

この記事は、インテル® ソフトウェア・ネットワークに掲載されている「Introduction to x64 Assembly」の日本語参考訳です。
はじめに
長年、PC プログラマーは x86 アセンブリーを使用して、高いパフォーマンスが要求されるコードを記述してきました。しかしながら、32 ビットの PC は 64 ビットに取って代わられつつあり、使用されるアセンブリー・コードも変わりました。この記事では、x64 アセンブリーの概要を説明します。x86 コードの知識はなくても構いませんが、あるとより理解しやすいでしょう。
x64 とは、インテルおよび AMD の 32 ビット x86 命令セット・アーキテクチャー (ISA) の 64 ビット拡張を表す一般的な名称です。AMD が最初に x64 を発表し、当初は x86-64 と呼ばれていましたが、後に AMD64 に変更されました。インテル の x64 は当初 IA-32e と呼ばれていましたが、後に EMT64 に変更されました。2 つのバージョンは完全に互換性があるわけではありませんが、ほとんどのコードはどちらのバージョンでも問題なく動作します。詳細は、『Intel® 64 and IA-32 Architectures Software Developer’s Manuals』 (英語) とAMD64 アーキテクチャーのテクニカル・ドキュメント (英語) を参照してください。2 つのバージョンの共通部分を x64 と呼びます。IA-64 と呼ばれる 64 ビットのインテル® Itanium® アーキテクチャーとは別のものです。
この記事では、ハードウェアの詳細 (キャッシュ、分岐予測、その他の高度なトピックなど) は取り上げません。これらの分野については、記事の最後で関連ドキュメントを紹介しています。
アセンブリーは通常、パフォーマンスに重大な影響を与える部分で使用されますが、ほとんどの開発者にとって、優れた C++ コンパイラーを上回るパフォーマンスを引き出すことは難しいでしょう。しかし、アセンブリーの知識はコードをデバッグする際に役立ちます。例えば、コンパイラーは正しくないアセンブリー・コードを生成することがありますが、その場合にデバッガーでコードを検証し、原因を特定することができます。また、コンパイラーのコード・オプティマイザーが間違いを犯すこともあります。ソースコードがない場合のコードの確認や修正にも、アセンブリーを使用できます。逆アセンブリーは、既存の実行ファイルの変更/修正を可能にします。どうしてあるものは遅く、ほかのものは速いのかといった、プログラミング言語の動作を理解するためには、アセンブリーの知識が必要です。さらに、アセンブリー・コードの知識は、マルウェアの診断には必要不可欠です。
アーキテクチャー
特定のプラットフォームのアセンブリーを習得する場合、まず最初にレジスターセットから取りかかると良いでしょう。
汎用アーキテクチャー
64 ビット・レジスターではより広いデータサイズとメモリーロケーションを利用でき、バイトは 8 ビット、ワードは 16 ビット、ダブルワードは 32 ビット、クワッドワードは 64 ビット、ダブル・クワッドワードは 128 ビットと定義されています。インテル形式では、バイトは “リトル・エンディアン” 形式で格納されます。つまり、下位のバイトが下位のメモリーアドレスに格納されます。

図 1 に示す 16 個の 64 ビット汎用レジスターのうち、最初の 8 個は歴史的な理由から RAX、RBX、RCX、RDX、RBP、RSI、RDI、RSP と表記され、続く 8 個の新しいレジスターは R8-R15 と表記されます。最初の 8 個のレジスターの最初の文字 R を E に変更すると (例えば RAX を EAX にすると)、下位 32 ビットにアクセスすることができます。同様に RAX、RBX、RCX、および RDX では、最初の文字 R を削除すると (例えば RAX を AX にすると) 下位 16 ビットにアクセスできます。さらに、X を L に変更すると (AX を AL) 16 ビットの下位バイトに、H に変更すると (AX を AH にすると) 16 ビットの上位バイトにアクセスできます。
新しいレジスター R8 から R15 にも、同様の方法でアクセスできます。例えば、R8 (クワッドワード)、R8D (下位ダブルワード)、R8W (最下位ワード)、R8B (MASM 形式の最下位バイト、インテル形式では R8L と表記) のようになります。R8H はありません。
