
この記事の PDF 版はこちらからご利用になれます。
はじめに
目的
CPU のベクトルユニットは、メディアの高速化と SIMD (Single Instruction, Multiple Data) を利用して並列処理を行うその他のカーネルの事実上の標準となっています。1 ベクトルユニットは、単一のレジスターファイルを、合計幅がベクトル・レジスター・ファイルの幅と等しい複数のレジスターの組み合わせとして扱うことができます。そのため、単一命令でこのベクトルレジスターのすべてのデータを並列に操作して、このパターンに一致するデータアクセスを持つアプリケーションを大幅にスピードアップすることができます。インテル® MMX® テクノロジーにより拡張されたアーキテクチャーで 8 ビット・レジスターとして扱われる 64 ビット・ベクトル・レジスター・ファイルから、インテル® アーキテクチャー・プロセッサー上の SIMD では、インテル® アドバンスト・ベクトル・エクステンション (インテル® AVX) とインテル® AVX2 世代の 32 個の並列 8 ビット操作が可能な 256 ビット・レジスター・ファイルに進化しました。 メディア・ワークロードのカーネルは、同じ操作 (例えばフィルタリング) がフレームの複数のピクセルに一様に適用されるため、この実行パターンに自然に合致します。そのため、いくつかの主要なオープンソース・プロジェクトではコードの高速化に SIMD 命令を活用しています。AVC (Advanced Video Coding) エンコードの x264 プロジェクト2 と HEVC (High Efficiency Video Coding) エンコードの x265 プロジェクト3 は、広く利用されているメディア・ライブラリーであり、インテル® MMX® テクノロジーからインテル® AVX2 まで、インテル® アーキテクチャー・プロセッサー上の複数世代の SIMD を活用しています。図 1 に示すように、x264 と x265 は SIMD コードを使用しないベースラインと比較して、それぞれ 2 倍と 5 倍のスピードアップを達成しています。HEVC のほうが AVC よりもフレーム当たりの作業量がはるかに多いため、x265 エンコーダーのほうが x264 よりもインテル® AVX2 から大きなパフォーマンス・ゲインが得られます。4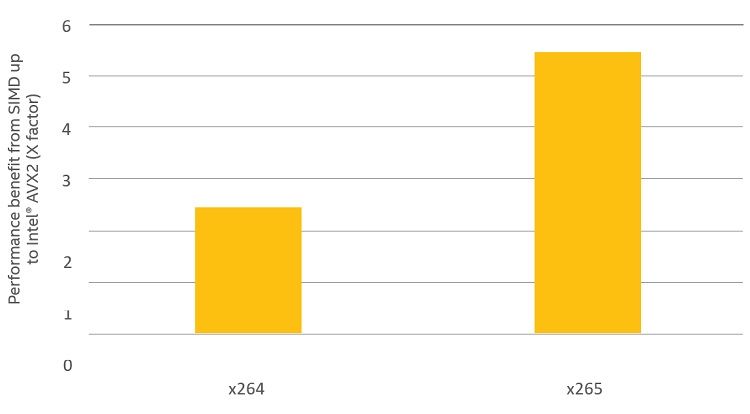 図 1. インテル® Core™ i7-4500U プロセッサー上で Main プロファイルの 1080p エンコードにインテル® AVX2 を使用した場合の x264 と x265 のパフォーマンス・ゲイン
図 1. インテル® Core™ i7-4500U プロセッサー上で Main プロファイルの 1080p エンコードにインテル® AVX2 を使用した場合の x264 と x265 のパフォーマンス・ゲイン
この記事の焦点
最近リリースされたインテル® Xeon® スケーラブル・プロセッサー (開発コード名 Purley) は、インテル® AVX-512 命令セットを採用しています。5 インテル® AVX-512 命令は、インテル® AVX2 と比較して、同じサイクル数で 2 倍の操作を実行することができます。このスループットを達成するため、より多くのダイ面積が利用されており、その結果、前世代の SIMD ユニットよりも消費電力が大きくなっています。そのため、特定のインテル® AVX-512 命令は、ほかの命令よりも CPU のクロック周波数低下幅が大きくなることが予想されます。6 このクロック周波数の低下は、インテル® AVX-512 命令のスループットによって相殺されますが、メディアカーネルは引き続き古い世代 の SIMD 命令 (すべてのカーネルがより広い幅によって利点が得られるわけではないため) と SIMD 変換に適していない単純な C コードに大きく依存するため、パフォーマンスが低下する可能性があります。 この記事は、インテル® AVX-512 の SIMD 命令を使用して x265 の計算負荷の高いカーネルを高速化した取り組みを紹介するケーススタディーです。エンコーダー全体のパフォーマンスを向上するため、CPU 周波数の低下を相殺する方法を説明します。この過程を通じて、HEVC エンコードの x265 でインテル® AVX-512 の使用が推奨される場合を示します。また、メディアカーネルを高速化する手段としてインテル® AVX-512 を選択する際の経験則を共有します。主な取り組み
メディアカーネルでインテル® AVX-512 を使用する場合、微妙なバランスが必要となります。我々の経験から、次のことを推奨します。- インテル® AVX-512 で高速化可能なカーネルを選択する際は、計算とメモリーの比率を考慮すべきです。この比率が高い場合、インテル® AVX-512 の使用を推奨します。また、インテル® AVX-512 を使用する場合、キャッシュライン境界をまたぐロードを回避するため、バッファーを 64B にアライメントします。
- デスクトップ SKU とワークステーション SKU (例えば、テストに使用したインテル® Core™ i9-7900X プロセッサー) では、CPU クロック周波数の低下がわずかであるため、すべてのエンコーダー構成でインテル® AVX-512 カーネルを有効にできます。
- サーバー SKU (例えば、テストに使用したインテル® Xeon® Platinum 8180 プロセッサー) では、アクティブなコア数に比例して、周波数の低下幅が大きくなります。そのため、インテル® AVX-512 では、クロックサイクルの利点が周波数のペナルティーを相殺することで、エンコーダーのパフォーマンスを向上できる、ピクセルごとの計算量が多い場合にのみ有効にすべきです。
具体的には、Main10 プロファイルで slower または veryslow プリセットを使用して 4K コンテンツをエンコードする場合にのみインテル® AVX-512 を使用することを推奨します。その他の設定 (解像度/プロファイル/プリセット) では、エンコーダーのパフォーマンスに影響する可能性があるため、インテル® AVX-512 カーネルの使用は推奨しません。
この記事で紹介する結果と推奨事項は、評価や実験的近似に限定されず、コミュニティー全体がインテル® AVX-512 を使用してメディア・ワークロードを高速化する利点を理解するのに役立つでしょう。 「背景情報」セクションでは、この記事で紹介する技術資料に関する背景情報を示します。「インテル® AVX-512 で x265 カーネルを高速化する」セクションでは、高速化する x265 カーネルの選択と Main/Main 10 プロファイルでの結果を説明します。「インテル® AVX-512 で x265 エンコードを高速化する」セクションでは、Main/Main 10 プロファイルでのエンコーダー全体の結果を示します。そして最後のセクションでは、x265 でインテル® AVX-512 の使用が推奨される場合と、特定のカーネルを高速化するためインテル® AVX-512 を選択する際の一般的な推奨事項を提供します。また、今後の課題も提示します。背景情報
背景情報のセクションでは、この記事で紹介する概念に関する背景情報を示します。「HEVC ビデオエンコード」では HEVC の背景情報を、「x265 オープンソース HEVC エンコーダー」では x265 における既存のパフォーマンス最適化手法に注目して述べます。「インテル® Xeon® スケーラブル・プロセッサー・プラットフォームについて」では、インテル® Xeon® スケーラブル・プロセッサーの概要を提供し、「インテル® AVX-512 を使用する SIMD ベクトル化」では、インテル® AVX-512 アーキテクチャーについて詳しく述べます。HEVC ビデオエンコード
HEVC は、広く普及している AVC 規格の後継として、2013 年に JCT- VC (ビデオ・コーディングに関する共同作業チーム) によってエンコード規格として批准されました。4 HEVC ビデオのエンコード/デコードプロセスは、画像の各ブロックを表すコーディング・ユニット (CU)、CU の動き補償予測を含むモードの決定を表す予測ユニット (PU)、および予測と実際のブロック間の残差のコード化方法を表す変換ユニット (TU) の 3 つのユニットを識別して処理を行います。 最初に、フレームがコーディング・ツリー・ユニット (CTU) と呼ばれる、オーバーラップしない最大のコーディング・ユニットに分割されます。次に、CTU が、さまざまなサイズ (64×64、32×32、16×16、8×8) の複数の CU に分割され、クワッドツリーを形成します。その後、(同じフレームまたは異なるフレームにある) 候補ブロックのセットから各 CU が予測されます。予測に使用されるブロックが同じフレーム内にある場合はイントラ予測ブロックと言われ、異なるフレーム内にある場合はインター予測ブロックと言われます。 イントラ予測ブロックは、予測ブロックと予測の角度を示すモードの組み合わせで構成されます。イントラ予測で許可されるモードは、DC、平面、角度モードと呼ばれ、予測ブロックのさまざまな角度を表します。インター予測ブロックは、予測に使用されたブロック (リファレンス・ブロック) と現在のブロックとリファレンス・ブロック間の差分を示す動きベクトル (MV) の組み合わせで構成されます。MV がゼロのブロックはマージモードを使用し、それ以外は AMP (Advanced Motion Prediction) モードを使用します。スキップモードは、予測ブロックがソースと同一である (つまり、残余がない) 特殊なマージモードです。AMP モードは、CU と同じサイズの PU (2Nx2N PU) を使用するか、MV を計算するためさらに分割します (矩形および非対称 PU)。そして、オリジナル画像と予測画像の差として生成された残差は、予測モードに応じて、32×32 から最大 4×4 ブロックの TU を使用して量子化およびコード化されます。 インター、イントラ、CU、PU、および TU の選択プロセス全体は、ビッグデータ、人工知能 (AI)、ハイパフォーマンス・コンピューティング、エンタープライズクラス IT、クラウド、ストレージ、通信、IoT を含む広範な使用モデルに利点をもたらします。1.5 倍のメモリー帯域幅、統合ネットワーク/ファブリック、統合アクセラレーター (オプション)、広範なワークロード向けのパフォーマンスなどが得られます。x265 の結果は、前世代のインテル® Xeon® プロセッサー E5-2600 と比較して、オフラインエンコードにおいて 50 – 67% の大幅なスピードアップを示しています。これは、主にレート歪み最適化 (RDO) によるもので、ターゲット・ビットレートで歪みが最小化されること、または歪みによって表されるターゲット品質レベルでビットレートが最小化されることを保証します。RDO プロセス全体を通して、CU、PU、TU のさまざまな組み合わせが、いくつかのカーネルを使用するエンコーダーによって試されます。この記事では、これらのカーネルをインテル® AVX-512 命令を使用するように変換してベクトル化します。 HEVC エンコードは、ビデオエンコードで複数のプロファイルをサポートしており、それぞれのプロファイルは各ピクセルを表現する異なるビット数を示します。Main と Main10 プロファイルは、HEVC の代表的なプロファイルです (対応する AVC のプロファイルはそれぞれ Main と High プロファイルです)。ピクセルの各コンポーネントは、Main プロファイルでは最小 8 ビットで表され、値は 0 -255 の範囲になります。Main10 プロファイルは、ピクセルあたり 10 ビットを使用し、ピクセルごとに 0 -1023 の範囲でエンコードされたビデオでより詳細な表現が可能です。x265 エンコーダーは、HEVC 規格に準拠したビデオ圧縮を提供するオープンソースの HEVC です。7 VLC*、HandBrake、8 および FFMpeg*9 を含む複数のオープンソース・フレームワークに統合されており、業界標準のオープンソースの HEVC ビデオ・エンコーダーです。x265 エンコーダーは、インテル® アーキテクチャー、ARM*、PowerPC* を含む複数のプラットフォーム向けにアセンブリー・レベルで最適化されています。 x265 エンコーダーは、複雑さを増す HEVC エンコードに対応するため、フレーム間とフレーム内の並列化手法を採用しています。10 フレーム間の並列化では、x265 はシステムレベルのソフトウェア・スレッドを使用して複数のフレームを並列にエンコードします。フレーム内の並列化では、x265 は HEVC 規格の波状並列処理 (WPP) ツールを利用します。この機能は、ブロックのエンコードを開始する前に、前の行からのイントラ予測に必要なブロックが確実に完了するようにしつつ、フレームの CTU の行を並列にエンコードすることを可能にします。つまり、現在の行の CTU のエンコードを開始する前に、前の行の次の CTU が確実に完了するようにします。これらの機能を組み合わせることで、公開されているリファレンス・エンコーダー HM と比較して、効率を損なうことなく大幅なスピードアップを達成できます。インテル® Xeon® スケーラブル・プロセッサー・プラットフォームについて
