

この記事は、https://www.oneapi.io/spec/ で 2023年9月14日に公開された『oneAPI 1.3 Provisional Specification Rev. 1』 (HTML、PDF) をベースにしています。原文は2000 ページ近くあり、翻訳の時間とリソースも限られるため、全文翻訳ではなく、記事形式で区切った仕様とその解説を提供することにしました。
この回では、『oneAPI 1.3 Provisional Specification Rev. 1』の「oneDNN」の「Memory」の節を取り上げています。
メモリー
oneDNN のメモリーには 2 つのレベルの抽象化があります。
メモリー・オブジェクト – エンジン固有のオブジェクトは、メモリー記述子とストレージの組み合わせです。
oneDNN は、テンソルの次元を表わすため次のエイリアスを定義します。
using dnnl::memory::dim = int64_t
次元サイズとインデックスを表す整数型。
using dnnl::memory::dims = std::vector<dim>
次元のベクトル。実装ではベクトル長を自由に制限できます。
このセクションは次の節で構成されます。
メモリー形式
oneDNN メモリー形式では、多次元テンソルが 1 次元の線形メモリーアドレス空間に格納されます。また、oneDNN は従来の多次元配列に対応するプレーンと、完全に不透過な最適化された 2 種類のメモリー形式の種類を指定します。
プレーンメモリー形式
プレーンメモリー形式は、dimensions 配列と strides 配列を使用して多次元テンソルがメモリーにどのように配置されるか記述します。どちらのレングスもテンソルのランクに等しくなります。oneDNN では次元の順番が固定されており、プリミティブよって各種次元が正規の解釈を持つことができます。例えば、CNN プリミティブでは、活性化テンソルの順番は {N,C,...,D,H,W} です。ここで、N はミニバッチ (またはバッチサイズ)、C はチャネル、D、H および W はイメージの空間次元を表し、それぞれ depth、height、width に相当します。空間次元は、最も外側から最も内側の順序で省略できます。例えば、D が存在する場合 H を省略することはできず、また W も省略することはできません。プリミティブごとの正規解釈が文書化されています。これは、strides 配列が、異なる次元のメモリーに配置される順番を定義する重要な役割を持つことを意味します。さらに、strides は dimensions と一致している必要があります。
さらに正確にするには、T をランク n とし δ をソートする strides 配列の順列とする、つまり、すべての 0≤i,j<n では、δ(i)<δ(j) の場合、strides[i]≥strides[j] です。その場合、以下が成立する必要があります。
δ(i)=δ(j) の場合、すべての 0≤i,j<n に対して、strides[i]=strides[j]∗dimensions[j]。
0≤j<n で、0≤ij<dimensions[j] のような座標 (i0,…,in−1) を持つ場合、メモリー内のオフセットは次のように計算されます。
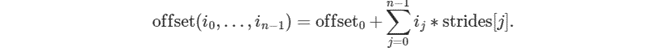
ここで、offset0 は親メモリーからのオフセットであり、dnnl::memory::desc::submemory_desc() を使用して作成されたサブメモリーのメモリー記述子に対してのみゼロ以外の値を持ちます。サブメモリーのメモリー記述子は、親メモリー記述子からストライドを継承します。これにより、インプレースの結合操作を表現できます。
例えば、M × N 行列 A (M 行 x N 列) を考えてみます。A が転置されて保存されるかにかかわりなく、dimensionsA={M, N} となります。ただし、転置されない場合、stridesA={LDA,1}、転置される場合 stridesA={1,LDA} となります。LDA は、A が転置されないと LDA≥N、転置されると LDA≥M になります。これはまた、A はメモリーに密に保存する必要がないことを示しています。
注: 上記の例は、oneDNN では行優先でデータが格納されていることを前提とすることを示しています。
コード例:
int M, N;
dnnl::memory::dims dims {M, N}; // 次元は常に同じです
// 非転置行列
dnnl::memory::dims strides_non_transposed {N, 1};
dnnl::memory::desc A_non_transposed {dims, dnnl::memory::data_type::f32,
strides_non_transposed};
// 転置行列
dnnl::memory::dims strides_transposed {1, M};
dnnl::memory::desc A_transposed {dims, dnnl::memory::data_type::f32,
strides_transposed};
形式タグ
strides に加えて、dnnl::memory::format_tag 列挙型の名前付き format tags を提供します。この型の列挙子は、密なプレーンレイアウトの strides の代わりに利用できます。
N 次元のメモリー形式の形式タグ名は、任意に並べ替え可能なアルファベットの最初の N 文字を使用します。この並べ替えにより、最大 6 次元のテンソル strides を計算できます。結果 strides には密ストレージを指定します。前述した命令法により次の同等性が成り立ちます。
