

この記事は、https://www.oneapi.io/spec/ で 2023年9月14日に公開された『oneAPI 1.3 Provisional Specification Rev. 1』 (HTML、PDF) をベースにしています。原文は2000 ページ近くあり、翻訳の時間とリソースも限られるため、全文翻訳ではなく、記事形式で区切った仕様とその解説を提供することにしました。
この回では、『oneAPI 1.3 Provisional Specification Rev. 1』の「oneDNN」の「Attributes」の節を取り上げています。
属性
プリミティブ記述子を作成する際に渡されるパラメーターは、操作の種類、伝播の種類、入力および出力テンソル記述子 (該当する場合はストライドなど)、およびプリミティブが実行されるエンジンなど、基本的な問題を指定します。
属性ではプリミティブの追加プロパティーを指定します。ユーザーは使用する前にそれらを作成し、対応するセッターで必要な内容を設定する必要があります。属性はプリミティブ記述子の作成中にコピーされるため、ユーザーは作成直後に属性を変更または破棄できます。
変更しない場合、属性は空のままにすることができ、これはデフォルト属性と同等となります。プリミティブ記述子のコンストラクターは、デフォルト・パラメーターとして空の属性を持っているため、必要な場合を除きユーザーは省略できます。
属性には、プリミティブの後に実行される計算である post-ops を含めることもできます。
- post-ops (英語)
スクラッチパッド・モード
一部のプリミティブには、計算の実行中に一時バッファーを必要とするものがあります。例えば、システムのすべてのコアを利用するのに十分な独立したワークがない操作では、リダクション次元 (GEMM 表記の K 次元) で並列化を行う場合があります。この場合、異なるスレッドがプライベートな一時バッファーで部分計算を行い、プライベートな結果がマージされ最終的な結果が生成されます。もう 1 つの例は、行列乗算 (GEMM) による畳み込みの実装です。GEMM を呼び出す前に、im2col 操作を使用してソース活性化を変換する必要があります。変換結果は一時バッファーに格納され、GEMM の入力として使用されます。
これら両方でプリミティブ計算が完了すると、一時バッファーは不要になります。oneDNN では、このようなメモリーバッファーをスクラッチパッドと呼んでいます。
どちらのタイプの実装でも、独立したタスクが少ない場合に備えて、リダクション用の追加スペースが必要になることがあります。im2col 変換に必要なメモリー容量は、ソースイメージのサイズに重みの空間サイズを掛けたものに比例します。リダクション・バッファーのサイズは、縮小するテンソルサイズ (例えば、重み逆方法の場合は diff_weights) にリダクション・グループ内のスレッド数 (上限はスレッドの総数) を掛けたものに比例します。
対照的に、他のプリミティブでは余分なスペースをほとんど使用しません。例えば、dnnl::sum プリミティブの実装の 1 つでは、すべての入力配列データへのポインターを格納する場合にのみ、一時スペースを必要とします (つまり、スクラッチパッドのサイズは n * sizeof(void *) です。n は被加数の数)。
oneDNN はスクラッチパッドを操作する 2 つのモードをサポートします。
enum class dnnl::scratchpad_mode
スクラッチパッド・モード。
値:
enumerator library
ライブラリーはスクラッチパッドの割り当てを管理します。この仕様で定義されていないメカニズムを使用して構成可能な実装固有のポリシーが複数存在することがあります。
enumerator user
ユーザーは、スクラッチパッド・メモリーを照会して、プリミティブに提供することでスクラッチパッドの割り当てを管理します。このモードは、スクラッチパッド・バッファーが 2 つのプリミティブの実行によって同時に使用されない限りスレッドセーフです。
スクラッチパッド・モードは、dnnl::primitive_attr::set_scratchpad_mode() プリミティブ属性を介して制御されます。
ユーザーがスクラッチパッド・メモリーをプリミティブに提供する場合、このメモリーはプリミティブが使用するエンジンと同じエンジンで作成する必要があります。
すべてのプリミティブは両方のスクラッチパッド・モードをサポートします。
注: プリミティブは、デフォルトではスレッドセーフではありません。スクラッチパッドの実行をスレッドセーフにする唯一の方法は、dnnl::scratchpad_mode::user モードを使用して同時に実行される 2 つのプリミティブに同じスクラッチパッド・メモリーを渡さないことです。
例
スクラッチパッドを管理するライブラリー
上記に示すように、これはデフォルトの動作です。スクラッチパッドによりプリミティブが消費するメモリー量をユーザーが照会する方法を示します。
// デフォルトの attr を使用し、ライブラリーはスクラッチパッドを割り当てます
dnnl::primitive::primitive_desc op_pd(params, /* 他の引数 */);
// スクラッチパッドによりプリミティブが消費するメモリー量を出力します
std::cout << "primitive will use "
<< op_pd.query_s64(dnnl::query::memory_consumption_s64)
<< " bytes" << std::endl;
