
この記事は、インテル® デベロッパー・ゾーンに公開されている「Adventures in Graph Analytics Benchmarking」(https://software.intel.com/en-us/blogs/2019/10/30/adventures-in-graph-analytics-benchmarking) の日本語参考訳です。
グラフ・アナリティクスは注目を集めており、包括的、客観的、および再現可能な方法でパフォーマンスを測定する重要性が増しています。このトピックについては別のブログ (英語) でも取り上げたとおり、カリフォルニア大学バークレー校の GAP Benchmark Suite (英語) など、既製のベンチマークを使用することを推奨します。LDBC Graphalytics (英語) などのグラフ・ベンチマークもありますが、使いやすさで GAP に勝るものはありません。GAP と Graphalytics には共通点が多くありますが、Graphalytics は特殊なソフトウェア構成を必要とする非常に強力なベンチマークです。
個人的には、ベンチマークにあまり興味がありません。しかし、意思決定にパフォーマンス・データが必要な場合、避けて通ることはできません。当然、データは正確であるとともに、意思決定に関連しているべきです。特定のベンチマークが、意図した目的に合ったものであることは重要です。そのため、図 1 のパフォーマンス比較には頭を抱えました。これは、RAPIDS* cuGraph と HiBench (英語) の PageRank パフォーマンスを比較したものです。HiBench は、PageRank だけでなく、さまざまな解析機能を測定するためインテルの HiBench チームによって開発されたビッグデータ・ベンチマークです。図 1 のテストでは、どちらも 50M の頂点と 2B のエッジのみを持つ合成グラフが使用されています。HiBench の測定には Apache Spark* が使用されています。私にとって Apache Spark* クラスターはビッグデータ (テラバイト) を意味します。私のラップトップのメモリーにロードできる 2B エッジのグラフ (圧縮スパース形式で約 8GB) は、ビッグデータとは言えません。単一システムのメモリーに十分収まるのに、なぜわざわざ Apache Spark* クラスターを使用しているのかは不明です。
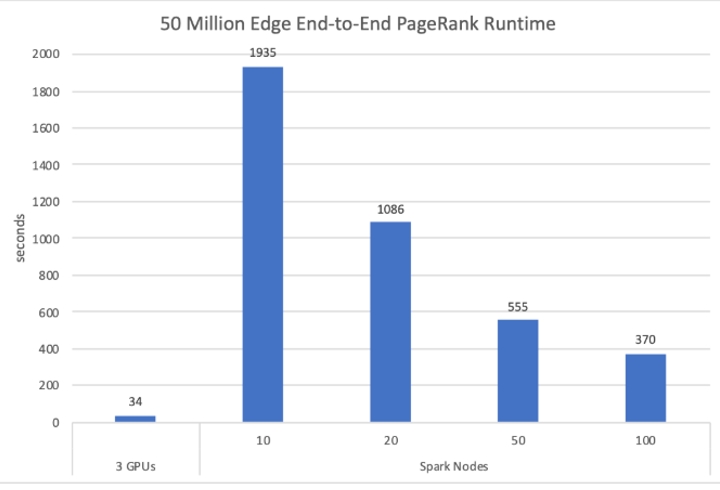
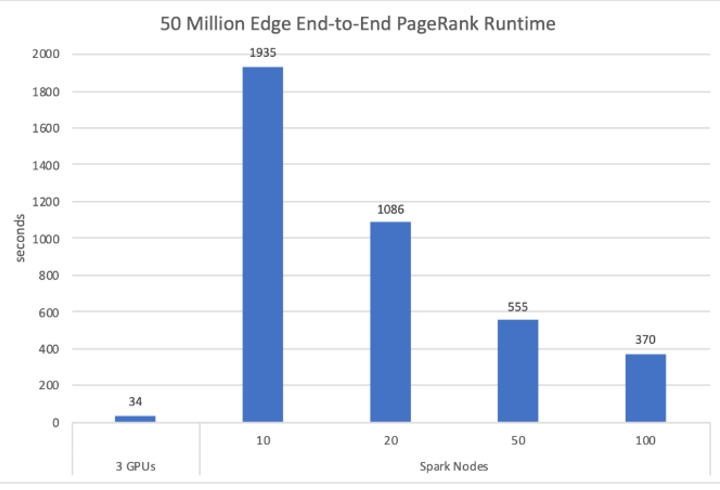
図 1. HiBench ベンチマーク。グラフのタイトル (元のグラフをそのまま引用) が間違っていることに注意してください。入力グラフには 50M ではなく、2B のエッジがあります。また、元のグラフでは、Apache Spark* GraphX を使用したと記載されていますが、HiBench (英語) PageRank ベンチマークはそれよりも効率の劣る MLLib を使用して実装されています。(出典: https://medium.com/rapids-ai/rapids-0-9-a-model-built-to-scale-dafbf4c1e1cb (英語))
実際にパフォーマンス・テストを実施するため、私は HiBench チームの同僚に 50M の頂点と 2B のエッジを持つグラフの生成を依頼しました。GAP ベンチマーク・パッケージの PageRank リファレンス実装を使用して、2 基のインテル® Xeon® プロセッサーを搭載した単一システム上で 48 スレッドで実行したところ、このグラフのエンドツーエンドの計算はわずか 12 秒で完了しました。1 これは、図 1 のパフォーマンスをはるかに上回っており、高額な NVIDIA* V100 GPU や Apache Spark* クラスターがなくても優れたパフォーマンスが得られることが分かりました。
これが、図 1 の cuGraph のパフォーマンスと同一条件での比較かどうかは分かりません。私は、デフォルトの GAP 収束許容値を使用し、反復回数を HiBench のデフォルトである 3 に制限しました。しかし、cuGraph テストに使用されたベンチマークのパラメーターは記載されていないため、同じであったかどうかは分かりません。
信頼性と再現性のあるベンチマークの生成には、透明性が重要です。例えば、PageRank では、収束許容値と最大反復回数により実行時間が大きく異なるため、これらのパラメーター値は明らかにされるべきです。これは、GAP のような既製のベンチマークを使用して、グラフ・アナリティクスのパフォーマンスを測定する最大の利点です。GAP を使用した PageRank テスト結果では、デフォルトで減衰係数は 0.85、許容値は 0.0001、最大反復回数は1,000 であることが分かっています。デフォルトでない値を使用した場合は、そのことを明確にすべきです。
図 1 の元のグラフには、「さまざまな n1-standard-8 [Google Cloud Platform*] ノードにおける [2B] エッジの cuGraph PageRank と Apache Spark* GraphX の比較 (値が低いほうが良い)」というキャプションが付けられていたため、HiBench チームもこのグラフに興味を持ちました。前述のとおり、HiBench の PageRank は、GraphX ではなく、MLLib を使用して実装されています。実験のため、HiBench チームは、GraphX を使用して PageRank を実装して、元の実装とパフォーマンスを比較しました。
