
この記事は、インテルのウェブサイトで公開されている「Faster Core-to-Core Communications」の日本語参考訳です。原文は更新される可能性があります。原文と翻訳文の内容が異なる場合は原文を優先してください。
この記事の PDF 版はこちらからご利用になれます。
メッセージ・レイテンシーの問題
メモリー帯域幅とスループットは長年にわたって大幅に向上してきましたが、ショートメッセージのエンドツーエンドのレイテンシーは過去 25 年ほとんど変わっていません。しかし、これらのショートメッセージは、分散システムにおけるデータ集約型のワークロードのマルチコア通信と計算には不可欠です。この重要性を考慮しないと、重大なパフォーマンスの低下につながる可能性があります。
この記事では、改善されたリングバッファーを使用してショートメッセージのレイテンシーとスループットを最適化する方法について説明します。従来のリングバッファーの設計を慎重に改良することで、複数の送信側から単一の第 4 世代インテル® Xeon® スケーラブル・プロセッサー・コア (8 つのリクエスターと 1 つのサーバースレッド) へのスループットを 1 秒あたり 4 億 5,000 万件の 64 バイトメッセージにまで向上できます。
では、マルチコア・コヒーレント通信と分散データ管理を高速化するための取り組みについて説明しましょう。
コヒーレント・メモリーの基礎
ほとんどのプログラマーは、現代のマルチコア・プロセッサーの基本的なコヒーレント・メモリー設計 (あるコアがメモリー位置に書き込み、別のコアがそれを読み取ると、2 つ目のコアが新しい値を取得する) を知っています。この設計には、アーキテクチャーにより「メモリー順序付け」のモデルが異なるなど、多くの微妙な点がありますが、基本的な考え方は同じです。
個々のメッセージを送信するワークフローのタイミングは単純で、概要は次のとおりです。
| コア 1 | コア 2 |
|---|---|
| メッセージバッファーに書き込み | |
| 「release」セマンティクスでフラグをアトミック書き込み | |
| 「acquire」セマンティクスでフラグをアトミック読み取り | |
| メッセージバッファーを読み取り |
release セマンティクスによるフラグ書き込みは、メッセージバッファーの書き込みがほかのスレッドで認識されるように (フラグへの書き込みよりも遅くならないように)、プラットフォーム上で必要なすべての操作を行います。acquire セマンティクスによるフラグ読み取りは、メッセージバッファーの読み取りがフラグの読み取りよりも早くならないように、プラットフォーム上で必要なすべての操作を行います。
この動作に問題はありません。では、多くのメッセージを送信する場合はどうなるでしょうか。
受信者はフラグをクリアしてメッセージを確認し、送信者は新しいメッセージを書き込む前にフラグを確認することになりますが、これらの操作は非常に遅く、非効率的です。
コヒーレント・メモリーを複数のコアで使用する
では、コヒーレンシーの概念を詳しく調べて、より説得力のあるアプローチが見つかるかどうか確認してみましょう。
この記事の冒頭で、現在のマルチコア・プロセッサーはコヒーレント・メモリーを備えていると述べました。初期のマルチプロセッサーでは、このような処理は、各 CPU がアクセスするたびにメインメモリーを読み書きすることにより行われていました。キャッシュやメモリー順序の問題はありませんでした。最近のコアは非常に高速ですが、メインメモリーは比較的低速であるため、キャッシュなしでは期待するパフォーマンスは得られません。1 つのコアの 1 つのスレッドがメモリーを読み書きしている場合、キャッシュはほとんどのアクセスをインターセプトして、結果をすばやく返します。しかし、複数のコアが誤ってまたは意図的に同じメモリー位置を使用する場合、処理はかなり複雑になります。