インテル® Xeon® スケーラブル・プロセッサー (開発コード名 Purley) は、画期的な新しいレベルのパフォーマンスを一貫して提供するように設計されています。最先端のテクノロジーをベースにしており、インテル® Xeon® スケーラブル・プロセッサーで改良されたマイクロアーキテクチャー機能を提供します。インテル® AVX-512 を使用する SIMD ベクトル化
インテル® AVX-512 ベクトルユニットは、512 ビットのレジスターファイルを提供し、インテル® AVX2 と比較して、サイクルあたり 2 倍の並列データ操作が可能です。インテル® AVX-512 アーキテクチャーを使用するためカーネルをベクトル化する利点は明白ですが、このタスクを開始する前にメディア・ワークロードに関していくつか重要な点を確認する必要があります。第 1 に、この向上した並列処理を活用するのに十分な並列性がメディアカーネルにあるかです。第 2 に、この並列処理を利用する実行の割合は、アムダールの法則に従って平均的なスピードアップを期待できる十分な大きさであるかです。そして、第 3 に、このようなベクトル化を行うことで、シリアルコードやベクトル化されていないコードの実行に影響がないかです。インテル® AVX-512 で x265 カーネルを高速化する
高速化の最初のステップとして、インテル® AVX-512 アセンブリー命令を使用して、高速化する x265 カーネルを選択しました。ベクトル化された SIMD コードを生成する自動化ツールはありますが、手書きのアセンブリーのほうが自動ベクトル化ツールよりも優れていることが分かりました。そのため、この手法を使用することにしました。このセクションでは、この手法をどのように実行したか、そして Main と Main10 プロファイルでのこれらのカーネルのサンプル実行で観測されたサイクルカウントのゲインについて詳しく述べます。高速化するカーネルを選択する
Main と Main10 プロファイルでインテル® AVX-512 命令を利用して最適化するため、x256 の基本計算から 1,000 を超えるカーネルを選択しました。これらのカーネルは、リソース要件に基づいて選択されました。異なるブロックコピーとブロックフィル・カーネルのように頻繁なメモリーアクセスを必要とするカーネルもあれば、DCT、iDCT、量子化カーネルのように計算を多用するカーネルもあります。また、それら 2 つをさまざまな割合で組み合わせたカーネルもあります。アセンブリー・ルーチンがアクセスするバッファーを 64 バイトでアライメントすることで、キャッシュミスが減り、一般にインテル® AVX-512 カーネルにとって利点があることが分かりました。インテル® AVX-512 命令で最適化された Main と Main10 プロファイルのカーネルの一覧はそれぞれ付録 A1 と A2 にあります。サイクルカウントの向上を評価するフレームワーク
x265 エンコーダーは、アセンブリー・カーネルの正当性とパフォーマンスを測定するツールとして、サンプル・テスト・ベンチマークを実装します。このベンチマークは、カーネルに対して有効な引数を受け取り、C プリミティブと対応するアセンブリー・カーネルを呼び出して、両方の出力バッファーを比較します。ランダムに分散された値のセットを使用して、入力タイプで可能なすべてのコーナーケースを検証します。各アセンブリー・カーネルは 100 回呼び出され、正当性を保証するため C プリミティブの出力と照合されます。パフォーマンスの向上を測定するため、テスト・ベンチマークは 1,000 回の実行におけるアセンブリー・カーネルと C カーネル間のクロック数の差 (rdtsc 命令で取得) を測定して、その平均を報告します。Main と Main10 プロファイルのカーネルのサイクルカウントの向上
図 2 は、インテル® AVX-512 を利用して高速化された Main プロファイルの 500 カーネルと、Main10 プロファイルの 600 を超えるカーネルのサイクルカウントの向上を示しています。それぞれの曲線においてカーネルは、対応するインテル® AVX-512 実装と比較したサイクルカウントのゲインで昇順にソートされています。付録 A は、インテル® AVX2 と比較したカーネルごとのサイクルカウントのゲインです。 Main と Main10 プロファイルのカーネルでは、平均サイクルカウントがインテル® AVX2 カーネルよりもそれぞれ 33% と 40% 向上しました。大幅なゲインの理由はいくつかあります。Main10 プロファイルでは、x265 は 16 ビットで各ピクセルを表します。一方、Main プロファイルでは、8 ビットを使用します。Main10 は技術的には 10 ビットで十分ですが、16 ビットを使用することで、ソフトウェアのすべてのデータ構造を簡素化できます。そのため、同じピクセル数に対する作業量が 2 倍になります。計算量が多いため、インテル® AVX2 とインテル® AVX-512 のゲインを比較した場合、Main10 プロファイルのカーネルのほうが Main プロファイルのカーネルよりもゲインが大きくなります。このことから、カーネルレベルでは、x265 を高速化するためインテル® AVX-512 を使用することで大きな利点が得られることが分かります。しかしこれは、インテル® AVX-512 命令を使用した場合と、インテル® AVX2 命令を使用した場合のクロック周波数低下の比較を考慮していません。次のセクションでは、この影響を考慮した全体のエンコード時間への影響について考えます。インテル® AVX-512 で x265 エンコードを高速化する
このセクションでは、実際の x265 エンコードにインテル® AVX-512 カーネルを使用する影響を考察します。「テスト構成」では、選択したビデオ、使用した x265 プリセット、テストマシンのシステム構成を含むテスト構成について説明します。「インテル® Core™ プロセッサー上でのエンコード」では、インテル® Core™ i9-7900X プロセッサーを搭載したワークステーション・マシン上での結果を示し、「インテル® Xeon® スケーラブル・プロセッサー上でのエンコード」では、2 基のインテル® Xeon® Platinum 8180 プロセッサーを搭載した典型的なハイエンドサーバー上での結果を示します。テスト構成
このテストでは、主に Main プロファイルの 1080p ビデオのエンコードと Main10 プロファイルの 4K ビデオのエンコードに注目しました。テストには、4 つの一般的な 1080p クリップ (crowdrun、ducks_take_off、park_ joy、old_town_cross) と 3 つの 4K クリップ (Netflix_Boat、Netflix_FoodMarket、Netflix_Tango) を使用しました。10 付録 B に使用したビデオのスクリーンショットと詳細があります。次のビットレート (Kbps 単位) で Main プロファイルの 1080p をエンコードします: 1000、3000、5000、および 7000。4K クリップでは、Main10 プロファイルは次のビットレート (Kbps 単位) をターゲットにします: 8000、10000、12000、および 14000。 セクション 3 で示したすべてのカーネルを含むバージョンの x265 でこれらのビデオをエンコードします。これらのカーネルは、x265 のデフォルトのブランチの一部として提供されました。カーネルは、デフォルトでは無効に設定されており、x265 コマンドライン・インターフェイスで -asm avx512 オプションを指定して有効にできます。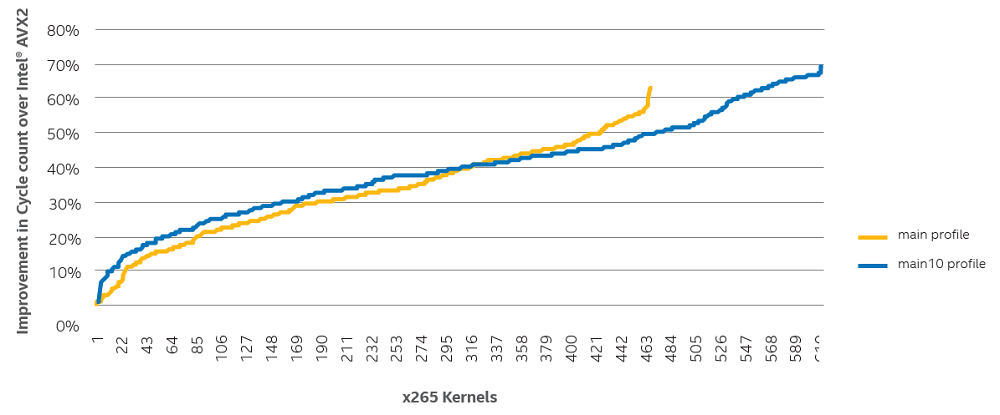 図 2. インテル® AVX-512 カーネルと対応するインテル® AVX2 カーネルを使用した場合の Main と Main10 プロファイルのサイクルカウントのゲイン
実験では、x265 の広範なユースケースを代表する 4 つのプリセットに注目しました: ultrafast、veryfast、medium、および veryslow。これらのプリセットは、エンコード効率と 1 秒あたりのフレーム数 (FPS) の異なるトレードオフを示しています。veryslow プリセットは、最も効率良いエンコードが可能ですが、最も低速です。OTT などのオフラインエンコードのユースケースに適しています。ultrafast プリセットは、x265 で最速の設定ですが、エンコード効率は最低です。veryfast と medium プリセットは、パフォーマンスとエンコード効率のバランスが良く、トレードオフの中間点と言えます。通常、より効率的なプリセットでは HEVC ツールが多く使用されるため、低効率のプリセットよりもピクセルあたりの計算量が増えます。前述のセクションの結果から分かるとおり、インテル® AVX-512 カーネルは、ピクセルあたりの計算量が多いほうが大きなスピードアップを得られる傾向にあるため、これは重要です。
図 2. インテル® AVX-512 カーネルと対応するインテル® AVX2 カーネルを使用した場合の Main と Main10 プロファイルのサイクルカウントのゲイン
実験では、x265 の広範なユースケースを代表する 4 つのプリセットに注目しました: ultrafast、veryfast、medium、および veryslow。これらのプリセットは、エンコード効率と 1 秒あたりのフレーム数 (FPS) の異なるトレードオフを示しています。veryslow プリセットは、最も効率良いエンコードが可能ですが、最も低速です。OTT などのオフラインエンコードのユースケースに適しています。ultrafast プリセットは、x265 で最速の設定ですが、エンコード効率は最低です。veryfast と medium プリセットは、パフォーマンスとエンコード効率のバランスが良く、トレードオフの中間点と言えます。通常、より効率的なプリセットでは HEVC ツールが多く使用されるため、低効率のプリセットよりもピクセルあたりの計算量が増えます。前述のセクションの結果から分かるとおり、インテル® AVX-512 カーネルは、ピクセルあたりの計算量が多いほうが大きなスピードアップを得られる傾向にあるため、これは重要です。
インテル® Core™ プロセッサー上でのエンコード
図 3 は、インテル® Core™ i9-7900X プロセッサーを搭載したワークステーション構成において、x265 の単一のインスタンスでインテル® AVX2 を使用した場合と比較して、インテル® AVX-512 を使用した場合の Main と Main10 の 1080p と 4K ビデオのエンコード・パフォーマンスを示しています。システム構成の詳細は、付録 C にあります。単一のインスタンスは、このシステムで HEVC エンコードを実行する典型的なユースケースのすべての構成において CPU 使用率が高くなります。インテル® Core™ i9-7900X プロセッサー
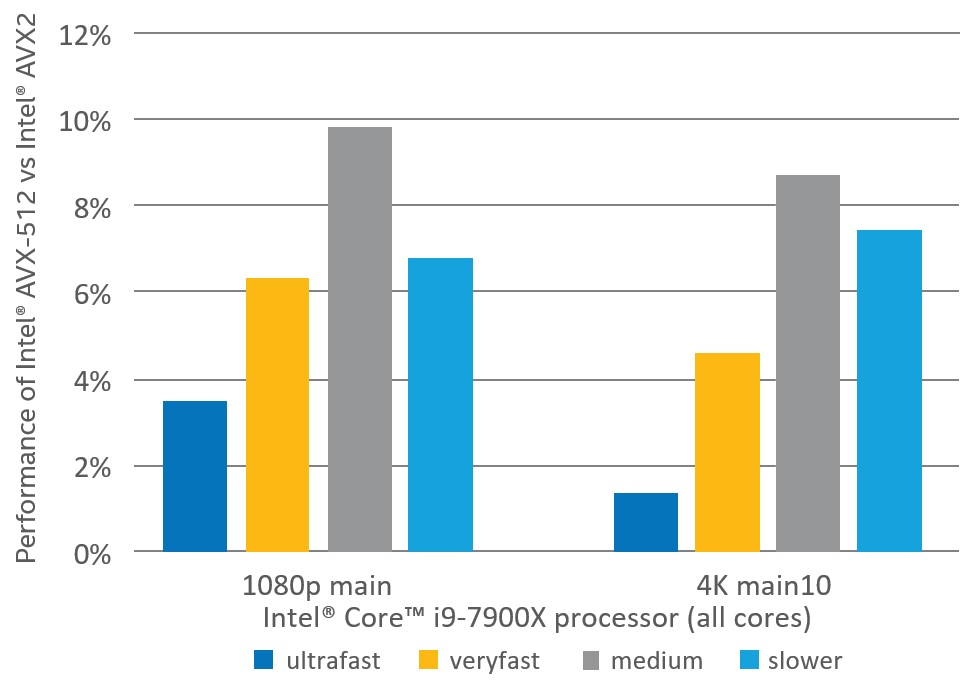 図 3. インテル® Core™ i9-7900X プロセッサーを搭載したワークステーション構成で測定された x265 の単一のインスタンスでインテル® AVX-512 カーネルを使用した場合のエンコーダー・パフォーマンス
図 3 の結果から、すべてのプロファイルとプリセットにおいて、インテル® AVX-512 カーネルを使用することでパフォーマンス・ゲインが得られることが分かります。インテル® Core™ i9-7900X プロセッサー・ベースのシステムでは、測定結果は大幅なクロック周波数の低下を示しませんでした。そのため、カーネルのサイクルカウントの向上は、エンコーダー・パフォーマンスに直接反映されます。エンコードごとのエンコーダー・パフォーマンスの比較では、インテル® AVX2 よりもインテル® AVX-512 のパフォーマンスが低くなるコマンドラインはありませんでした。
そのため、インテル® Core™ i9-7900X プロセッサーと周波数の低下がわずかである同様のシステムでは、x265 を使用する場合、すべてのエンコード・プロファイルと解像度でインテル® AVX-512 カーネルを有効にすることを推奨します。
図 3. インテル® Core™ i9-7900X プロセッサーを搭載したワークステーション構成で測定された x265 の単一のインスタンスでインテル® AVX-512 カーネルを使用した場合のエンコーダー・パフォーマンス
図 3 の結果から、すべてのプロファイルとプリセットにおいて、インテル® AVX-512 カーネルを使用することでパフォーマンス・ゲインが得られることが分かります。インテル® Core™ i9-7900X プロセッサー・ベースのシステムでは、測定結果は大幅なクロック周波数の低下を示しませんでした。そのため、カーネルのサイクルカウントの向上は、エンコーダー・パフォーマンスに直接反映されます。エンコードごとのエンコーダー・パフォーマンスの比較では、インテル® AVX2 よりもインテル® AVX-512 のパフォーマンスが低くなるコマンドラインはありませんでした。
そのため、インテル® Core™ i9-7900X プロセッサーと周波数の低下がわずかである同様のシステムでは、x265 を使用する場合、すべてのエンコード・プロファイルと解像度でインテル® AVX-512 カーネルを有効にすることを推奨します。
インテル® Xeon® スケーラブル・プロセッサー上でのエンコード