残念ながら、n1-standard-8 ノードで使用されたプロセッサーの種類は分かりませんが、各ノードには 8 つの vCPU (単一ハードウェア・ハイパースレッド) と 30GB のメモリーがあることが分かっています (つまり、図 1 の 100 ノードのテストでは、数 GB しか必要としないグラフに 3TB ものメモリーが使用されていました)。これに加えて、ほかの多くの省略要素により、正確な比較は不可能です。HiBench チームは、利用可能な Apache Spark* クラスターの 1 つ (1 つのマスターと合計 440 の vCPU の 4 つのワーカー) でおおよその比較を行いました。2 同じサイズのグラフ (50M の頂点、2B のエッジ) では、MLLib PageRank は 461 秒かかりましたが、GraphX PageRank は 157 秒しかかかりませんでした。これに最も近い結果は、図 1 の 50 ノード (400 vCPU) の Apache Spark* です。このような小規模な問題に Apache Spark* を使用することは適切ではありませんが、HiBench チームの結果のほうが図 1 で報告されているものよりはるかに優れています。
冒頭で述べたとおり、パフォーマンスは、包括的、客観的、および再現可能な方法で測定することが需要です。そのため、GAP Benchmark Suite などの既製のグラフ・アナリティクス・ベンチマークの使用を推奨します。このトピックについては以前のブログ (英語) でも取り上げましたが、グラフ・アナリティクスは広範で多様です。GAP を含め、計算ドメインのあらゆる面をカバーできるベンチマークはありません。例えば、GAP のコミュニティー検出は十分ではありません (GAP の接続コンポーネントのベンチマークは、計算パターンが多くのコミュニティー検出アルゴリズムと共通しているため、それで十分であると言う方もいるでしょう)。もしこれが意思決定にとって重要な場合、代わりにコミュニティー検出に対応した Graphalytics ベンチマークを使用したり、GAP に更新を提案することができます。どちらであっても、コミュニティー・サポートや実績のない、全く新しいベンチマークを作成するよりは良いでしょう。
__________
1Processor: Intel® Xeon® Gold 6252 (2.1 GHz, 24 cores), HyperThreading enabled (48 virtual cores); Memory: 384 GB Micron DDR4-2666; Operating system: Ubuntu Linux release 4.15.0-29, kernel 31.x86_64; Software: GAP Benchmark Suite (downloaded and run September 2019).
2Processor: Intel® Xeon® Platinum 8180 (2.5 GHz, 28 cores), HyperThreading enabled (56 virtual cores); Memory: 384 GB Micron DDR4-2666; Network: Intel® 82599ES 10-Gigabit SFI/SFP+; Operating system: CentOS Linux release 7.6.1810, kernel v3.10.0-862.el7.x86_64; Software: Oracle Java JDK (build 1.8.0_65), Hadoop 2.7.0, Spark 2.4.3, and HiBench 7.0.
法務上の注意書き
Performance results are based on testing as of September 2019 by Intel Corporation and may not reflect all publicly available security updates. See configuration disclosure for details. No product or component can be absolutely secure. For more complete information about performance and benchmark results, visit www.intel.com/benchmarks.
Cost reduction scenarios described are intended as examples of how a given Intel-based product, in the specified circumstances and configurations, may affect future costs and provide cost savings. Circumstances will vary. Intel does not guarantee any costs or cost reduction.
コンパイラーの最適化に関する詳細は、最適化に関する注意事項を参照してください。