多くの設計では、データのアクセシビリティーと妥当性の状態を反映する、MESI (Modified (変更)、Exclusive (排他)、Shared (共有)、Invalid (無効)) と呼ばれる一貫性プロトコルを使用しています。複数のコアが 1 つの位置を読み取る場合、その位置が両方のキャッシュで「共有」状態になる可能性があります。一方のコアが書き込みを行う場合、まずもう一方のコピーを無効にする必要があります。そのため、ほとんどの設計では、オンチップの「キャッシュおよびホーム・エージェント」が各アドレスのコピーを持っているコアとその状態を追跡する、キャッシュ・ディレクトリー・タイプの実装を使用しています。
コアが書き込みを行い、状態が排他的 (exclusive) でない場合、コアはホーム・エージェントに許可を求める必要があります。ほかのキャッシュにコピーがある場合、ホーム・エージェントはそれらのキャッシュに「スヌープ無効化」メッセージを送信します。ホーム・エージェントは、これらの応答を確認すると、要求元のキャッシュに排他状態に入る許可を送ります。
コアがある位置の読み取りを行おうとして、その位置の状態が無効の場合、コアはホーム・エージェントに許可を求める必要があります。ほかのコアでその位置が排他 (または変更) 状態の場合、ホーム・エージェントは共有状態に移行して変更されたデータをエージェントに返すように所有エージェントに要求し、エージェントが要求元のコアにそのデータを送れるようにします。
このほかに、5 つ目の Owned (所有) 状態を追加した MOESI (Modified (変更)、Owned (所有)、Exclusive (排他)、Shared (共有)、Invalid (無効)) プロトコルを使用している設計もあります。所有データは、変更と共有の両方としてタグ付けされます。この指定により、変更されたデータを共有する前にメインメモリーに書き戻すことができます。データは最終的に書き戻す必要がありますが、書き戻しは遅延されることがあります。
つまり、複雑になる可能性があり、チップ全体ですべてのメッセージ処理が複雑になると、大幅な遅延とパフォーマンスの低下が発生する可能性が高くなります。
コア間のレイテンシー
では、1 つのコアがフラグを設定して、別のコアがフラグに気付くまで、どのくらい時間がかかるでしょうか。テストプログラムを書いて調べてみましょう。
例えば、2 ソケットの 112 個のコアと 224 個のスレッドを備えたインテル® Xeon® CPU Max 9480 プロセッサー・ベースのシステム (開発コード名 Sapphire Rapids) で考えてみましょう。このシステムの各コアには 2 つのハイパースレッドがあり、コア・ハードウェアを共有します。
コード例では 2 つのスレッドがあり、指定されたコアで実行するように設定され、フラグを前後にバウンスして、指定された数のハンドオフを完了するのにかかるタイムスタンプ・カウンター・ティックの数を測定します。
レイテンシーのテストコード例
void *remote_thread(void *arg __attribute__((unused)))
{
set_cpu(remote_cpu);
ready = 1;
for (uint64_t i = 1; i <= nrequests; i += 2) {
while(data.flag.load(std::memory_order_acquire) != i);
data.flag.store(i+1, std::memory_order_release);
}
return (NULL);
}
unsigned long send_wait() {
set_cpu(main_cpu);
while (ready.load(std::memory_order_acquire) == 0);
unsigned long start = rdtsc();
for (uint64_t i = 1; i <= nrequests; i += 2) {
data.flag.store(i, std::memory_order_release);