このセクションでは、2 基のインテル® Xeon® Platinum 8180 プロセッサーを搭載したハイエンドサーバー構成 (デュアルソケット構成、CPU ごとに 56 ハイパースレッディング・コア) で、インテル® AVX-512 により高速化された x265 を使用した場合の結果を示します。システム構成の詳細は、付録 C を参照してください。 8 スレッドと 16 スレッドを使用した x265 の単一インスタンスのパフォーマンス 図 4 は、Main プロファイルで 1080p ビデオのエンコードと Main10 プロファイルで 4K ビデオのエンコードにインテル® AVX-512 カーネルを使用する場合と、インテル® AVX2 命令のみのカーネルを使用する場合を比較した、x265 の単一インスタンスのパフォーマンスです。グラフでは、CPU 上のアクティブなコア数を増やした場合の影響を理解するため、インスタンスごとに 8 スレッドと 16 スレッドの 2 つの構成を示しています。インスタンスごとのスレッド数は、x265 ライブラリーの--pools オプションで制御します。
グラフから、この 2 つの構成では、Main10 プロファイルの 4K コンテンツのエンコードのほうが、Main プロファイルの 1080p コンテンツのエンコードよりもゲインが大きいことが分かります。また、使用した解像度とプロファイルでは、ピクセルごとの作業量が多いプリセット (veryslow のように効率の良いプリセット) のほうが、高速なプリセットよりも大きなゲインが得られました。実際、Main プロファイルの 1080p コンテンツでは、平均してパフォーマンスの低下が見られました。これは、特定の構成においてピクセルごとの作業量が多いほうがインテル® AVX-512 を使用することで優れた利点が得られるという前述の結果と一致しています。さらに、これらのプロファイルの S 字カーブ (簡略化のためここでは示していません) を調査したところ、4K Main10 の veryslow 設定以外のいくつかのエンコーダー・コマンドラインでは、インテル® AVX2 と比較してパフォーマンスが低下しました。
そのため、インテル® AVX-512 が有効なカーネルは、Main10 プロファイルの veryslow 設定で 4K コンテンツをエンコードする場合のみ使用することを推奨します。ほかのプリセットとエンコーダー設定では、クロック周波数の低下を相殺してサイクルカウントのゲインを達成するのに十分なピクセルごとの作業量が得られません。
図 4 からもう 1 つ分かることは、x265 の単一インスタンスで 8 スレッドを使用した場合のほうが、16 スレッドを使用した場合よりも一般にシステム全体のパフォーマンス・ゲインが大きくなることです。さらなる解析により、インテル® Xeon® Platinum 8180 プロセッサーでインテル® AVX-512 命令を使用するコア数が増えると、周波数がさらに低下し、インテル® AVX-512 命令の使用によるゲインが小さくなることが分かりました。通常のサーバーでは、エンコーダー・ベンダーはすべての利用可能な CPU コアを利用して、スループットを最大化しようとします。
このユースケースについては、セクション 4.3.2 で説明します。セクション 4.3.2 では、4K Main10 エンコードでサーバーを飽和させ、アクティブなコア数の増加により周波数がさらに低下してゲインが消滅するかどうかを調査します。
インテル® Xeon® Platinum 8180 プロセッサー
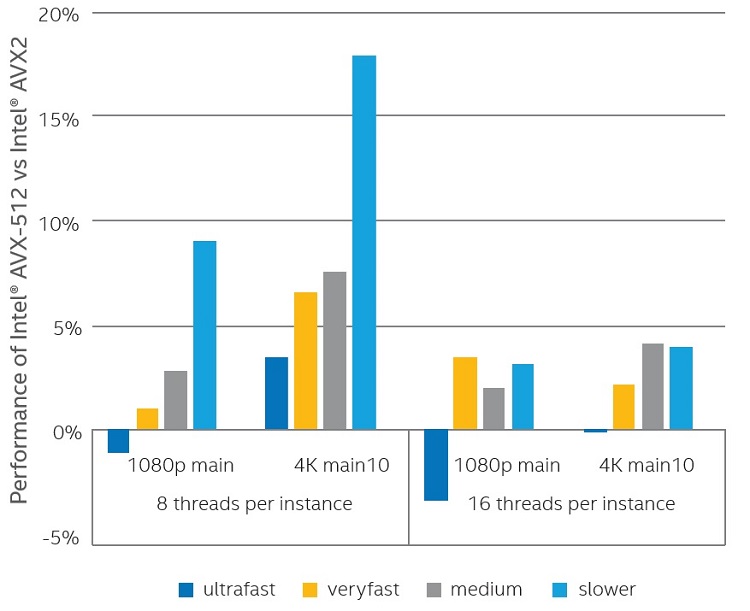 図 4. 2 基のインテル® Xeon® Platinum 8180 プロセッサーを搭載したサーバー構成において 8 または 16 スレッドでインテル® AVX-512 を使用した場合のインテル® AVX2 と比較した x265 の単一のインスタンスの相対パフォーマンス
x265 の複数のインスタンスでインテル® Xeon® Platinum 8180 プロセッサーを飽和させる
Main10 プロファイルで 4K をエンコードする場合に、アクティブなコア数を増やすことでパフォーマンスが低下するか調査するため、インスタンスごとに 16 スレッドを使用して、デュアルソケットのインテル® Xeon® Platinum 8180 プロセッサー・ベースのサーバーの一方または両方の CPU を飽和させました。インテル® AVX-512 を使用してすべての x265 インスタンスで同じクリップを異なるビットレートでエンコードした場合の合計 FPS を測定し、インテル® AVX2 を使用した場合と比較した結果を図 5 に 示します。
図 4. 2 基のインテル® Xeon® Platinum 8180 プロセッサーを搭載したサーバー構成において 8 または 16 スレッドでインテル® AVX-512 を使用した場合のインテル® AVX2 と比較した x265 の単一のインスタンスの相対パフォーマンス
x265 の複数のインスタンスでインテル® Xeon® Platinum 8180 プロセッサーを飽和させる
Main10 プロファイルで 4K をエンコードする場合に、アクティブなコア数を増やすことでパフォーマンスが低下するか調査するため、インスタンスごとに 16 スレッドを使用して、デュアルソケットのインテル® Xeon® Platinum 8180 プロセッサー・ベースのサーバーの一方または両方の CPU を飽和させました。インテル® AVX-512 を使用してすべての x265 インスタンスで同じクリップを異なるビットレートでエンコードした場合の合計 FPS を測定し、インテル® AVX2 を使用した場合と比較した結果を図 5 に 示します。
インテル® Xeon® Platinum 8180 プロセッサー – シングルまたはデュアルソケットの飽和
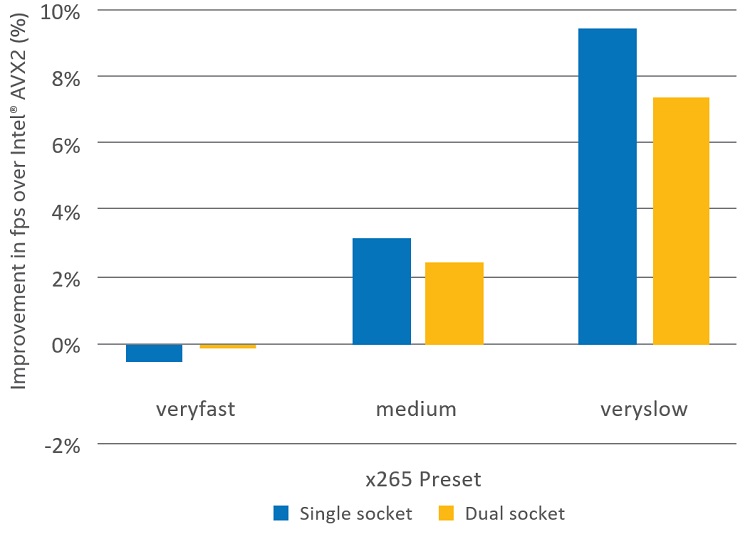 図 5. x265 インスタンスでのインテル® Xeon® Platinum 8180 プロセッサーのシングルソケットとデュアルソケットの飽和
図 5 では、CPU の一方または両方が飽和しても、Main10 の 4K ビデオのエンコードは、インテル® AVX2 を使用した場合と比較してパフォーマンス・ゲインが得られることを示しています。しかし、より少ないコアを使用する x265 の単一インスタンスの場合と比較すると、ゲインが小さいことが分かります。さらに、veryfast や medium などの低効率なプリセットでは、アクティブなコア数を増やすと周波数がさらに低下してゲインが消滅します。
これらの結果は、インテル® AVX-512 カーネルは Main10 で veryslow プリセットを使用して 4K コンテンツをエンコードする場合にのみ有効にすべきであるという我々の推奨を裏付けるものです。ピクセルごとの計算量が少ないプリセットでは、インテル® AVX-512 カーネルを使用すると、インテル® AVX2 カーネルを使用する場合よりもパフォーマンスが低下する可能性があります。
図 5. x265 インスタンスでのインテル® Xeon® Platinum 8180 プロセッサーのシングルソケットとデュアルソケットの飽和
図 5 では、CPU の一方または両方が飽和しても、Main10 の 4K ビデオのエンコードは、インテル® AVX2 を使用した場合と比較してパフォーマンス・ゲインが得られることを示しています。しかし、より少ないコアを使用する x265 の単一インスタンスの場合と比較すると、ゲインが小さいことが分かります。さらに、veryfast や medium などの低効率なプリセットでは、アクティブなコア数を増やすと周波数がさらに低下してゲインが消滅します。
これらの結果は、インテル® AVX-512 カーネルは Main10 で veryslow プリセットを使用して 4K コンテンツをエンコードする場合にのみ有効にすべきであるという我々の推奨を裏付けるものです。ピクセルごとの計算量が少ないプリセットでは、インテル® AVX-512 カーネルを使用すると、インテル® AVX2 カーネルを使用する場合よりもパフォーマンスが低下する可能性があります。
まとめと今後の課題
この記事では、新しいインテル® Xeon® Scalable プロセッサーで利用可能なインテル® AVX-512 命令を使用して、オープンソースの HEVC エンコーダー x265 を高速化した事例を紹介しました。この事例では、CPU 周波数の低下がサイクルカウントの利点によって相殺されるようにインテル® AVX-512 を使用した高速化に適したカーネルを選択し、エンコーダー・パフォーマンスを向上するためピクセルごとの計算量のバランスが良いエンコーダー構成を選択する必要がありました。推奨事項
メディアカーネルでインテル® AVX-512 を使用する場合、微妙なバランスが必要となります。我々の経験から、次のことを推奨します。- インテル® AVX-512 で高速化可能なカーネルを選択する際は、計算とメモリーの比率を考慮すべきです。この比率が高い場合、インテル® AVX-512 の使用を推奨します。また、インテル® AVX-512 を使用する場合、キャッシュライン境界をまたぐロードを回避するため、バッファーを 64B にアライメントします。
- デスクトップ SKU とワークステーション SKU (例えば、テストに使用したインテル® Core™ i9-7900X プロセッサー) では、CPU クロック周波数の低下がわずかであるため、すべてのエンコーダー構成でインテル® AVX-512 カーネルを有効にできます。
- サーバー SKU (例えば、テストに使用したインテル® Xeon® Platinum 8180 プロセッサー) では、アクティブなコア数に比例して、周波数の低下幅が大きくなります。そのため、インテル® AVX-512 では、クロックサイクルの利点が周波数のペナルティーを相殺することで、エンコーダーのパフォーマンスを向上できる、ピクセルごとの計算量が多い場合にのみ有効にすべきです。
具体的には、slower/veryslow プリセットを使用して Main10 プロファイルで 4K コンテンツをエンコードする場合にのみインテル® AVX-512 を使用することを推奨します。その他の設定 (解像度/プロファイル/プリセット) では、エンコーダーのパフォーマンスに影響する可能性があるため、インテル® AVX-512 カーネルの使用は推奨しません。
この記事で紹介する結果と推奨事項は、評価や実験的近似に限定されず、コミュニティー全体がインテル® AVX-512 を使用してメディア・ワークロードを高速化する利点を理解するのに役立つでしょう。今後の課題
インテル® AVX-512 を使用して x265 を高速化する作業を通して、今後取り組みが必要ないくつかの課題が明らかになりました。高速化されたカーネルは、公開メーリングリストから入手できます。インテル® AVX-512 によりさらなる高速化を実現するため、今後次の課題に取り組む必要があります: (1) x265 で利用可能なほかの解像度とプリセットのビデオでのインテル® AVX-512 の使用に関する詳細な解析、(2) CPU 周波数を監視してインテル® AVX-512 カーネルを動的に有効/無効にする方法の実現、および (3) ワーカースレッドを異なるタイプのスレッドに分割して、その一部のみがインテル® AVX-512 を実行することで CPU 周波数が低下するコアの数を制限するようにエンコーダーを再構築。我々は引き続きこれらのソリューションの開発に取り組み、オープンソースに貢献していきます。皆さんもぜひ http://x265.org (英語) でプロジェクトに貢献してください。謝辞
この取り組みの一部には、インテル社からのエンジニアリング臨時援助金が使用されました。この取り組みを通じて幅広いサポートを提供してくれた MulticoreWare の多くの開発者とエンジニアに感謝します。特に、Thomas A. Vaughan 氏のアドバイスと Min Chen 氏のアセンブリー・パッチに関する専門的な助言に謝意を表します。付録 A
A1 – Main プロファイルの 1 サイクルあたりの命令数 (IPC) ゲイン
| プリミティブ | IPC ゲイン | プリミティブ | IPC ゲイン | プリミティブ | IPC ゲイン | プリミティブ | IPC ゲイン |
|---|---|---|---|---|---|---|---|
| sad | 0.16% | i422 chroma_vss | 32.70% | i420 chroma_vpp | 23.19% | luma_vss | 43.18% |
| pixelavg _pp | 0.87% | luma_vss | 32.89% | addAvg | 23.37% | luma_vss | 43.35% |
| i444 chroma_vps | 1.14% | sad_x3 | 33.01% | addAvg | 23.38% | i444 chroma_hpp | 43.43% |
| i444 chroma_vps | 1.18% | luma_vps | 33.05% | i444 chroma_hps | 23.53% | ssd_s | 43.57% |
| pixelavg _pp | 1.41% | i420 chroma_hpp | 33.08% | i420 chroma_hps | 23.77% | luma_hps | 43.68% |