新しいレジスターで使用される REX プリフィックスが付くオペコードのコーディング上の問題により、バイト・レジスターのアクセスには制限があります。命令は、新しいバイト・レジスター (例えば R11B など) と以前からあるレジスターの上位バイト (AH、BH、CH、DH) を同時に参照することはできませんが、以前からあるレジスターの下位バイト (AL、BL、CL、DL) は使用できます。REX プリフィックスが付く命令で (AH、BH、CH、DH) は (BPL、SPL、DIL、SIL) に変更されます。
64 ビットの命令ポインター RIP は、次に実行される命令を指しています。RIP は、64 ビットのフラット・メモリー・モデルをサポートします。現行のオペレーティング・システムのメモリーアドレスのレイアウトについては後述します。
スタックポインター RSP は、最後にスタックに追加された項目を指しています。RSP は下位アドレス方向に移動します。スタックは、サブルーチンのリターンアドレスの格納、C/C++ などの高水準言語でのパラメーターの引き渡し、呼び出し規約の “シャドウ部分” の格納に使用されます。
RFLAGS レジスターには、演算結果やプロセッサーの制御に使用されるフラグが格納されています。これは、x86 の 32 ビット・レジスター EFLAGS に上位 32 ビット (予約済み、現在は未使用) を追加したものです。表 1 によく使用されるフラグを示します。その他のフラグのほとんどは、オペレーティング・システム・レベルのタスクに使用されるもので、常に読み込まれた値のままにすべきです。
表 1 – 一般的なフラグ
| シンボル | ビット | 名前 | 説明 |
| CF | 0 | キャリー | 演算で繰り上げ/繰り下げが発生した場合に設定されます。 |
| PF | 2 | パリティー | 最下位バイトの 1 の数が偶数の場合は 1、そうでない場合は 0 に設定されます。 |
| AF | 4 | 補助キャリー | BCD 演算で使用されるキャリーフラグです。 |
| ZF | 6 | ゼロ | 結果が 0 の場合に設定されます。 |
| SF | 7 | 符号 | 結果の最上位ビットが 1 の場合に設定されます。 |
| OF | 11 | オーバーフロー | 符号付き演算でオーバーフローが発生した場合に設定されます。 |
| DF | 10 | 方向 | 文字列操作の方向を示します (インクリメントまたはデクリメント) |
| ID | 21 | ID | CPUID 命令の使用を制御します。 |
浮動小数点演算ユニット (FPU) には、8 個のレジスター FPR0-FPR7、ステータスレジスターと制御レジスター、その他の特殊レジスターがあります。FPR0-7 はそれぞれ、表 2 に示す型の値を 1 つ格納できます。浮動小数点演算は IEEE 754 に準拠します。
ほどんどの C/C++ コンパイラーは 32 ビットと 64 ビットの型 (float と double) をサポートしていますが、アセンブリーで利用可能な 80 ビットはサポートしていません。これらのレジスターは、8 個の 64 ビット MMX レジスターと内部リソースを共有します。FPR0-7 を利用したアセンブリーコードは、x87 命令と呼ばれます。
表 2 – 浮動小数点のデータ型
| データ型 | 長さ | 精度 (ビット) | 10 進数の精度 | 10 進数の範囲 |
| 単精度 | 32 | 24 | 7 | 1.18*10^-38 ~ 3.40*10^38 |
| 倍精度 | 64 | 53 | 15 | 2.23*10^-308 ~ 1.79*10^308 |
| 拡張制度 | 80 | 64 | 19 | 3.37*10^-4932 ~ 1.18*10^4932 |
2 進化 10 進数 (BCD) はいくつかの 8 ビット命令でサポートされており、浮動小数点レジスターでサポートされている変わった形式では 80 ビット (17 桁の BCD データ型) を利用できます。
16 個の 128 ビット XMM レジスター (x86 よりも 8 個多い) については後述します。
この他にも、セグメントレジスター (x64 ではほとんど使用されていない)、制御レジスター、メモリー管理レジスター、デバッグレジスター、仮想レジスター、あらゆる内部パラメーター (キャッシュのヒット/ミス数、分岐のヒット/ミス数、実行されたマイクロオペレーション、タイミング、ほか) を追跡するパフォーマンス・レジスターがあります。注目すべきパフォーマンス・オペコードに RDTSC と RDTSCP というものがあります。これは、小さなコード範囲のプロファイルにかかるプロセッサー・サイクルをカウントするのに使用されます。