while(data.flag.load(std::memory_order_acquire) != i+1);
}
unsigned long stop = rdtsc();
return(stop - start);
}この例の構成では、読み取りタイムスタンプ・カウンター (RDTSC) は 2 GHz 刻みであり、プログラムは半分のラウンドトリップ時間について次のデータを表示します。
| 状況 | RDTSC カウント | ナノ秒 |
|---|---|---|
| 同一コア (他の HT) | 33 | 16.5 |
| 同一ソケット | 123 | 61.5 |
| ほかのソケット | 300 | 150 |
注: これらの観察結果の結果として生じる影響の詳細は、Substack の Jason Rahman 氏の記事 (英語) [1] を参照してください。
コア間の帯域幅
コア間の通信のレイテンシーが不必要に高くなることは明らかですが、帯域幅についてはどうでしょうか?
帯域幅も、1 つのコアにバッファーを書き込み、フラグを待機し、別のコアでバッファーを読み取って時間を測定することにより測定できます。前と同じプラットフォーム構成と同様の方法を使用すると、あるコアが 32K バイトを書き込む場合、別のコアがそれを読み取るのに約 9000 RDTSC カウント、つまり 4.5 マイクロ秒かかることがわかります。これは約 7.3 GB/秒に相当します。
興味深いことに、最近の新しい CLDEMOTE 命令により、プログラマーはハードウェアに対して、キャッシュラインをキャッシュ階層内で、L3 までプッシュダウンする必要があることをヒントとして伝えることができます。完了すると、2 つめのコアは約 2900 RDTSC カウントで 32K バイト、つまり約 22 GB/秒で読み取ることができます。この数値は、International Supercomputing 2023 IXPUG ワークショップでの John McCalpin 氏のプレゼンテーション “Bandwidth Limits in the Intel® Xeon® CPU Max Series“ (英語) [2] で報告された観察結果と一致しています。
また、プロセッサー・コアには、未処理のメモリー操作が存在する可能性があることもわかっています。例えば、最初のケースでは、別のコアのキャッシュにあるダーティーなデータを読み取る場合、同じソケットのラウンドトリップが 120 ナノ秒であるにもかかわらず、512 キャッシュライン (32K バイト) を 4.5 マイクロ秒、つまり 1 行あたり約 8.8 ナノ秒でトラバースできます。ここでのデータフローは、アウトオブオーダー実行、複数の未処理メモリー参照、および積極的なハードウェア・プリフェッチの組み合わせで実現されます。
コア間のメッセージ処理の要点
この測定により、コア間のメッセージ処理の「ルーフライン」を確立でき、レイテンシーと帯域幅に対するハードウェアの制限とソフトウェアの目標が分かります。
これまでの観察から得られた重要なポイントは、高速なコア間プロトコルでは、メモリーの一貫性アクティビティーを可能な限り回避する必要があるということです。
ここで、一般的なメッセージ・キューイング・メカニズムであるリングバッファーの詳細を調べて、コア間のメッセージ処理パフォーマンスに対する追加の制御を確認することにしましょう。
リングバッファー
リングバッファーのデータ構造は、プロデューサー (生産者) とコンシューマー (消費者) 間を制御するキューとして使用されてきた長い歴史があり、多くのクローズドおよびオープンソースのライブラリー、技術論文、解説書籍が利用できます。
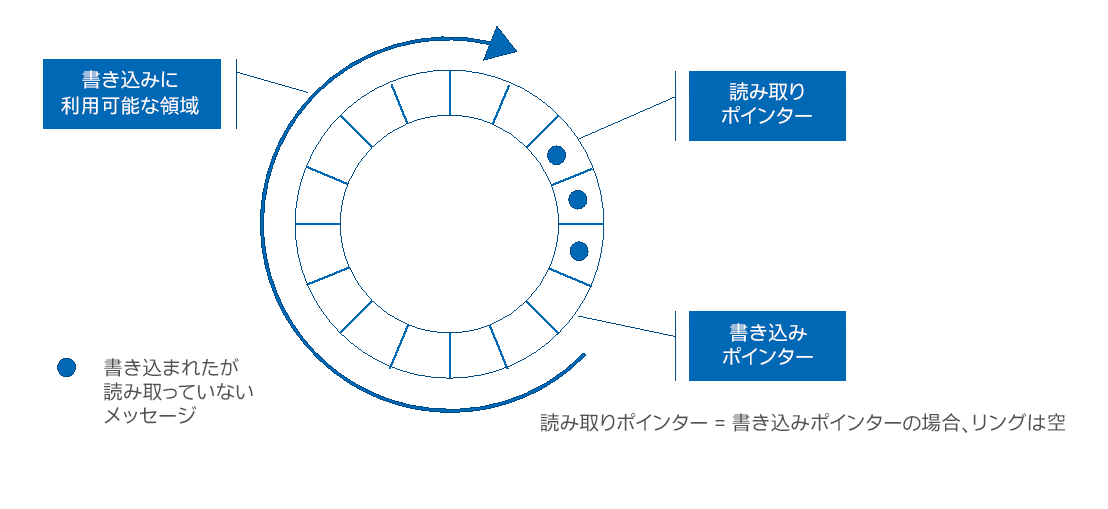
例えば、Herlihy の「The Art of Multiprocessor Programming」 (英語) [3] では、このテーマに 1 章を割いています。図 1 は、共有制御変数を使用した従来のリングバッファーの設計を示しています。