| convert_p2s | 1.95% | i444 chroma_hpp | 33.14% | var | 23.95% | luma_vss | 43.75% |
| i420 chroma_vps | 2.45% | sad_x4 | 33.14% | i420 chroma_hpp | 24.03% | luma_hps | 43.84% |
| i420 chroma_vps | 2.72% | i444 chroma_vss | 33.16% | i422 chroma_vpp | 24.11% | luma_hps | 43.94% |
| i422 chroma_hps | 2.83% | i420 chroma_vss | 33.16% | i444 chroma_vss | 24.15% | luma_vsp | 44.06% |
| i420 p2s | 3.21% | copy _ps | 33.33% | i422 chroma_vss | 24.15% | luma_vsp | 44.11% |
| i444 p2s | 3.21% | i420 copy _ps | 33.33% | i420 chroma_vss | 24.15% | sub_ps | 44.11% |
| sad_x3 | 3.29% | i444 chroma_vss | 33.34% | i420 chroma_vps | 24.20% | i444 chroma_hpp | 44.15% |
| i420 chroma_vps | 3.62% | i422 chroma_vss | 33.34% | i444 chroma_vpp | 24.20% | convert_p2s | 44.33% |
| sad_x4 | 4.50% | i420 chroma_vss | 33.34% | i420 chroma_vpp | 24.20% | i444 chroma_hpp | 44.35% |
| sad | 4.62% | i422 copy _ps | 33.43% | sad | 24.21% | luma_vss | 44.42% |
| i420 chroma_hps | 4.90% | i444 chroma_vss | 33.43% | i444 chroma_vps | 24.22% | luma_hps | 44.43% |
| i420 chroma_hps | 5.19% | i422 chroma_vss | 33.43% | i420 chroma_vps | 24.22% | luma_hpp | 44.48% |
| pixel_satd | 5.42% | i420 chroma_hpp | 33.55% | i444 chroma_hps | 24.25% | luma_vpp | 44.54% |
| i444 chroma_vps | 5.43% | i422 chroma_hpp | 33.57% | i420 chroma_hpp | 24.42% | luma_vss | 44.61% |
| i422 chroma_hps | 5.82% | dequant_normal | 33.60% | sad_x4 | 24.53% | cpy1Dto2D_shl | 44.61% |
| i444 chroma_vps | 6.78% | sad_x4 | 33.62% | i444 chroma_hps | 24.57% | luma_vsp | 44.62% |
| dct | 7.06% | i444 chroma_vss | 33.89% | i422 chroma_hps | 24.65% | luma_vsp | 44.66% |
| i444 chroma_hps | 7.08% | i420 chroma_vss | 33.89% | psyCost_pp | 24.89% | luma_vss | 44.70% |
| i444 chroma_hps | 7.26% | sad_x3 | 33.92% | i422 chroma_vps | 25.00% | luma_vpp | 44.74% |
| i422 chroma_vss | 8.85% | i420 pixel_satd | 34.01% | i444 chroma_vss | 25.17% | luma_vsp | 44.85% |
| luma_vss | 9.76% | i444 chroma_hps | 34.02% | i422 chroma_vss | 25.17% | i422 copy _sp | 45.20% |
| i422 chroma_hps | 10.27% | luma_vps | 34.04% | i420 chroma_vss | 25.17% | getResidual32 | 45.24% |
| i444 chroma_hps | 11.00% | i444 chroma_hpp | 34.20% | i422 chroma_vps | 25.66% | luma_vpp | 45.30% |
| i444 chroma_hps | 11.14% | i420 pixel_satd | 34.20% | luma_vps | 25.82% | luma_hps | 45.35% |
| sad | 11.26% | i420 chroma_hpp | 34.23% | i444 chroma_vps | 25.89% | i444 chroma_hpp | 45.41% |
| i420 chroma_hps | 11.38% | i444 chroma_vss | 34.43% | i444 chroma_vps | 25.92% | luma_hpp | 45.49% |
| pixel_sa8d | 11.55% | i422 chroma_vss | 34.43% | i420 chroma_hps | 25.95% | convert_p2s | 45.52% |
| i444 chroma_hps | 11.91% | i420 chroma_vss | 34.43% | i420 chroma_vps | 26.07% | luma_hps | 45.58% |
| luma_vpp | 11.96% | i422 chroma_vsp | 34.59% | convert_p2s | 26.25% | luma_vpp | 45.62% |
| i422 chroma_hps | 12.10% | i444 chroma_vss | 34.71% | i422 chroma_vps | 26.42% | convert_p2s | 45.62% |
| copy _pp | 12.54% | i444 chroma_vss | 34.76% | i444 chroma_vps | 26.56% | luma_vpp | 45.69% |
| ssd_s | 12.58% | addAvg | 34.88% | i444 chroma_vss | 26.71% | cpy2Dto1D_shl | 45.75% |
| i420 chroma_vps | 12.58% | addAvg | 35.14% | i422 chroma_vss | 26.71% | i422 addAvg | 45.76% |
| i444 chroma_hps | 12.79% | sad | 35.43% | i420 chroma_vss | 26.71% | convert_p2s | 46.00% |
| idct | 13.32% | ssd_ss | 35.45% | sad_x4 | 26.80% | i420 add_ps | 46.09% |
| luma_vps | 13.78% | i444 chroma_vss | 35.51% | i422 chroma_hpp | 27.06% | add_ps | 46.10% |
| i444 chroma_hps | 13.87% | i420 pixel_satd | 35.55% | i422 chroma_hps | 27.13% | luma_vsp | 46.14% |
| sad | 13.88% | pixelavg _pp | 35.56% | luma_hpp | 27.15% | luma_hps | 46.29% |
| copy _cnt | 14.25% | luma_vpp | 35.62% | i420 pixel_satd | 27.23% | luma_vss | 46.31% |
| luma_vpp | 14.28% | luma_vpp | 36.21% | i444 chroma_vss | 27.24% | i444 chroma_vsp | 46.52% |
| pixel_satd | 14.45% | i420 chroma_hpp | 36.45% | i422 chroma_vss | 27.24% | i422 chroma_vsp | 46.52% |
| idct | 14.49% | i422 chroma_hpp | 36.65% | luma_hpp | 27.29% | i420 chroma_vsp | 46.52% |
| pixel_satd | 14.92% | i422 chroma_hpp | 36.76% | luma_vps | 27.45% | luma_hps | 46.65% |
| pixel_satd | 14.99% | sad | 36.76% | psyCost_pp | 27.62% | pixelavg _pp | 46.67% |
| sad | 15.21% | i422 chroma_hpp | 36.81% | luma_vsp | 27.72% | luma_vss | 46.88% |
| idct | 15.23% | copy _pp | 36.82% | i422 chroma_hps | 28.00% | i422 addAvg | 46.88% |
| sad_x3 | 15.32% | pixelavg _pp | 36.84% | pixel_satd | 28.50% | luma_hps | 46.90% |
| i444 chroma_vpp | 15.47% | convert_p2s | 36.87% | cpy2Dto1D_shl | 28.69% | luma_vsp | 46.97% |
| i422 chroma_vpp | 15.47% | i420 p2s | 36.87% | luma_vps | 28.71% | i422 p2s | 47.10% |
| i420 chroma_vpp | 15.47% | i444 p2s | 36.87% | i444 chroma_hpp | 28.78% | copy _pp | 47.11% |
| pixel_satd | 15.52% | i444 chroma_hpp | 37.07% | i420 pixel_satd | 28.80% | luma_vss | 47.64% |
| pixel_satd | 15.62% | luma_vpp | 37.11% | i422 pixel_satd | 28.81% | i444 chroma_hpp | 47.83% |
| pixel_satd | 15.66% | luma_vss | 37.49% | i422 pixel_satd | 28.95% | i422 addAvg | 47.85% |
| sad_x3 | 15.70% | addAvg | 37.76% | luma_vss | 29.26% | luma_hps | 48.46% |
| pixel_satd | 15.75% | i444 chroma_vps | 37.90% | i444 chroma_vss | 29.29% | copy _ps | 48.57% |
| i420 chroma_hps | 15.83% | i444 chroma_vss | 38.04% | i420 chroma_hps | 29.42% | sub_ps | 48.83% |
| copy _pp | 15.93% | i444 chroma_vps | 38.05% | luma_vpp | 29.43% | luma_hpp | 48.97% |
| luma_vpp | 16.10% | i444 chroma_vps | 38.23% | scale1D_128to64 | 29.50% | i422 add_ps | 49.02% |
| nquant | 16.33% | sad | 38.42% | luma_vss | 29.59% | i444 chroma_vsp | 49.43% |
| sad | 16.35% | i444 chroma_hpp | 38.45% | i444 chroma_vpp | 29.69% | i420 sub_ps | 49.46% |
| i444 chroma_vpp | 16.39% | Weight_sp | 38.48% | i422 chroma_vpp | 29.69% | add_ps | 49.50% |
| i420 chroma_hps | 16.60% | i444 chroma_hpp | 38.55% | i420 chroma_vpp | 29.69% | i422 sub_ps | 49.52% |
| i444 chroma_vpp | 17.02% | sad | 38.56% | i422 chroma_hps | 29.71% | i420 addAvg | 49.74% |
