
この記事は、The Parallel Universe Magazine 50 号に掲載されている「PyTorch* Inference Acceleration with Intel® Neural Compressor」の日本語参考訳です。原文は更新される可能性があります。原文と翻訳文の内容が異なる場合は原文を優先してください。

インテル® ニューラル・コンプレッサー (英語) は、CPU と GPU 上でディープラーニング (DL) の推論のモデルサイズを小さくして高速化する、オープンソースの Python* ライブラリーです (図 1)。量子化、プルーニング、知識蒸留などの一般的なネットワーク圧縮技術に対して、複数の DL フレームワークにわたる統一されたインターフェイスを提供します。このツールは、ユーザーが最適な量子化モデルを素早く見つけられるように、精度を意識した自動チューニングをサポートしています。また、事前に定義された目標を使用してプルーニングしたモデルを生成するため、異なるウェイト・プルーニング・アルゴリズムを実装し、教師モデルから生徒モデルへの知識の蒸留を支援します。インテル® ニューラル・コンプレッサーは、フレームワーク間の相互運用性を高めるため、ONNX* ランタイムに加えて、TensorFlow*、PyTorch*、MXNet* などのフレームワーク向けに API を提供しています。ここでは、PyTorch* モデルでこのツールを使用する利点に注目します。
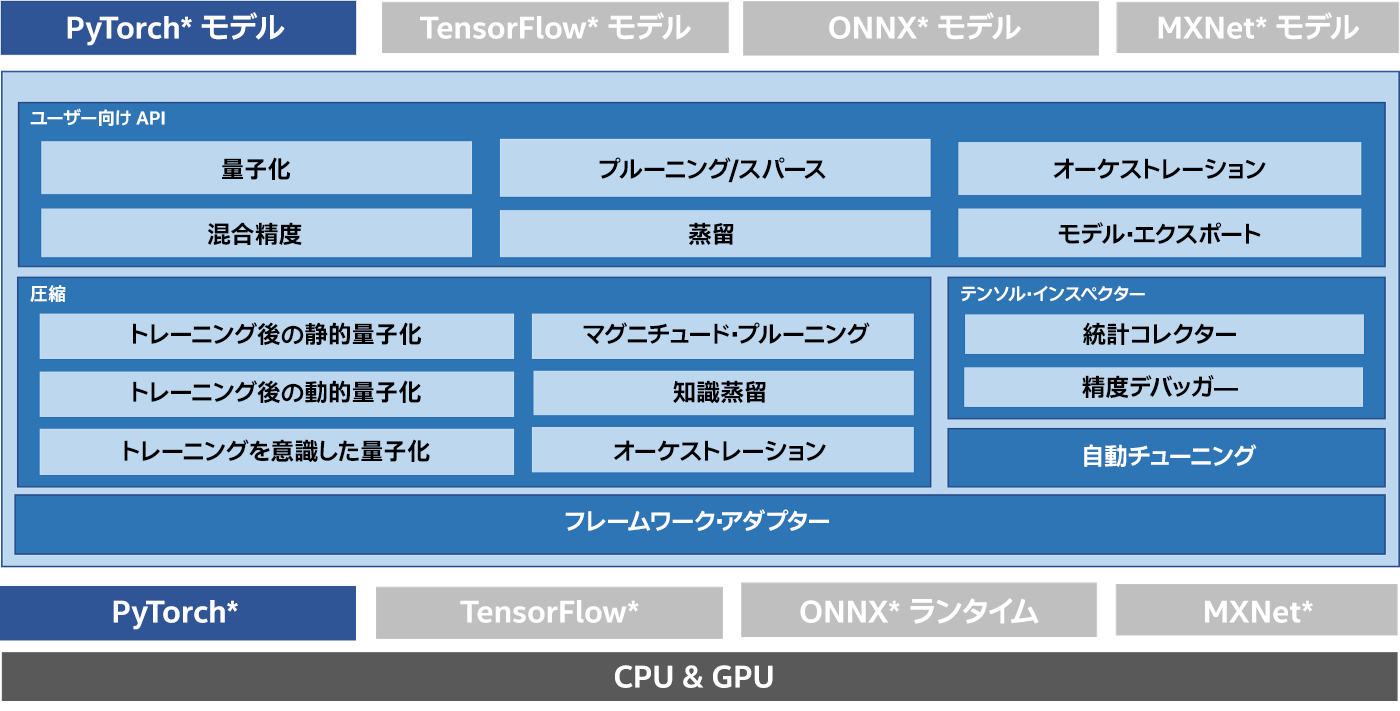
図 1. インテル® ニューラル・コンプレッサー
インテル® ニューラル・コンプレッサーは PyTorch* の量子化を拡張し、量子化と自動混合精度、精度を考慮したチューニング向けの高度なレシピを提供します。PyTorch* モデルを入力として受け取り、最適なモデルを生成します。量子化機能は、標準の PyTorch* 量子化 API をベースに構築されており、モデルレベルからオペレーター・レベルまでのきめ細かい量子化粒度をサポートするため、独自の変更を加えています。このアプローチにより、手動でチューニングをすることなく、より高い精度を得ることができます。
