
この記事は、The Parallel Universe Magazine 47 号に掲載されている「Scale Your pandas Workflow with Modin*」の日本語参考訳です。原文は更新される可能性があります。原文と翻訳文の内容が異なる場合は原文を優先してください。

AI やデータサイエンスが急速に進化することで、膨大な量のデータが利用できるようになり、日々複雑化し続けるアイデアや解決策を導き出すことができます。一方で、これらの進化は、価値抽出からシステム・エンジニアリングへと焦点が移っています。また、ハードウェアの性能は、人が適切な活用方法を学ぶよりも速いスピードで成長しています。
このような傾向から、「データエンジニア」という新しいポジションが登場したり、データ・サイエンティストがデータサイエンスの中核である調査ではなく、インフラストラクチャー関連の問題に対処する必要性が出ています。その主な理由の 1 つは、データ・サイエンティスト向けに最適化されたデータサイエンスとマシンラーニングのインフラストラクチャーが存在しないことです。すべてのデータ・サイエンティストがソフトウェア・エンジニアリングに精通しているわけではありません。この 2 つは、別々の、ときどき重複するスキルセットと考えることができます。
データ・サイエンティストは習慣の生き物です。彼らは、pandas*、scikit-learn*、NumPy*、PyTorch* など、Python* データスタックで慣れ親しんだツールを好みます。しかし、これらのツールは、通常、並列処理やテラバイトのデータには適していません。
Anaconda とインテルは、データ・サイエンティストにとって最も重要な、使い慣れたソフトウェア・スタックと API をいかにスケーラブルかつ高速にするかという問題を解決するため協力しています。この記事では、Anaconda の「defaults」チャネル (および conda-forge) から利用可能な、インテル® oneAPI AI アナリティクス・ツールキット (AI キット) (英語) に含まれるインテル® ディストリビューションの Modin (英語) を紹介します。
pandas* だけでは十分でない理由
pandas* は業界標準ですが、本質的に多くの場合シングルスレッドで動作し、大規模なデータセットでは遅くなります。メモリーに収まらないデータセットでは動作しない場合もあります。この問題を解決するほかの選択肢 (例えば、Dask、pySpark、vaex.io など) もありますが、どれも pandas* と完全に互換性のあるインターフェイスを提供していないため、ユーザーはワークロードを変更する必要があります。
Modin はエンドユーザーに何を提供するのでしょうか? Modin は、「ツールはデータ・サイエンティストの役に立つべきであって、その逆はない」という考えに忠実であろうとしています。「import pandas as pd」文を「importmodin.pandas as pd」文に変更するだけで、多くのユースケースでスケーラビリティーを向上できます。
Modin を使用する理由
「pandas* ワークフローを別のフレームワークに書き換える」必要をなくすことで、データインサイトの開発サイクルの短縮が可能になります (図 1)。
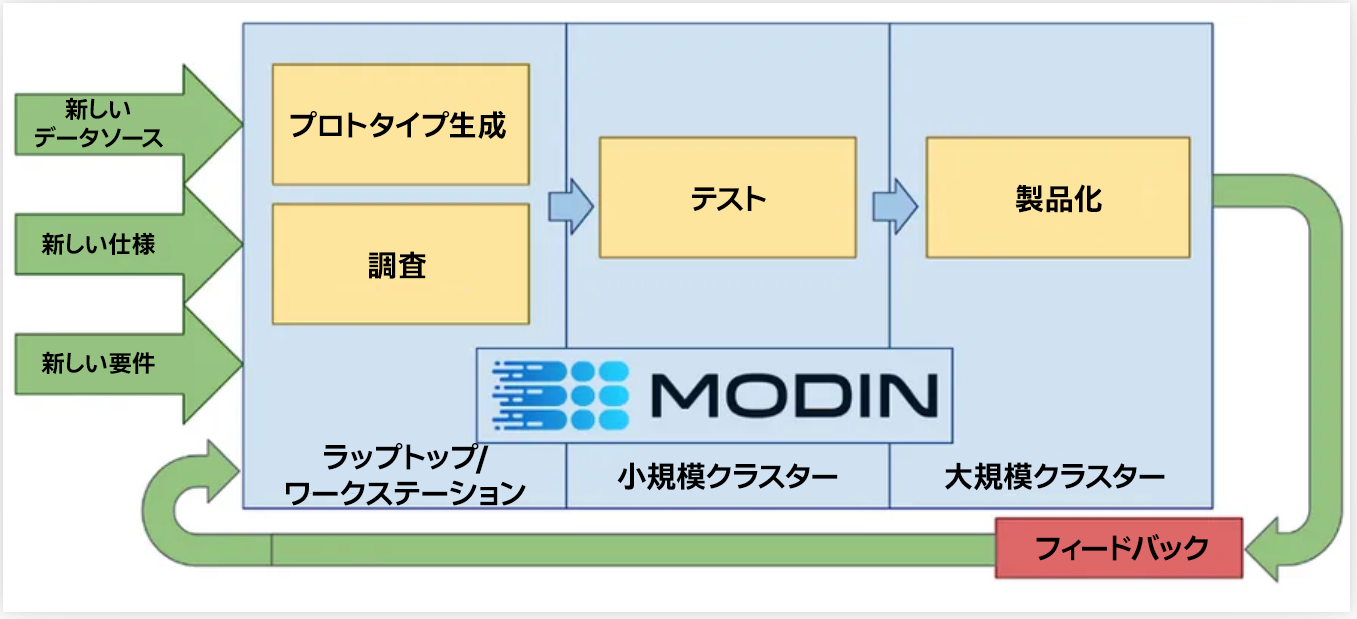
図 1. 継続的な開発サイクルでの Modin の使用
Modin は、DataFrame をグリッド分割することで、特定の操作をセル単位、列単位、行単位で並列分散して実行し、ハードウェアを効率良く活用します (図 2)。特定の操作では、OmniSci* エンジンとの実験的な統合を利用して、マルチコアのパワーをさらに活用することが可能です。
製品とパフォーマンス情報
1実際の性能は利用法、構成、その他の要因によって異なります。詳細については、www.Intel.com/PerformanceIndex (英語) を参照してください。