| i422 chroma_vpp | 17.02% | luma_hpp | 38.79% | i422 pixel_satd | 29.75% | convert_p2s | 49.75% |
| i420 chroma_vpp | 17.02% | pixel_satd | 39.15% | i444 chroma_vpp | 29.82% | i422 p2s | 49.75% |
| pixel_satd | 17.08% | luma_hpp | 39.21% | i422 chroma_vpp | 29.82% | i444 p2s | 49.75% |
| luma_vps | 17.10% | i444 chroma_hpp | 39.30% | luma_vss | 29.91% | luma_vss | 49.84% |
| luma_vps | 17.36% | i444 chroma_vps | 39.39% | i444 chroma_vss | 29.92% | luma_hpp | 50.00% |
| i444 chroma_vss | 17.55% | addAvg | 39.51% | i422 chroma_vss | 29.92% | copy _sp | 50.11% |
| i420 chroma_vss | 17.55% | i420 chroma_hpp | 39.55% | i420 chroma_vss | 29.92% | luma_vss | 50.22% |
| pixel_satd | 17.59% | i422 pixel_satd | 39.57% | luma_vps | 30.19% | luma_hpp | 50.61% |
| pixel_satd | 17.66% | i422 chroma_hpp | 39.61% | sad_x4 | 30.24% | luma_hpp | 51.19% |
| i444 chroma_vss | 18.42% | convert_p2s | 39.78% | sad | 30.30% | i444 chroma_vsp | 51.23% |
| i422 chroma_vss | 18.42% | i420 p2s | 39.78% | luma_vps | 30.37% | luma_hpp | 51.70% |
| i420 chroma_vss | 18.42% | i422 p2s | 39.78% | luma_vps | 30.39% | nonPsyRdoQuant | 51.74% |
| i444 chroma_vpp | 18.49% | i444 p2s | 39.78% | i444 chroma_vpp | 30.39% | i444 chroma_vsp | 52.08% |
| i420 chroma_vpp | 18.49% | copy _sp | 39.93% | i422 chroma_vpp | 30.39% | copy _pp | 52.17% |
| luma_vps | 18.50% | i420 addAvg | 40.02% | i420 chroma_vpp | 30.39% | i444 chroma_vsp | 52.22% |
| luma_vpp | 18.51% | luma_hps | 40.04% | ssd_ss | 30.44% | i444 chroma_vsp | 52.28% |
| sad_x3 | 18.99% | i444 chroma_hpp | 40.07% | i422 chroma_hpp | 30.45% | nonPsyRdoQuant | 52.32% |
| copy _pp | 19.76% | addAvg | 40.64% | i420 pixel_satd | 30.53% | i422 copy _ss | 52.45% |
| luma_vss | 19.80% | luma_vsp | 40.87% | i422 chroma_vpp | 30.54% | nonPsyRdoQuant | 52.56% |
| pixel_satd | 19.89% | i444 chroma_vsp | 40.96% | i444 chroma_hpp | 30.54% | i444 chroma_vsp | 52.77% |
| sad | 20.09% | i420 chroma_vsp | 40.96% | i422 chroma_hpp | 30.56% | i422 chroma_vsp | 52.77% |
| sad_x3 | 20.26% | luma_vss | 41.01% | i444 chroma_hpp | 30.63% | blockfill_s | 52.93% |
| i444 chroma_hps | 20.52% | i420 copy _sp | 41.12% | i420 chroma_hpp | 30.85% | i444 chroma_vsp | 53.30% |
| i420 chroma_hps | 20.80% | copy _cnt | 41.14% | luma_vsp | 30.95% | i422 chroma_vsp | 53.30% |
| psyCost_pp | 21.15% | luma_vsp | 41.16% | sad_x4 | 30.95% | i420 chroma_vsp | 53.30% |
| i444 chroma_hps | 21.17% | Weight_pp | 41.23% | i422 chroma_vss | 30.99% | i422 chroma_vsp | 53.36% |
| pixel_satd | 21.19% | luma_hps | 41.42% | i444 chroma_hps | 31.12% | i444 chroma_vsp | 54.34% |
| pixel_satd | 21.21% | addAvg | 41.84% | i444 chroma_vpp | 31.17% | i422 chroma_vsp | 54.34% |
| quant | 21.23% | i420 addAvg | 41.87% | i444 chroma_vpp | 31.20% | i420 chroma_vsp | 54.34% |
| sad_x3 | 21.29% | luma_vsp | 41.99% | sad | 31.29% | psyRdoQuant | 54.44% |
| i444 chroma_vpp | 21.42% | luma_hps | 42.05% | luma_vsp | 31.33% | luma_hpp | 54.62% |
| i422 chroma_vpp | 21.42% | convert_p2s | 42.13% | sad_x3 | 31.34% | i444 chroma_vsp | 54.64% |
| i420 chroma_vpp | 21.42% | i420 p2s | 42.13% | i422 pixel_satd | 31.46% | i420 chroma_vsp | 54.64% |
| i420 chroma_vps | 21.60% | i422 p2s | 42.13% | luma_hps | 31.52% | luma_hpp | 54.78% |
| pixel_satd | 21.61% | i444 p2s | 42.13% | i444 chroma_vpp | 31.57% | luma_hpp | 55.06% |
| i444 chroma_vps | 21.69% | i444 chroma_vsp | 42.31% | pixelavg _pp | 31.62% | luma_hpp | 55.40% |
| i422 chroma_hps | 21.99% | i422 chroma_vsp | 42.31% | luma_vps | 31.76% | copy _pp | 55.41% |
| i420 addAvg | 22.01% | i420 chroma_vsp | 42.31% | i444 chroma_hps | 31.78% | psyRdoQuant | 55.70% |
| luma_vsp | 22.09% | luma_vsp | 42.35% | sad_x3 | 31.95% | psyRdoQuant | 55.72% |
| i444 chroma_vps | 22.27% | i420 chroma_hpp | 42.43% | i444 chroma_vss | 31.96% | var | 55.75% |
| i422 chroma_vps | 22.41% | nonPsyRdoQuant | 42.51% | i420 chroma_vss | 31.96% | copy _ss | 56.00% |
| sad_x4 | 22.44% | luma_hps | 42.54% | i422 chroma_vss | 32.01% | i444 chroma_vsp | 56.36% |
| var | 22.51% | addAvg | 42.56% | i444 chroma_hpp | 32.12% | i422 chroma_vsp | 56.36% |
| i444 chroma_vpp | 22.64% | luma_hps | 42.58% | var | 32.17% | i420 chroma_vsp | 56.36% |
| i420 chroma_vpp | 22.64% | luma_vss | 42.82% | i420 chroma_hpp | 32.32% | i420 copy _ss | 56.63% |
| sad_x4 | 22.84% | i422 addAvg | 42.93% | i444 chroma_hps | 32.44% | i444 chroma_vsp | 57.60% |
| i444 chroma_vpp | 22.87% | luma_vpp | 42.97% | luma_vsp | 32.61% | i420 chroma_vsp | 57.60% |
| i422 chroma_vpp | 22.87% | dequant_scaling | 42.98% | i444 chroma_vss | 32.67% | copy _pp | 58.33% |
| i422 chroma_hpp | 22.92% | luma_hpp | 42.99% | i420 chroma_vss | 32.67% | copy _ss | 60.09% |
| sad_x4 | 23.09% | i444 chroma_vsp | 43.05% | i444 chroma_vss | 32.69% | psyRdoQuant | 62.80% |
| i444 chroma_vpp | 23.19% | i422 chroma_vsp | 43.05% | i422 chroma_vss | 32.69% | i444 chroma_vsp | 62.98% |
| i420 chroma_vss | 32.69% | i420 chroma_vsp | 62.98% |
A2 – Main10 プロファイルの IPC ゲイン
| プリミティブ | IPC ゲイン | プリミティブ | IPC ゲイン | プリミティブ | IPC ゲイン | プリミティブ | IPC ゲイン |
|---|---|---|---|---|---|---|---|
| convert_p2s | 1.26% | i422 chroma_hps | 39.92% | i422 chroma_vpp | 29.64% | i444 chroma_hpp | 49.20% |
| i420 p2s | 1.26% | i422 p2s | 40.30% | i420 chroma_vpp | 29.64% | i444 chroma_hps | 49.45% |
| i444 p2s | 1.26% | luma_hpp | 40.35% | i444 chroma_vsp | 29.82% | cpy2Dto1D_shl | 49.70% |
| addAvg | 1.86% | i422 chroma_hpp | 40.52% | i422 chroma_vsp | 29.82% | luma_hvpp | 49.80% |
| addAvg | 6.88% | copy _cnt | 40.55% | i420 chroma_vsp | 29.82% | luma_vss | 49.84% |
| dct | 7.06% | luma_vpp | 40.58% | luma_vss | 29.91% | i420 chroma_hps | 49.85% |
| sad_x3 | 7.65% | luma_vsp | 40.59% | i444 chroma_vss | 29.92% | convert_p2s | 49.87% |
| sad | 7.74% | i444 chroma_vps | 40.60% | i422 chroma_vss | 29.92% | i420 p2s | 49.87% |
| sad | 8.29% | i422 chroma_vps | 40.60% | i420 chroma_vss | 29.92% | i422 p2s | 49.87% |
| i420 addAvg | 8.36% | i420 chroma_vps | 40.60% | i444 chroma_vps | 29.93% | i422 p2s | 49.87% |
