
この記事は、Medium の Intel Analytics Software で公開されている「You Don’t Have to Spend $800,000 to Compute PageRank」の日本語参考訳です。
大規模なグラフ・アナリティクスを行う最適な方法
私はベンチマークにはあまり興味がありませんが、グラフ・アナリティクスのベンチマークには一応注目しています。
また、ときどき、不正確で誤解を招くと思われるベンチマークや、一部しか語られていないベンチマークについて調査しています。
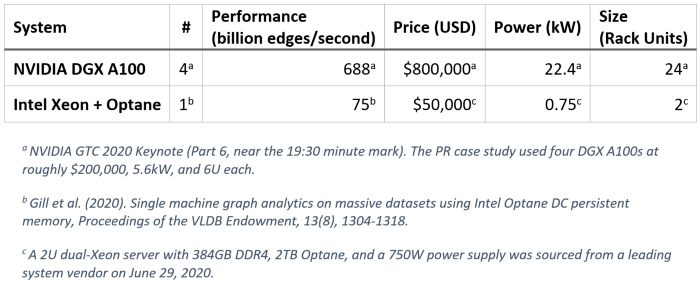
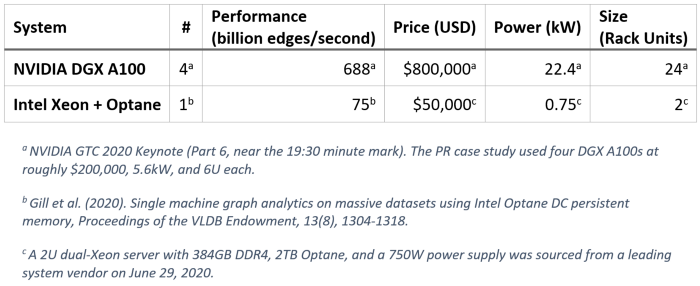
2020 年 5 月 14 日に行われた Jensen Huang 氏の NVIDIA* GTC 2020 基調講演を聴いていたところ、彼のパフォーマンスに関する主張の 1 つに目が留まりました。NVIDIA* GTC 2020 Keynote Part 6 (英語) の 19:30 あたりの大規模なグラフ・アナリティクスの説明で、DGX A100 ラックは 1,280 億エッジのウェブグラフの PageRank (PR) を 6,880億 エッジ/秒で計算できると主張しています。検証に利用可能な DGX A100 ラックはありませんが、もしこれが真実であるとすると、このグラフの PR を計算するため $800,000 も費やす必要があるでしょうか? 私はそうは思いませんが、皆さんが判断できるように、このベンチマークについて詳しく見てみましょう。
「インテル® Optane™ DC パーシステント・メモリーを使用した大規模データセットの単一マシン・グラフ・アナリティクス」 (英語) は、インテルの同僚と学術関係者によって発表された 1,280 億エッジのウェブグラフの PR 結果です。この記事は 2020 年 4 月に発表されましたが、GTC 基調講演の 1 年前の 2019 年 4 月に arXiv.org で公開されていたもの (英語) です。彼らは、2 基の第 2 世代インテル® Xeon® スケーラブル・プロセッサー 2.20GHz、384GB DDR4 メモリー、および 6TB インテル® Optane™ DC パーシステント・メモリーを搭載した単一の 2U サーバーで、750 億エッジ/秒を達成しています。このとき、6TB インテル® Optane™ DC パーシステント・メモリーのうち、2TB のみが使用されました。
「明示的なヒュージページの割り当てを評価し、インテル® Optane™ DC パーシステント・メモリー・モジュール (PMM) と DRAM の実験用にそれぞれ 2TB と 360GB を予約しました。」
グラフのロードにはこれで十分でした。ウェブのグラフが同一であることを確認できる十分なソース情報はありませんが、同じか、少なくとも非常に類似していることは間違いありません。
それぞれの PR 計算のシステム特性を比較すると、パフォーマンスだけではすべてを語れないことが明らかになります。以下の表は、2U インテル® Xeon® プロセッサー・ベースのサーバーが DGX A100 ラックの 6.3% の価格、3.3% の電力、8.3% のスペースで 10.9% のパフォーマンスを達成していることを示しています。つまり、インテル® Xeon® プロセッサー・ベースのサーバーのほうが、1 ドルあたりのパフォーマンスは 1.7 倍、1 ワット当たりのパフォーマンスは 3.3 倍、ラックユニットあたりのパフォーマンスは 1.3 倍優れています。
さらに、数あるグラフ・アナリティクス・アルゴリズムの中でも、PR は容易に並列化できるため、DGX A100 の紹介に選ばれたと考えられます。ほかのグラフ・アナリティクス・アルゴリズムは、効率良く並列化することが容易ではなく、PR のように大幅なスケーリングをもたらしません。DGX A100 で利用可能なほかのグラフ・アナリティクス・アルゴリズムのスケーラブルな並列実装があるかどうかも疑問です。一方、前述の 1 年前の論文では、同じ 128 エッジのウェブグラフで PR だけでなく、幅優先探索、媒介中心性、連結成分、k コア分解、単一ソース最短パスなど、ほかの多くの一般的なアルゴリズムの計算を実行しています。
PR のパフォーマンスだけが重要で、$800,000 の予算と 22-kW の電力、そして十分な冷却能力があるのであれば、DGX A100 ラックを使用してみてください。そうでない場合は、十分なメモリーを備えたインテル® Xeon® プロセッサー・ベースのサーバー 1 基のほうが、大規模な汎用グラフ・アナリティクスに適しています。