// この場合、スクラッチパッドは内部にあるため、ユーザーが表示するスクラッチパッド・
// メモリー記述子は空である必要があります
auto zero_md = dnnl::memory::desc();
ユーザー管理のスクラッチパッド
// 空 (デフォルト) の属性を作成
dnnl::primitive_attr attr;
// デフォルトのスクラッチパッド・モードは `library`
assert(attr.get_scratchpad_mode() == dnnl::scratchpad_mode::library);
// スクラッチパッド・モードを `user` に設定
attr.set_scratchpad_mode(dnnl::scratchpad_mode::user);
// カスタム属性でプリミティブ記述子を作成
dnnl::primitive::primitive_desc op_pd(op_d, attr, engine);
// スクラッチパッド・メモリー記述子を照会
dnnl::memory::desc scratchpad_md = op_pd.scratchpad_desc();
// この構成ではプリミティブはメモリーを消費しないことに注意
assert(op_pd.query_s64(dnnl::query::memory_consumption_s64) == 0);
// プリミティブを作成
dnnl::primitive prim(op_pd);
// ... コードを記述 ...
// スクラッチパッド・メモリーを作成
// 注: プリミティブにスクラッチパッドが必要ない場合、
// scratchpad_md.get_size() は 0 を返します。
// この場合、scratchpad_ptr == nullptr を使用しても問題ありません。
void *scratchpad_ptr = user_memory_manager::allocate(scratchpad_md.get_size());
// 注: このエンジンは、複数のプリミティブのエンジンである必要があります
dnnl::memory scratchpad(scratchpad_md, engine, scratchpad_ptr);
// プリミティブへスクラッチパッド・メモリーを渡します
prim.execute(stream, { /* other arguments */,
{DNNL_ARG_SCRATCHPAD, scratchpad}});
量子化
プリミティブは、量子化を必要とする低精度の計算をサポートする場合があります。このプロセスは、「量子化モデル」(英語) で詳しく説明します。
量子化属性 (スケールとゼロポイント)
oneDNN は、プリミティブの引数で指定された量子化パラメーターを設定するため、dnnl::primitive_attr::set_scales_mask() と dnnl::primitive_attr::set_zero_points_mask() を提供します。
ソース (と重み) テンソルが int8 データタイプでない場合、プリミティブは出力スケールをサポートしないことがあります。つまり、単精度浮動小数点データタイプで動作する畳み込みは、出力結果がスケールしない場合があるということです。
量子化パラメーターのブロードキャスト・セマンティクスは、dnnl::primitive_attr::set_scales_mask() と dnnl::primitive_attr::set_zero_points_mask() メソッドに渡されるマスクを介して処理されます。例えば、プリミティブのデスティネーションが D0×...×Dn−1 テンソルで、di 次元 (0≤di<n) ごとにスケールを必要とする場合、次のようになります。
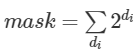
スケール数は以下でなければなりません。

マスクはプリミティブ作成時に属性を設定する必要があり、実際のスケールとゼロポイントは引数としてプリミティブ関数に渡されます。
量子化パラメーターは、単精度浮動小数点データタイプ (dnnl::memory::data_type::f32) が適用されます。保存する前に、必要に応じて結果は飽和したデスティネーションのデータタイプに変換されます。丸めはハードウェアの設定に従って行われます。
post-ops (英語) を使用する場合、同じ dnnl::primitive_attr::set_scales_mask() と
dnnl::primitive_attr::set_zero_points_mask() を使用して、量子化パラメーターを設置の post-ops 引数に渡します。
例 1: 出力チャネルごとのスケーリングによる重みの量子化
// 重み次元
const int OC, IC, KH, KW;
// プレーン形式のオリジナルの f32 重み
dnnl::memory::desc wei_plain_f32_md(
{OC, IC, KH, KW}, // dims
dnnl::memory::data_type::f32, // オリジナルデータは f32
dnnl::memory::format_tag::hwigo // プレーンメモリー形式
);
// 量子化された重みのスケーリング係数
// 各出力チャネルで固有のスケール。
std::vector<float> wei_scales(OC) = { /* 値 */ };
dnnl::memory();
// int8 畳み込みプリミティブ記述子
