

この記事は、https://www.oneapi.io/spec/ で 2023年9月14日に公開された『oneAPI 1.3 Provisional Specification Rev. 1』 (HTML、PDF) をベースにしています。原文は2000 ページ近くあり、翻訳の時間とリソースも限られるため、全文翻訳ではなく、記事形式で区切った仕様とその解説を提供することにしました。
この回では、『oneAPI 1.3 Provisional Specification Rev. 1』の「oneDNN」の「RNN」の節を取り上げています。
RNN
RNN プリミティブは次の図に示すように、展開されたリカレントセルのスタックを計算します。ここで、破線で囲まれた bias、src_iter および dst_iter パラメーターはオプションです。指定されない場合、bias、src_iter はデフォルトで 0 となります。変数名は標準の規則 (英語) に従います。
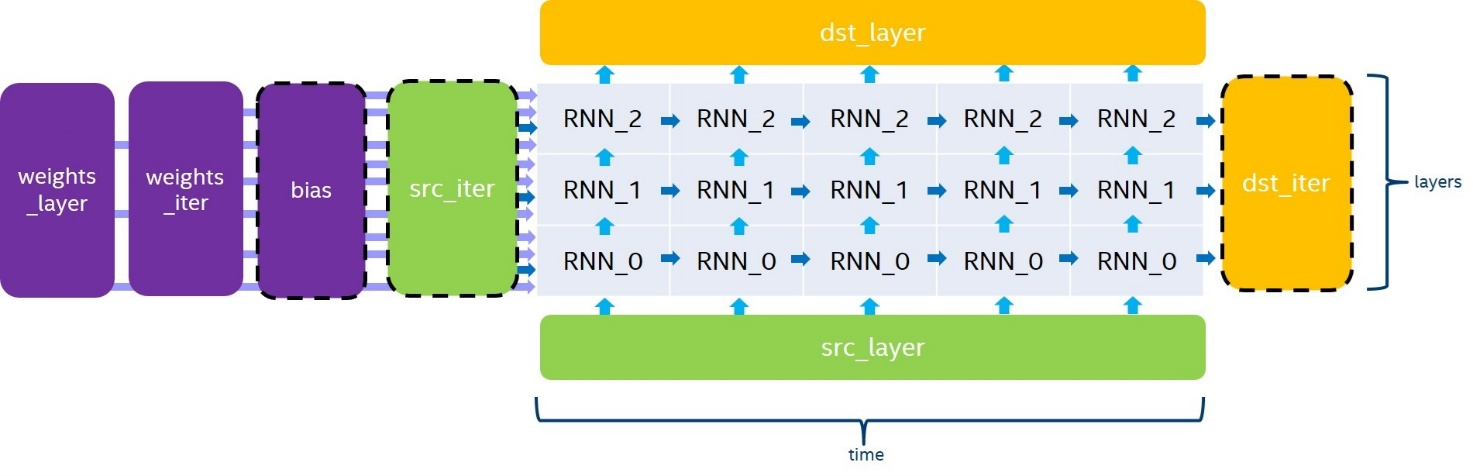
RNN プリミティブは 4 方向の評価モードをサポートします。
left2rightは、入力データのタイムスタンプを昇順で処理します。right2leftは、入力データのタイムスタンプを降順で処理します。bidirectional_concatは、left2rightとright2leftのすべてのスタックレイヤーを個別に処理し、チャネル次元で出力をdst_layerに連結します。bidirectional_sumは、left2rightとright2leftからすべてのスタックレイヤーを個別に処理して、2 つの出力をdst_layerに累積します。
RNN プリミティブは、src_layer、src_iter、dst_layer、および dst_iter に対して異なるチャネルの引き渡しをサポートしていますが、次元の一貫性を保つため、次の条件を満たす必要があります。
channels (dst_layer)= channels (dst_iter)T>1の場合、channels (src_iter)= channels (dst_iter)L>1の場合、channels (src_layer)= channels (dst_layer)bidirectional_concat方向を使用する場合、channels (dst_layer)=2∗channels (dst_iter)
アンロールされたリカレントセルのスタックを実行する一般的な数式は、前のレイヤーの現在の反復 (ht,l−1 および ct,l−1) と、現在のレイヤーの前の反復 (ht−1,l) によって異なります。非 LSTM セルの正確な式は次のとおりです。
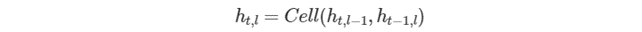
ここで、t、l は、タイムスタンプのインデックスと処理中のセルのレイヤーです。
そして、LSTM セルの式は次のようになります。
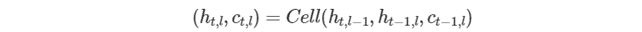
ここで、t、l は、タイムスタンプのインデックスと処理中のセルのレイヤーです。
セル関数
RNN API は 6 つセル関数を提供します。
- Vanilla RNN: 単一ゲートのリカレントセル
- LSTM: 4 ゲートの長短期間のメモリーセル
- GRU: 3 ゲートのリカレント・ユニット・セル
- Linear-before-reset GRU (リセット前の線形 GRU): リセットゲートの前に線形レイヤーを持つ 3 ゲートのリカレント・ユニット・セル
- AUGRU: アテンション更新ゲートを備えた 3 ゲートのゲートリカレント・ユニット・セル
- Linear-before-reset AUGRU (リセット前の線形 GRU): リセットゲートとアテンション更新ゲートの前に線形レイヤーを持つ 3 ゲートのリカレント・ユニット・セル
Vanilla RNN
次の例のように、dnnl::vanilla_rnn_forward::primitive_desc または dnnl::vanilla_rnn_forward::primitive_desc で初期化されたシングルゲート・リカレント・セル。
auto vanilla_rnn_pd =
dnnl::vanilla_rnn_forward::primitive_desc(engine, aprop,
