
この記事は、The Parallel Universe Magazine 46 号に掲載されている「A Novel Scale-Out Training Solution for Deep Learning Recommender Systems」の日本語参考訳です。

DLRM(Deep Learning Recommendation Model)は、Facebook が導入したディープラーニング・ベースの推奨モデルです。最先端のモデルであり、MLPerf* トレーニング・ベンチマークの一部となっています。DLRM は、計算、メモリー、I/O 依存の処理のバランスを取る必要があるため、シングルソケットおよびマルチソケットの分散型トレーニングにおいて独自の課題を抱えています。この課題を解決するため、データとモデルの並列化、新しいハイブリッドの Split-SGD + LAMB オプティマイザー、より大きなグローバル・バッチ・サイズでモデルを収束させる効率良いハイパーパラメーター・チューニング、スケールアップおよびスケールアウトをサポートする新しいデータローダーを用いて、インテル® Xeon® プロセッサー・ベースのクラスター上で DLRM トレーニングの効率的なスケールアウト・ソリューションを実装しました。MLPerf* v1.0 のトレーニング結果では、64 個のインテル® Xeon® 8376H プロセッサーを使用して、DLRM を 15 分でトレーニングできることが示されています。これは、MLPerf* v0.7(16 個のインテル® Xeon® 8380 プロセッサーにしかスケーリングできなかった)に比べて 3 倍のパフォーマンス向上です。この記事では、このパフォーマンス向上を実現するために行った最適化について説明します。
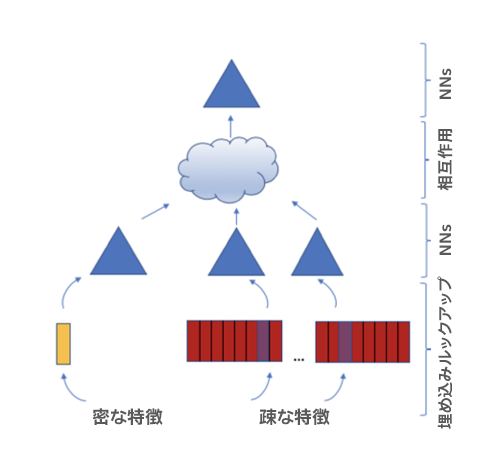
図 1.DLRM モデルの構造。密な特徴は下位 MLP(多層パーセプトロン)層の入力であり、疎な特徴は埋め込みテーブルの入力です。下位 MLPと埋め込みからの出力は、上位 MLP 層の入力となります。