詳細は、『Intel® 64 and IA-32 Architectures Software Developer’s Manuals』 (英語、全 5 巻) を参照してください。http://www.intel.com/content/www/us/en/processors/architectures-software-developer-manuals.html?wapkw= intel® 64 and ia-32 architectures software developer’s manuals (英語) から PDF 版を無料でダウンロードできます。
SIMD アーキテクチャー
SIMD (Single Instruction Multiple Data) 命令は、1 つの命令で複数のデータを並列に実行します。アセンブリー・ルーチンでよく使用されます。MMX と SSE 命令 (それぞれ、MMX および XMM レジスターを使用) は SIMD 演算をサポートしており、最大 8 つのデータに対して並列に演算を実行します。例えば、MMX を使用して、1 つの命令で 8 つのバイトの加算を行えます。
8 個の 64 ビット MMX レジスター MMX0-MMX7 は FPR0-7 のエイリアスなので、x87 FP 演算と MMX 演算の混在するコードでは、必要な値を上書きしてしまわないように注意しなければなりません。MMX 命令は整数型を処理します。MMX レジスターにある値に対して、バイト、ワード、ダブルワードの演算を実行できます。算術演算、シフト/回転、比較など、ほとんどの MMX 命令は、”パックド” を表す ‘P’ で始まります。例えば、PCMPGTB は “符号付きパックド・バイト整数がより大きいかどうか比較” します。
16 個の 128 ビット XMM レジスターは、1 つの命令で 4 つの単精度値または 2 つの倍精度値の演算を実行できます。また、一部の命令は、バイト、ワード、ダブルワード、クワッドワードのパックド整数も処理します。これらの命令はストリーミング SIMD 拡張命令 (SSE) と呼ばれ、いくつかの種類があります。現在あるのは SSE、SSE2、SSE3、SSSE3、SSE4 です。インテルは、さらに拡張された SSE として、新しい 256 ビット幅のデータパスに対応したインテル® アドバンスト・ベクトル・エクステンション (インテル® AVX) を発表しました。
SSE 命令には、浮動小数点型と整数型の両方に対する、移動、算術演算、比較、シャッフル、アンパック、ビット単位演算があります。命令には、PMULHUW や RSQRTPS のように処理を表す名前が付けられています。SSE にはメモリーのプリフェッチに関連する命令 (パフォーマンス) とメモリーフェンスに関する命令 (マルチスレッドの安全性) もあります。
表 3 に命令群と使用されるレジスターの種類、同時に処理される要素数、項目のデータ型を示します。例えば、SSE3 と 128 ビット XMM レジスターを使用する場合、2 個の浮動小数点値 (64 ビットでなければならない) を同時に処理したり、16 個の整数値 (バイト・サイズでなければならない) を同時に処理することができます。
各プロセッサーでサポートされている命令セットは、プロセッサー固有情報を返す CPUID 命令で確認できます。
表 3
| 拡張命令セット | レジスターのサイズ/型 | 項目の型 | 同時に処理される項目数 |
| MMX | 64 MMX | 整数 | 8、4、2、1 |
| SSE | 64 MMX | 整数 | 8、4、2、1 |
| SSE | 128 XMM | 浮動小数点数 | 4 |
| SSE2/SSE3/SSSE3 ほか | 64 MMX | 整数 | 2、1 |
| SSE2/SSE3/SSSE3 ほか | 128 XMM | 浮動小数点数 | 2 |
| SSE2/SSE3/SSSE3 ほか | 128 XMM | 整数 | 16、8、4、2、1 |
ツール
アセンブラー
インターネットで「x64 対応アセンブラー」について検索すると、NASM (Netwide Assembler) や NASM を書き直した YASM、高速な FASM (Flat Assembler)、そして従来の Microsoft* MASM が見つかるでしょう。さらに、WinASM と呼ばれる x86 および x64 アセンブリー向けの無料 IDE も見つかるでしょう。各アセンブラーによって、ほかのアセンブラーのマクロと構文のサポート状況は異なります。C++ や Java* とは違い、アセンブラー間でアセンブリー・コードのソース互換はありません。
プラットフォーム SDK に含まれる 64 ビット・バージョンの MASM、ML64.EXE を使用した例について考えてみましょう。この例では、次の形式の MASM 構文を使用しています: 命令 デスティネーション, ソース。
