
この記事は、The Parallel Universe Magazine 57 号に掲載されている「Accelerate Memory-Bandwidth-Bound Kernels Using the Intel® Data Streaming Accelerator (Intel® DSA)」の日本語参考訳です。原文は更新される可能性があります。原文と翻訳文の内容が異なる場合は原文を優先してください。

インテル® データ・ストリーミング・アクセラレーター (インテル® DSA) は、第 4 世代インテル® Xeon® スケーラブル・プロセッサー以降で利用できる、高性能なデータコピーおよび変換アクセラレーターです。メモリーコピー、比較、フィルなどのさまざまなデータ操作をサポートします。インテル® DSA は、作業キューと記述子を使用して CPU ソフトウェアと対話します。記述子には、操作のタイプ、ソースアドレスとデスティネーション・アドレス、データ長など、目的の操作に関する情報が含まれています。詳細については、The Parallel Universe 第 53 号の「ダイレクト・メモリー・アクセスの先へ: インテル® データ・ストリーミング・アクセラレーターによるデータセンター・コストの削減」を参照してください。
多くの科学および商用アプリケーションは、最適なパフォーマンスを実現するため、高性能な CPU と高いメモリー帯域幅を必要とします。CPU は世代を重ねるごとに、コアの追加、SIMD 幅の増加、新しい ISA 拡張などのマイクロアーキテクチャー機能によって性能が大幅に向上していますが、DRAM 帯域幅の向上はこれまで CPU の改良に追従できていませんでした。DRAM からデータをフェッチする速度が CPU 実行ユニットのストールを防ぐのに十分ではないため、実際のアプリケーションでは期待される性能向上が得られない「メモリーウォール」と呼ばれる現象に長年悩まされてきました。
CPU には、ロード/ストアキューとスーパーキュー形式のアーキテクチャー・バッファーと、メモリーウォールの効果を軽減するハードウェア・プリフェッチャーがありますが、各 CPU コアがハードウェア・キューに保持できるエントリーの数は限られているため、コア数が少ない場合はメモリー帯域幅への影響は限定的です。DRAM からデータをフェッチする必要がある場合、各メモリー要求が DRAM レイテンシーによりバッファースロットを長時間占有するため、キューがボトルネックになります。この対策として、利用可能な DRAM 帯域幅を完全に飽和させるため、より多くの CPU コアを使用して同時にメモリーアクセス要求を生成するのが一般的です。ただし、コア数が少ない状態で高いメモリー帯域幅を実現することは依然として困難です。
この記事では、インテル® DSA の長所を CPU と組み合わせて補完し、メモリー依存カーネル (つまり、メモリー・サブシステムが演算のデータオペランドを CPU コアに供給できる速度によってパフォーマンスが決まる操作) を高速化する手法について説明します。