dnnl::convolution_forward::primitive_desc conv_pd(/* 次の例を参照 */);
// 畳み込み重みメモリー記述子を照会
dnnl::memory::desc wei_conv_s8_md = conv_pd.weights_desc();
// リオーダーの属性を準備
dnnl::primitive_attr attr;
const int quantization_mask = 0
| (1 << 0); // dim #0 の OC 次元ごとのスケール
attr.set_scales_mask(DNNL_ARG_DST, quantization_mask);
// 実行するリオーダーを作成:
// wei_s8(oc, ic, kh, kw) <- wei_f32(oc, ic, kh, kw) / scale(oc)
// データ形式の変換を含む
auto wei_reorder_pd = dnnl::reorder::primitive_desc(
wei_plain_f32_md, engine, // ソース
wei_conv_s8_md, engine, // デスティネーション
attr);
auto wei_reorder = dnnl::reorder(wei_reorder_pd);
例 2: 出力チャネルごとの量子化を使用したグループによる畳み込み
この例は、前述の例 (理想的には最初の例) を補完するものです。出力ごとのチャネルのスケーリングにより、int8 畳み込みを行うことを想定します。
const float src_scale; // src_f32[:] = src_scale * src_s8[:]
const float dst_scale; // dst_f32[:] = dst_scale * dst_s8[:]
// 量子化された重みのスケーリング係数 (上記で宣言)
// 各グループと出力チャネルで固有のスケール
std::vector<float> wei_scales(OC) = {...};
// 畳み込みの src、weights、および dst メモリー記述子
// メモリー形式タグ = any を使用して、畳み込み実装が適切な
// メモリー形式を選択できるようにします
dnnl::memory::desc src_conv_s8_any_md(
{BATCH, IC, IH, IW}, // dims
dnnl::memory::data_type::s8, // オリジナルデータは s8
dnnl::memory::format_tag::any // 畳み込みに選択させる
);
dnnl::memory::desc wei_conv_s8_any_md(
{OC, IC, KH, KW}, // dims
dnnl::memory::data_type::s8, // オリジナルデータは s8
dnnl::memory::format_tag::any // 畳み込みに選択させる
);
dnnl::memory::desc dst_conv_s8_any_md(...); // 同上
// 畳み込みの属性を準備
dnnl::primitive_attr attr;
const int data_mask = 0; // ソースとデスティネーションのテンソルごとのスケールとゼロポイント
const int wei_mask = 0
| (1 << 1); // OC 次元ごとのスケール (重みテンソルの dim #0)
// ( OC, IC, KH, KW)
// 0 1 2 3
attr.set_scales_mask(DNNL_ARG_SRC, data_mask);
attr.set_zero_points_mask(DNNL_ARG_SRC, data_mask);
attr.set_scales_mask(DNNL_ARG_WEIGHTS, wei_mask);
attr.set_scales_mask(DNNL_ARG_DST, data_mask);
attr.set_zero_points_mask(DNNL_ARG_DST, data_mask);
// 畳み込みプリミティブの記述子を作成
auto conv_pd = dnnl::convolution_forward::primitive_desc(
dnnl::prop_kind::forward_inference,
dnnl::algorithm::convolution_direct,
src_conv_s8_any_md, // 重要なことは
wei_conv_s8_any_md, // s8 で計算を行うように
dst_conv_s8_any_md, // 指定すること
strides, padding_l, padding_r,
dnnl::padding_kind::zero
attr); // 属性は量子化フローを表す
暗黙的なダウン・コンバージョンと浮動小数点演算モード
oneDNN は、プリミティブの実行中に fp32 から精度の低いデータタイプへの暗黙的なダウン・コンバージョンを可能にする dnnl::primitive_attr::set_fpmath_mode() を提供します。一部のアプリケーションでは、精度に影響を与えることなく計算を高速化できます。
dnnl::primitive_attr::set_fpmath_mode() プリミティブ属性は、特定のプリミティブに対して許される暗黙的なダウン・コンバージョンを指定します。現在、f32 より低精度のデータタイプ (f16、bf16 または tf32) へのダウン・コンバージョンのみが許されます。さらに、ダウン・コンバージョンは計算中にのみ許され、ストレージのデータタイプ (f32 のままである必要があります) には影響しません。