δ(i)+1=δ(j) の場合、すべての 0≤i,j<n−1 に対して strides[i]=strides[j]∗dimensions[j]。
行列の例では、上記の非転置行列には dnnl::memory::format_tag::ab を使用し、転置行列には dnnl::memory::format_tag::ba を使用できます。
int M, N;
dnnl::memory::dims dims {M, N}; // 次元は常に同じです
// 非転置行列
dnnl::memory::desc A_non_transposed {dims, dnnl::memory::data_type::f32,
dnnl::memory::format_tag::ab};
// 転置行列
dnnl::memory::desc A_transposed {dims, dnnl::memory::data_type::f32,
dnnl::memory::format_tag::ba};
注: この節では、可読性のためメモリー形式のタグ名を省略しています。例えば、dnnl::memory::format_tag::abcd は abcd に省略されます。
また、抽象化形式タグ名以外に oneDNN ではいくつかのエイリアスも提供します。CNN と RNN の例を示します。
nchwはabcdのエイリアスです (前述の CNN 次元の正規順序付けを参照してください)。oihwはabcdのエイリアスです。nhwcはacdbのエイリアスです。tncはabcのエイリアスです。ldioはabcdのエイリアスです。ldioはabdcのエイリアスです。
最適化された形式 any
oneDNN がサポートする別種の形式は、strides または dimensions 配列で直接作成できない不透過な最適化されたメモリー形式です。最適化されたメモリー形式の記述子は、特定のプリミティブ記述子の作成時に any を渡すことでのみ作成できます。このプリミティブ記述子は、メモリー記述子を照会することができます。プレーンメモリー形式のデータは、計算前に最適化されたデータ形式のデータとして再配置する必要があります。再配置のコストは高いため、最適化されたメモリー形式は計算グラフを通して伝播する必要があります。
最適化された形式では、パディング、ブロッキング、およびその他のデータ変換により、特定のアーキテクチャーで最適なデータ配置を維持できます。これは、dnnl::memory::desc::permute_axes() や dnnl::memory::desc::submemory_desc() など典型的な操作が失敗する可能性があることを意味します。データを保存するメモリー容量を計算する際に次元サイズの積を使うことは適切ではありません。dnnl::memory::desc::get_size() を使用します。
メモリー形式伝播
メモリー形式の伝播は、oneDNN を適切に使用する上で理解すべき概念の 1 つです。
畳み込みと内積プリミティブは、入力または出力プレースホルダー・メモリー形式 any を使用して作成する際にメモリー形式を選択します。選択されるメモリー形式は、ハードウェアや畳み込みパラメーターなどの状況に依存します。プレースホルダー any メモリー形式を使用することは、それらが在るほとんどのトポロジーで最も計算集約的な操作であるため、畳み込みに推奨されます。
要素ごと、LRN、バッチ正規化などのプリミティブは、順伝播で前のレイヤーと同じメモリー形式を使用する必要があるため、複数の oneDNN プリミティブを介してメモリー形式を伝播します。これにはコストが発生する可能性があり、計算集約型のプリミティブが必要としない限り避けるべき再配置を排除できます。パフォーマンス上の理由から、このようなプリミティブの逆計算には、対応する順計算と一致するメモリー形式が必要となります。つまり、逆計算プリミティブを初期化するには、dnnl::memory::format_tag::any メモリー形式タグを使用する必要があります。
以下は、操作記述の初期化中にメモリー形式 any を使用する場合と、使用しない場合の簡単なサマリーです。
| プリミティブの種類 | 順伝播 | 逆伝播 | 伝播なし |
|---|---|---|---|
| 計算集約型: (逆) 畳み込み、行列乗算、内積、RNN | any を使用 |
any を使用 |
N/A |
| メモリー帯域幅の制限: プーリング、レイヤーとバッチの正規化、ローカル応答正規化、要素ごと、シャッフル、ソフトマックス | ソーステンソルには前のレイヤーのメモリー形式を使用し、デスティネーション・テンソルには any 形式を使用します |
勾配テンソルには any を使用し、データテンソルには実際のメモリー形式を使用します。 |
N/A |
| メモリー帯域幅の制限: 並べ替え、連結、合計、バイナリー | N/A | N/A | ソーステンソルには前のレイヤーのメモリー形式を使用し、デスティネーション・テンソルには any 形式を使用します |
トレーニング・ワークロードを実行する場合、順伝播と逆伝播の間に追加の形式同期が必要になります。これは、逆伝播を実装するプリミティブの記述子コンストラクター hint_pd 引数によって実現されます。
API
enum class dnnl::memory::format_tag
メモリー形式タグの仕様。
メモリー形式タグはさらに 2 つのカテゴリーに分類されます。
ドメインにとらわれない、つまり特定のプリミティブのテンソルの使い方に依存しない名前。この名前は、