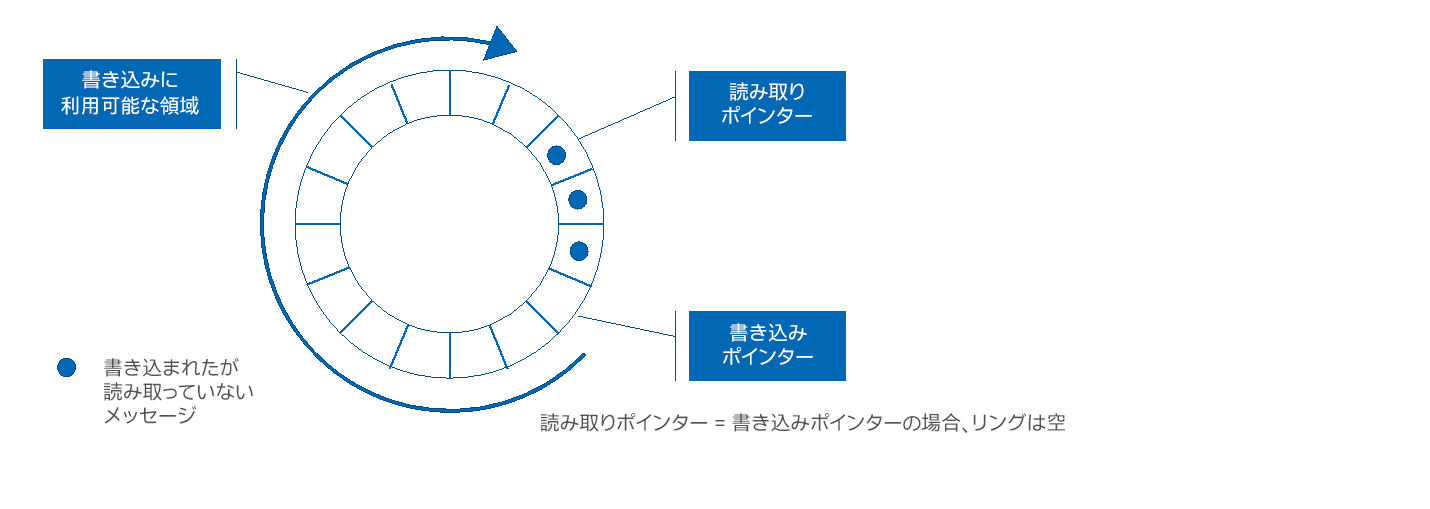
図 1. 従来のリングバッファーの設計
この記事のテスト構成の詳細
テスト実施日: 性能の測定結果は 2024年10月25日現在のインテルの社内テストに基づいています。また、現在公開中のすべてのセキュリティー・アップデートが適用されているとは限りません。
システム構成とワークロードのセットアップ: 1 ノード、1x インテル® Xeon® CPU マックス 9480 プロセッサー、Denali Pass プラットフォーム、合計 DDR5 メモリー 512GB (16 スロット/32GB/3200)、ucode 0x2c0001d1、インテル® ハイパースレッディング・テクノロジー有効、インテル® ターボ・ブースト・テクノロジー有効、EIST 有効、SUSE Linux Enterprise Server 15 SP5、5.14.21-150500.55.80-default、1x NVMe 1.0TB (OS ドライブ)、インテル® oneAPI DPC++/C++ コンパイラー 2024.2.0 (2024.2.0.20240602)。
性能の測定結果はシステム構成の日付時点のテストに基づいています。また、現在公開中のすべてのセキュリティー・アップデートが適用されているとは限りません。詳細については、公開されている構成情報を参照してください。絶対的なセキュリティーを提供できる製品またはコンポーネントはありません。
性能は、使用状況、構成、その他の要因によって異なります。詳細については、http://www.intel.com/PerformanceIndex/ (英語) を参照してください。実際の費用と結果は異なる場合があります。
コード例: 従来のリングバッファー
リングバッファーを実装する C++ クラスを見てみますしょう。
typedef struct {
uint32_t data[15];
std::atomic_uint32_t sequence;
} message_t;
class alignas(CACHELINE_SIZE) Ring {
std::atomic_uint32_t shared_write_pointer __attribute__((aligned(CACHELINE_SIZE)));
std::atomic_uint32_t shared_read_pointer __attribute__((aligned(CACHELINE_SIZE)));
unsigned sender_write_pointer __attribute__((aligned(CACHELINE_SIZE)));
unsigned sender_read_pointer __attribute__((aligned(CACHELINE_SIZE)));
unsigned receiver_write_pointer __attribute__((aligned(CACHELINE_SIZE)));
unsigned receiver_read_pointer __attribute__((aligned(CACHELINE_SIZE)));
unsigned ring_size __attribute__((aligned(CACHELINE_SIZE)));
message_t *ring __attribute__((aligned(CACHELINE_SIZE)));
public:
Ring(unsigned size)
{
ring_size = size;
shared_write_pointer.store(0);
shared_read_pointer.store(0);
sender_write_pointer = 0;
sender_read_pointer = 0;
receiver_write_pointer = 0;
receiver_read_pointer = 0;
ring = (message_t *) aligned_alloc(CACHELINE_SIZE, ring_size * sizeof(message_t));
