

この記事は、https://www.oneapi.io/spec/ で 2023年9月14日に公開された『oneAPI 1.3 Provisional Specification Rev. 1』 (HTML、PDF) をベースにしています。原文は2000 ページ近くあり、翻訳の時間とリソースも限られるため、全文翻訳ではなく、記事形式で区切った仕様とその解説を提供することにしました。
この回では、『oneAPI 1.3 Provisional Specification Rev. 1』の「Software Architecture」の節を取り上げています。
ソフトウェア・アーキテクチャー
oneAPI は、さまざまなデータ並列アクセラレーター向けに共通のプログラミング・インターフェイスを提供します (以下の図を参照)。プログラマーは、API プログラミングとダイレクト・プログラミングの両方に SYCL* を利用します。oneAPI プラットフォームの機能は、システム・ソフトウェアに oneAPI デバイスの一般抽象化を提供するレベルゼロ・インターフェイスによって決定されます。
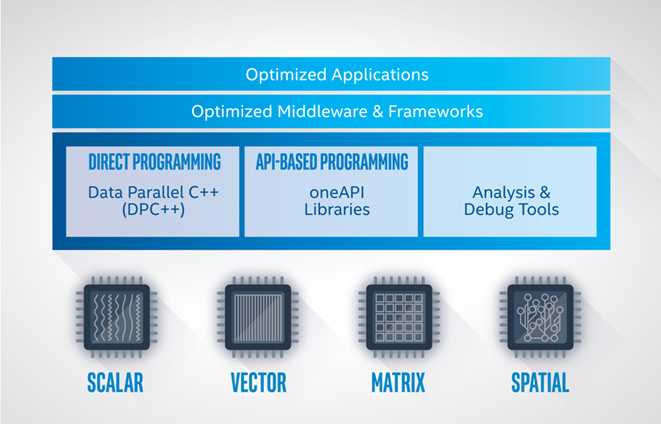
oneAPI プラットフォーム
oneAPI プラットフォームは、ホストとデバイスのコレクションで構成されます。ホストは通常マルチコア CPU であり、デバイスは 1 つ以上の GPU、FPGA、またはその他のアクセラレーターです。ホストとして機能するプロセッサーは、ソフトウェアによってターゲットデバイスとすることもできます。
各デバイスには関連付けられたコマンドキューがあります。oneAPI を採用するアプリケーションは、標準 C++ の実行セマンティクスに従ってホスト上で実行されます。関数オブジェクトをデバイス上で実行するには、アプリケーションは関数オブジェクトを含むコマンドグループをデバイスのキューに送信します。関数オブジェクトには、関連する変数と関数定義が含まれます。キューに送信された関数オブジェクトは、データ並列カーネルまたは単にカーネルと呼ばれます。
ホストで実行されるアプリケーションとデバイスで実行される関数は、メモリーを介して通信します。oneAPI は、デバイスの機能に応じてプラットフォーム全体でメモリーを共有するいくつかのメカニズムを定義しています。
| メモリー共有メカニズム | 説明 |
|---|---|
| バッファー・オブジェクト | アプリケーションは、デバイスにデータを渡すためバッファー・オブジェクトを作成できます。バッファーはデータ配列です。
コマンドグループは、デバイスの呼び出しでアクセスされるバッファーを特定するアクセサー・オブジェクトを定義します。 oneAPI ランタイムは、デバイスで実行される関数がバッファー内のデータにアクセスできるようにします。 バッファーアクセサーのメカニズムは、すべての oneAPI プラットフォームで利用可能です。 |
| 統合アドレッシング | 統合アドレッシングは、ホストとすべてのデバイスが統一されたアドレス空間を共有することを保証します。統合アドレス空間のポインター値は、常にメモリー上の同じ場所を指します。 |
| 統合共有メモリー | 統合共有メモリーを使用すると、バッファーやアクセサーを使用することなくポインターを介してデータを共有できます。
使用するデバイスの機能に応じて、この機能にはいくつかのレベルのサポートが提供されます。 |
スケジューラーは、コマンドグループをデバイスで実行するタイミングを決定します。コマンドグループを実行する準備ができたことを判断するため、次のメカニズムが採用されています。
バッファーアクセサー方式を使用する場合、バッファーが定義され必要に応じてデバイスにコピーされると、コマンドグループの準備が整います。
デバイスで順序付けされたキューを使用する場合、キュー内の直前のコマンドグループが完了すると、次のコマンドグループの準備が整います。
統合共有メモリーを使用する場合、コマンドグループに関連するイベント・オブジェクトのセットを指定する必要があります。すべてのイベントが完了するとコマンドグループの準備が整います。
ホスト上のアプリケーションとデバイス上の関数は、実行を調整する機能を持つオブジェクトであるイベントを介して同期できます。バッファーアクセサーを使用する場合、アプリケーションとデバイスはホストアクセサー、バッファー・オブジェクトの破棄、またはより高度なメカニズムを使用して同期することもできます。
API プログラミングの例
API プログラミングでは、プログラマーがターゲットデバイスとメモリー通信方法を指定する必要があります。次の例では、oneMKL 行列乗算ルーチン (GEMM) を呼び出します。SYCL* で記述され、関係のないコードは省略されています。
GPU での計算を指定する gpu_selector で初期化されたキューを作成し、ホストで割り当てられたバッファーを保持するバッファーを定義します。標準の C++ の GEMM 呼び出しに、キューを指定するパラメーターを追加して、配列への参照配列を含むバッファー参照へ置き換えます。それ以外は、標準の GEMM C++ インターフェイスと同一です。
using namespace cl::sycl;
// ホストの配列を宣言
double *A = new double[M*N];
double *B = new double[N*P];
double *C = new double[M*P];
{
// gpu_selector でデバイスキューを初期化
queue q{gpu_selector()};
// ホストの配列にバインドされる行列の 1D バッファーを作成
buffer<double, 1> a{A, range<1>{M*N}};
buffer<double, 1> b{B, range<1>{N*P}};
buffer<double, 1> c{C, range<1>{M*P}};
mkl::transpose nT = mkl::transpose::nontrans;
// 構文
// void gemm(queue &exec_queue, transpose transa, transpose transb,
// int64_t m, int64_t n, int64_t k, T alpha,
// buffer<T,1> &a, int64_t lda,
// buffer<T,1> &b, int64_t ldb, T beta,
// buffer<T,1> &c, int64_t ldc);
// call gemm
mkl::blas::gemm(q, nT, nT, M, P, N, 1.0, a, M, b, N, 0.0, c, M);
}
// ブロックを終了すると、バッファーのデストラクターは結果を配列 C に書き戻します
ダイレクト・プログラミングの例
ダイレクト・プログラミングでは、API プログラミングと同様に、ターゲットデバイスとメモリー通信方法を指定します。さらに、計算を実行するコマンドグループを定義して送信する必要があります。次の例は、単純な並列行列乗算を示します。SYCL* で記述され、関係のないコードは省略されています。
