

この記事は、The Parallel Universe Magazine 50 号に掲載されている「Habana Gaudi*2 Processor for Deep Learning」の日本語参考訳です。原文は更新される可能性があります。原文と翻訳文の内容が異なる場合は原文を優先してください。

2022年5月に開催されたインテル® Vision 2022 において、インテルの関連会社である Habana は、トレーニング・パフォーマンスが大幅に向上した第 2 世代ディープラーニング・プロセッサー「Gaudi2*」 (図 1) を発表しました。高効率な第 1 世代 Gaudi* アーキテクチャーをベースに、AWS* EC2* DL1 クラウド・インスタンスやオンプレミスの Supermicro Gaudi* AI Training Server でコスト・パフォーマンスを最大 40% 向上します。プロセスを 16nm から 7nm に縮小し、AI にカスタマイズされたテンソル・プロセッサー・コアを 8 から 24 に増やし、FP8 サポートを追加し、メディア圧縮エンジンを統合しています。Gaudi2* のパッケージメモリーは 3 倍になり、HBM2e 96GB、帯域幅 2.45TB/秒になりました。これらの進化により、一般的なコンピューター・ビジョンや自然言語処理モデルにおいて、NVIDIA* A100 80G と比較して高いスループットを実現します (図 2 と図 3)。
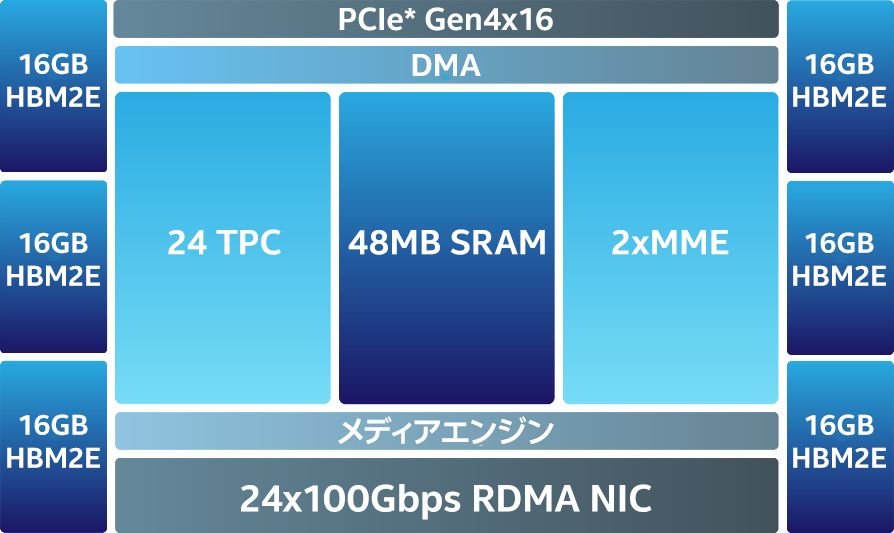
図 1. Gaudi2* アーキテクチャー
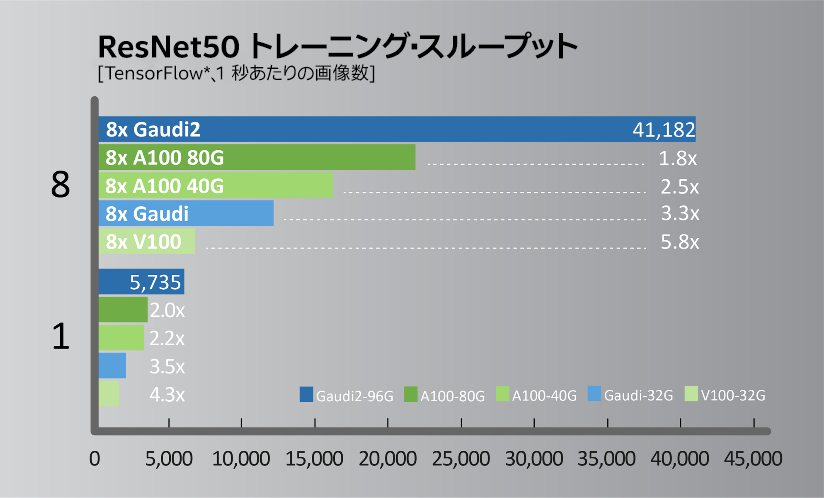
図 2. ResNet50 トレーニング・スループットの比較。システム構成: https://github.com/HabanaAI/Model-References/tree/master/TensorFlow/computer_vision/Resnets/resnet_keras (英語)。