一部のアセンブラーでは、ソースとデスティネーションが入れ替わるため、注意してください。
C/C++ コンパイラー
C/C++ コンパイラーでは、32ビットでも64ビットでも、インライン・アセンブリーを使ってコードにアセンブリーを埋め込むことができますが、Microsoft* Visual Studio* C/C++ は、x64 バージョンではインライン・アセンブリーがサポートされません。これは、恐らくコード・オプティマイザーの内部処理を容易にするためでしょう。したがって、個別のアセンブリー・ファイルと外部アセンブラーを使用するか、またはヘッダーファイル “intrn.h” にある組込み関数を使用しなければなりません ([Birtolo] と [MSDN] を参照)。ほかのコンパイラーでも同様の方法を選択できます。
組込み関数を使用する理由:
- x64 でインライン・アセンブリーがサポートされていない
- 使いやすさ: 手動でレジスターの割り当てを行う代わりに、変数名を使用できる
- アセンブリーよりもクロスプラットフォーム: コンパイラーの開発元は各種アーキテクチャーに組込み関数を移植することができる
- 組込み関数のほうがオプティマイザーが効率良く動作する
例えば、Microsoft* Visual Studio* 2008 には、次の組込み関数があります。
unsigned short _rot16(unsigned short a, unsigned char b)
この組込み関数は、16 ビット値のビットを b ビット右に回転し、その結果を返します。これは、C では次のように表現できます。
unsigned short a1 = (b>>c)|(b<<(16-c));
このコードは、15 個のアセンブリー命令に展開されます (デバッグビルドの場合。リリースビルドの場合、プログラム全体の最適化により切り分けが難しいですが、同じような長さになります)。組込み関数を使用すると、次のように表現できます。
unsigned short a2 = _rotr16(b,c);
このコードは、4 個のアセンブリー命令に展開されます。詳細は、ヘッダーファイルとドキュメントを参照してください。
命令の基本
アドレッシング・モード
基本的な命令の説明に入る前に、アドレッシング・モード (命令がレジスターやメモリーにアクセスする方法) を理解する必要があります。以下に一般的なアドレッシング・モードとその例を示します。
- 即値: ADD EAX, 14 ; 32 ビットの EAX に 14 を足す
- レジスターとレジスター: ADD R8L, AL ; R8L に 8 ビットの AL を足す
- 間接アドレッシング: 8、16、または 32 ビットのディスプレースメント、ベース/インデックスが格納された汎用レジスター、インデックスのスケール値 1、2、4、または 8 倍。これらはセグメント FS: や GS: で事前定義することもできますが、ほとんどの場合その必要はありません。MOV R8W, 1234[8*RAX+RCX] ; アドレス 8*RAX+RCX+1234 にあるワードを R8W に移動する 命令はさまざまな方法で表すことができます。次の命令はすべて同等です。
MOV ECX, dword ptr table[RBX][RDI] MOV ECX, dword ptr table[RDI][RBX] MOV ECX, dword ptr table[RBX+RDI] MOV ECX, dword ptr [ table + RBX + RDI ]
dword ptr は、アセンブラーに MOV 命令のエンコード方法を指示します。
- RIP 相対アドレッシング: x64 で追加された新しいアドレッシング・モードです。現在の命令ポインターとの相対値でデータテーブルへアクセスすることができ、メモリー位置に依存しないコードを容易に実装できます。
MOV AL, [RIP] ; RIP は次の命令 NOP を指す
NOP
このオペコード形式は、MASM では使用できませんが、FASM や YASM などのほかのアセンブラーでは使用できます。MASM では、RIP 相対アドレッシングが暗黙で組込まれています。
MOV EAX, TABLE ; RIP 相対アドレッシングを使用してテーブルアドレスを取得する
- 特殊なケース: 一部のオペコードは、独特な方法でレジスターを使用します。例えば、64 ビットのオペランド値に対する符号付き整数の除算 IDIV では、RDX:RAX に格納されている 128 ビット値をオペランド値で割って、その結果を RAX に格納し、剰余を RDX に格納します。
命令セット