assert(ring);
for (unsigned i = 0; i < ring_size; i += 1) ring[i].sequence.store(0 - ring_size);
}
~Ring()
{
free(ring);
ring = NULL;
}
void send(message_t &msg)
{
unsigned wp = sender_write_pointer;
while ((wp - shared_read_pointer.load(std::memory_order_acquire)) >= (ring_size -1));
memcpy(&ring[wp % ring_size], &msg, sizeof(message_t) - sizeof(std::atomic_uint32_t));
ring[wp % ring_size].sequence.store(wp, std::memory_order_relaxed);
wp += 1;
shared_write_pointer.store(wp, std::memory_order_release);
sender_write_pointer = wp;
}
int poll()
{
unsigned rp = receiver_read_pointer;
unsigned wp = shared_write_pointer.load(std::memory_order_acquire);
if (rp == wp) return 0;
message_t *mp = &ring[rp % ring_size];
assert(mp->sequence == rp);
rp = rp + 1;
shared_read_pointer.store(rp, std::memory_order_release);
receiver_read_pointer = rp;
return(1);
}
};1 つのコアで受信スレッドを開始し、ほかのコアで N 個の送信スレッドを開始するテストプログラムを使用して測定を行います。
このプログラムの各送信者はリングのコピーを持っています。受信者は、想定した数のメッセージを受信するまで、順番にすべての送信者をポーリングします。さらに、各スレッドはパフォーマンス・カウンター API (PAPI) ライブラリー (英語) を使用して、実行中のデータ・キャッシュのミス数を記録します。すべての実行で、送信スレッドごとに 100,000 件のメッセージが使用されます。
| 送信者数 | メッセージごとの RDTSC サイクル | メッセージごとの受信者ミス | メッセージごと送信者ミス |
|---|---|---|---|
| 1 | 181 | 2.3 | 1.98 |
| 2 | 107 | 2.4 | 2.4 |
| 4 | 144.8 | 2.9 | 2.9 |
| 8 | 117.6 | 2.92 | 2.92 |
| 16 | 134.7 | 2.87 | 2.92 |

ピーク帯域幅は、2 つのクライアントと 1 つのサーバースレッドで達成されます。測定結果は、1 秒あたり約 1.2 ギガバイト、メッセージ率は 1 秒あたり 1,870 万メッセージです。ミス率 (クライアント・スレッドが 4 つ以上ある場合) は、送信側と受信側の両方でメッセージあたり約 3 回のミスです。
この結果は、接続の両端で読み取りポインター、書き込みポインター、およびメッセージ自体がミスになるため、納得できます。
ここでの大きな問題は、shared_read_pointer と shared_write_pointer が、その名前が示すように、送信者と受信者の両方で使用されるため、論理的には必要ない可能性のある一貫性アクティビティーが発生することです。
| 送信者使用 | 受信者使用 | |
|---|---|---|
| 書き込みポインター | リングスペースの割り当て | 新着メッセージの検出 (通知) |