aからfまでの文字によって論理次元を表し、次元がメモリーに配置される順番を示します。例えば、dnnl::memory::format_tag::abは 2 番目の論理次元 (bで示される) が最内である。つまりstride = 1であり、最初の論理次元 (a) が 2 番目の次元サイズと等しいストライドでメモリー内に配置されます。一方、dnnl::memory::format_tag::baは同じテンソルの転置バージョンであり、最も外側の次元 (a) が最も内側になります。ドメイン固有の名前で、CNN などの特定のドメイン・コンテキストでのみ意味を持ちます。これらの名前は、対応するドメインにとらわれないタグのエイリアスであり、利便性のため使用されます。例えば、
dnnl::memory::format_tag::ncは、2D CCN 活性化テンソルのメモリー形式を示します。ここで、チャネル次元は最内の次元であり、バッチ次元は最外の次元です。さらに、dnnl::memory::format_tag::ncはdnnl::memory::format_tag::abのエイリアスです。CNN プリミティブの場合、活性化テンソルの論理次元がバッチ、チャネル、空間の順になります。つまり、バッチは最初の論理次元 (a) に対応し、チャネルは 2 番目の次元 (b) に対応します。
次のドメイン固有表記は、メモリー形式タグに適用されます。
'n'はミニバッチの次元を示します。'c'はチャンネルの次元を示します。- 複数のチャンネル次元がある場合 (例えば畳み込み重みテンソル)、
'i'と'o'は、入力と出力チャンネルの次元を示します。 'g'は畳み込み重みのグループ次元を示します。'd'、'h'および'w'は、ぞれぞれ空間の深さ、高さ、そして幅を示します。
値については、こちら (英語) をご覧ください。
法務上の注意書き
The content of this oneAPI Specification is licensed under the Creative Commons Attribution 4.0 International License (英語). Unless stated otherwise, the sample code examples in this document are released to you under the MIT license (英語).
This specification is a continuation of Intel’s decades-long history of working with standards groups and industry/academia initiatives such as The Khronos Group*, to create and define specifications in an open and fair process to achieve interoperability and interchangeability. oneAPI is intended to be an open specification and we encourage you to help us make it better. Your feedback is optional, but to enable Intel to incorporate any feedback you may provide to this specification, and to further upstream your feedback to other standards bodies, including The Khronos Group SYCL* specification, please submit your feedback under the terms and conditions below. Any contribution of your feedback to the oneAPI Specification does not prohibit you from also contributing your feedback directly to other standard bodies, including The Khronos Group under their respective submission policies.
By opening an issue, providing feedback, or otherwise contributing to the specification, you agree that Intel will be free to use, disclose, reproduce, modify, license, or otherwise distribute your feedback at its sole discretion without any obligations or restrictions of any kind, including without limitation, intellectual property rights or licensing obligations.
This document contains information on products, services and/or processes in development. All information provided here is subject to change without notice.
© Intel Corporation. Intel、インテル、Intel ロゴ、その他のインテルの名称やロゴは、Intel Corporation またはその子会社の商標です。
* その他の社名、製品名などは、一般に各社の表示、商標または登録商標です。