表 4 は、いくつかの一般的な命令のリストです。* は、その項目に複数のオペコードが存在し、* はサフィックスを表します。
表 4 – 一般的なオペコード
| オペコード | 意味 | オペコード | 意味 |
| MOV | メモリーからレジスター、レジスターからメモリー、メモリーとレジスター間の移動 | AND/OR/XOR/NOT | ビット単位の論理演算 |
| CMOV* | さまざまな条件付きの移動 | SHR/SAR | 論理/算術右シフト |
| XCHG | 交換 | SHL/SAL | 論理/算術左シフト |
| BSWAP | バイト・スワップ | ROR/ROL | 右/左に回転 |
| PUSH/POP | スタックへのプッシュ/スタックからのポップ | RCR/RCL | キャリー・ビット付き右/左回転 |
| ADD/ADC | 加算/キャリー付き加算 | BT/BTS/BTR | ビット・テスト/ビットの設定/ビットのリセット |
| SUB/SBC | 減算/キャリー付き減算 | JMP | 無条件ジャンプ |
| MUL/IMUL | 乗算/符号なし乗算 | JE/JNE/JC/JNC/J* | 等しい/等しくない/キャリーあり/キャリーなし/その他多数の条件を満たす場合にジャンプ |
| DIV/IDIV | 除算/符号なし除算 | LOOP/LOOPE/LOOPNE | ECX を使用するループ |
| INC/DEC | インクリメント/デクリメント | CALL/RET | サブルーチンの呼び出し/リターン |
| NEG | 否定 | NOP | 何もしない |
| CMP | 比較 | CPUID | CPU 情報 |
一般的な命令である LOOP 命令は、必要に応じて RCX、ECX、または CX をデクリメントし、結果が 0 でない場合はジャンプします。例:
XOR EAX, EAX ; eax をゼロにする MOV ECX, 10 ; ループを 10 回実行する Label: ; アセンブリーのラベル INX EAX ; eax をインクリメントする LOOP Label ; ECX をデクリメントし、0 でない場合はループを実行する
その他のオペコードには、文字列操作、プリフィックスの繰り返し、I/O ポート操作、フラグの設定/クリア/テスト、浮動小数点演算 (通常、先頭の文字は F。移動、整数から変換/整数への変換、算術演算、比較、超越演算、代数演算、および制御関数) を行うものがあります。マルチスレッド、パフォーマンス問題、その他に対応したキャッシュとメモリー操作を行うオペコードもあります。各オペコードの詳細は、『Intel® 64 and IA-32 Architectures Software Developer’s Manual』 (英語) の 第 2 巻パート 2 を参照してください。
オペレーティング・システム
64 ビット・システムは、理論的には 264 バイトのデータのアドレッシングが可能ですが、現在のチップでは 16 エクサバイト (18,446,744,073,709,551,616 バイト) すべてにアクセスできるものはありません。例えば、AMD アーキテクチャーではアドレスの下位 48 ビットだけを使用し、ビット 48 から 63 はビット 47 のコピーにする必要があります。そうでない場合、例外が発生します。そのため、アドレスは使用可能な仮想アドレス空間の 0 から 00007FFF`FFFFFFFF までと FFFF8000`00000000 から FFFFFFFF`FFFFFFFF までの合計 256TB (281,474,976,710,656 バイト) となります。さらに、64 ビット・メモリーのアドレッシングには、OS で管理する非常に大きなページングテーブルが必要になり、16 エクサバイトすべてを利用できないシステムにとって貴重なメモリーを使用することになります。これらは仮想アドレスであって、物理アドレスではないことに注意してください。
結果、多くのオペレーティング・システムは、この空間の上位半分 (上から下に向かって) を OS で使用し、下位半分 (下から上に向かって) をユーザープログラムで使用しています。Windows* の現行バージョンでは、44 ビットのアドレッシング (16 テラバイト = 17,592,186,044,416 バイト) を使用しています (図 2 を参照)。ユーザープログラムのアドレスは OS によって割り当てられるため、ユーザープログラムにとってアドレスはそれほど重要ではありませんが、ユーザーアドレスとカーネルアドレスを区別できるためデバッグの際に便利です。