コマンドグループを GPU で実行するのを指定するため、gpu_selector で初期化されたキューを作成し、ホストで割り当てられたバッファーを保持するバッファーを定義します。次に、コマンドグループをキューに送信して計算を実行します。コマンドグループは、配列 A と B を読み取り、C に書き込むアクセサーを定義します。次に、C++ ラムダ関数を記述して、行列乗算の 1 要素を計算する関数オブジェクトを作成します。関数オブジェクトを配列 A と B に対し並列に関数をマップする parallel_for へのパラメーターとして指定します。カーネルのスコープを離れると、C を保持するバッファー・オブジェクトのデストラクターがデータをホストの配列に書き戻します。
#include <CL/sycl.hpp>
using namespace sycl;
int main() {
// declare host arrays
double *Ahost = new double[M*N];
double *Bhost = new double[N*P];
double *Chost = new double[M*P];
{
// gpu_selector でデバイスキューを初期化
queue q{gpu_selector()};
// ホストの配列にバインドされる行列の 1D バッファーを作成
buffer<double, 2> a{Ahost, range<2>{M,N}};
buffer<double, 2> b{Bhost, range<2>{N,P}};
buffer<double, 2> c{Chost, range<2>{M,P}};
// 行列 c=a*b を計算するコマンドグループをキューに送信
q.submit([&](handler &h){
// A と B を読み取り、C に書き込み
auto A = a.get_access<access::mode::read>(h);
auto B = b.get_access<access::mode::read>(h);
auto C = c.get_access<access::mode::write>(h);
int WidthA = a.get_range()[1];
// カーネルを実行
h.parallel_for(range<2>{M, P},
[=](id<2> index){
int row = index[0];
int col = index[1];
// 配列 C の 1 つの要素の結果を計算
double sum = 0.0;
for (int i = 0; i < WidthA; i++) {
sum += A[row][i] * B[i][col];
}
C[index] = sum;
});
});
}
// ブロックを終了すると、バッファーのデストラクターは結果を配列 C に書き戻します
}
法務上の注意書き
The content of this oneAPI Specification is licensed under the Creative Commons Attribution 4.0 International License (英語). Unless stated otherwise, the sample code examples in this document are released to you under the MIT license (英語).
This specification is a continuation of Intel’s decades-long history of working with standards groups and industry/academia initiatives such as The Khronos Group*, to create and define specifications in an open and fair process to achieve interoperability and interchangeability. oneAPI is intended to be an open specification and we encourage you to help us make it better. Your feedback is optional, but to enable Intel to incorporate any feedback you may provide to this specification, and to further upstream your feedback to other standards bodies, including The Khronos Group SYCL* specification, please submit your feedback under the terms and conditions below. Any contribution of your feedback to the oneAPI Specification does not prohibit you from also contributing your feedback directly to other standard bodies, including The Khronos Group under their respective submission policies.
By opening an issue, providing feedback, or otherwise contributing to the specification, you agree that Intel will be free to use, disclose, reproduce, modify, license, or otherwise distribute your feedback at its sole discretion without any obligations or restrictions of any kind, including without limitation, intellectual property rights or licensing obligations.
This document contains information on products, services and/or processes in development. All information provided here is subject to change without notice.
© Intel Corporation. Intel、インテル、Intel ロゴ、その他のインテルの名称やロゴは、Intel Corporation またはその子会社の商標です。
* その他の社名、製品名などは、一般に各社の表示、商標または登録商標です。