さらに、第 3 世代インテル® Xeon® スケーラブル・プロセッサーの PyTorch* 自動混合精度機能を拡張し、BF16 と FP32 に加えて INT8 をサポートしています。まず、量子化可能な演算子をすべて FP32 から INT8 に変換し、BF16 カーネルが PyTorch* でサポートされ、ベースとなるハードウェアで高速化されている場合は、残りの FP32 演算子を BF16 に変換します(図 2)。
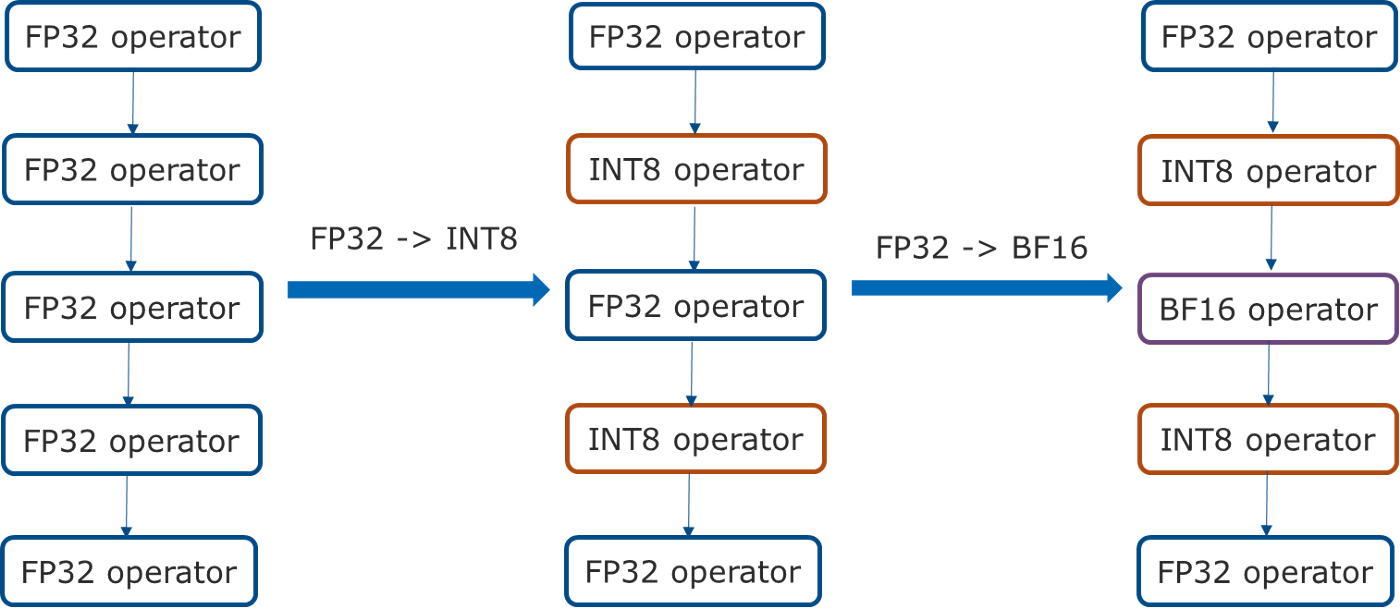
図 2. 自動混合精度
インテル® ニューラル・コンプレッサーは、量子化の生産性を高めるため、精度を考慮した自動チューニング・メカニズムをサポートしています。まず、量子化粒度 (per_tensor または per_channel)、量子化スキーム (対称または非対称)、量子化データ型 (u8 または s8)、キャリブレーション手法 (最小値-最大値または KL 発散) など、量子化機能についてフレームワークに問い合わせ (図 3)、次に各オペレーターでサポートされているデータ型を問い合わせます。結果に応じて、ツールは量子化設定の異なるセットからなるチューニング空間全体を生成し、チューニングの繰り返しを開始します。量子化設定の各セットについて、キャリブレーション、量子化、評価を行い、評価が目標精度に達すると、ツールはチューニング・プロセスを終了し、量子化モデルを生成します。
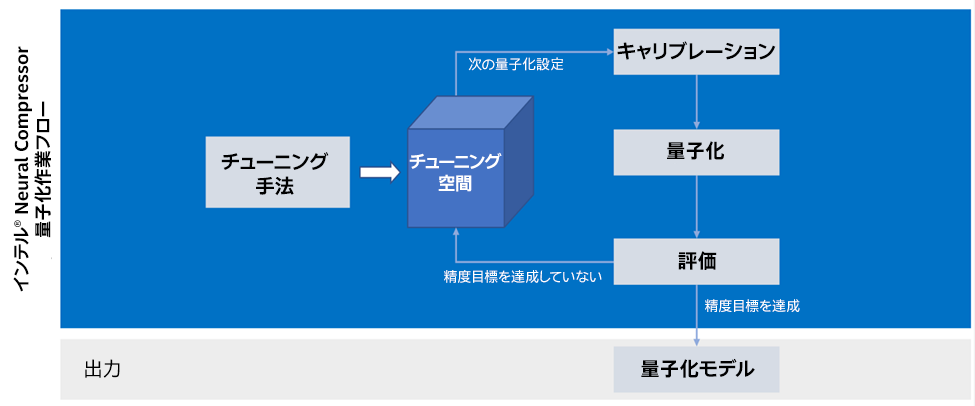
図 3. 精度を意識した自動チューニング
プルーニングでは、主に非構造化および構造化ウェイト・プルーニングに注目します。非構造化プルーニングは、トレーニング中に重みの大きさが事前定義されたしきい値未満になった場合、マグニチュード・アルゴリズムを使用して重みを削除します。構造化プルーニングは、実験的なタイル単位のスパースカーネルを実装し、スパースモデルのパフォーマンスを向上させ、フィルター・プルーニングは、勾配によって計算された重要度スコアに応じて、モデル内のヘッド、中間層、隠れ状態を削除する勾配に基づくアルゴリズムを実装します。
インテル® ニューラル・コンプレッサーは、知識蒸留アルゴリズムも実装しており、大きな「教師」モデルから小さな「生徒」モデルへ、妥当性を損なうことなく知識を伝達します (図 4)。両モデルには同じ入力が与えられ、生徒モデルはその結果を教師および正しい結果ラベルの両方と比較しながら学習します。