| 読み取りポインター | フロー制御 (リングフル検出) | フロー制御 |
メッセージ通知
つまり、受信側は新しいメッセージが利用可能になったことを知る必要があります。従来のリングバッファーでは、書き込みポインターが読み取りポインターと等しくない場合、少なくとも 1 つのメッセージが利用可能です。受信者は、メッセージを受信するため、書き込みポインター、読み取りポインター、およびメッセージ自体の 3 つのメモリー位置にアクセスする必要があります。
しかし、メッセージ準備完了フラグがメッセージ自体にあるとしたらどうでしょうか? 受信者は 1 回のアクセスで新しいメッセージの存在をテストし、それを読み取ることができます。リングバッファーでは、受信側者は次のメッセージがどこに到着するかはわかりますが、いつ到着するかはわかりません。新しいメッセージの少なくとも 1 ビットが前のメッセージと異なり、同じリングバッファーのスロットを占有することを保証できる限り、受信者は常に新しいメッセージが存在することを認識できます。
リングスロットの一部をフラグとして割り当てることもできます。送信者は設定でき、受信者はクリアできます。しかし、送信者がバッファー使用と以降の使用の間でフラグビットを切り替えるようにすることで、受信者がバッファーに書き込むことなくバッファーの一貫性を簡素化できます。
フロー制御
送信者は、新しいメッセージを送信する前に、リング内にスペースがあるか確認する必要があります。従来のリングバッファーでは、読み取りポインターが書き込みポインターより 1 つ先にあるときリングがフルになります。それ以外では、空きスロットが少なくとも 1 つあります。
送信者は、メッセージを送信するため、書き込みポインター、読み取りポインター、およびメッセージ自体の 3 つのメモリー位置にアクセスする必要があります。ただし、リング内のすべてのスロットが使用可能であることにこだわらなければ、フロー制御をより緩やかな方法で実行でき、送信側と受信側間のやり取りが大幅に少なくなります。
特に、受信者は、送信者がフロー制御に使用する読み取りポインターの 2 番目のコピーを保持できますが、10 番目または 100 番目のメッセージごとにしか更新しません。これにより、フロー制御のコヒーレンス・トラフィックを大幅に削減できます。
これら 2 つのアイデアを組み合わせると、次のようになります。
- メッセージ通知をメッセージ自体に配置する
- フロー制御を「遅延」にする
すると、送信者は、メッセージごとに 1 回以上のキャッシュミス (メッセージ自体と、遅延フロー制御値をチェックしている間に時々発生するミス) でメッセージを送信できます。
以下は、このアイデアを取り入れたリング・バッファー・オブジェクトを再実装したものです。
コード例: 新しいリングバッファー
typedef struct {
uint32_t data[15];
std::atomic_uint32_t sequence;
} message_t;
class alignas(CACHELINE_SIZE) Ring {
std::atomic_uint32_t shared_write_pointer __attribute__((aligned(CACHELINE_SIZE)));
std::atomic_uint32_t shared_read_pointer __attribute__((aligned(CACHELINE_SIZE)));
unsigned sender_write_pointer __attribute__((aligned(CACHELINE_SIZE)));
unsigned sender_read_pointer __attribute__((aligned(CACHELINE_SIZE)));
unsigned receiver_write_pointer __attribute__((aligned(CACHELINE_SIZE)));
unsigned receiver_read_pointer __attribute__((aligned(CACHELINE_SIZE)));