OS 関連の最後の項目は、マルチスレッド・プログラミングに関係したものですが、このトピックは大きすぎるためここでは取り上げません。共有リソースが破壊されないようにするメモリーバリア操作用の各種オペコードがあることだけ知っておいてください。
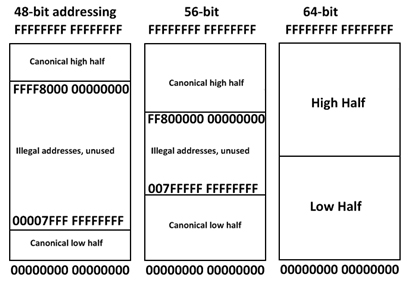
図 2 – メモリー・アドレッシング
呼び出し規約
オペレーティング・システムのライブラリーを利用するには、パラメーターの引き渡し方法とスタックの管理方法を知らなければなりません。プラットフォームに関するこれらの詳細を呼び出し規約と呼びます。
一般的な x64 呼び出し規約として、C 形式の関数呼び出しに使用される Microsoft* 64 があります (MSDN (http://msdn.microsoft.com/en-us/library/9b372w95.aspx)、Chen、Pietre を参照)。Linux* では、これはアプリケーション・バイナリー・インターフェイス (ABI) と呼ばれます。ここで説明する呼び出し規約は、x64 Linux* システムで使用されるものとは異なります。
Microsoft* x64 の呼び出し規約は、レジスター領域の拡張により、fastcall しかありません (x86 では、stdcall、thiscall、fastcall、cdecl など多数あります)。C/C++ 形式の関数を使用する場合のルールは、次のとおりです。
- RCX、RDX、R8、R9 は、左から右にこの順序で整数およびポインター引数に使用されます。
- XMM0、1、2、および 3 は浮動小数点引数に使用されます。
- 追加の引数は、左から右へスタックにプッシュされます。
- パラメーターの長さが 64 ビット未満の場合、ゼロ拡張されず、上位ビットは不定です。
- 関数を呼び出す前に、呼び出し元で (必要に応じて RCX、RDX、R8、および R9 を格納するための) 32 バイトの “シャドウ領域” を割り当てなければなりません。
- 呼び出し後に、呼び出し元でスタックをクリーンアップしなければなりません。
- (x86 と同じように) 整数型の戻り値は、64 ビット以下の場合は RAX に格納され返されます。
- 浮動小数点型の戻り値は、XMM0 に格納され返されます。
- サイズの大きな戻り値 (構造体など) は、呼び出し元によりスタックに領域が割り当てられ、呼び出し先が呼び出されるときにリターン領域へのポインターが RCX に格納されます。そして、整数パラメーターで使用されるレジスターは右に 1 つプッシュされます。RAX はこのアドレスを呼び出し元に返します。
- スタックは 16 バイトでアライメントされています。”call” 命令は 8 バイトの戻り値をプッシュするため、リーフでない関数はスタック領域を割り当てる際に、値を 16n+8 形式で指定してスタックを調整する必要があります。
- RAX、RCX、RDX、R8、R9、R10、および R11 レジスターは不定で、関数呼び出し時に破棄されると考えなければなりません。
- RBX、RBP、RDI、RSI、R12、R13、R14、および R15 は、これらを使用する関数で保存されなければなりません。
- 浮動小数点 (つまり MMX) レジスターの呼び出し規約はありません。
- 詳細 (可変個引数、例外処理、スタックの巻き戻しなど) は、Microsoft* のサイトを参照してください。
例
ここまでの説明を踏まえて、x64 アセンブリーの例を見てみましょう。最初の例は、Windows* でメッセージボックスを表示する単純なスタンドアロンの x64 アセンブリー・プログラムです。
; サンプル x64 アセンブリー・プログラム ; Chris Lomont 2009 www.lomont.org extrn ExitProcess: PROC ; システム・ライブラリーの外部関数 extrn MessageBoxA: PROC .data caption db '64-bit hello!', 0 message db 'Hello World!', 0 .code Start PROC sub rsp, 28h ; シャドウ領域、スタックをアライメントする mov rcx, 0 ; hWnd = HWND_DESKTOP lea rdx, message ; LPCSTR lpText lea r8, caption ; LPCSTR lpCaption mov r9d, 0 ; uType = MB_OK call MessageBoxA ; MessageBox API 関数の呼び出し mov ecx, eax ; uExitCode = MessageBox(...) call ExitProcess Start ENDP End