Habana* SynapseAI* コンテナー: https://vault.habana.ai/ui/repos/tree/General/gaudi-docker/1.6.0/ubuntu20.04/habanalabs/tensorflow-installer-tf-cpu-2.9.1 (英語)。Habana* Gaudi* パフォーマンス: https://developer.habana.ai/resources/habana-training-models (英語)。結果は異なることがあります。NVIDIA* A100/V100 パフォーマンスの出典: https://ngc.nvidia.com/catalog/resources/nvidia:resnet_50_v1_5_for_tensorflow/performance (英語) で公表されている NVIDIA DGX* A100-40G と NVIDIA DGX* V100-32G の結果。
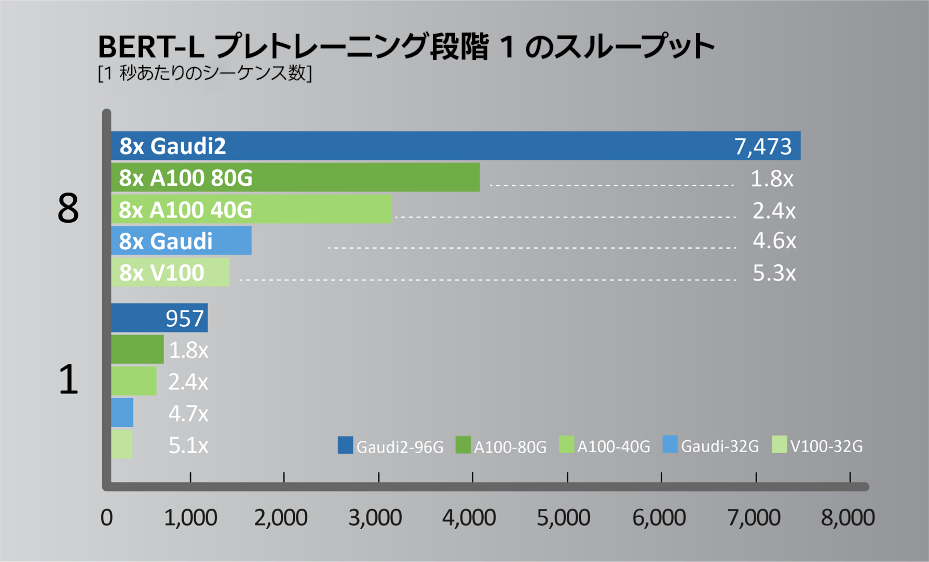
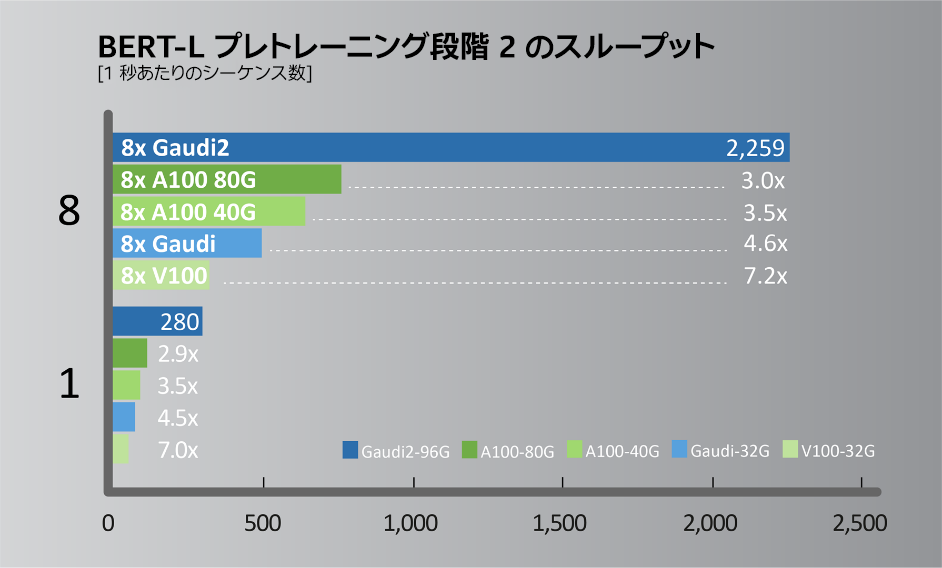
図 3. BERT-L プレトレーニング段階 1 と 2 のスループットの比較。システム構成: A100-80GB:Habana による測定値。Azure* インスタンス Standard_ND96amsr_A100_v4 で単一の A100-80GB と NVIDIA* NGC の TF docker 22.03-tf2-py3 を使用して測定 (段階 1: Seq len=128、BS=312、accu steps=256。段階 2: seq len=512、BS=40、accu steps=768)。A100-40GB:Habana による測定値。NVIDIA DGX* A100 で単一の A100-40GB と NVIDIA* NGC の TF docker 22.03-tf2-py3 を使用して測定 (段階 1: Seq len=128、BS=64、accu steps=1024。段階 2: seq len=512、BS=16、accu steps=2048)。V100-32GB:Habana による測定値。