垂直分割埋め込みテーブルベースのハイブリッド並列処理
DLRM MLPerf* トレーニングのスケーラビリティーを向上させるためハイブリッド並列ソリューションを使用し、さらにスケーラビリティー向上のため垂直分割埋め込みテーブルを使用します(図 1)。
MLPerf* の DLRM トレーニングには 26 個の埋め込みテーブルがあります。テーブルのエントリー番号は、40M、40M、40M、40M、40790948、3067956、590152、405282、39060、20265、17295、12973、11938、7424、7122、2209、1543、976、155、108、63、36、14、10、4、および 3 です。各エントリーのセマンティクスをモデル化するため、128 個の Float32/Bloat16 数値が使用されています。埋め込みテーブルを処理する簡単な方法は、疎な all-reduce によるデータ並列処理です。モデルのウェイトは、モデル・インスタンス間で複製する必要があります。また、データ並列処理ではすべての埋め込みテーブルを複製する必要があるため、26 個の埋め込みテーブルを使用すると、1 つのモデル・インスタンスに 100GB 以上のメモリーが必要になります。
通信のオーバーヘッドと各デバイスの必要メモリーを軽減するため、ハイブリッド並列分散トレーニング・ソリューションを使用しています(図 2 と 3)。埋め込みテーブルは、密な勾配を使用する小さなテーブルと、疎な勾配を使用する大きな埋め込みテーブルに分けられます。MLPerf* DLRM の場合、埋め込みテーブルはエントリー番号が 2048 未満の場合は小さなテーブルとして、それ以上は大きなテーブルとして扱われます。ここでは、10 個の小さな埋め込みテーブルと 16 個の大きな埋め込みテーブルがあります。モデルを並列処理する関係からモデル・インスタンスは、大きな埋め込みテーブルの一部のローカルコピーを保持します。