activation, direction, src_layer_desc, src_iter_desc,
weights_layer_desc, weights_iter_desc, bias_desc,
dst_layer_desc, dst_iter_desc, attr);
Vanilla RNN セルは、ReLU、Tanh、および Sigmoid 活性化関数をサポートする必要があります。次の式は、前方パスに対して Vanilla RNN セルで実行される数学操作を定義しています。
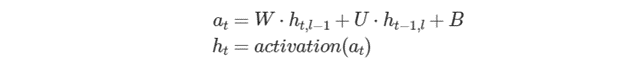
LSTM
LSTM (または Vanilla LSTM)
次の例のように、dnnl::vanilla_rnn_forward::primitive_desc または dnnl::vanilla_rnn_forward::primitive_desc で初期化された 4 ゲートの長短期メモリー・リカレント・セル。
auto lstm_pd = dnnl::lstm_forward::primitive_desc(engine, aprop,
direction, src_layer_desc, src_iter_h_desc, src_iter_c_desc,
weights_layer_desc, weights_iter_desc, bias_desc,
dst_layer_desc, dst_iter_h_desc, dst_iter_c_desc, attr);
ゲート数に応じた次元を持つすべてのテンソルで、ゲートの順番が暗黙的に i、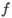 、
、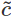 、
、o である必要があることに注意してください。次の式は、これらのゲートと前方パスの出力を数学的に説明するものです。
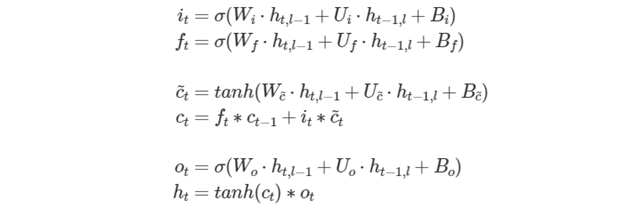
ここで、W∗ は weights_layer に、U∗ は weights_iter に、B∗ は bias に格納されます。
注: 次元の一貫性を保つため、channels(src_iter_c) = channels(dst_iter_c) = channels(dst_iter) でなければならないことに注意してください。
ピープホールがある LSTM
次の例のように、dnnl::vanilla_rnn_forward::primitive_desc または dnnl::vanilla_rnn_forward::primitive_desc で初期化されたピープホールがある 4 ゲートの長短期メモリー・リカレント・セル。
auto lstm_pd = dnnl::lstm_forward::primitive_desc(engine, aprop,
direction, src_layer_desc, src_iter_h_desc, src_iter_c_desc,
weights_layer_desc, weights_iter_desc, weights_peephole_desc,
bias_desc, dst_layer_desc, dst_iter_h_desc, dst_iter_c_desc,
attr);
Vanilla LSTM と同様に、ゲートの順番が i、、、o であることが暗黙的に要求されます。ピーホール重みの場合、ゲートの順番は math:i、、o です。次の式は、これらのゲートと前方パスの出力を数学的に説明したものです。
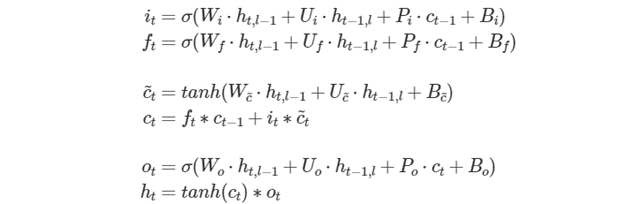
ここで、P∗ は weights_peephole に格納され、そのほかのパラメーターは Vanilla LSTM と同じです。
注: 操作記述子コンストラクターに渡される weights_peephole_desc がゼロメモリー記述子である場合、プリミティブは投影がない LSTM プリミティブと同じように動作します。
投影付き LSTM
次の例のように、dnnl::vanilla_rnn_forward::primitive_desc または dnnl::vanilla_rnn_forward::primitive_desc で初期化された投射がある 4 ゲートの長短期メモリー・リカレント・セル。