| sad_x3 | 8.77% | sad_x3 | 40.64% | i422 chroma_vps | 29.93% | i444 p2s | 49.87% |
| luma_vss | 9.76% | nonPsyRdoQuant | 40.70% | i420 chroma_vps | 29.93% | luma_hps | 49.94% |
| intra_pred_ang27 | 9.79% | add_ps | 40.71% | luma_vsp | 30.06% | i422 chroma_hps | 50.07% |
| cpy2Dto1D_shl | 10.13% | sad_x4 | 40.73% | i444 chroma_vsp | 30.11% | i444 chroma_hpp | 50.13% |
| sad_x3 | 10.81% | luma_vpp | 40.73% | i422 chroma_vsp | 30.11% | luma_vss | 50.22% |
| sad_x4 | 10.96% | copy _pp | 40.81% | i420 chroma_vsp | 30.11% | luma_hpp | 50.25% |
| i420 addAvg | 11.05% | i422 chroma_vps | 40.88% | pixel_satd | 30.30% | i420 chroma_vpp | 50.28% |
| pixel_satd | 11.05% | luma_vss | 41.01% | i422 pixel_satd | 30.30% | luma_hps | 50.67% |
| i420 pixel_satd | 11.05% | i444 chroma_vsp | 41.02% | i422 pixel_satd | 30.35% | addAvg | 50.67% |
| i422 pixel_satd | 11.05% | i420 chroma_vsp | 41.02% | add_ps | 30.69% | i422 addAvg | 50.67% |
| luma_vsp | 12.64% | i444 chroma_vsp | 41.05% | sad | 30.94% | luma_hpp | 50.75% |
| copy _cnt | 13.29% | i420 chroma_vsp | 41.05% | dequant_normal | 31.10% | i420 chroma_hpp | 50.82% |
| idct | 13.32% | sad | 41.06% | sad | 31.37% | copy _pp | 50.95% |
| i444 chroma_vps | 14.44% | intra_pred_ang34 | 41.06% | pixel_satd | 31.43% | i422 addAvg | 50.99% |
| i422 chroma_vps | 14.44% | convert_p2s | 41.09% | i420 pixel_satd | 31.43% | luma_hps | 51.17% |
| i420 chroma_vps | 14.44% | i444 p2s | 41.09% | i422 pixel_satd | 31.43% | i422 chroma_hpp | 51.22% |
| idct | 14.49% | nonPsyRdoQuant | 41.21% | i444 chroma_vpp | 31.60% | i444 chroma_hpp | 51.37% |
| i444 chroma_vpp | 14.84% | sad_x4 | 41.22% | i422 chroma_vss | 31.76% | luma_hpp | 51.48% |
| idct | 15.23% | i422 chroma_vpp | 41.25% | i444 chroma_vss | 31.96% | luma_hps | 51.57% |
| luma_vsp | 15.24% | i420 chroma_vpp | 41.25% | i420 chroma_vss | 31.96% | copy _ss | 51.58% |
| sad_x3 | 15.53% | i420 chroma_vpp | 41.36% | sad | 31.99% | luma_hpp | 51.63% |
| addAvg | 15.60% | i444 chroma_vsp | 41.40% | psyCost_pp | 32.12% | luma_hps | 51.64% |
| i422 chroma_vpp | 15.71% | luma_vpp | 41.43% | i420 chroma_hps | 32.32% | luma_hps | 51.65% |
| i420 chroma_vpp | 15.71% | luma_hvpp | 41.46% | i422 addAvg | 32.46% | luma_hps | 51.70% |
| addAvg | 15.90% | luma_vpp | 41.48% | i422 chroma_vss | 32.62% | luma_hps | 51.81% |
| i422 chroma_vpp | 16.07% | i444 chroma_vsp | 41.51% | i444 chroma_vss | 32.67% | i422 chroma_hpp | 51.86% |
| intra_pred_ang25 | 16.22% | luma_hvpp | 41.54% | i420 chroma_vss | 32.67% | luma_hps | 51.89% |
| nquant | 16.33% | intra_pred_ang11 | 41.55% | i444 chroma_vss | 32.69% | addAvg | 51.89% |
| sad_x4 | 16.42% | convert_p2s | 41.58% | i422 chroma_vss | 32.69% | i420 addAvg | 51.89% |
| luma_vsp | 16.55% | sad_x4 | 41.71% | i420 chroma_vss | 32.69% | i422 addAvg | 51.89% |
| i420 addAvg | 17.12% | sad_x4 | 41.71% | luma_vss | 32.89% | luma_hps | 51.93% |
| sad_x4 | 17.33% | luma_vsp | 41.78% | i444 chroma_vsp | 33.14% | luma_hps | 51.99% |
| i444 chroma_vss | 17.55% | sad_x4 | 41.83% | i422 chroma_vsp | 33.14% | i444 chroma_hpp | 52.16% |
| i420 chroma_vss | 17.55% | i444 chroma_vsp | 42.01% | i444 chroma_vss | 33.16% | i422 copy _sp | 52.45% |
| i444 chroma_vps | 17.88% | i444 chroma_vsp | 42.08% | i420 chroma_vss | 33.16% | i422 copy _ps | 52.45% |
| i422 chroma_vps | 17.88% | i422 chroma_vsp | 42.08% | convert_p2s | 33.27% | i422 copy _ss | 52.45% |
| i420 chroma_vps | 17.88% | nonPsyRdoQuant | 42.13% | i444 chroma_vss | 33.34% | i444 chroma_hps | 52.94% |
| pixel_satd | 18.02% | pixelavg _pp | 42.17% | i422 chroma_vss | 33.34% | copy _ss | 53.20% |
| i422 addAvg | 18.13% | i422 chroma_vpp | 42.20% | i420 chroma_vss | 33.34% | i420 chroma_hps | 53.22% |
| i444 chroma_vss | 18.42% | i420 chroma_vpp | 42.20% | i444 chroma_vss | 33.43% | i422 chroma_hps | 53.27% |
| i422 chroma_vss | 18.42% | luma_vps | 42.30% | i422 chroma_vss | 33.43% | i420 chroma_hpp | 53.48% |
| i420 chroma_vss | 18.42% | sub_ps | 42.52% | pixelavg _pp | 33.45% | copy _pp | 53.53% |
| addAvg | 19.50% | luma_vsp | 42.55% | pixel_satd | 33.45% | i422 chroma_hpp | 53.81% |
| i444 chroma_vps | 19.54% | luma_hvpp | 42.65% | i420 pixel_satd | 33.45% | i422 chroma_hpp | 53.89% |
| i422 chroma_vps | 19.54% | pixelavg _pp | 42.65% | addAvg | 33.46% | i444 chroma_hpp | 54.31% |
| i420 chroma_vps | 19.54% | luma_vps | 42.72% | luma_vsp | 33.47% | ssd_ss | 54.69% |
| sad_x3 | 19.75% | convert_p2s | 42.77% | sad_x4 | 33.51% | i422 chroma_hpp | 54.77% |
| luma_vss | 19.80% | luma_vss | 42.82% | i444 chroma_vsp | 33.79% | i420 chroma_hpp | 55.18% |
| i422 pixel_satd | 19.95% | luma_vsp | 43.05% | i422 chroma_vsp | 33.79% | luma_hpp | 55.53% |
| pixel_satd | 20.02% | convert_p2s | 43.11% | i420 chroma_vsp | 33.79% | i444 chroma_hpp | 55.56% |
| i420 pixel_satd | 20.02% | i444 chroma_hpp | 43.15% | i444 chroma_vss | 33.89% | i444 chroma_hpp | 55.78% |
| i422 pixel_satd | 20.02% | luma_vsp | 43.17% | i420 chroma_vss | 33.89% | i444 chroma_hpp | 55.94% |
| i444 chroma_vps | 20.09% | luma_vss | 43.18% | luma_vsp | 34.08% | luma_hpp | 55.96% |
| i420 chroma_vps | 20.09% | luma_vsp | 43.22% | sub_ps | 34.13% | copy _sp | 56.00% |
| i422 chroma_vss | 20.53% | luma_hvpp | 43.24% | i444 chroma_vsp | 34.18% | copy _ps | 56.00% |
| sad_x4 | 20.69% | luma_vss | 43.35% | i420 chroma_vsp | 34.18% | i444 chroma_hpp | 56.07% |
| i444 chroma_vps | 20.86% | luma_vsp | 43.36% | i444 chroma_vsp | 34.22% | luma_hpp | 56.16% |
| i422 chroma_vps | 20.86% | i420 chroma_hpp | 43.38% | i422 chroma_vsp | 34.22% | i420 copy _sp | 56.63% |
| i444 chroma_vpp | 20.98% | cpy1Dto2D_shl | 43.50% | i420 chroma_vsp | 34.22% | i420 copy _ps | 56.63% |
| quant | 21.23% | luma_vsp | 43.50% | i444 chroma_vss | 34.43% | i420 copy _ss | 56.63% |
| i422 chroma_vpp | 21.45% | luma_vpp | 43.51% | i422 chroma_vss | 34.43% | i422 chroma_hpp | 57.32% |
| sad | 21.61% | copy _pp | 43.54% | i420 chroma_vss | 34.43% | i444 chroma_hps | 57.33% |