dnnl::primitive_attr::set_fpmath_mode() プリミティブ属性は、次の 3 種類の値を受け取ることができます。
strict モードでは、ダウン・コンバージョンが無効になります (デフォルト)。
any モードでは、f32 から低精度の浮動小数点データタイプ (f16、bf16 または tf32) へのすべての変換が可能です。
f32 から指定されるデータタイプと同じ精度以上のデータタイプ (少なくとも同一の指数と仮数ビット) へのダウン・コンバージョンのみを許可する特定のデータタイプ (f16、bf16 または tf32)。
この属性のデフォルトは strict です。ただし、グローバル関数や環境変数を公開して、デフォルト値を変更することは許されます。
プリミティブ計算のデータタイプが整数である場合、この属性は無視されます。
エラー処理に関連する属性
属性は対応するプリミティブ記述子とは別に作成されるため、整合性チェックは遅延します。ユーザーは必要な構成の属性を適切に設定できます。ただし、設定した属性でプリミティブ記述子を作成しようとすると、その構成をサポートするプリミティブ実装が存在しないことがあります。その場合、ライブラリーは dnnl::error 例外をスローします。
API
API については、こちら (英語) をご覧ください。
法務上の注意書き
The content of this oneAPI Specification is licensed under the Creative Commons Attribution 4.0 International License (英語). Unless stated otherwise, the sample code examples in this document are released to you under the MIT license (英語).
This specification is a continuation of Intel’s decades-long history of working with standards groups and industry/academia initiatives such as The Khronos Group*, to create and define specifications in an open and fair process to achieve interoperability and interchangeability. oneAPI is intended to be an open specification and we encourage you to help us make it better. Your feedback is optional, but to enable Intel to incorporate any feedback you may provide to this specification, and to further upstream your feedback to other standards bodies, including The Khronos Group SYCL* specification, please submit your feedback under the terms and conditions below. Any contribution of your feedback to the oneAPI Specification does not prohibit you from also contributing your feedback directly to other standard bodies, including The Khronos Group under their respective submission policies.
By opening an issue, providing feedback, or otherwise contributing to the specification, you agree that Intel will be free to use, disclose, reproduce, modify, license, or otherwise distribute your feedback at its sole discretion without any obligations or restrictions of any kind, including without limitation, intellectual property rights or licensing obligations.
This document contains information on products, services and/or processes in development. All information provided here is subject to change without notice.
© Intel Corporation. Intel、インテル、Intel ロゴ、その他のインテルの名称やロゴは、Intel Corporation またはその子会社の商標です。
* その他の社名、製品名などは、一般に各社の表示、商標または登録商標です。
