないとデフォルトで上位にあるオフロードデバイス (この場合インテル® UHD グラフィックス 770) が自動選択されます。このデバイスのリソース (デバイス名、ベンダー名、CU 数、最大 work-group サイズ、最大 sub-group サイズ、sub-group サイズ、最大ローカル・メモリー・サイズ、最大グローバル・メモリー・サイズ、そして最大グローバル・メモリー・キャッシュ・サイズ) が表示されます。
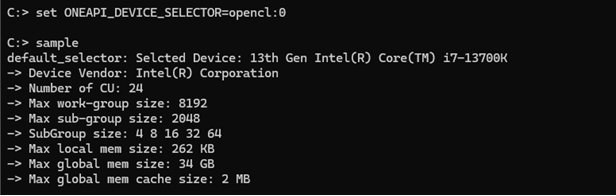
同様に、デバイスセレクター環境変数に opencl:0 (ここでは CPU) を設定して実行してみます。
最後に、今回の目的である NVIDIA GPU (cuda:0) を選択して実行します。
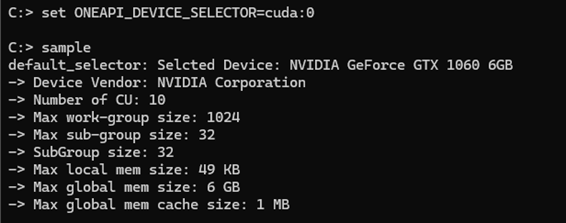
いかがですか? Windows 環境で簡単に SYCL プログラムをマルチターゲットで実行できますね。
ちなみに、コンパイル時のオプションを -fsycl-targets=nvptx64-nvidia-cuda に変更すると、生成されるプログラムは NVIDIA GPU 専用となり、デバイスセレクター環境変数を設定しなくても NVIDIA GPU だけで実行できます。
余談ですが、iSUS やインテル社の記事にデバイスセレクター環境変数を set ONEAPI_DEVICE_SELECTOR=”cuda:0″ のようにダブルクオートで囲む記載がありますが、” ” で囲んではいけません。エラーになります。また、インテル® DPC++/C++ コンパイラーはすでに 2025.0.4 にアップデートされていますが、2025.0.0 の oneAPI for NVIDIA GPUプラグインはそのまま使用できます。
マルチターゲットや NVIDIA GPU 向けのプログラミングのヒントについては導入ガイド (https://www.isus.jp/products/oneapi/oneapi-for-nvidia-gpu-get-started/) を参照してください。
残念ながら、oneAPI for AMD GPU プラグイン Windows 版のリソースは表明されていません。リリースされれば、さらに選択の自由度が高まることでしょう。興味がある方は Linux 環境でお試しください。修行のような作業が必要になりますが …