例えば、8 つのソケットを使用し、1 つのソケットに 1 つのインスタンスを使用した場合、すべてのインスタンスが 2 つの大きな埋め込みテーブルを保持します。16 ソケットの場合、各インスタンスは 1 つの大きな埋め込みテーブルしか保持しません。各モデル・インスタンスは、ローカルバッチのインデックスで埋め込みテーブルをルックアップする代わりに、グローバルバッチのインデックスでローカルの埋め込みテーブルをルックアップします。ルックアップ操作の後、モデル・インスタンスは、自分のローカルバッチのルックアップ・エントリーだけでなく、ほかのインスタンスのバッチのルックアップ・エントリーも保持することになります。ランク間の埋め込み情報の交換には、all-to-all の集合通信が使用されます。データ並列処理を行うため、下位 MLP、上位 MLP、10 個の小さな埋め込みテーブルをすべてのモデル・インスタンスで複製し、ランク間の勾配を平均化するため all-reduce 集合通信が使用されます。
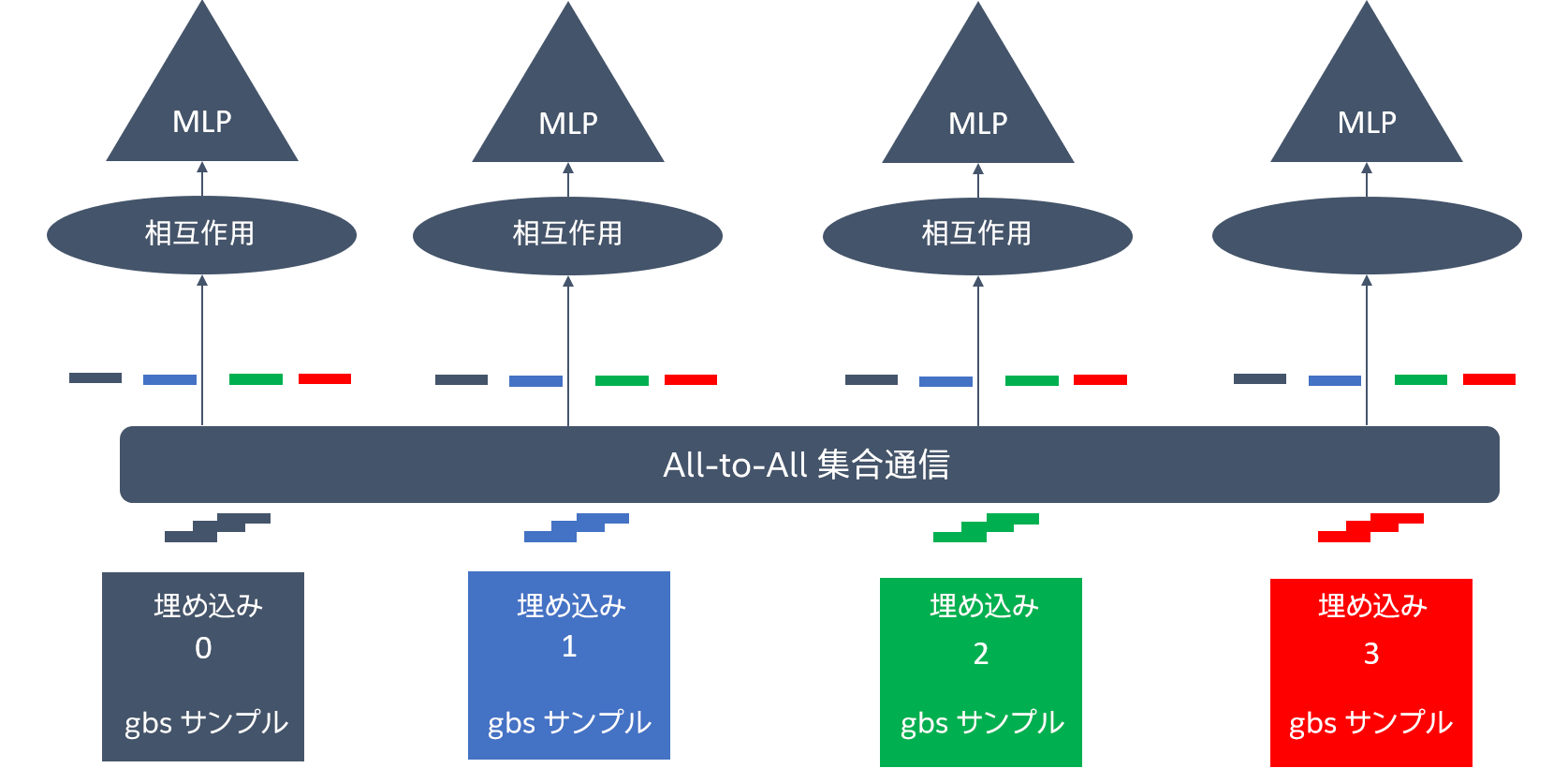
図 2. 4 つの埋め込みテーブルを持つ 4 つのモデル・インスタンス間のハイブリッド並列処理を示しています。色付きのブロックは異なる埋め込みテーブルを示します(gbs: グローバル・バッチ・サイズ)。同じ埋め込みテーブルからのルックアップ・エントリーが異なるインスタンスに分散されています。
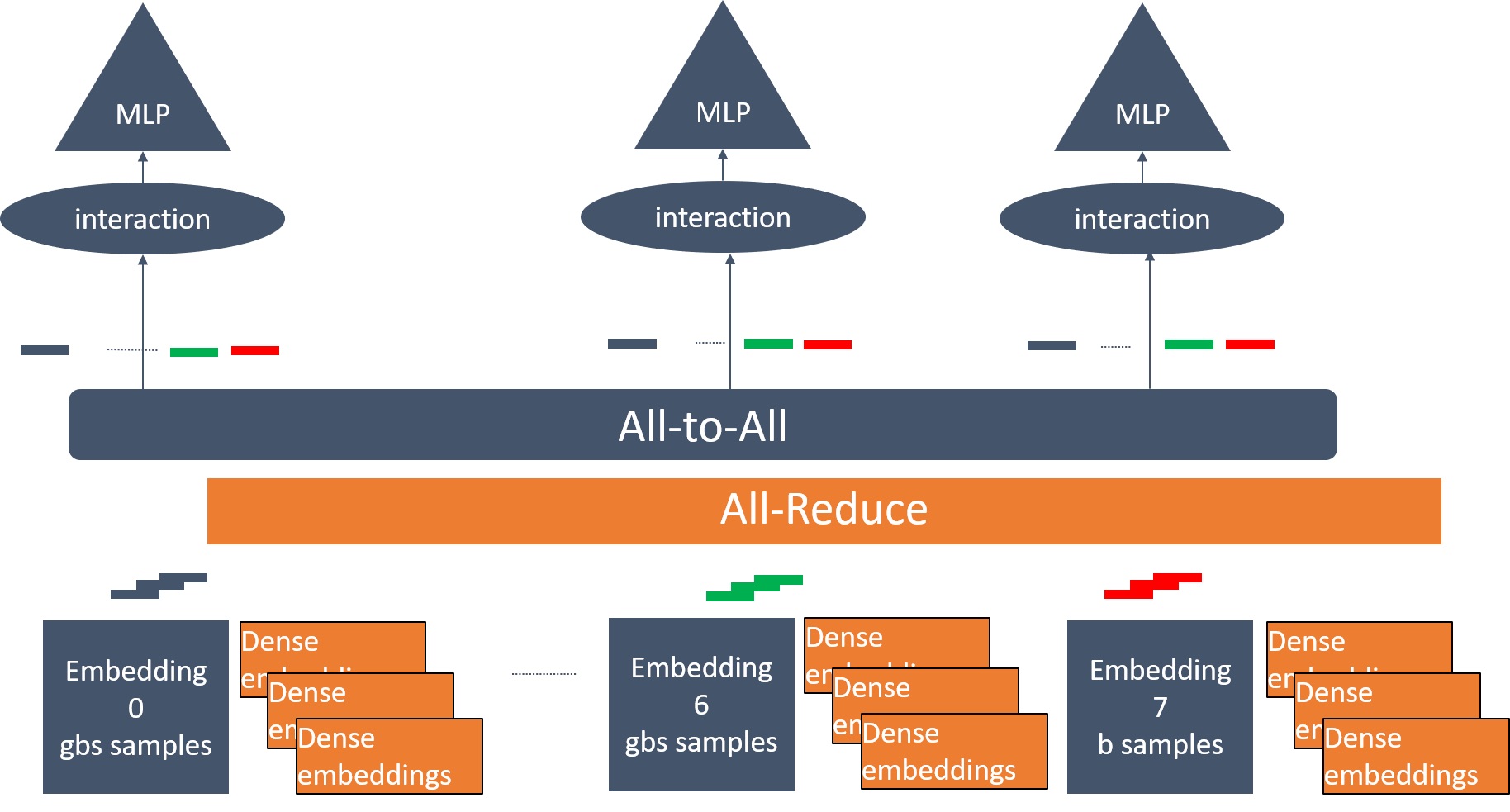
図 3. 小さな埋め込みテーブルの勾配を密な勾配に変換します。データ並列処理の勾配の同期には all-reduce を、モデル並列処理の埋め込み情報の交換には all-to-all を使用しています。
製品とパフォーマンス情報
1実際の性能は利用法、構成、その他の要因によって異なります。詳細については、www.Intel.com/PerformanceIndex (英語) を参照してください。