NVIDIA p3dn.24xlarge で単一の V100-32GB と NVIDIA* NGC の TF docker 21.12-tf2-py3 を使用して測定 (段階 1: Seq len=128、BS=64、accu steps=1024。段階 2: seq len=512、BS=8、accu steps=4096)。Gaudi2*: Habana による測定値。Gaudi2*-HLS システムで単一の Gaudi2* と SynapseAI* TF docker 1.5.0 を使用して測定 (段階 1: Seq len=128、BS=64、accu steps=1024。段階 2: seq len=512、BS=16、accu steps=2048) 。結果は異なることがあります。
100Gb の RoCE2 (RDMA over Converged Ethernet) ポートは、第 1 世代 Gaudi* の 10 個から、Gaudi2* で 24 個に増え、トレーニング・パフォーマンスをコスト効率良く簡単にスケールアウトできるようになりました。各 Gaudi2* の 21 のポートは、サーバー内のほかの 7 つのプロセッサーに All-to-All のノンブロッキング構成で接続するためのものです (図 4)。各プロセッサーのポートのうち 3 つはスケールアウト専用で、8 枚構成の Gaudi* サーバーである HLS-Gaudi2* は 2.4Tb のネットワーク・スループットを提供します。システム設計を簡素化するため、Habana では 8 枚構成の Gaudi2* ベースボードも提供しています。オンチップの RoCE により、ディープラーニング・クラスターの要件に合わせて、1 台から 1000 台までの Gaudi2* システムを簡単に構成できます。また、業界標準のイーサネットでシステムを実装することで、Gaudi2* はイーサネット・スイッチとネットワーク機器の選択肢を広げ、さらなるコスト削減を可能にします。また、ネットワーク・インターフェイス・コントローラー・ポートをオンチップにすることにより、部品点数と総システムコストを削減します。
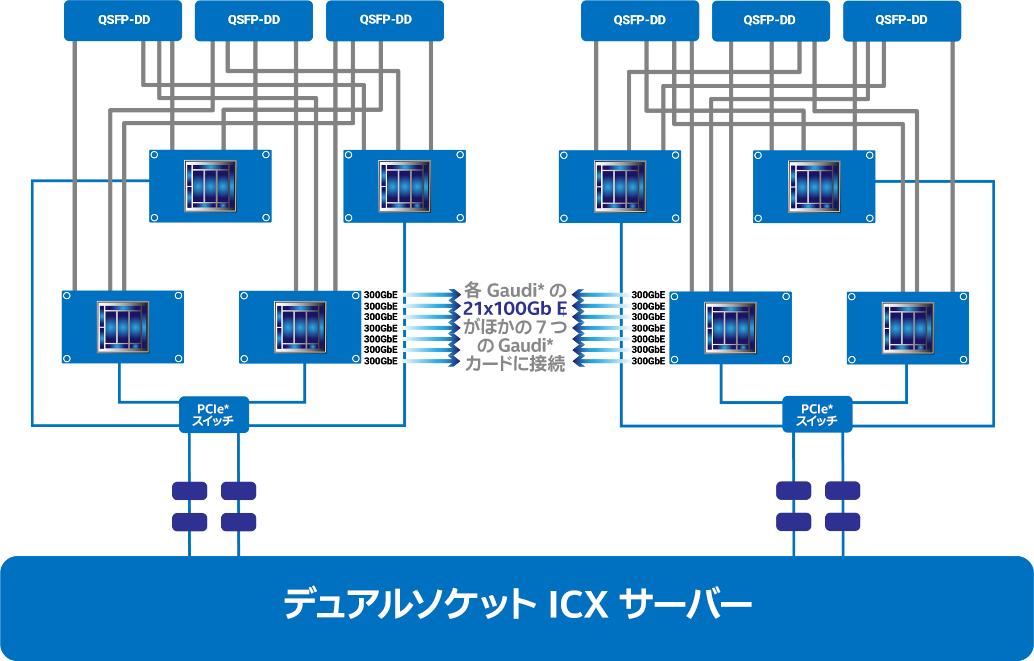

図 4. Gaudi2* ネットワーク構成