この hello.asm を保存し、Microsoft* Windows* x64 SDK に含まれる ML64 で次のコマンドを実行してコンパイルします。
ml64 hello.asm /link /subsystem:windows /defaultlib:kernel32.lib /defaultlib:user32.lib /entry:Start
Windows* 用の実行ファイルが作成され、適切なライブラリーにリンクされます。コンパイルされた実行ファイル hello.exe を実行すると、メッセージボックスが表示されます。
次の例は、Microsoft* Visual Studio* 2008 を使って、アセンブリー・ファイルと C/C++ ファイルをリンクします。ほかのコンパイラーでも同様の手順になります。最初に、コンパイラーが x64 に対応していることを確認します。次に、以下の手順を実行します。
- 新しい空の C++ コンソールプロジェクトを作成します。アセンブリーに移植する関数を作成し、main から呼び出します。
- [ビルド] > [構成マネージャ] で、デフォルトの 32 ビット・ビルドを変更します。
- [アクティブ ソリューション プラットフォーム] ドロップダウン・メニューから、<新規作成...> を選択します。
- [新しいプラットフォームを入力または選択してください] から x64 を選択します。x64 が表示されない場合は、64 ビットの SDK ツール を追加する方法を調べて、x64 プラットフォームを追加してください。
- コードをコンパイルし、ステップインにします。メニューから [デバッグ] > [ウィンドウ] > [逆アセンブル] を選択し、結果とアセンブリー関数に必要なインターフェイスを確認します。
- アセンブリー・ファイルを作成し、プロジェクトに追加します。デフォルトで 32 ビットのアセンブラーが選択されます。
- アセンブリー・ファイルのプロパティーを開き、すべての設定を選択して、カスタム・ビルド・ステップを編集します。
- 次のコマンドラインを指定します。
ml64.exe /DWIN_X64 /Zi /c /Cp /Fl /Fo $(IntDir)\$(InputName).obj $(InputName).asm
出力は以下に設定します。
$(IntDir)\$(InputName).obj
- ビルドして、実行します。
例えば、main.cpp に整数パラメーター 5 個とダブル・パラメーター 1 個に対して単純な算術演算を行い、ダブル型の結果を返す関数 CombineC を記述します。CombineA.asm という別のファイルの CombineA と呼ばれる関数で同じ機能をアセンブリーで記述します。以下に C++ ファイルを示します。
// x64 アセンブリー・ファイルに対応する C++ コード #includeusing namespace std; double CombineC(int a, int b, int c, int d, int e, double f) { return (a+b+c+d+e)/(f+1.5); } // 注: C++ で関数名が変更されないように extern "C" が必要です extern "C" double CombineA(int a, int b, int c, int d, int e, double f); int main(void) { cout << "CombineC: " << CombineC(1,2,3,4, 5, 6.1) << endl; cout << "CombineA: " << CombineA(1,2,3,4, 5, 6.1) << endl; return 0; }
関数の先頭に extern "C" を付けて、C++ で関数名が変更されないようにする必要があります。以下にアセンブリー・ファイル CombineA.asm を示します。
; サンプル x64 アセンブリー・プログラム .data realVal REAL8 +1.5 ; 8 バイトで実数を格納する .code PUBLIC CombineA CombineA PROC ADD ECX, DWORD PTR [RSP+28H] ; 第 1 パラメーターとオーバーフロー・パラメーターを足す ADD ECX, R9D ; ほかの 3 つのレジスター・パラメーターを足す ADD ECX, R8D ; ADD ECX, EDX ; MOVD XMM0, ECX ; ダブルワード ECX を XMM0 に移動する CVTDQ2PD XMM0, XMM0 ; ダブルワードを浮動小数点に変換する MOVSD XMM1, realVal ; 1.5 をロードする ADDSD XMM1, MMWORD PTR [RSP+30H] ; パラメーターを足す DIVSD XMM0, XMM1 ; 除算を実行し、結果を xmm0 に格納する RET ; リターンする CombineA ENDP End