unsigned ring_size __attribute__((aligned(CACHELINE_SIZE)));
message_t *ring __attribute__((aligned(CACHELINE_SIZE)));
public:
Ring(unsigned size)
{
ring_size = size;
shared_write_pointer.store(0);
shared_read_pointer.store(0);
sender_write_pointer = 0;
sender_read_pointer = 0;
receiver_write_pointer = 0;
receiver_read_pointer = 0;
ring = (message_t *) aligned_alloc(CACHELINE_SIZE, ring_size * sizeof(message_t));
assert(ring);
for (unsigned i = 0; i < ring_size; i += 1) ring[i].sequence.store(0 - ring_size);
}
~Ring()
{
free(ring);
ring = NULL;
}
void send(message_t &msg)
{
unsigned wp = sender_write_pointer;
while ((wp - shared_read_pointer.load(std::memory_order_acquire)) == ring_size);
memcpy(&ring[wp % ring_size], &msg, sizeof(message_t) - sizeof(std::atomic_uint32_t));
ring[wp % ring_size].sequence.store(wp, std::memory_order_release);
sender_write_pointer = wp + 1;
}
int poll()
{
unsigned rp = receiver_read_pointer;
message_t *mp = &ring[rp % ring_size];
if (mp->sequence != rp) return 0;
rp = rp + 1;
if ((rp & ((ring_size - 1) >> 1)) == 0) shared_read_pointer.store(rp, std::memory_order_release);
receiver_read_pointer = rp;
return(1);
}
};テストプログラムを再実行すると、結果が大幅に改善されました。
| 送信者数 | メッセージごとの RDTSC サイクル | メッセージごとの受信者ミス | メッセージごと送信者ミス | 秒あたりのメッセージ (x10^6) | GB/秒 |
|---|---|---|---|---|---|
| 1 | 48.2 | 1.23 | .99 | 41.5 | 2.7 |
| 2 | 9.8 | 1.001 | 1.01 | 205.0 | 13.1 |
| 4 | 6.8 | 1.005 | 1.002 | 294.1 | 18.8 |
| 8 | 5.3 | 1.002 | 1.001 | 375.5 | 23.9 |
| 16 | 5.9 | 1.03 | 1.002 | 339.1 | 21.7 |
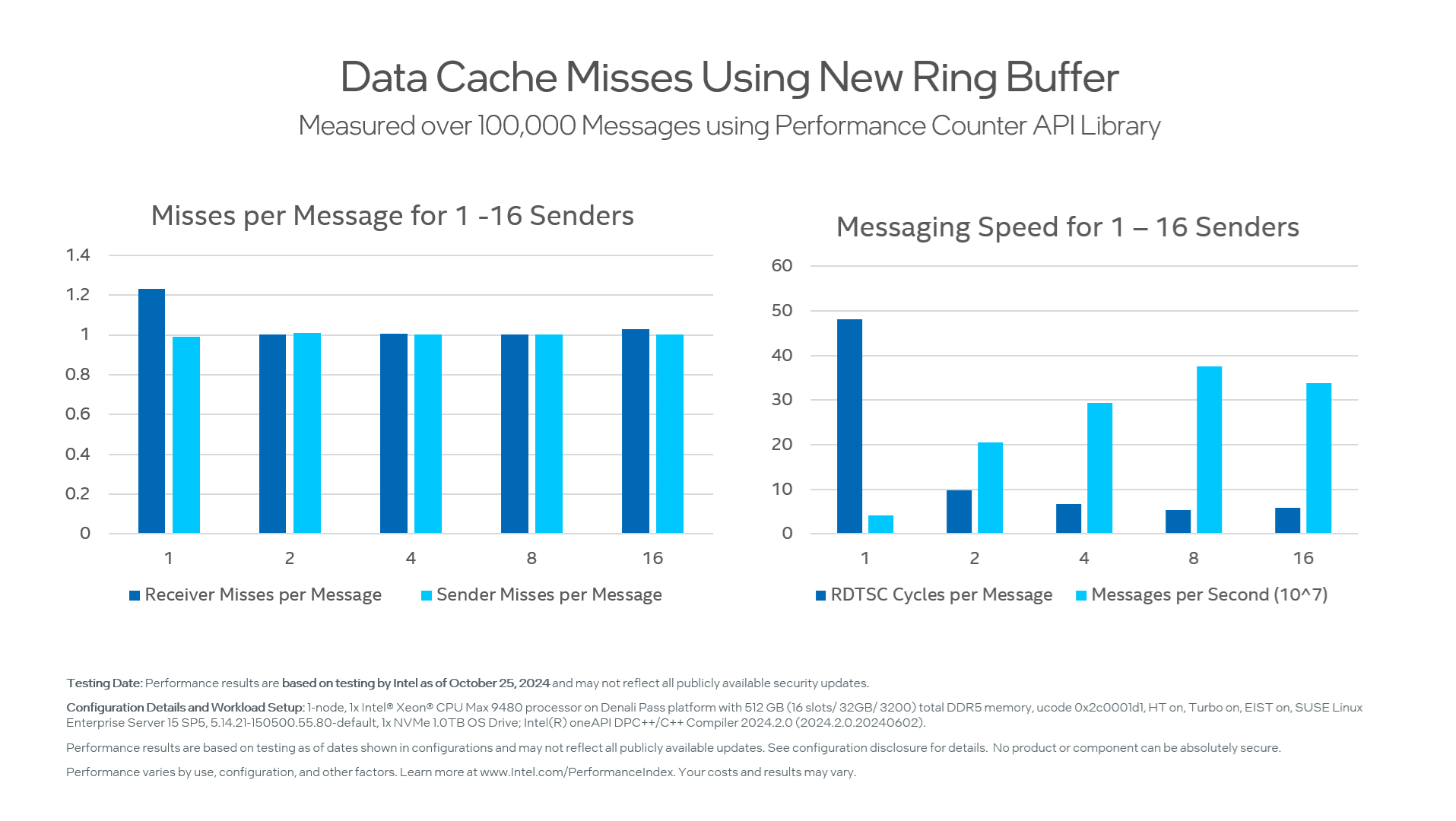
1 つの送信者は、1 秒あたり 4,100 万件のメッセージを送信できるようになりました。これは、1 メッセージあたり 64 バイトの場合、2.7GB/秒になります。
パフォーマンスは適切にスケールし、8 つのクライアントでは、1 秒あたり 3 億 7,500 万メッセージ、1 秒あたり約 24 ギガバイトに達します。つまり、単一のリングバッファーのパフォーマンスを 2 倍にし、受信コアの帯域幅の限界に達するまで設計をスケールできるようにしました。