auto lstm_pd = dnnl::lstm_forward::primitive_desc(engine, aprop,
direction, src_layer_desc, src_iter_h_desc, src_iter_c_desc,
weights_layer_desc, weights_iter_desc, weights_peephole_desc,
weights_projection_desc, bias_desc, dst_layer_desc,
dst_iter_h_desc, dst_iter_c_desc, attr);
Vanilla LSTM と同様に、ゲート依存の次元を持つすべてのテンソルのゲートの順番は、暗黙的に i、、、o である必要があります。次の式は、これらのゲートと順方向パス出力の数学的関係を示しています (簡単にするため、ピープホールがない LSM を示します)。
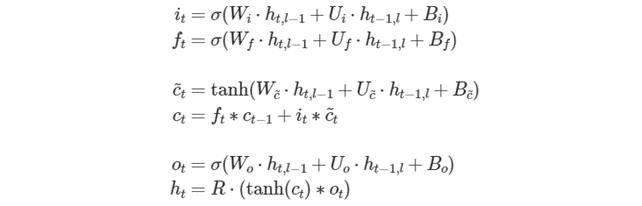
ここで、R は weights_projection に格納され、そのほかのパラメーターは Vanilla LSTM と同じです。
注: 操作記述子コンストラクターに渡される weights_projection_desc がゼロメモリー記述子である場合、プリミティブは投影がない LSTM プリミティブと同じように動作します。
GRU
次の例のように、dnnl::vanilla_rnn_forward::primitive_desc または dnnl::vanilla_rnn_forward::primitive_desc で初期化された 3 ゲートのゲート・リカレント・ユニット・セル。
auto gru_pd = dnnl::gru_forward::primitive_desc(engine, aprop,
direction, src_layer_desc, src_iter_desc, weights_layer_desc,
weights_iter_desc, bias_desc, dst_layer_desc, dst_iter_desc,
attr);
ゲート数に対応した次元を持つすべてのテンソルでは、ゲートの順番が math:u、r、o であることが暗黙的に要求されることに注意してください。次の式は、これらのゲートの数学的定義を示します。
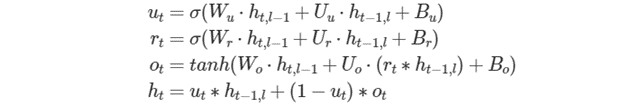
ここで、W∗ は weights_layer に、U∗ は weights_iter に、B∗ は bias に格納されます。
注: ht を計算する際に ut を (1−ut) に置き換える必要がある場合、Wu、Uu、Bu に −1 を乗算することでこれを実現できます。これは、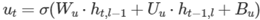 および であるため可能です。
および であるため可能です。
Linear-Before-Reset GRU (リセット前の線形 GRU)
リセットゲートの前に線形レイヤーが適用された 3 ゲートのゲート・リカレント・ユニット・セル。次の例のように、dnnl::vanilla_rnn_forward::primitive_desc または dnnl::vanilla_rnn_forward::primitive_desc で初期化されます。
auto lbr_gru_pd = dnnl::lbr_gru_forward::primitive_desc(engine,
aprop, direction, src_layer_desc, src_iter_desc,
weights_layer_desc, weights_iter_desc, bias_desc,
dst_layer_desc, dst_iter_desc, attr);
次の式は、Linear-Before-Reset GRU (リセット前の線形 GRU) セルの数学的な動作を示します。
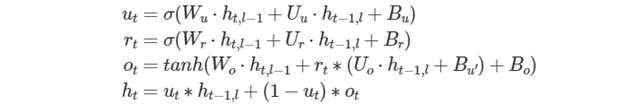
bias を除き、ゲート数に対応する次元を持つすべてのテンソルは、ゲートの順番が u、r、o であることが暗黙的に要求されることに注意してください。bias テンソルの場合、u、r、o、u′ であることが暗黙的に要求されます。
注: ht を計算する際に ut を (1−ut) に置き換える必要がある場合、Wu、Uu、Bu に −1 を乗算することでこれを実現できます。これは、 および であるため可能です。