このプログラムを実行すると、1.97368 という値が 2 回出力されます。
まとめ
この記事では、x64 アセンブリー・プログラミングに必要な情報の概要を説明しました。次のステップとして、『Intel® 64 and IA-32 Architectures Software Developer's Manuals』 (英語) を参照してみてください。アセンブリーの知識がある場合は、第 1 巻のアーキテクチャーの詳細から読み始めると良いでしょう。その他にも、アセンブリーに関する本やオンライン・チュートリアルも参考になります。
コードがどのように実行されるのかを理解するには、アセンブリー・コードと高水準言語の両方が分かるようになるまで、デバッガーでコードを 1 つずつ見て、逆アセンブリーを確認してみると良いでしょう。C/C++ コンパイラーでは、リリースビルドよりもデバッグビルドのほうが分かりやすいので、デバッグビルドから始めてみてください。最後に、MASM フォーラム http://www.masm32.com (英語) にも有益な情報が多数あります。
参考文献 (英語)
『AMD64 Architecture Tech Docs』: http://developer.amd.com/resources/developer-guides-manuals/
NASM: http://www.nasm.us/
YASM: http://www.tortall.net/projects/yasm/
FASM: http://www.flatassembler.net/
Dylan Birtolo 著、『New Intrinsic Support in Visual Studio 2008』: http://blogs.msdn.com/vcblog/archive/2007/10/18/new-intrinsic-support-in-visual-studio-2008.aspx
Raymond Chen 著、『The history of calling conventions, part 5: amd64』: https://blogs.msdn.microsoft.com/oldnewthing/20040114-00/
『Intel® 64 and IA-32 Architectures Software Developer's Manuals』: http://www.intel.com/content/www/us/en/processors/architectures-software-developer-manuals.html?wapkw= intel® 64 and ia-32 architectures software developer's manuals
『Compiler Intrinsics』: http://msdn.microsoft.com/en-us/library/26td21ds.aspx
『Calling Convention』: http://msdn.microsoft.com/en-us/library/9b372w95.aspx
Matt Pietrek 著、『Everything You Need To Know To Start Programming 64-Bit Windows Systems』: http://msdn.microsoft.com/en-us/magazine/cc300794.aspx
著者紹介
Chris Lomont は、Cybernet Systems Co., Ltd. のリサーチエンジニアで、量子コンピューティング・アルゴリズム、NASA 向けの画像処理、アメリカ国土安全保障省 向けのセキュリティー・ハードウェアの開発、コンピューター科学捜査を含む、さまざまなプロジェクトに従事しています。パデュー大学で数学の博士号および物理、数学、コンピューター・サイエンスの学士号を取得しており、ゲーム開発、財務モデリング、ロボット工学、さまざまなコンサルティングの経験があります。余暇には、夫婦一緒にハイキング、映画鑑賞、おしゃべり、趣味のプログラミング、数学の研究、物理の勉強、音楽の演奏、さまざまな実験を行っています。Lomont 氏の Web サイト www.lomont.org (英語) と電子ガジェットのサイト www.hypnocube.com (英語) もご覧ください。
コンパイラーの最適化に関する詳細は、最適化に関する注意事項を参照してください。