| i444 chroma_vpp | 21.78% | luma_hvpp | 43.57% | pixel_satd | 34.59% | luma_hpp | 57.40% |
| i444 chroma_vps | 22.06% | luma_vpp | 43.58% | i444 chroma_vss | 34.71% | i420 chroma_hps | 57.97% |
| i420 chroma_vps | 22.06% | luma_hvpp | 43.60% | i444 chroma_vss | 34.76% | luma_hpp | 58.55% |
| i444 chroma_vsp | 22.12% | luma_vss | 43.75% | intra_pred_ang10 | 34.76% | i444 chroma_hps | 59.21% |
| i422 chroma_vsp | 22.12% | luma_vps | 43.77% | i444 chroma_vps | 34.80% | i420 chroma_hps | 59.46% |
| i420 chroma_vsp | 22.12% | i444 chroma_vsp | 43.80% | i444 chroma_vps | 34.98% | blockfill_s | 59.53% |
| i444 chroma_vsp | 22.14% | i420 chroma_vsp | 43.80% | luma_vps | 35.07% | luma_hpp | 59.56% |
| i422 chroma_vsp | 22.14% | pixelavg _pp | 43.94% | i444 chroma_vps | 35.34% | i422 chroma_hps | 59.75% |
| i420 chroma_vsp | 22.14% | psyRdoQuant | 44.02% | Weight_pp | 35.37% | copy _sp | 60.09% |
| i422 chroma_vpp | 22.28% | sad_x3 | 44.17% | i444 chroma_vss | 35.51% | copy _ps | 60.09% |
| i420 chroma_vpp | 22.28% | pixelavg _pp | 44.23% | luma_vps | 35.63% | luma_hps | 60.23% |
| i444 chroma_vpp | 22.28% | luma_hvpp | 44.24% | i422 chroma_hps | 35.68% | psyRdoQuant | 60.25% |
| i422 chroma_vpp | 22.35% | luma_hvpp | 44.28% | i444 chroma_vps | 36.38% | luma_hpp | 60.26% |
| ssd_ss | 22.60% | luma_vsp | 44.31% | i422 chroma_vss | 36.56% | i444 chroma_hps | 60.28% |
| i444 chroma_vpp | 23.06% | dequant_scaling | 44.37% | sad | 36.66% | i420 chroma_hps | 60.48% |
| sad_x4 | 23.09% | convert_p2s | 44.40% | luma_vpp | 36.68% | luma_hps | 60.76% |
| luma_vpp | 23.67% | luma_vpp | 44.41% | i444 chroma_vpp | 36.70% | copy _pp | 60.87% |
| luma_vpp | 23.82% | luma_vss | 44.42% | luma_vsp | 36.71% | i444 chroma_hps | 60.92% |
| i444 chroma_vpp | 23.84% | sad_x4 | 44.42% | sad_x3 | 36.75% | i422 chroma_hps | 61.09% |
| i444 chroma_vss | 24.15% | luma_vpp | 44.60% | sad_x4 | 36.78% | luma_hpp | 61.28% |
| i422 chroma_vss | 24.15% | luma_vss | 44.61% | pixel_satd | 36.88% | i444 chroma_hpp | 61.38% |
| i420 chroma_vss | 24.15% | luma_hvpp | 44.61% | i422 chroma_vpp | 36.91% | luma_hpp | 61.43% |
| intra_pred_ang9 | 24.37% | getResidual32 | 44.64% | copy _pp | 36.96% | luma_hpp | 61.44% |
| i444 chroma_vpp | 24.41% | luma_hpp | 44.68% | addAvg | 37.08% | i422 chroma_hps | 61.55% |
| luma_vpp | 24.48% | luma_vss | 44.70% | sad_x4 | 37.09% | luma_hpp | 61.58% |
| i422 addAvg | 24.62% | luma_hvpp | 44.73% | i420 chroma_vpp | 37.29% | luma_hpp | 62.26% |
| psyCost_pp | 24.88% | i444 chroma_vsp | 44.76% | i422 chroma_vpp | 37.36% | i422 chroma_hps | 62.31% |
| i420 chroma_vpp | 24.90% | i422 chroma_vsp | 44.76% | i420 chroma_vpp | 37.36% | luma_hpp | 62.35% |
| i422 chroma_vpp | 25.11% | i420 chroma_vsp | 44.76% | luma_vss | 37.49% | i420 chroma_hpp | 62.39% |
| i420 chroma_vpp | 25.11% | sad_x4 | 44.85% | luma_vpp | 37.53% | i420 chroma_hps | 62.39% |
| i444 chroma_vps | 25.17% | luma_hvpp | 45.15% | i444 chroma_vps | 37.54% | i444 chroma_hpp | 62.46% |
| i422 chroma_vps | 25.17% | luma_vps | 45.19% | i422 chroma_vps | 37.54% | luma_hpp | 62.63% |
| i420 chroma_vps | 25.17% | i422 chroma_hpp | 45.23% | i420 chroma_vps | 37.54% | i444 chroma_hps | 62.88% |
| i444 chroma_vss | 25.17% | intra_pred_dc | 45.26% | i444 chroma_vpp | 37.59% | i420 chroma_hps | 62.95% |
| i422 chroma_vss | 25.17% | sad | 45.31% | i420 chroma_vpp | 37.59% | luma_hpp | 63.07% |
| i420 chroma_vss | 25.17% | luma_vps | 45.36% | i444 chroma_vps | 37.59% | i444 chroma_hps | 63.15% |
| i422 chroma_vps | 25.28% | psyRdoQuant | 45.40% | i422 chroma_vps | 37.59% | luma_hps | 63.16% |
| i444 chroma_vps | 25.97% | i420 add_ps | 45.40% | pixel_satd | 37.60% | i420 chroma_hpp | 63.34% |
| i422 chroma_vps | 25.97% | pixelavg _pp | 45.52% | i444 chroma_vps | 37.60% | luma_hpp | 63.61% |
| i420 chroma_vps | 25.97% | addAvg | 45.54% | i420 chroma_vps | 37.60% | i420 chroma_hps | 63.85% |
| luma_vpp | 26.22% | i420 addAvg | 45.54% | i444 chroma_vsp | 37.66% | luma_hpp | 63.91% |
| sad | 26.25% | i422 addAvg | 45.54% | i422 chroma_vps | 37.68% | i420 chroma_hpp | 64.12% |
| psyCost_pp | 26.30% | i444 chroma_vsp | 45.57% | i444 chroma_vpp | 37.69% | i444 chroma_hps | 64.15% |
| i444 chroma_vsp | 26.38% | i422 chroma_vsp | 45.57% | i444 chroma_vps | 37.71% | i444 chroma_hpp | 64.23% |
| i420 chroma_vsp | 26.38% | i420 chroma_vsp | 45.57% | i420 chroma_vps | 37.71% | i422 chroma_hpp | 64.39% |
| i420 addAvg | 26.39% | luma_vps | 45.58% | convert_p2s | 37.73% | i422 chroma_hpp | 64.56% |
| i422 addAvg | 26.39% | pixelavg _pp | 45.61% | i420 p2s | 37.73% | i444 chroma_hps | 64.84% |
| pixel_satd | 26.62% | luma_vps | 45.62% | i422 p2s | 37.73% | i422 chroma_hps | 64.87% |
| i444 chroma_vss | 26.71% | luma_vps | 45.64% | i444 p2s | 37.73% | i444 chroma_hpp | 64.92% |
| i422 chroma_vss | 26.71% | sad_x3 | 45.65% | i444 chroma_vpp | 37.74% | i420 chroma_hps | 64.93% |
| i420 chroma_vss | 26.71% | i422 add_ps | 45.68% | i444 chroma_vpp | 37.76% | i422 chroma_hpp | 65.05% |
| luma_vsp | 26.77% | addAvg | 45.72% | addAvg | 37.80% | i444 chroma_hps | 65.06% |
| luma_vps | 27.04% | i420 addAvg | 45.72% | i422 chroma_vpp | 37.99% | i420 chroma_hpp | 65.14% |
| luma_vpp | 27.10% | pixelavg _pp | 45.80% | i444 chroma_vss | 38.04% | i422 chroma_hps | 65.35% |
| i444 chroma_vss | 27.24% | i444 chroma_hpp | 45.95% | i420 chroma_hpp | 38.04% | i422 chroma_hps | 65.63% |
| i422 chroma_vss | 27.24% | psyRdoQuant | 45.96% | luma_vps | 38.08% | i444 chroma_hps | 65.72% |
| i422 chroma_vps | 27.26% | luma_vsp | 45.97% | i444 chroma_vpp | 38.09% | i422 chroma_hpp | 65.80% |
| i420 addAvg | 27.28% | sad | 46.04% | i444 chroma_vpp | 38.27% | i444 chroma_hpp | 65.88% |
| i422 addAvg | 27.28% | luma_hvpp | 46.17% | i422 chroma_vpp | 38.27% | i420 chroma_hpp | 65.92% |
| addAvg | 27.55% | luma_vss | 46.31% | i444 chroma_hps | 38.30% | i420 chroma_hpp | 65.94% |
| i422 chroma_vpp | 27.71% | sad_x3 | 46.36% | intra_pred_ang2 | 38.34% | i444 chroma_hps | 66.03% |