AUGRU
次の例のように、dnnl::augru_forward::primitive_desc または dnnl::augru_backward::primitive_desc で初期化された 3 ゲートのゲート・リカレント・ユニット・セル。
auto augru_pd = dnnl::augru_forward::primitive_desc(engine, aprop,
direction, src_layer_desc, src_iter_desc, attention_desc,
weights_layer_desc, weights_iter_desc, bias_desc,
dst_layer_desc, dst_iter_desc, attr);
ゲート数に応じた次元を持つすべてのテンソルで、ゲートの順番が暗黙的に u、r、o である必要があることに注意してください。次の式は、これらのゲートと前方パスの出力を数学的に説明するものです。
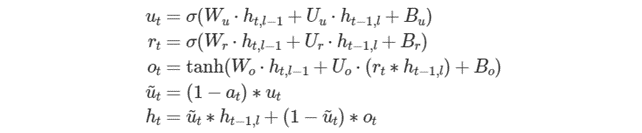
ここで、W∗ は weights_layer に、U∗ は weights_iter に、B∗ は bias に格納されます。
Linear-Before-Reset AUGRU (リセット前の線形 AUGRU)
リセットゲートの前に線形レイヤーが適用された 3 ゲートのゲート・リカレント・ユニット・セル。次の例のように、dnnl::lbr_augru_forward::primitive_desc または dnnl::lbr_augru_backward::primitive_desc で初期化されます。
auto lbr_augru_pd =
dnnl::lbr_augru_forward::primitive_desc(engine, aprop,
direction, src_layer_desc, src_iter_desc, attention_desc,
weights_layer_desc, weights_iter_desc, bias_desc,
dst_layer_desc, dst_iter_desc, attr);
次の式は、Linear-Before-Reset GRU (リセット前の線形 AUGRU) セルの数学的な動作を示します。
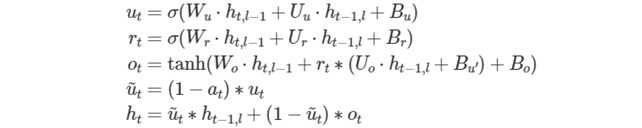
bias を除き、ゲート数に対応する次元を持つすべてのテンソルは、ゲートの順番が u、r、o であることが暗黙的に要求されることに注意してください。bias テンソルの場合、u、r、o、u′ であることが暗黙的に要求されます。
実行引数
実行時に入力と出力は、次の表で示す実行引数インデックスにマップする必要があります。

操作の詳細
N/A
サポートされるデータタイプ
次の表に、それぞれの入力および出力メモリー・オブジェクトの RNN プリミティブでサポートする必要があるデータタイプの組み合わせを示します。
注: この節では、可読性のためデータタイプの名称を短縮しています。例えば、dnnl::memory::data_type::f32 は f32 に短縮されます。

- LSTM およびピープホール STM セルでは、セル状態データタイプは常に f32 です。
- 逆伝播のすべての
diff_*テンソルは f32 です。 - 投影付き LSTM はまだ定義されていません。
データ表現
oneDNN プログラミング・モデルでは、RNN プリミティブはプレースホルダー・メモリー形式 #dnnl::memory::format_tag::any (any に短縮) をサポートし、プリミティブのパラメーターに基づいてデータと重みメモリー・オブジェクト形式を定義できます。
次の表は、RNN プリミティブでサポートされるデータレイアウトを示します。
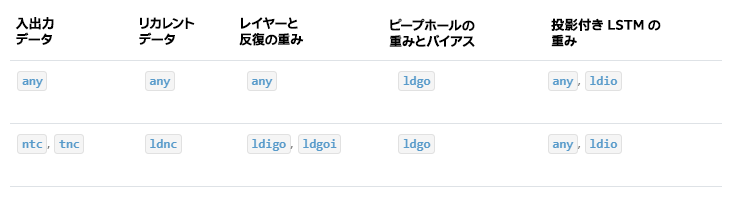
RNN プリミティブは、明示的に指定されたメモリー形式によって作成できますが、パフォーマンスは最適ではない可能性があります。any を使用する場合、最初に RNN プリミティブ記述子を作成してから、実際のデータと重みメモリー・オブジェクト形式を照会する必要があります。