キャッシュライン降格
でも待ってください! 新しい CLDEMOTE 命令を覚えていますか? この命令を使用して、発信元の L1 から下位のキャッシュレベルに新しく書き込まれたメッセージを「プッシュ」するとどうなるでしょう。試してましょう!
CLDEMOTE を使用してメッセージを段階的に送信するテーブル。
| 送信者数 | メッセージごとの RDTSC サイクル | メッセージごとの受信者ミス | メッセージごと送信者ミス | 秒あたりのメッセージ (x10^6) | GB/秒 |
|---|---|---|---|---|---|
| 1 | 63.6 | 1.33 | 0.0001 | 31.5 | 2.0 |
| 2 | 38.2 | 1.18 | 0.0003 | 52.3 | 3.3 |
| 4 | 22.2 | 1.085 | 0.0003 | 90.0 | 5.8 |
| 8 | 4.4 | 1.002 | 0.0001 | 452.5 | 29.0 |
| 16 | 4.4 | 1.02 | 0.0001 | 457.7 | 29.3 |
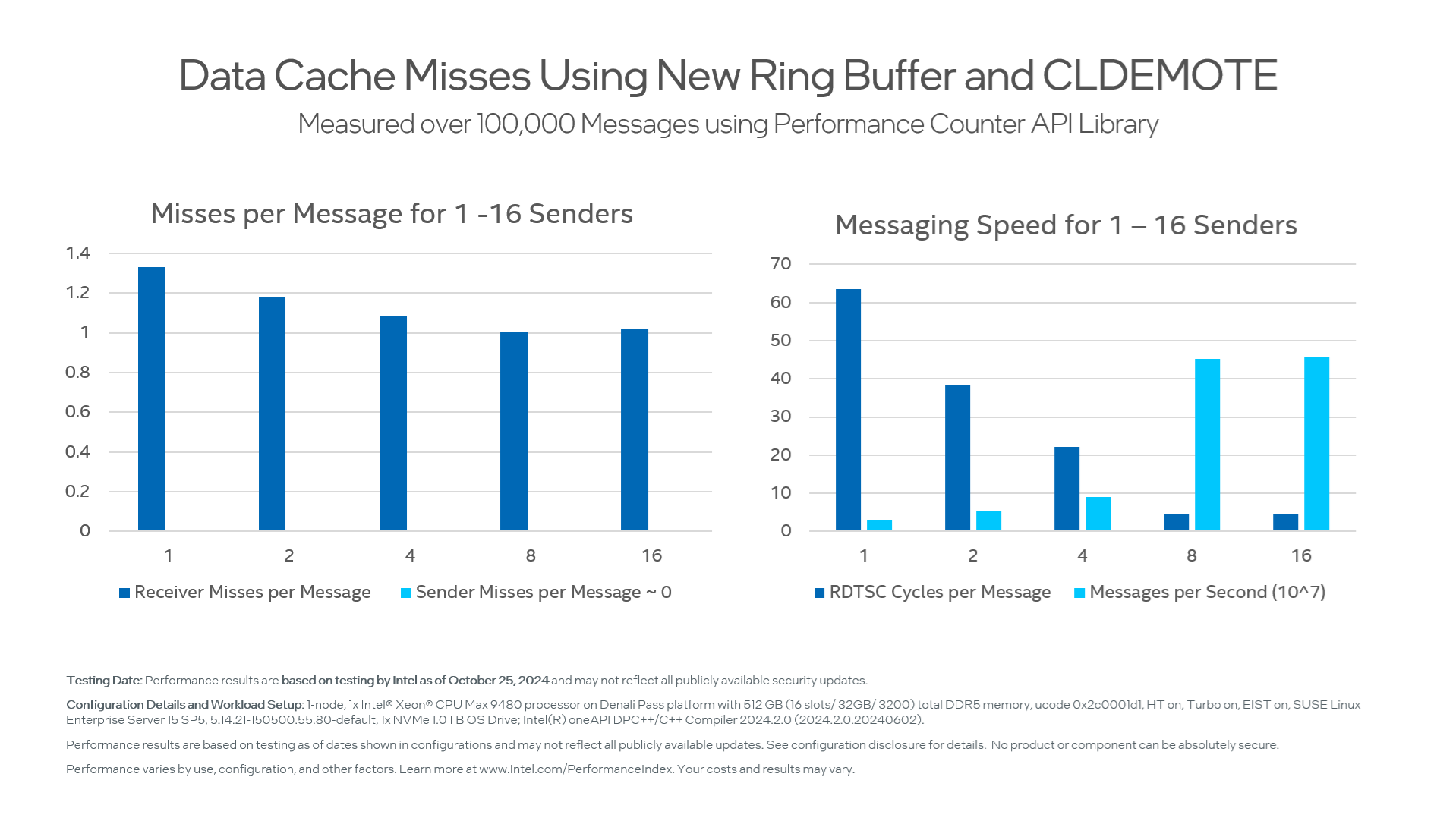
これはかなり興味深いですね! CLDEMOTE を使用すると、1 スレッドではプログラムが少し遅くなり、2 または 4 スレッドの場合はかなり遅くなり、8 および 16 スレッドの場合は 20% 速くなります。十分なスレッドがあれば、個々のクライアントはサーバーがポーリングする前に CLDEMOTE を完了するのに十分な時間を確保でき、それは成功と言えます。スレッド数が少ないと、余分なメモリーシステムのアクティビティーが原因で、ポーリング操作の待機時間が長くなることがあります。総合的に判断すると、CLDEMOTE は、パフォーマンス・クリティカルなパス上にない場合は良いアイデアであると思われます。
まとめ
メモリー・コヒーレンス・イベントを最小限に抑えるキュー設計により、コア間のメッセージ率とレイテンシーを大幅に改善できます。特に、64 バイトのメッセージの場合、送信側と受信側のそれぞれで、平均してメッセージあたり 1 回を超えるキャッシュミスを達成するキューを設計できます。
キャッシュレベルとデータ階層を積極的に管理することで、スレッド化が進んだアプリケーションでパフォーマンスを大幅に向上させることもできます。今後の記事にご期待ください
ツールキットのダウンロード
計算集約型の分散コンピューティングとハイパフォーマンス・コンピューティングの最新の開発動向を把握するには、インテル® oneAPI HPC ツールキット (英語) をご覧ください。 スタンドアロン (英語) のインテル® MPI ライブラリーなど個々のコンポーネントをダウンロードすることもできます。
興味深いソフトウェア・アーキテクチャーとパフォーマンスのトピックに関する記事やディスカッションをさらにご覧になりたい場合は、こちらをご覧ください。
参考文献 (英語)
[1] Rahman, J (2023), Intel® Xeon® Scalable Processor Core-To-Core Latency, SubStack [2] McCalpin, J (2023), Bandwidth Limits in the Intel® Xeon® CPU Max Series, International Supercomputing 2023 IXPUG Workshop [3] Herlihy, M. et al. (2020), The Art of Multiprocessor Programming 2nd ed., Elsevier, ISBN: 9780124159501.製品および性能に関する情報
1 性能は、使用状況、構成、その他の要因によって異なります。詳細については、http://www.intel.com/PerformanceIndex/ (英語) を参照してください。