| i420 chroma_vpp | 27.71% | sad_x3 | 46.42% | i444 chroma_hps | 38.37% | i422 chroma_hps | 66.03% |
| pixel_satd | 27.93% | luma_vps | 46.44% | i444 chroma_vpp | 38.48% | i420 chroma_hps | 66.15% |
| ssd_s | 28.04% | luma_hpp | 46.46% | copy _pp | 38.51% | i422 chroma_hpp | 66.20% |
| pixel_satd | 28.10% | i444 chroma_vsp | 46.66% | addAvg | 38.54% | i422 chroma_hps | 66.20% |
| pixelavg _pp | 28.47% | sad_x3 | 46.71% | nonPsyRdoQuant | 38.57% | i420 chroma_hps | 66.29% |
| i420 pixel_satd | 28.54% | luma_hpp | 46.82% | sad_x3 | 38.74% | i422 chroma_hpp | 66.32% |
| i422 pixel_satd | 28.54% | luma_vss | 46.88% | sad_x3 | 38.80% | i444 chroma_hpp | 66.38% |
| pixel_satd | 28.56% | i422 chroma_hps | 46.99% | sad | 38.84% | i444 chroma_vpp | 66.41% |
| i420 pixel_satd | 28.56% | intra_pred_ang26 | 47.26% | Weight_sp | 38.86% | i444 chroma_hps | 66.50% |
| i422 pixel_satd | 28.56% | luma_vps | 47.31% | pixel_satd | 38.88% | i444 chroma_vpp | 66.61% |
| i444 chroma_vps | 28.75% | luma_hvpp | 47.44% | i420 pixel_satd | 38.88% | i444 chroma_vpp | 66.63% |
| luma_vps | 28.78% | pixelavg _pp | 47.50% | copy _pp | 38.96% | i444 chroma_hps | 66.64% |
| luma_vps | 28.82% | luma_vss | 47.64% | i422 sub_ps | 39.19% | i444 chroma_hpp | 66.64% |
| i422 chroma_hps | 28.86% | luma_vps | 47.69% | i420 sub_ps | 39.34% | i420 chroma_hpp | 66.64% |
| i420 chroma_hps | 29.02% | i420 chroma_hpp | 47.78% | i420 chroma_hps | 39.47% | i420 chroma_hpp | 66.65% |
| sad_x3 | 29.04% | i422 chroma_hps | 47.82% | luma_vpp | 39.54% | i444 chroma_hps | 66.71% |
| i444 chroma_hps | 29.11% | luma_vsp | 47.93% | luma_hvpp | 39.63% | i422 chroma_hpp | 66.71% |
| luma_vsp | 29.13% | luma_hvpp | 48.30% | i444 chroma_vps | 39.68% | i444 chroma_hps | 66.75% |
| luma_vss | 29.26% | addAvg | 48.40% | i420 chroma_vps | 39.68% | i444 chroma_hps | 66.91% |
| i444 chroma_vss | 29.29% | i420 addAvg | 48.40% | luma_hpp | 39.72% | i422 chroma_hpp | 66.92% |
| luma_vpp | 29.39% | luma_hps | 48.96% | addAvg | 39.77% | i444 chroma_hpp | 67.59% |
| luma_vss | 29.59% | luma_hps | 49.05% | convert_p2s | 39.79% | i444 chroma_hpp | 67.78% |
| i420 p2s | 39.79% | i420 chroma_hpp | 69.14% | ||||
| i444 p2s | 39.79% | i444 chroma_hpp | 69.23% |
付録 B
使用した 1080p テストクリップとビットレート 次の 1080p クリップをテスト結果の生成に使用しました。 park_ joy _1080p.y4m
park_ joy _1080p.y4m
 crowd_run_1080p50.y4m
crowd_run_1080p50.y4m
 ducks_take_off_1080p50.y4m
ducks_take_off_1080p50.y4m
 old_town_cross_1080p50.y4m
old_town_cross_1080p50.y4m
 Netflix_Boat_4096x2160_60fps_10bit_420.y4m
Netflix_Boat_4096x2160_60fps_10bit_420.y4m
 Netflix_Tango_4096x2160_60fps_10bit_420.y4m
Netflix_Tango_4096x2160_60fps_10bit_420.y4m
 Netflix_FoodMarket_4096x2160_60fps_10bit_420.y4m
Netflix_FoodMarket_4096x2160_60fps_10bit_420.y4m
付録 C
| インテル® Core™ i7-4500U プロセッサー上でのテスト構成 | |
|---|---|
| システム属性 | 値 |
| OS 名 | Windows® 10 Professional |
| バージョン | 10.0.16299 ビルド 16299 |
| システムモデル | MS-7A93 |
| システムの種類 | x64 ベースの PC |
| プロセッサー | インテル® Core™ i7-4500U CPU @ 3.30GHz、 3312MHz、 10 コア、 20 論理プロセッサー |
| ソケットごとのコア数 | 2 |
| コアごとのスレッド数 | 2 |
| ソケット数 | 1 |
| NUMA ノード数 | 1 |
| BIOS | |
| BIOS バージョン/日付 | American Megatrends Inc. 1.00、6/2/2017 |
| SMBIOS バージョン | 3 |
| BIOS モード | UEFI |
| グラフィック・インターフェイス | |
| バージョン | PCI-Express* |
| リンク幅 | x16 |
| サポートされる最大値 | x16 |
| メモリー | |
| タイプ | DDR3 |
| チャネル | 1 |
| サイズ | 8GB |
| DRAM 周波数 | 800MHz |
| コマンドレート (CR) | 2T |
| インテル® Core™ i9-7900X プロセッサー・ベースのテストシステム構成 | |
|---|---|
| システム属性 | 値 |
| OS 名 | Microsoft* Windows® 10 Enterprise |
| バージョン | 110.0.16299 ビルド 16299 |
| システムモデル | MS-7A93 |
| システムの種類 | x64 ベースの PC |
| プロセッサー | インテル® Core™ i9-7900X CPU @ 3.30GHz、 3312Mhz、 10 コア、 20 論理プロセッサー |
| ソケットごとのコア数 | 10 |
| コアごとのスレッド数 | 2 |
| ソケット数 | 1 |
| NUMA ノード数 | 1 |
| BIOS | |
| BIOS バージョン/日付 | American Megatrends Inc. 1.00, 6/2/2017 |
| SMBIOS バージョン | 3 |
| BIOS モード | UEFI |
| グラフィック・インターフェイス | |
| バージョン | PCI-Express* |
| リンク幅 | x16 |
| サポートされる最大値 | x16 |
| メモリー | |
| タイプ | DDR4 |
| チャネル | 2 |
| サイズ | 32GB |
| DRAM 周波数 | 1066.80MHz |
| コマンドレート (CR) | 2T |
| インテル® Xeon® Platinum 8180 プロセッサー・ベースのテストシステム構成 | |
|---|---|
| システム属性 | 値 |
| OS 名 | CentOS* |
| バージョン | 7.2 |
| システムモデル | インテル® S4PR1SY2B |
| システムの種類 | x86_64 |
| プロセッサー | インテル® Xeon® Platinum 8180 CPU @ 2.50GHz |
| ソケットごとのコア数 | 28 |
| コアごとのスレッド数 | 2 |
| ソケット数: | 2 |
| NUMA ノード数 | 2 |
| BIOS | |
| BIOS バージョン/日付 | SE5C620.86B.0X.01.0007.062120172 125 / 06/21/2017 |
| SMBIOS バージョン | 2.8 |
| BIOS モード | UEFI |
| グラフィック・インターフェイス | |
| バージョン | PCI-Express* |
| リンク幅 | x16 |
| サポートされる最大値 | x16 |
| メモリー | |
| タイプ | DDR4 |
| チャネル | 2 |
| サイズ | 192GB |
| DRAM 周波数 | 1333MHz |
| コマンドレート (CR) | 2T |
参考文献
- David A. Patterson and John L. Hennessey, Computer Organization and Design: the Hardware/Software Interface, 2nd Edition, Morgan Kaufmann Publishers, Inc., San Francisco, California, 1998, p.751.
- VideoLAN Organization, x264, The best H.264/AVC encoder. https://www.videolan.org/developers/x264.html (英語)
- MulticoreWare Inc., x265 HEVC Encoder/H.265 Video Codec. http://x265.org/ (英語)
- G. J. Sullivan, J.-R. Ohm, W.-J. Han and T. Wigand, “Overview of the High Efficiency Video Coding (HEVC) Standard,” IEEE Transactions on Circuits and Systems for Video Technology, vol. 22, no. 12,pp. 1649-1668, 2012.
- Intel Corporation, Intel Advanced Vector Instructions 512. https://www.intel.in/content/www/in/en/architecture-and-technology/avx-512-overview.html
- Intel Corporation, “Intel® Xeon® Processor Scalable Family Specification Update”, February, 2018. https://www.intel.com/content/dam/www/public/us/en/documents/specification-updates/xeon-scalable-spec-update.pdf (英語)
- x265.org (英語)
- HandBrake, An OpenSource Video Transcoder. https://handbrake.fr/ (英語)
- FFMPEG, A complete, cross-platform solution to record, convert and stream audio and video. (英語)
- MulticoreWare Inc., “x265 Receives Significant Boost from Intel Xeon Scalable Processor Family.” http://x265.org/x265-receives-significant-boost-intel-xeon-scalable-processor-family/ (英語)