注: RNN プリミティブは、パディングされたテンソルとビューをサポートする必要があります。したがって、2 つのメモリー記述子が同じデータレイアウトを共有していても、それらは異なる可能性があります。
post-ops と属性
現在、post-ops と属性は、LSTM の int8 バリアントでのみ使用されます。
API
API については、こちら (英語) をご覧ください。
法務上の注意書き
The content of this oneAPI Specification is licensed under the Creative Commons Attribution 4.0 International License (英語). Unless stated otherwise, the sample code examples in this document are released to you under the MIT license (英語).
This specification is a continuation of Intel’s decades-long history of working with standards groups and industry/academia initiatives such as The Khronos Group*, to create and define specifications in an open and fair process to achieve interoperability and interchangeability. oneAPI is intended to be an open specification and we encourage you to help us make it better. Your feedback is optional, but to enable Intel to incorporate any feedback you may provide to this specification, and to further upstream your feedback to other standards bodies, including The Khronos Group SYCL* specification, please submit your feedback under the terms and conditions below. Any contribution of your feedback to the oneAPI Specification does not prohibit you from also contributing your feedback directly to other standard bodies, including The Khronos Group under their respective submission policies.
By opening an issue, providing feedback, or otherwise contributing to the specification, you agree that Intel will be free to use, disclose, reproduce, modify, license, or otherwise distribute your feedback at its sole discretion without any obligations or restrictions of any kind, including without limitation, intellectual property rights or licensing obligations.
This document contains information on products, services and/or processes in development. All information provided here is subject to change without notice.
© Intel Corporation. Intel、インテル、Intel ロゴ、その他のインテルの名称やロゴは、Intel Corporation またはその子会社の商標です。
* その他の社名、製品名などは、一般に各社の表示、商標または登録商標です。