パフォーマンスの測定には、標準の STREAM ベンチマークを使用し、CPU のメモリー・パフォーマンスの特性を把握します。STREAM は、Copy、Scale、Add、Triad の 4 つのカーネルで構成されており (表 1)、これらのカーネルはすべてメモリー依存です。

表 1. STREAM カーネルの特性
インテル® DSA は強力なデータコピー/変換エンジンとして機能しますが、データオペランドに対する乗算、加算、積和演算 (FMA: Fused Multiply-Add) などの算術演算の実行はサポートしていません。そのため、インテル® DSA だけでは、メモリーと演算が混在するアプリケーション・カーネルを実行できません。ただし、インテル® DSA は、演算によって生成されるデスティネーション・データの場所 (DRAM または CPU 上の最終レベルキャッシュ (LLC)) を制御する独自の機能を提供します。例えば、DRAM にあるソースバッファーから、DRAM (CPU キャッシュをバイパス) または LLC にあるデスティネーションにデータをコピーできます。
インテル® DSA のキャッシュ書き込み機能を、DRAM から LLC へのプロキシー・ハードウェア・プリフェッチ・エンジンとして使用し、CPU コアで演算を処理できます。このソリューションは、インテル® DSA のデータ転送 (DRAM から LLC へ) と、LLC から CPU レジスターへの非同期コピーによる CPU 計算を効率的にオーバーラップすることで機能します。デフォルトでは、インテル® DSA は LLC の約 14MB の部分に書き込むことができます (第 4 世代インテル® Xeon® スケーラブル・プロセッサー上の 15 ウェイの LLC のうち 2 ウェイ、有効サイズ = 2/15 * LLC のサイズ = 14MB)。図 1 は、CPU のみのアプローチと CPU + インテル® DSA のハイブリッド・ワークフローの高レベルの違いを示しています。
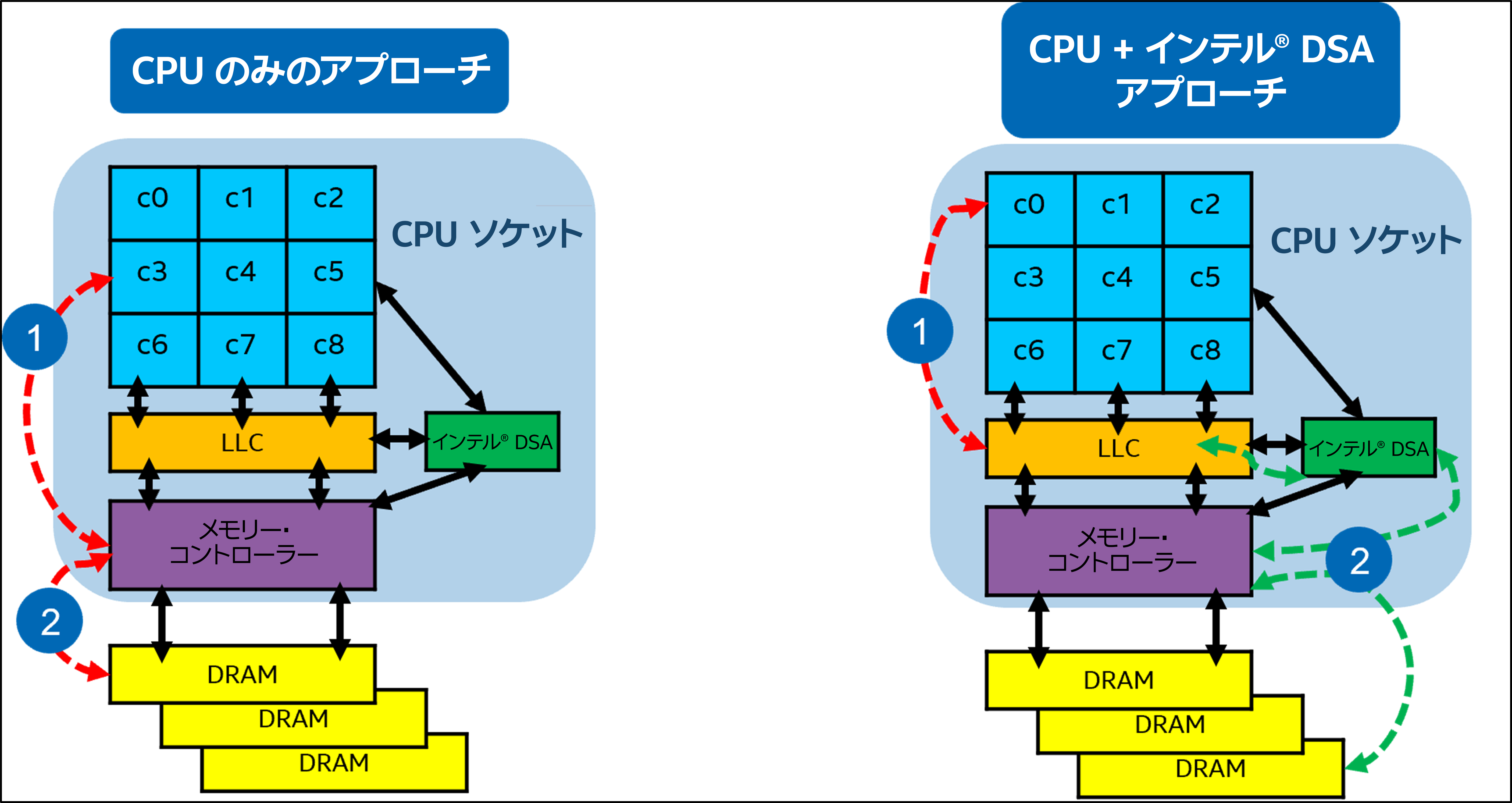
図 1. CPU のみのアプローチと CPU + インテル® DSA のハイブリッド実装の高レベルの違い
CPU のみのアプローチでは、ステップ 1 と 2 は、DRAM 上のデータに対する CPU コアからのロード/ストア要求を指し、メモリー・コントローラーに送られます。CPU + インテル® DSA アプローチのステップ 1 では、CPU は DRAM ではなく LLC からデータをロードします。ステップ 2 では、インテル® DSA は DRAM (メモリー・コントローラー経由) から LLC へのデータ転送を開始します。ステップ 1 と 2 はパイプライン化され、非同期的に実行されるため、CPU が Tx の時点で読み取る必要のあるデータは、T(x-1) でインテル® DSA によって LLC にコピー済みです。つまり、インテル® DSA が同時に次の反復のデータを DRAM からフェッチして LLC に書き込む一方で、CPU は現在の反復のデータを LLC から読み取って演算を実行します。ソフトウェア・パイプラインにより、すべてのインテル® DSA エンジンが効率良く使用されるようになります。
